operador summarize
Produz uma tabela que agrega o conteúdo da tabela de entrada.
Sintaxe
T [ SummarizeParameters ] [[Coluna = ] Agregação [, ...]] [by [Coluna =] GroupExpression [, ...]] | summarize
Saiba mais sobre as convenções de sintaxe.
Parâmetros
| Nome | Digitar | Obrigatória | Descrição |
|---|---|---|---|
| Coluna | string |
O nome da coluna de resultado. Assume o padrão de um nome derivado da expressão. | |
| Agregação | string |
✔️ | Uma chamada para uma função de agregação, como count() ou avg(), com nomes de coluna como argumentos. |
| GroupExpression | escalar | ✔️ | Uma expressão escalar que pode fazer referência aos dados de entrada. A saída terá o mesmo número de registros e de valores distintos em todas as expressões de grupo. |
| SummarizeParameters | string |
Zero ou mais parâmetros separados por espaço na forma de Name = Value que controlam o comportamento. Confira os parâmetros com suporte. |
Observação
Quando a tabela de entrada está vazia, a saída depende do uso de GroupExpression:
- Se GroupExpression não for fornecido, a saída será uma linha única (vazia).
- Se GroupExpression for fornecido, a saída não terá linhas.
Parâmetros com suporte
| Nome | Descrição |
|---|---|
hint.num_partitions |
Especifica o número de partições usadas para compartilhar a carga de consulta em nós de cluster. Confira a consulta aleatória |
hint.shufflekey=<key> |
A consulta shufflekey compartilha a carga de consulta em nós de cluster usando uma chave para particionar dados. Confira a consulta aleatória |
hint.strategy=shuffle |
A consulta de estratégia shuffle compartilha a carga de consulta em nós de cluster, em que cada nó processará uma partição dos dados. Confira a consulta aleatória |
Retornos
As linhas de entrada são organizadas em grupos com os mesmos valores que as expressões by . Em seguida, as funções de agregação especificadas são calculadas sobre cada grupo, produzindo uma linha para cada grupo. O resultado contém as colunas by e pelo menos uma coluna para cada agregação calculada. (Algumas funções de agregação retornam várias colunas.)
O resultado tem a mesma quantidade de linhas e de diferentes combinações de valores by (que pode ser zero). Se nenhuma chave de grupo for fornecida, o resultado terá um único registro.
Para resumir intervalos de valores numéricos, use bin() para reduzir os intervalos a valores discretos.
Observação
- Embora você possa fornecer expressões aleatórias para as expressões de agregação e de agrupamento, é mais eficiente usar nomes de coluna simples ou aplicar
bin()a uma coluna numérica. - Não há mais suporte para os compartimentos de hora automática das colunas datetime. Em vez disso, use a compartimentalização explícita. Por exemplo,
summarize by bin(timestamp, 1h).
Valores padrão das agregações
A seguinte tabela resume os valores padrão das agregações:
| Operador | Valor padrão |
|---|---|
count(), countif(), dcount(), dcountif(), count_distinct(), sum(), sumif(), , variance(), varianceif(), stdev(), stdevif() |
0 |
make_bag(), make_bag_if(), make_list(), make_list_if(), , make_set()make_set_if() |
Matriz dinâmica vazia ([]) |
| Todos os outros | nulo |
Observação
Ao aplicar essas agregações a entidades que incluem valores nulos, os valores nulos são ignorados e não são considerados no cálculo. Para obter exemplos, confira Valores padrão das agregações.
Exemplos
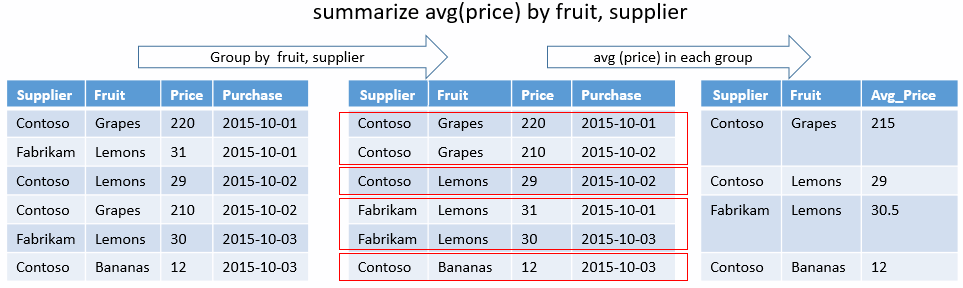
Combinação exclusiva
A consulta a seguir determina as combinações exclusivas de State e EventType que existem para tempestades que resultaram em lesões diretas. Não há funções de agregação, apenas chaves de agrupamento. A saída só exibirá as colunas desses resultados.
StormEvents
| where InjuriesDirect > 0
| summarize by State, EventType
Saída
A tabela a seguir mostra apenas as cinco primeiras linhas. Para ver a saída completa, execute a consulta.
| Estado | EventType |
|---|---|
| TEXAS | Thunderstorm Wind |
| TEXAS | Saturação de Flash |
| TEXAS | Clima de Inverno |
| TEXAS | Vento Forte |
| TEXAS | Saturação |
| ... | ... |
Carimbo de data/hora mínimo e máximo
Encontra as tempestades de chuva forte mínimas e máximas no Havaí. Não há nenhuma cláusula group-by, ou seja, há apenas uma linha na saída.
StormEvents
| where State == "HAWAII" and EventType == "Heavy Rain"
| project Duration = EndTime - StartTime
| summarize Min = min(Duration), Max = max(Duration)
Saída
| Mín | Max |
|---|---|
| 01:08:00 | 11:55:00 |
Contagem distinta
Crie uma linha para cada continente, mostrando uma contagem das cidades nas quais as atividades ocorrem. Como há poucos valores para "continent", nenhuma função de agrupamento é necessária na cláusula 'by':
StormEvents
| summarize TypesOfStorms=dcount(EventType) by State
| sort by TypesOfStorms
Saída
A tabela a seguir mostra apenas as cinco primeiras linhas. Para ver a saída completa, execute a consulta.
| Estado | TypesOfStorms |
|---|---|
| TEXAS | 27 |
| CALIFÓRNIA | 26 |
| Pensilvânia | 25 |
| GEÓRGIA | 24 |
| ILLINOIS | 23 |
| ... | ... |
Histograma
O exemplo a seguir calcula um tipo de evento de tempestade de histograma que teve tempestades que duraram mais de um dia. Como Duration tem muitos valores, use bin() para agrupar os valores em intervalos de um dia.
StormEvents
| project EventType, Duration = EndTime - StartTime
| where Duration > 1d
| summarize EventCount=count() by EventType, Length=bin(Duration, 1d)
| sort by Length
Saída
| EventType | Comprimento | EventCount |
|---|---|---|
| Seca | 30.00:00:00 | 1646 |
| Wildfire | 30.00:00:00 | 11 |
| Calor | 30.00:00:00 | 14 |
| Saturação | 30.00:00:00 | 20 |
| Chuva Forte | 29.00:00:00 | 42 |
| ... | ... | ... |
Agrega os valores padrão
Quando a entrada do operador summarize tiver pelo menos uma chave group-by, o resultado também será vazio.
Quando a entrada do operador summarize não possui uma chave de agrupamento por vazia, o resultado são os valores padrão das agregações utilizadas no summarize. Para obter mais informações, consulte Valores padrão das agregações.
datatable(x:long)[]
| summarize any_x=take_any(x), arg_max_x=arg_max(x, *), arg_min_x=arg_min(x, *), avg(x), buildschema(todynamic(tostring(x))), max(x), min(x), percentile(x, 55), hll(x) ,stdev(x), sum(x), sumif(x, x > 0), tdigest(x), variance(x)
Saída
| any_x | arg_max_x | arg_min_x | avg_x | schema_x | max_x | min_x | percentile_x_55 | hll_x | stdev_x | sum_x | sumif_x | tdigest_x | variance_x |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NaN | 0 | 0 | 0 | 0 |
O resultado de avg_x(x) é NaN devido à divisão por 0.
datatable(x:long)[]
| summarize count(x), countif(x > 0) , dcount(x), dcountif(x, x > 0)
Saída
| count_x | countif_ | dcount_x | dcountif_x |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
datatable(x:long)[]
| summarize make_set(x), make_list(x)
Saída
| set_x | list_x |
|---|---|
| [] | [] |
A agregação média soma todos os não nulos e conta apenas aqueles que participaram do cálculo (não considera nulos).
range x from 1 to 4 step 1
| extend y = iff(x == 1, real(null), real(5))
| summarize sum(y), avg(y)
Saída
| sum_y | avg_y |
|---|---|
| 15 | 5 |
A contagem regular contará valores nulos:
range x from 1 to 2 step 1
| extend y = iff(x == 1, real(null), real(5))
| summarize count(y)
Saída
| count_y |
|---|
| 2 |
range x from 1 to 2 step 1
| extend y = iff(x == 1, real(null), real(5))
| summarize make_set(y), make_set(y)
Saída
| set_y | set_y1 |
|---|---|
| [5.0] | [5.0] |
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de