Monitorar o desempenho, a integridade e o uso do Azure Data Explorer com métricas
As métricas de Data Explorer do Azure fornecem indicadores-chave para a integridade e o desempenho dos recursos de cluster do Azure Data Explorer. Use as métricas detalhadas neste artigo para monitorar o uso, a integridade e o desempenho do cluster Data Explorer do Azure em seu cenário específico como métricas autônomas. Você pode usar métricas como a base para Painéis do Azure e Alertas do Azure operacionais.
Para obter mais informações sobre o Azure Metrics Explorer, confira Metrics Explorer.
Pré-requisitos
- Uma assinatura do Azure. Criar uma conta gratuita do Azure.
- Um cluster e um banco de dados do Azure Data Explorer. Criar um cluster e um banco de dados.
Use as métricas para monitorar os recursos do Azure Data Explorer
- Entre no portal do Azure.
- No painel esquerdo do cluster Data Explorer do Azure, pesquise métricas.
- Selecione métricas para abrir o painel métricas e iniciar a análise no cluster.
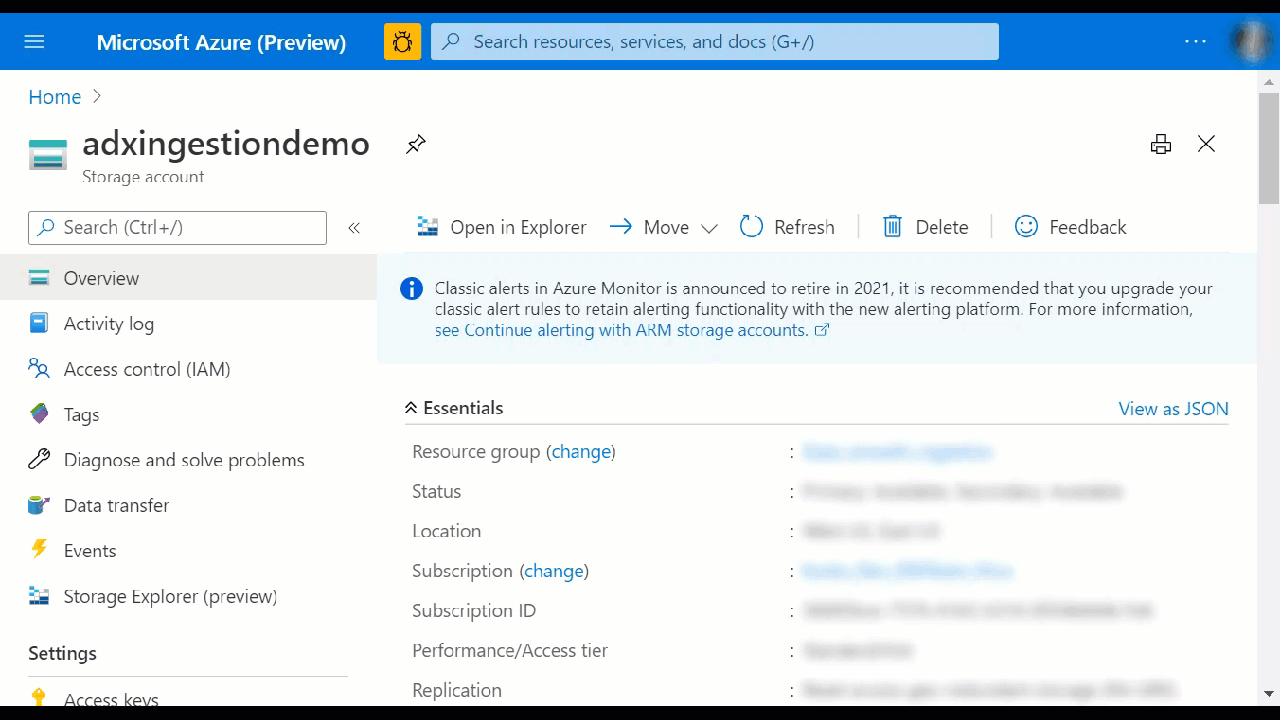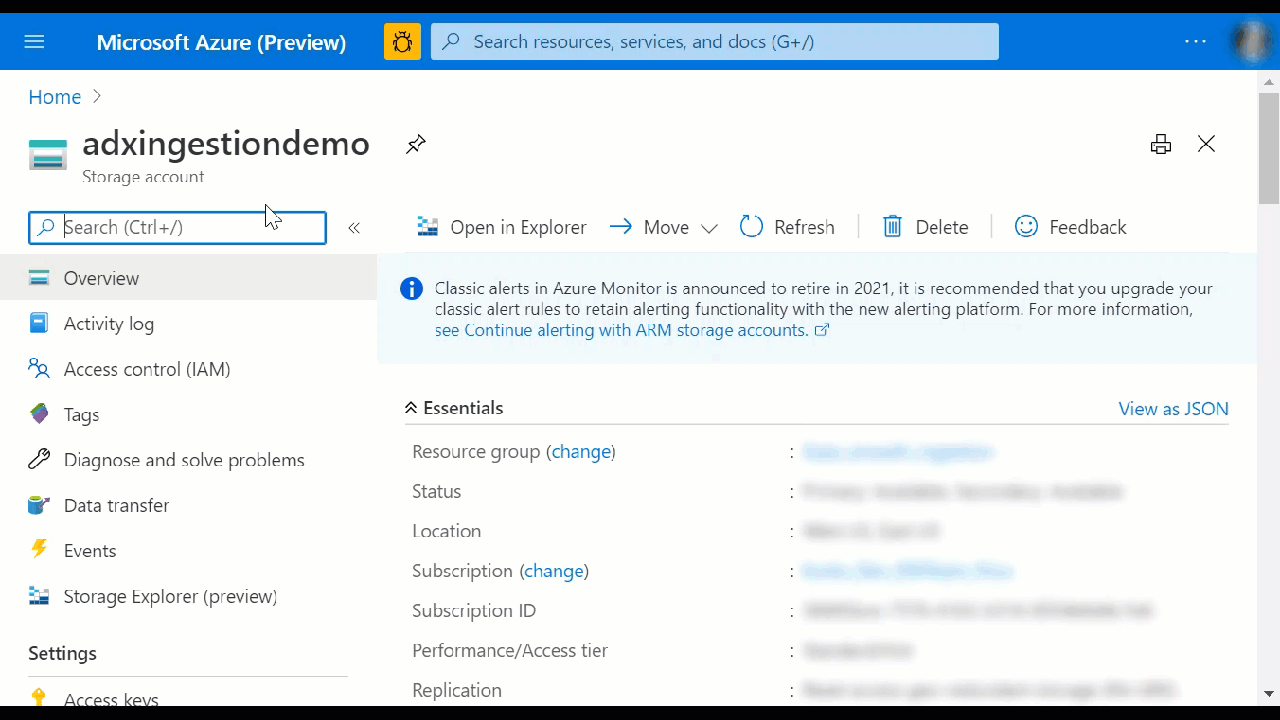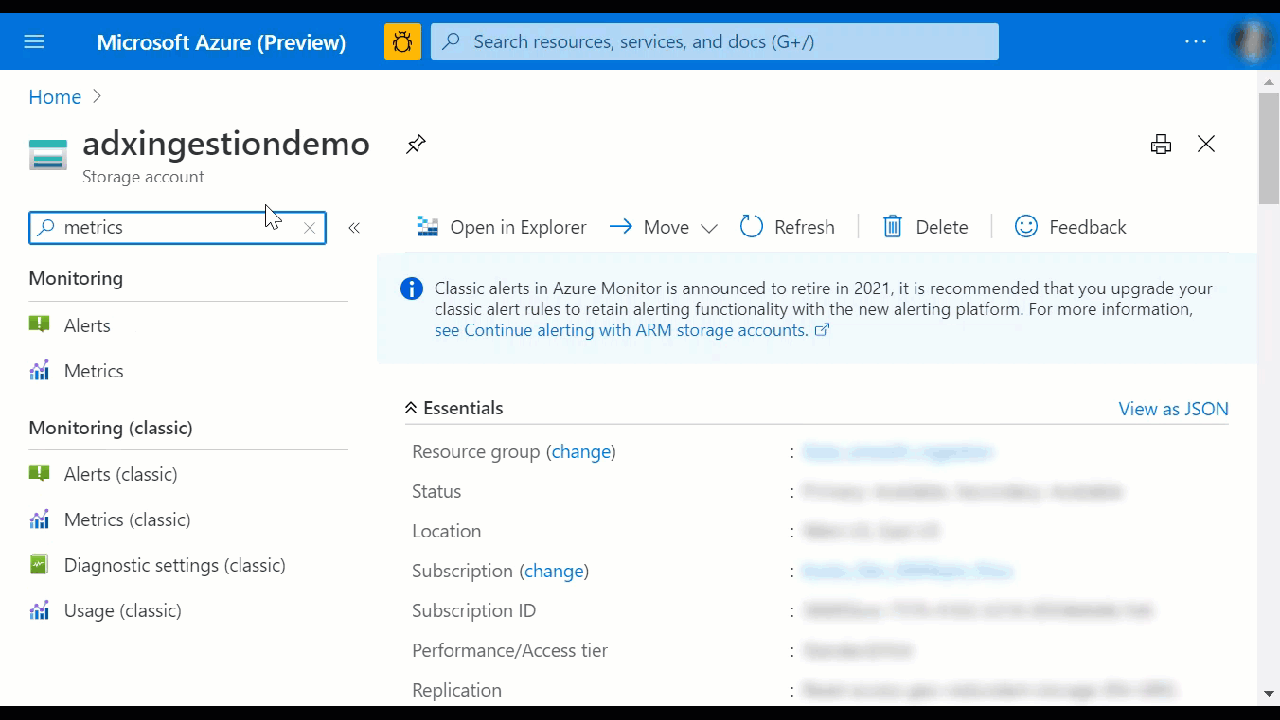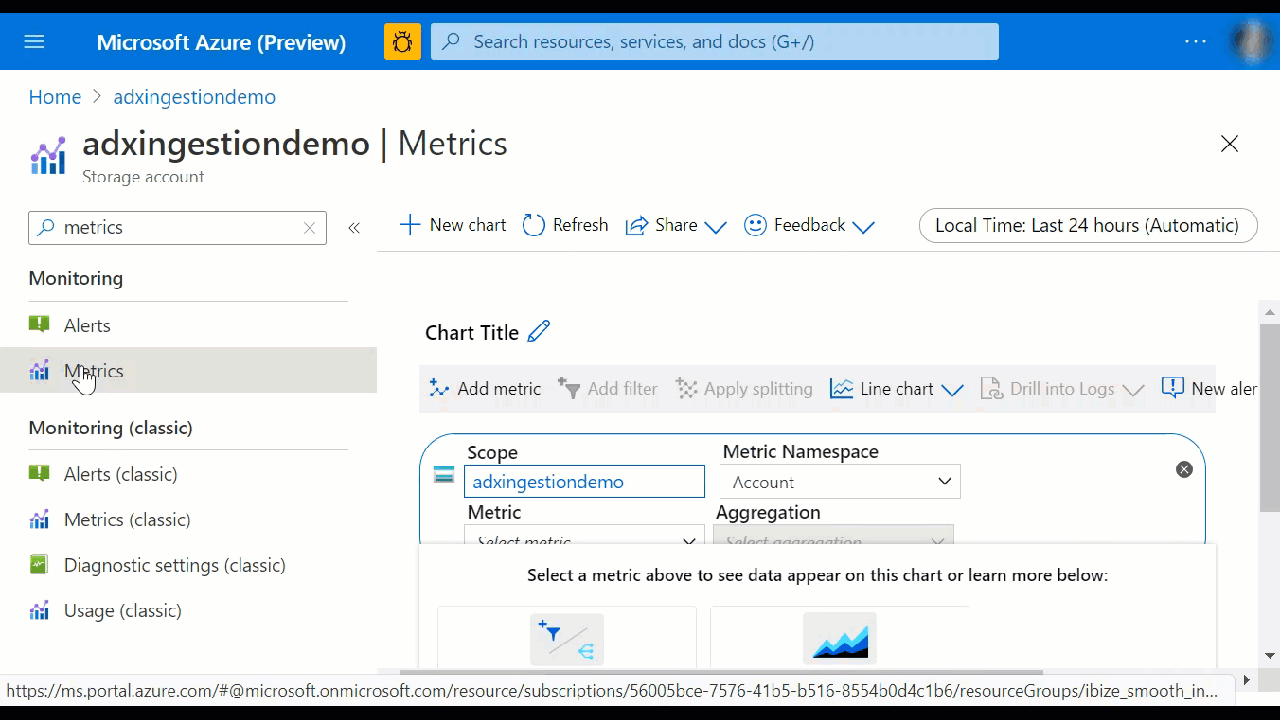
Trabalhar no painel métricas
No painel métricas, selecione métricas específicas a serem controladas, escolha como agregar seus dados e crie gráficos de métricas para exibir em seu painel.
Os seletores de Recurso e Namespace de métrica são previamente selecionados para o cluster do Azure Data Explorer. Os números na imagem a seguir correspondem à lista numerada abaixo. Eles orientam você pelas diferentes opções de configuração e exibição de suas métricas.
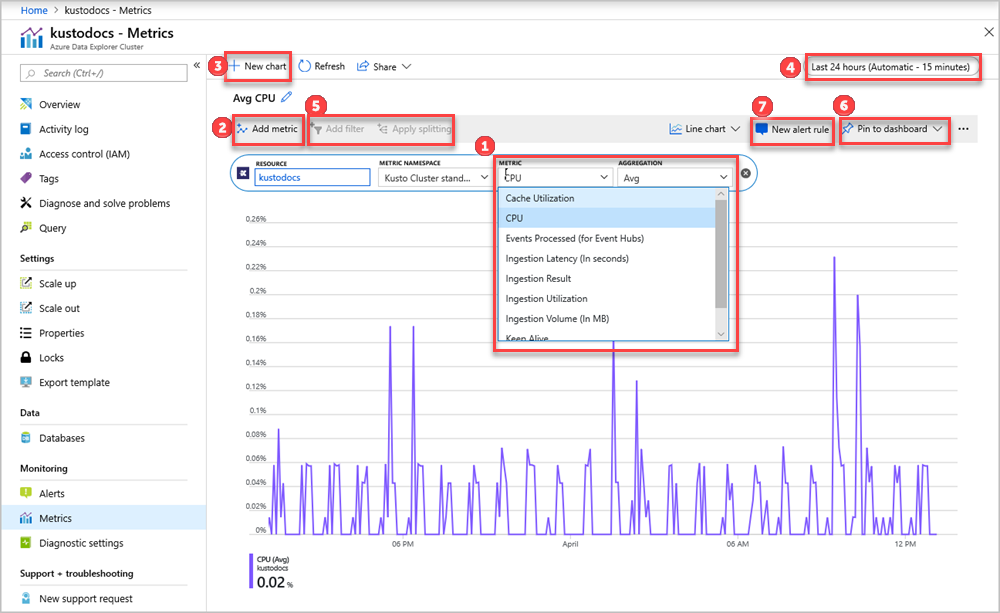
- Para criar um gráfico de métrica, selecione nome da Métrica e Agregação relevante por métrica. Para obter mais informações sobre métricas diferentes, consulte métricas do Azure Data Explorer com suporte.
- Selecione Adicionar métrica para ver várias métricas plotadas no mesmo gráfico.
- Para vários gráficos em uma única exibição, selecione o botão + Novo gráfico.
- Use o seletor de tempo para alterar o intervalo de tempo (padrão: últimas 24 horas).
- Use Adicionar filtro e Aplicar divisão para métricas que têm dimensões.
- Selecione Fixar no painel para adicionar a configuração do gráfico aos painéis para que você possa exibi-lo novamente.
- Defina Nova regra de alerta para visualizar suas métricas usando os critérios definidos. A nova regra de alerta incluirá seu recurso de destino, métrica, divisões e dimensões de filtro do seu gráfico. Modifique essas configurações usando o painel criação de regra de alerta.
Métricas do Azure Data Explorer com suporte
As métricas de do Azure Data Explorer fornecem informações sobre o desempenho geral e o uso dos recursos, bem como sobre ações específicas, como ingestão ou consulta. As métricas neste artigo foram agrupadas por tipo de uso.
Os tipos de métricas são:
- Métricas de cluster
- Métricas de exportação
- Métricas de ingestão
- Métricas da ingestão de streaming
- Métricas de consulta
- Métricas de exibição materializada
Para obter uma lista alfabética das métricas de Azure Monitor para o Azure Data Explorers, consulte métricas de cluster do Azure Data Explorer com suporte.
Métricas de cluster
As métricas de cluster rastreiam a integridade geral do cluster. Por exemplo, uso de recursos e ingestão e capacidade de resposta.
| Métrica | Unidade | Agregação | Descrição da métrica | Dimensões |
|---|---|---|---|---|
| Utilização do cache (preterido) | Percentual | Avg, Max, Min | Percentual de recursos de cache alocados atualmente em uso pelo cluster. O cache é o tamanho do SSD alocado para a atividade do usuário de acordo com a política de cache definida. Uma utilização média de cache de até 80% é um estado sustentável para um cluster. Se a utilização média do cache for superior a 80%, o cluster deverá ser dimensionado para um nível de preços otimizado para armazenamento ou escalado horizontalmente para mais instâncias. Como alternativa, adapte a política de cache para menos dias no cache. Se a utilização do cache for superior a 100%, o tamanho dos dados a serem armazenados nele será maior que o tamanho total do cache no cluster. Essa métrica foi preterida e é apresentada somente para compatibilidade com versões anteriores. Em vez disso, use a métrica ‘Fator de utilização do cache’. |
Nenhum |
| Fator de utilização de cache | Percentual | Avg, Max, Min | Percentual de espaço em disco utilizado dedicado ao cache quente no cluster. 100% significa que o espaço em disco atribuído aos dados de acesso frequente é utilizado de maneira ideal. Nenhuma ação é necessária, e o cluster está totalmente adequado. Menos de 100% significa que o espaço em disco atribuído aos dados de acesso frequente não é totalmente utilizado. Mais de 100% significa que o espaço em disco do cluster não é grande o suficiente para acomodar os dados de acesso frequente, conforme definido pelas políticas de cache. Para garantir que o espaço suficiente esteja disponível para todos os dados ativos, o volume de dados de acesso frequente precisa ser reduzido ou o cluster precisa ser escalado horizontalmente. Recomendamos habilitar a escala automática. |
Nenhum |
| CPU | Percentual | Avg, Max, Min | Percentual de recursos de computação alocados atualmente em uso por computadores no cluster. Uma CPU média de 80% ou menos é sustentável para um cluster. O valor máximo da CPU é 100%, o que significa que não há recursos de computação adicionais para processar dados. Quando um cluster não estiver com um bom desempenho, verifique o valor máximo da CPU para determinar se há CPUs específicas bloqueadas. |
Nenhum |
| Utilização da ingestão | Percentual | Avg, Max, Min | Percentual de recursos reais usados para ingerir dados do total de recursos alocados, na política de capacidade, para executar a ingestão. A política de capacidade padrão não tem mais de 512 operações simultâneas de ingestão ou 75% dos recursos de cluster investidos na ingestão. A utilização média de ingestão de até 80% é um estado sustentável para um cluster. O valor máximo de utilização de ingestão é 100%, o que significa que toda a capacidade de ingestão de clusters, podendo resultar em uma fila de ingestão. |
Nenhum |
| InstanceCount | Count | Avg | Contagem total de instâncias. | |
| Keep alive | Count | Avg | Acompanha a rapidez de resposta do cluster. Um cluster totalmente responsivo retorna o valor 1 e um cluster bloqueado ou desconectado retorna 0. |
|
| Número total de comandos limitados | Count | Avg, Max, Min, Sum | O número de comandos restritos (rejeitados) no cluster, pois o número máximo permitido de comandos simultâneos (paralelos) foi atingido. | Nenhum |
| Número total de extensões | Count | Avg, Max, Min, Sum | Número total de extensões de dados no cluster. As alterações nessa métrica podem implicar grandes alterações na estrutura de dados e alta carga no cluster, uma vez que a mesclagem de extensões de dados é uma atividade que exige muito da CPU. |
Nenhum |
| Latência do seguidor | Milissegundos | Avg, Max, Min | O banco de dados de seguidores sincroniza as alterações nos bancos de dados de líderes. Devido à sincronização, há um atraso de dados de alguns segundos a alguns minutos na disponibilidade dos dados. Essa métrica mede o comprimento do atraso de tempo. O atraso de tempo depende de vários fatores como: o tamanho geral e a taxa dos dados ingeridos para o líder, o número de bancos de dados seguidos, a taxa de operações internas executadas no líder (operações de mesclagem/recompilação). Essa é uma métrica de nível de cluster: os seguidores capturam metadados de todos os bancos de dados seguidos. Essa métrica representa a latência do processo. |
Nenhum |
Exportar métricas
As métricas de exportação controlam a integridade geral e o desempenho de operações de exportação como atraso, resultados, número de registros e utilização.
| Métrica | Unidade | Agregação | Descrição da métrica | Dimensões |
|---|---|---|---|---|
| Número de registros exportados em exportação contínua | Count | Sum | O número de registros exportados em todos os trabalhos de exportação contínua. | ContinuousExportName |
| Atraso máximo de exportação contínua | Count | Max | O atraso (em minutos) relatado pelos trabalhos de exportação contínua no cluster. | Nenhum |
| Contagem de exportação contínua pendente | Count | Max | O número de trabalhos de exportação contínua pendentes. Esses trabalhos estão prontos para serem executados, mas aguardando em uma fila, possivelmente devido à capacidade insuficiente). | |
| Resultado da exportação contínua | Contagem | Count | O resultado de falha/êxito de cada execução de exportação contínua. | ContinuousExportName |
| Utilização da exportação | Percentual | Max | Capacidade de exportação usada, fora da capacidade total de exportação no cluster (entre 0 e 100). | Nenhum |
Métricas de ingestão
As métricas de ingestão controlam a integridade geral e o desempenho das operações de ingestão, como latência, resultados e volume. Para refinar sua análise:
- Aplique filtros a gráficos para plotar dados parciais por dimensões. Por exemplo, explore a ingestão para um
Databaseespecífico. - Aplique a divisão a um gráfico para visualizar dados por componentes diferentes. Esse processo é útil para analisar as métricas que são relatadas por cada etapa do pipeline de ingestão, por exemplo
Blobs received.
| Métrica | Unidade | Agregação | Descrição da métrica | Dimensões |
|---|---|---|---|---|
| Contagem de blob do lote | Count | Avg, Max, Min | Número de fontes de dados em um lote agregado para ingestão. | Backup de banco de dados |
| Duração do lote | Segundos | Avg, Max, Min | A duração da fase de envio em lote no fluxo de ingestão. | Backup de banco de dados |
| Tamanho do lote | Bytes | Avg, Max, Min | Tamanho dos dados não compactados esperados em um lote agregado para ingestão. | Backup de banco de dados |
| Lotes processados | Count | Sum, Max, Min | Número de lotes concluídos para ingestão. Batching Type: o gatilho usado para lacrar um lote. Para obter uma lista completa dos tipos de envio em lote, confira Tipos de envio em lote. |
Banco de dados, tipo de lote |
| Blobs recebidos | Count | Sum, Max, Min | Número de blobs recebidos do fluxo de entrada por um componente. Use aplicar divisão para analisar cada componente. |
Banco de dados, Tipo de componente, nome do componente |
| Blobs processados | Count | Sum, Max, Min | Número de blobs processados por um componente. Use aplicar divisão para analisar cada componente. |
Banco de dados, Tipo de componente, nome do componente |
| Blobs removidos | Count | Sum, Max, Min | Número de blobs removidos permanentemente por um componente. Para cada blob, uma métrica Ingestion result com um motivo de falha é enviada. Use aplicar divisão para analisar cada componente. |
Banco de dados, Tipo de componente, nome do componente |
| Latência de descoberta | Segundos | Avg | Tempo do enfileiramento de dados até a descoberta por conexões de dados. Esse tempo não está incluído na Latência de preparo nem nas métricas de Latência de ingestão. A latência de descoberta pode aumentar nas seguintes situações:
|
Tipo de componente, nome do componente |
| Eventos recebidos | Count | Sum, Max, Min | Número de eventos recebidos por conexões de dados do fluxo de entrada. | Tipo de componente, nome do componente |
| Eventos processados | Count | Sum, Max, Min | Número de eventos processados por conexões de dados. | Tipo de componente, nome do componente |
| Eventos removidos | Count | Sum, Max, Min | Número de eventos removidos permanentemente pelas conexões de dados. Para cada evento, uma Ingestion result métrica com um motivo de falha é enviada. |
Tipo de componente, nome do componente |
| Eventos processados (para Hubs de Eventos/IoT) (preterido) | Count | Max, Min, Sum | Número total de eventos lidos do Hub de Eventos/Hub IoT e processados pelo cluster. Esses eventos podem ser divididos pelo status: Recebido, Rejeitado, Processado. Essa métrica foi preterida e é apresentada somente para compatibilidade com versões anteriores. Em vez disso, use as métricas 'Eventos recebidos', 'Eventos processados' e 'Eventos descartados'. |
Status |
| Latência de ingestão | Segundos | Avg, Max, Min | Latência de dados ingeridos, desde o momento em que os dados foram recebidos no cluster até que eles estejam prontos para consulta. O período de latência de ingestão depende do cenário de ingestão.Ingestion Kind: Ingestão de streaming ou ingestão em fila |
Tipo de Ingestão |
| Resultados da ingestão | Count | Sum | Número total de fontes que falharam ou com êxito para serem ingeridas.Status: Êxito para ingestão bem-sucedida ou a categoria de falha para falhas. Para ver uma lista completa das possíveis categorias de falha, consulte Códigos de erro de ingestão Azure Data Explorer. Failure Status Type: se a falha é permanente ou transitória. Para ingestão bem-sucedida, essa dimensão é None.Observação:
|
Status, Tipo de Status de Falha |
| Volume de ingestão (em bytes) | Count | Max, Sum | O tamanho total dos dados ingeridos para o cluster (em bytes) antes da compactação. | Backup de banco de dados |
| Tamanho da fila | Count | Avg | Número de mensagens pendentes na fila de entrada de um componente. O componente do gerenciador de lote tem uma mensagem por blob. O componente do gerenciador de ingestão tem uma mensagem por lote. Um lote é um único comando de ingestão com um ou mais blobs. | Tipo de componente |
| Mensagem mais antiga da fila | Segundos | Avg | Tempo em segundos a partir do momento da inserção da mensagem mais antiga na fila de entrada de um componente. | Tipo de componente |
| Tamanho dos dados recebidos em bytes | Bytes | Avg, Sum | Tamanho dos dados recebidos por conexões de dados do fluxo de entrada. | Tipo de componente, nome do componente |
| Latência de preparo | Segundos | Avg | Hora de quando uma mensagem é aceita pelo Azure Data Explorer, até que seu conteúdo seja recebido por um componente de ingestão para processamento. Use aplicar filtros e selecione Tipo de componente > StorageEngine para mostrar a latência total de ingestão. |
Banco de dados, Tipo de componente |
Métricas da ingestão de streaming
As métricas de ingestão de streaming acompanham os dados de ingestão de streaming e a taxa de solicitação, a duração e os resultados.
| Métrica | Unidade | Agregação | Descrição da métrica | Dimensões |
|---|---|---|---|---|
| Taxa de Dados de Ingestão de Streaming | Count | RateRequestsPerSecond | O volume total de dados ingeridos para o cluster. | Nenhum |
| Duração da Ingestão de Streaming | Milissegundos | Avg, Max, Min | Duração total de todas as solicitações de ingestão de streaming. | Nenhum |
| Taxa de Solicitação de Ingestão de Streaming | Count | Count, Avg, Max, Min, Sum | Número total de solicitações de ingestão de streaming. | Nenhum |
| Resultado da Ingestão de Streaming | Count | Avg | Número total de solicitações de ingestão de streaming por tipo de resultado. | Resultado |
Métricas de consulta
As métricas de desempenho de consulta acompanham a duração da consulta e o número total de consultas simultâneas ou limitadas.
| Métrica | Unidade | Agregação | Descrição da métrica | Dimensões |
|---|---|---|---|---|
| Duração da consulta | Milissegundos | Avg, Min, Max, Sum | Tempo total até que os resultados da consulta sejam recebidos (não inclui latência de rede). | QueryStatus |
| QueryResult | Contagem | Contagem | Número total de consultas. | QueryStatus |
| Número total de consultas simultâneas | Count | Avg, Max, Min, Sum | O número de consultas são executados em paralelo no cluster. Essa métrica é uma boa maneira de estimar a carga no cluster. | Nenhum |
| Número total de consultas limitadas | Count | Avg, Max, Min, Sum | O número de consultas limitadas (rejeitadas) no cluster. O número máximo de consultas simultâneas (paralelas) permitidas é definido na política de limite de taxa de solicitação. | Nenhum |
Métricas de exibição materializada
| Métrica | Unidade | Agregação | Descrição da métrica | Dimensões |
|---|---|---|---|---|
| MaterializedViewHealth | 1, 0 | Avg | O valor será 1 se a exibição for considerada íntegra, caso contrário, 0. | Banco de Dados, MaterializedViewName |
| MaterializedViewAgeSeconds | Segundos | Avg | O age da exibição é definido pela hora atual menos o último tempo de ingestão processado pela exibição. O valor da métrica é tempo em segundos (quanto menor for o valor, a exibição será "mais íntegra"). |
Banco de Dados, MaterializedViewName |
| MaterializedViewResult | 1 | Avg | A métrica inclui uma dimensão que indica o resultado do último ciclo de materialização (consulte a métrica ResultMaterializedViewResult para obter detalhes sobre os valores possíveis). O valor da métrica sempre é igual a 1. |
Banco de Dados, MaterializedViewName, Resultado |
| MaterializedViewRecordsInDelta | Contagem de registros | Avg | O número de registros atualmente na parte não processada da tabela de origem. Para obter mais informações, consulte Padrão de exibição materializada | Banco de Dados, MaterializedViewName |
| MaterializedViewExtentsRebuild | Contagem de extensões | Avg | O número de extensões que exigiram atualizações no ciclo de materialização. | Banco de Dados, MaterializedViewName |
| MaterializedViewDataLoss | 1 | Max | A métrica é acionada quando os dados de origem não processadas estão se aproximando da retenção. Indica que a exibição materializada não é não íntegra. | Banco de Dados, MaterializedViewName, Tipo |
Conteúdo relacionado
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de