Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma avaliação gratuita!
Os fluxos de dados estão disponíveis nos pipelines do Azure Data Factory e do Azure Synapse. Este artigo se aplica ao fluxo de dados de mapeamento. Se você for iniciante nas transformações, veja o artigo introdutório Transformar dados usando um fluxo de dados de mapeamento.
A transformação de divisão condicional roteia as linhas de dados para diferentes fluxos com base em condições de correspondência. A transformação de divisão condicional é semelhante a uma estrutura de decisão CASE em uma linguagem de programação. A transformação avalia expressões, e com base nos resultados, direciona a linha de dados para o fluxo especificado.
Configuração
A configuração Dividir determina se a linha de dados flui para o primeiro fluxo de correspondência ou para cada fluxo ao qual ela corresponde.
Use o construtor de expressões de fluxo de dados para inserir uma expressão para a condição de divisão. Para adicionar uma nova condição, clique no ícone de adição em uma linha existente. Um fluxo padrão também pode ser adicionado para linhas que não correspondem a nenhuma condição.
Script de fluxo de dados
Sintaxe
<incomingStream>
split(
<conditionalExpression1>
<conditionalExpression2>
...
disjoint: {true | false}
) ~> <splitTx>@(stream1, stream2, ..., <defaultStream>)
Exemplo
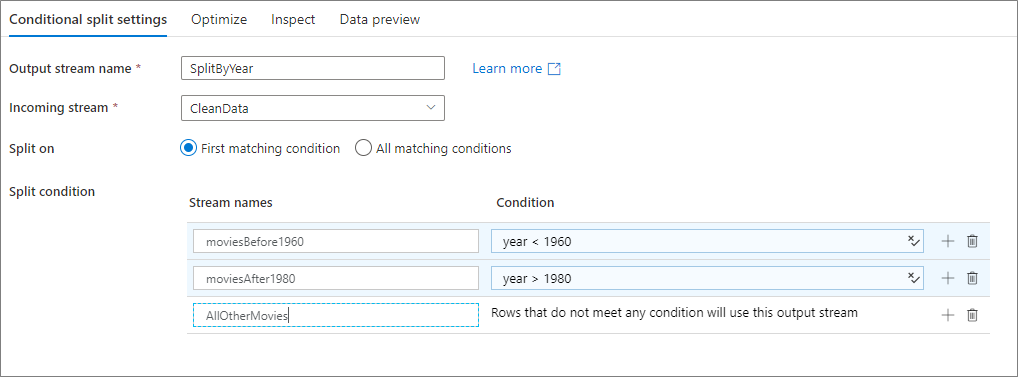
O exemplo abaixo é uma transformação de divisão condicional chamada SplitByYear que usa o fluxo de entrada CleanData. Essa transformação tem duas condições de divisão: year < 1960 e year > 1980. disjoint é False porque os dados vão para a primeira condição de correspondência em vez de todas as condições de correspondência. Cada linha que corresponde à primeira condição vai para o fluxo de saída moviesBefore1960. Todas as linhas restantes que correspondem à segunda condição vão para o fluxo de saída moviesAFter1980. Todas as outras linhas fluem por meio do fluxo padrão AllOtherMovies.
Na UI do serviço, essa transformação é semelhante à imagem abaixo:
O script de fluxo de dados para essa transformação está no trecho de código abaixo:
CleanData
split(
year < 1960,
year > 1980,
disjoint: false
) ~> SplitByYear@(moviesBefore1960, moviesAfter1980, AllOtherMovies)
Conteúdo relacionado
As transformações de fluxo de dados comuns usadas com divisão condicional são as transformação de junção, a transformação de pesquisa e a transformação de seleção