Copiar dados do Azure Data Lake Storage Gen1 para Gen2 com o Azure Data Factory
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma avaliação gratuita!
O Azure Data Lake Storage Gen2 é um conjunto de recursos dedicados à análise de Big Data que está integrado ao Armazenamento de blobs do Azure. Você pode usá-lo para fazer interface com seus dados usando os paradigmas de sistema de arquivos e armazenamento de objetos.
Se você estiver usando o Azure Data Lake Storage Gen1, avalie a nova funcionalidade do Azure Data Lake Storage Gen2 copiando dados do Data Lake Storage Gen1 para o Gen2 por meio do Azure Data Factory.
O Azure Data Factory é um serviço de integração de dados baseado em nuvem completamente gerenciado. Ele pode ser usado para popular o data lake com dados de um conjunto avançado de armazenamentos de dados locais e baseados em nuvem e economizar tempo durante a criação das soluções de análise. Para obter uma lista de conectores compatíveis, consulte a tabela Armazenamentos de dados com suporte.
O Azure Data Factory oferece uma solução de movimentação de dados gerenciados de expansão. Graças à arquitetura de expansão do Data Factory, é possível ingerir dados com alta taxa de transferência. Para obter mais informações, confira o Desempenho da atividade Copy.
Este artigo mostra como usar a ferramenta de cópia de dados do Data Factory para copiar dados do Azure Data Lake Storage Gen1 para o Azure Data Lake Storage Gen2. Você pode seguir as etapas semelhantes para copiar dados de outros tipos de armazenamentos de dados.
Pré-requisitos
- Uma assinatura do Azure. Se você não tiver uma assinatura do Azure, crie uma conta gratuita antes de começar.
- Conta do Azure Data Lake Store Gen1 contendo dados.
- Conta de Armazenamento do Azure com o Data Lake Storage Gen2 habilitado. Se você ainda não tem conta de armazenamento, crie uma.
Criar uma data factory
Se você ainda não criou o data factory, siga as etapas no Início Rápido: crie um data factory usando o portal do Azure e o Estúdio do Azure Data Factory para criar um. Depois de criá-lo, navegue até o data factory no portal do Azure.
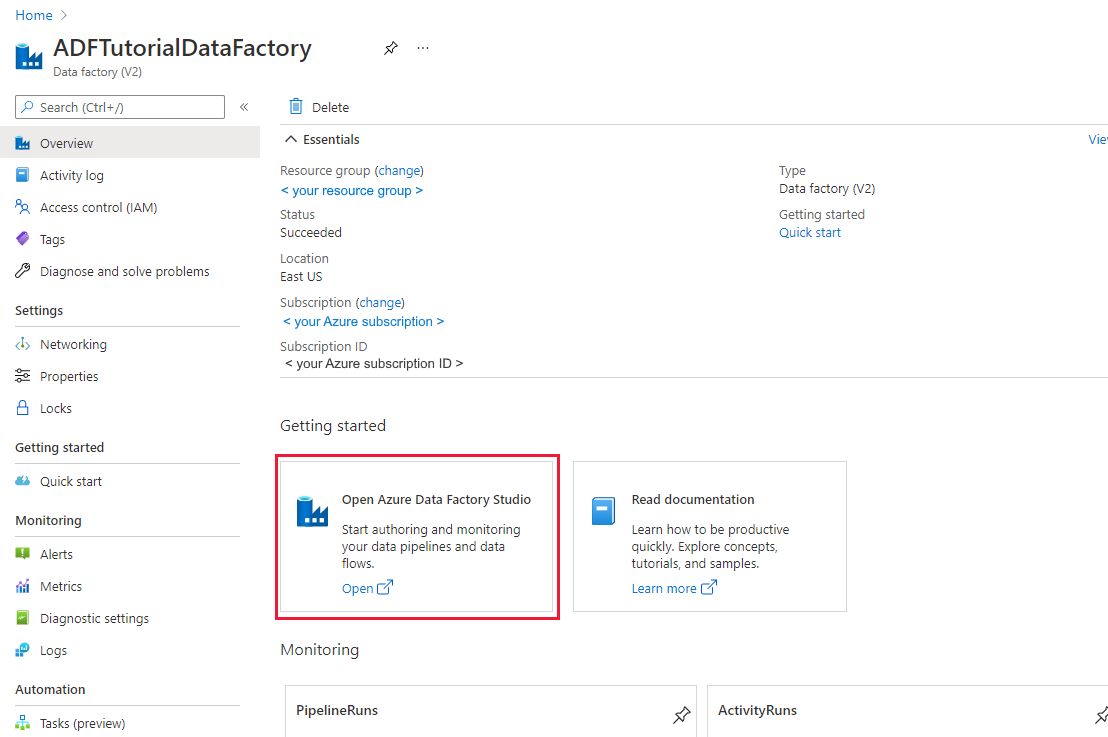
Selecione Abrir no bloco Abrir Estúdio do Azure Data Factory para iniciar o aplicativo Data Integration em uma guia separada.
Carregar dados no Azure Data Lake Store Gen2
Na página inicial, selecione o bloco Ingerir para a inicialização da ferramenta de cópia de dados.
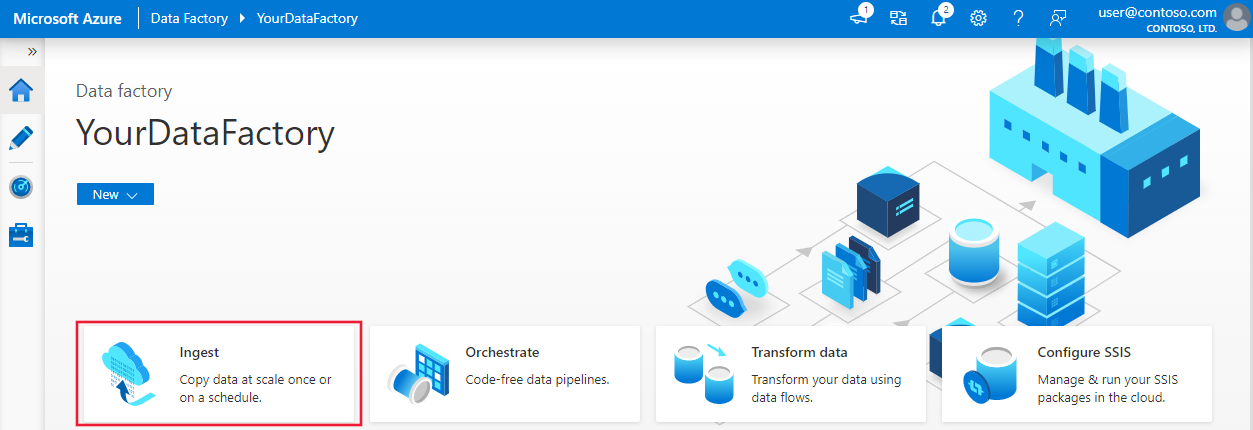
Na página Propriedades, escolha Tarefa de cópia interna em Tipo de tarefa e Executar uma vez agora em Cadência ou agendamento da tarefa e selecione Avançar.
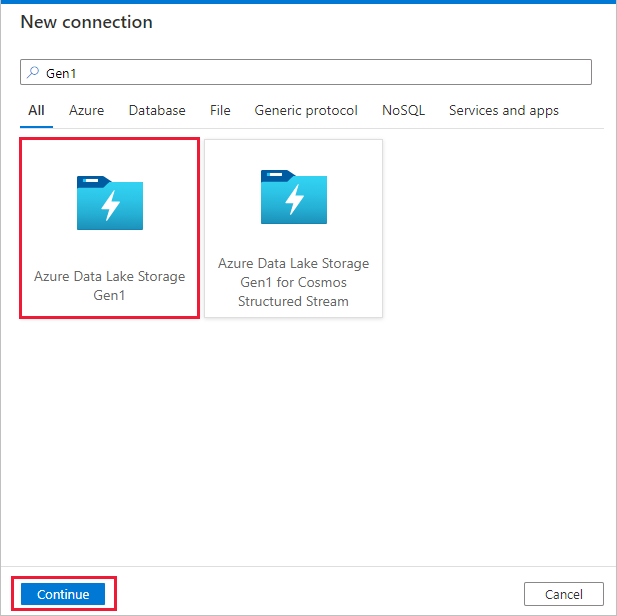
Na página Armazenamento de dados de origem, selecione + Nova conexão.
Selecione Azure Data Lake Storage Gen1 na galeria de conectores e clique em Continuar.
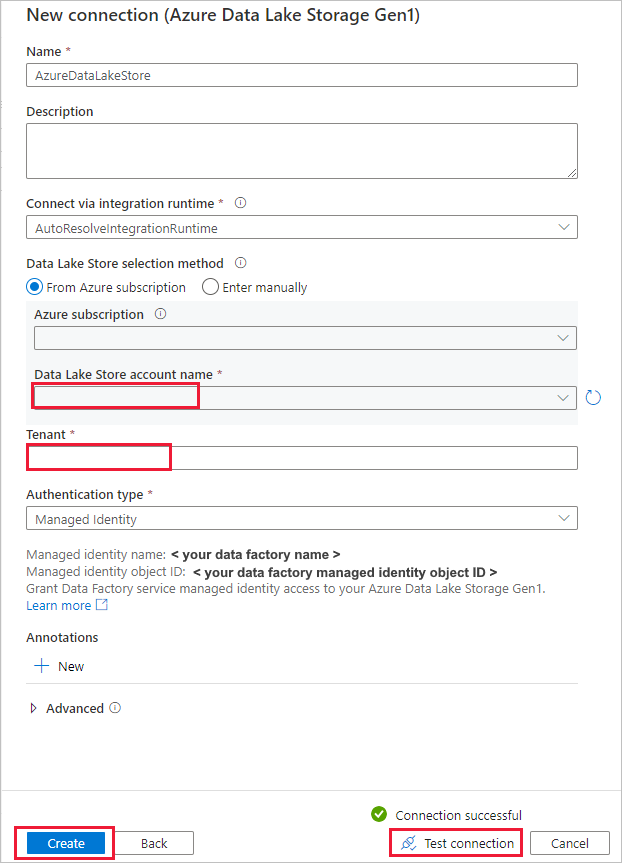
Na página Nova conexão (Azure Data Lake Storage Gen1) , siga estas etapas:
- Selecione o Data Lake Storage Gen1 para o nome da conta e especifique ou valide o Locatário.
- Selecione Testar conectividade para validar as configurações. Em seguida, selecione Criar.
Importante
Neste passo a passo, você deve usar uma identidade gerenciada para recursos do Azure para autenticar o Azure Data Lake Storage Gen1. Para conceder à identidade gerenciada as permissões corretas no Azure Data Lake Storage Gen1, siga estas instruções.
Na página Armazenamento de dados de origem, siga estas etapas:
- Selecione a conexão criada recentemente na seção Conexão.
- Em Pasta ou arquivo, navegue até a pasta e o arquivo que receberá a cópia. Selecione a pasta ou o arquivo e clique em OK.
- Especifique o comportamento de cópia marcando as opções Recursivamente e Cópia binária. Selecione Avançar.
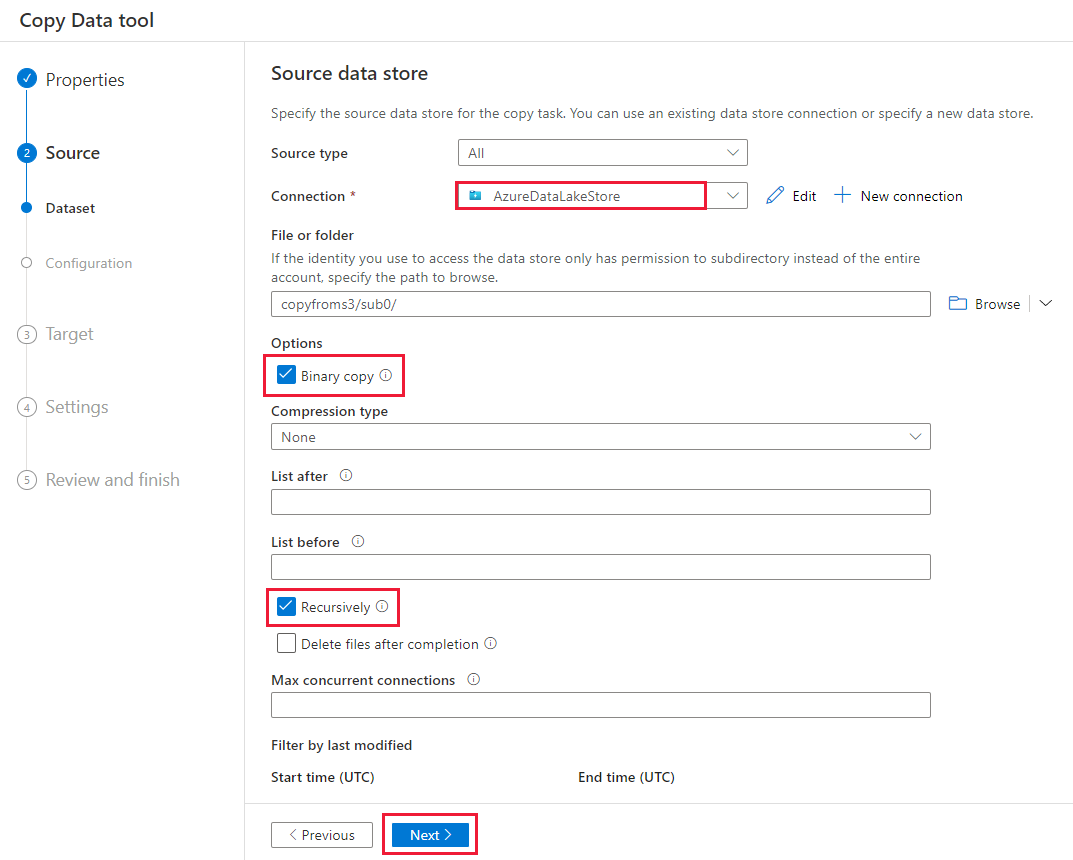
Na página Armazenamento de dados de destino, selecione + Nova conexão>Azure Data Lake Storage Gen2>Continuar.
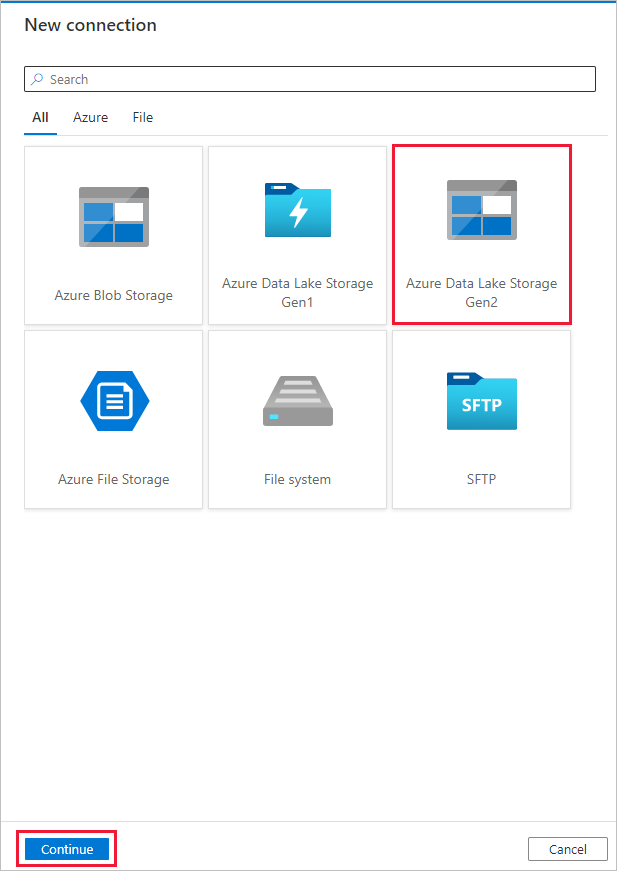
Na página Nova conexão (Azure Data Lake Storage Gen2) , siga estas etapas:
- Selecione a conta compatível do Data Lake Storage Gen2 na lista suspensa Nome da conta de armazenamento.
- Selecione Criar para criar a conexão.
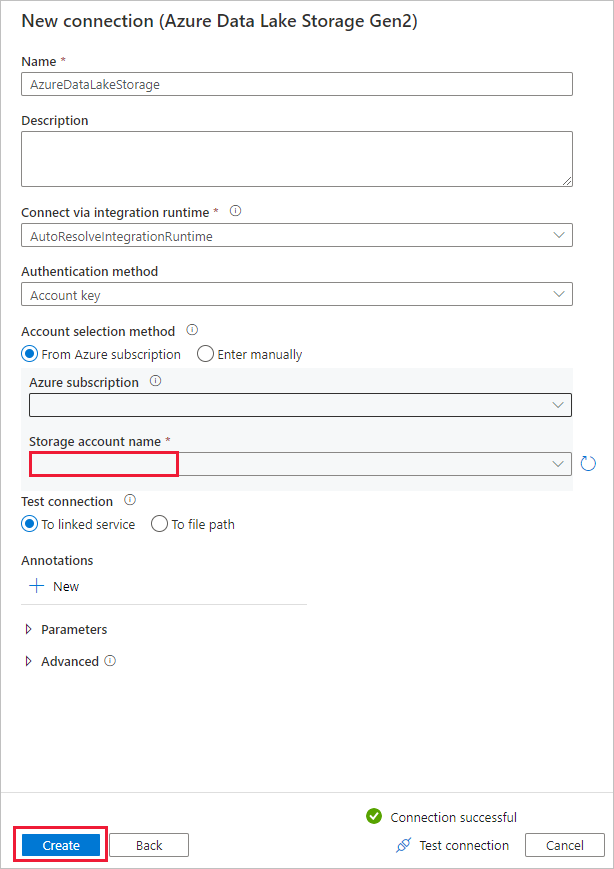
Na página Armazenamento de dados de destino, siga estas etapas:
- Selecione a conexão criada recentemente no bloco de Conexão.
- Em Caminho da pasta, insira copyfromadlsgen1 como o nome da pasta de saída e selecione Avançar. O Data Factory criará as subpastas e o sistema de arquivos do Azure Data Lake Storage Gen2 correspondentes durante a cópia, caso eles não existam.
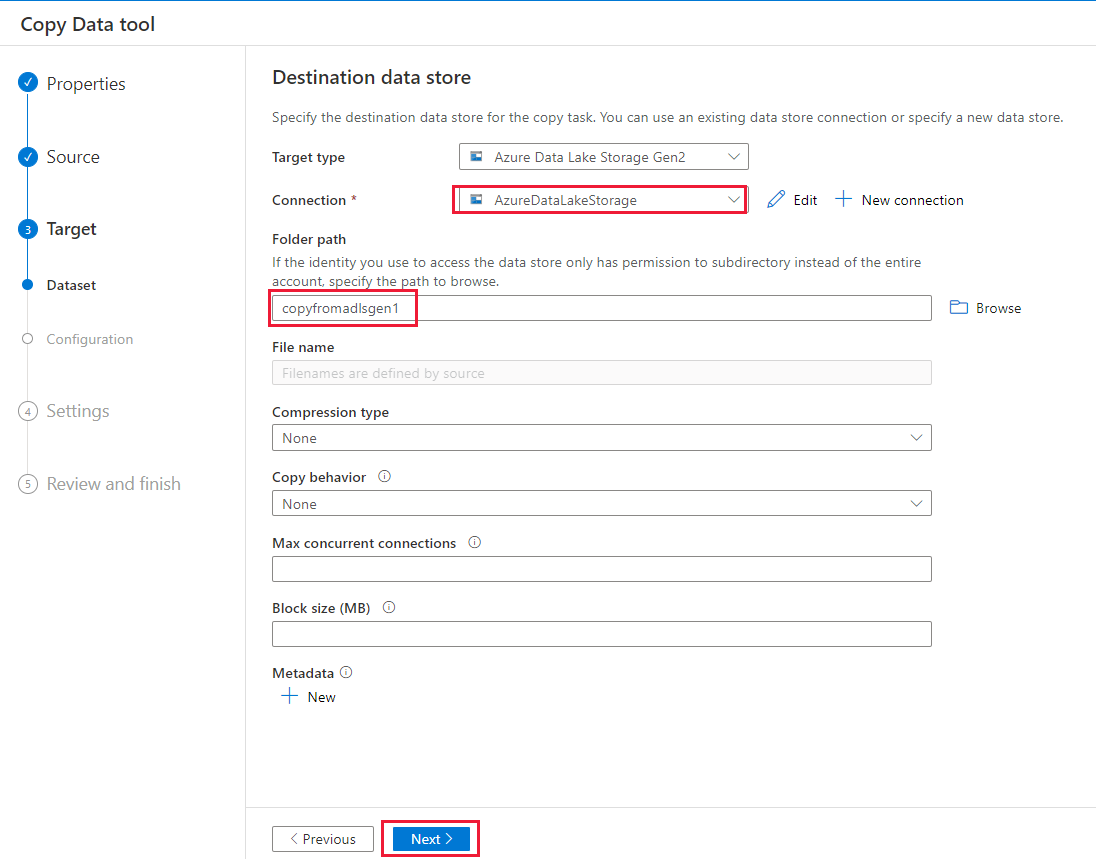
Na página Configurações, especifique CopyFromADLSGen1ToGen2 para o campo Nome da tarefa e selecione Próximo para usar as configurações padrão.
Na página Resumo, analise as configurações e selecione Avançar.
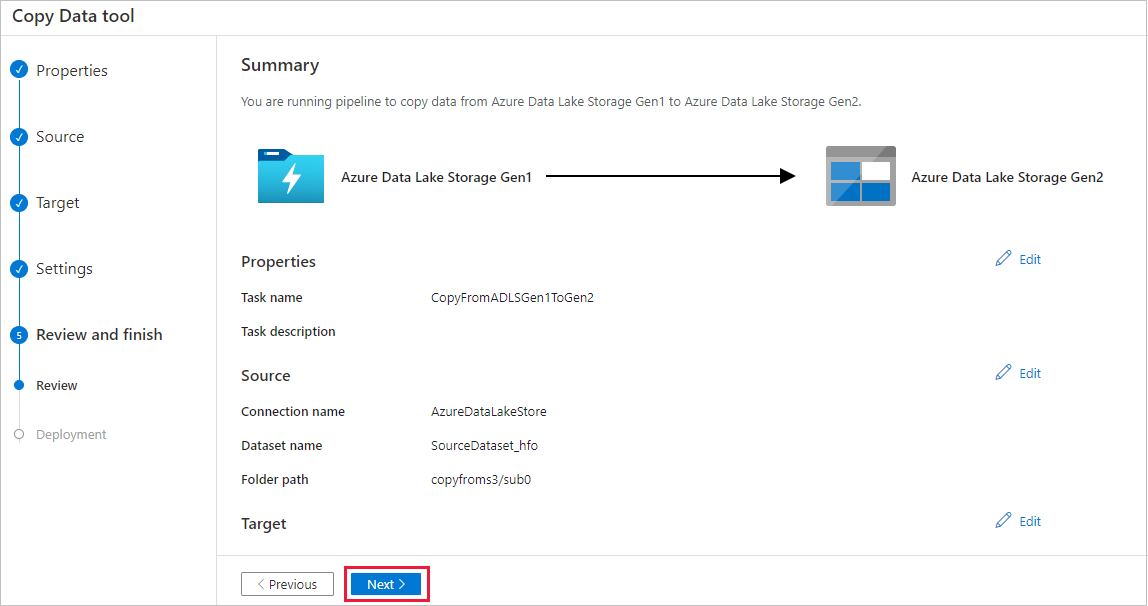
Na página Implantação, selecione Monitorar para monitorar o pipeline.
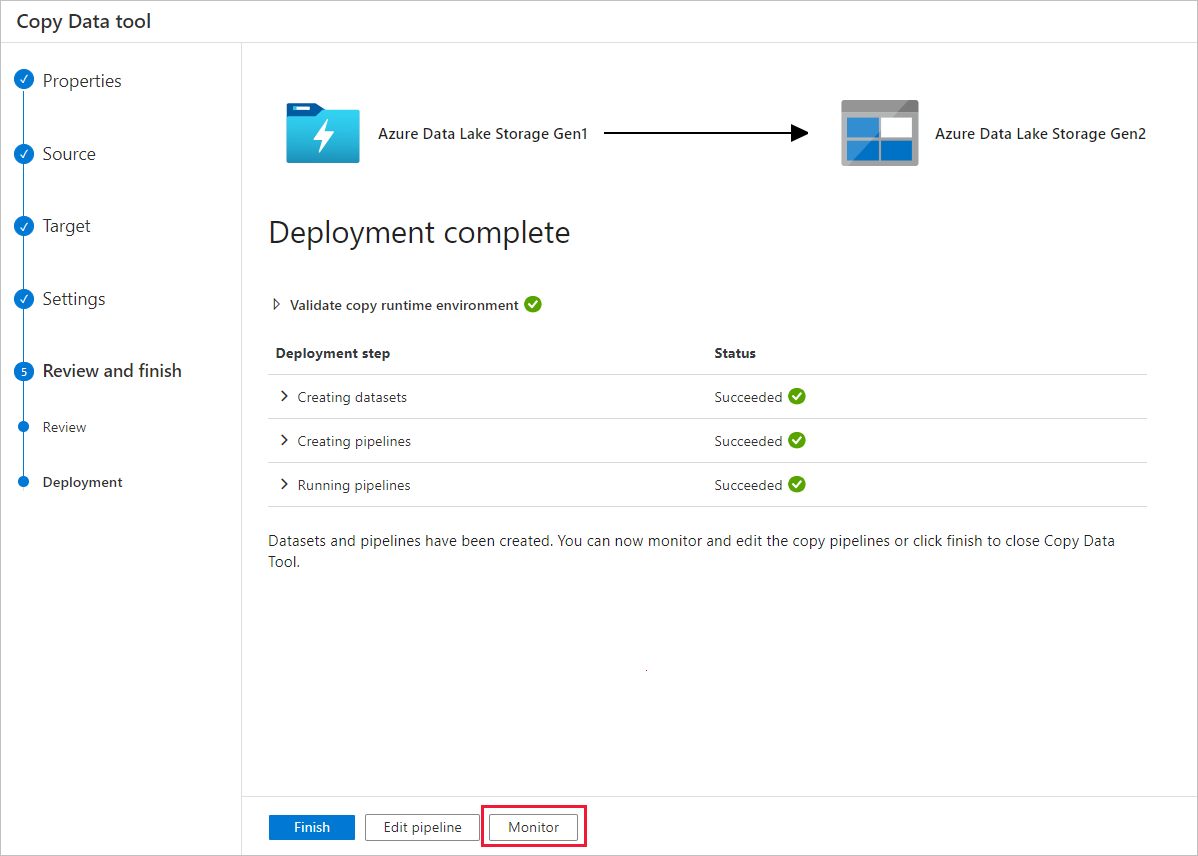
Observe que a guia Monitor à esquerda é selecionada automaticamente. A coluna Nome do pipeline inclui links para ver os detalhes da execução de atividade e executar o pipeline novamente.
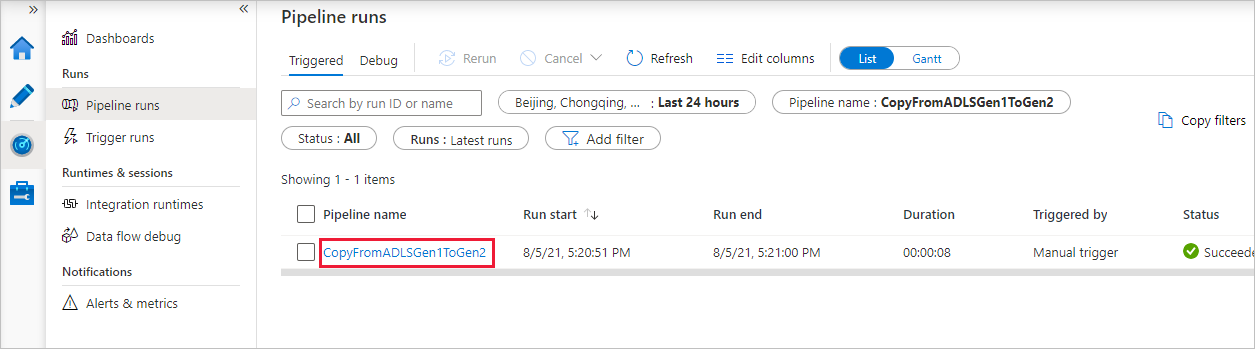
Para ver as execuções de atividade associadas à execução de pipeline, selecione o link na coluna Nome do pipeline. Há apenas uma atividade (atividade de cópia) no pipeline. Assim, você vê apenas uma entrada. Para voltar à visualização de execuções de pipeline, selecione o link Todas as execuções do pipeline no menu de trilha na parte superior. Selecione Atualizar para atualizar a lista.
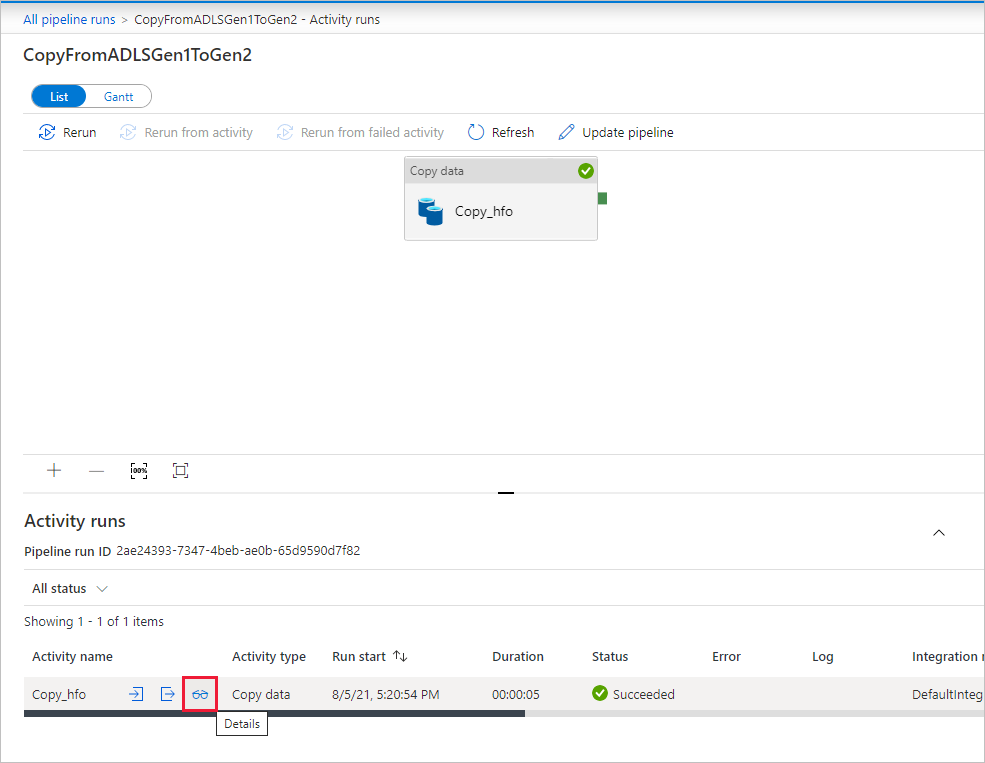
Para monitorar os detalhes de execução de cada atividade de cópia, selecione o link Detalhes (imagem de óculos) em Nome da atividade na visualização de monitoramento de atividade. Você pode monitorar detalhes como o volume de dados copiados da fonte para o coletor, taxa de transferência de dados, etapas de execução com duração correspondente e configurações usadas.
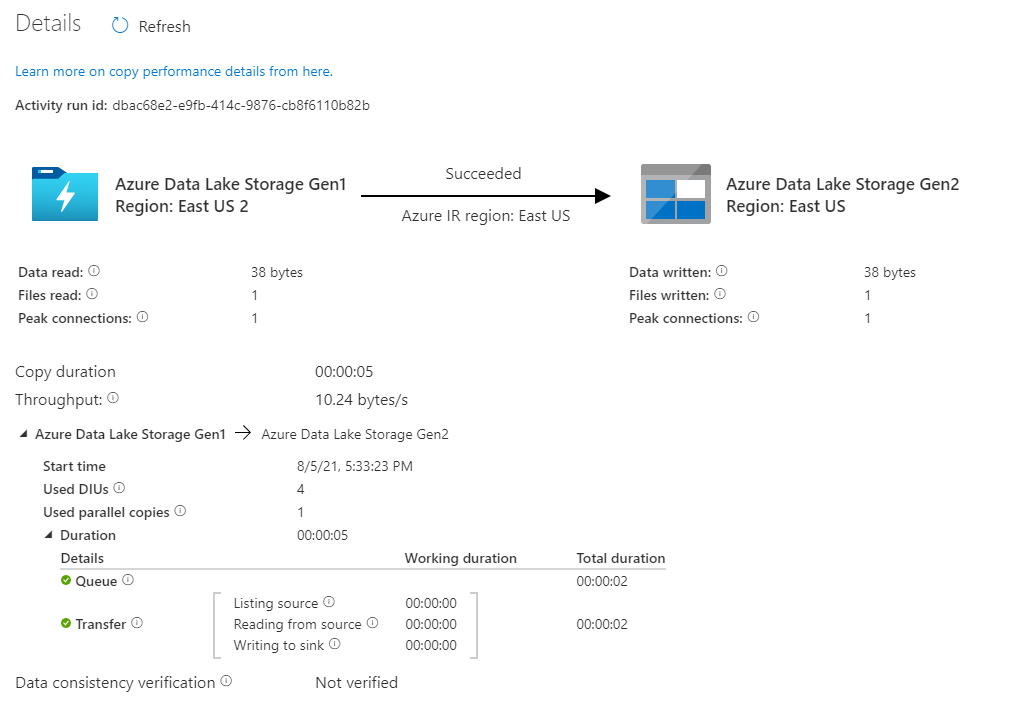
Verifique se os dados serão copiados para a conta do Azure Data Lake Storage Gen2.
Práticas recomendadas
Para avaliar a atualização do Azure Data Lake Storage Gen1 para o Azure Data Lake Storage Gen2 em geral, confira Atualizar soluções de análise de Big data do Azure Data Lake Storage Gen1 para o Azure Data Lake Storage Gen2. As seções a seguir apresentam práticas recomendadas para usar o Data Factory em uma atualização de dados do Data Lake Storage Gen1 para o Data Lake Storage Gen2.
Migração de dados de instantâneo inicial
Desempenho
O ADF oferece uma arquitetura sem servidor que permite o paralelismo em diferentes níveis, possibilitando aos desenvolvedores criar pipelines para utilizar totalmente a largura de banda da rede, bem como a IOPS de armazenamento e a largura de banda para maximizar a taxa de transferência da movimentação de dados para o seu ambiente.
Os clientes migraram petabytes de dados com êxito que consistiam em centenas de milhões de arquivos do Data Lake Storage Gen1 a Gen2, com uma taxa de transferência sustentada de 2 GBps e superior.
É possível obter maiores velocidades de movimentação de dados aplicando diferentes níveis de paralelismo:
- Uma só atividade de cópia pode aproveitar os recursos de computação escalonáveis: ao usar o Azure Integration Runtime, você pode especificar até 256 unidades de integração de dados (DIUs) para cada atividade de cópia por meio da computação sem servidor; ao usar o runtime de integração auto-hospedada, você pode escalar verticalmente o computador no modo manual ou escalá-lo horizontalmente para vários computadores (até quatro nós) e uma só atividade de cópia fará a partição do conjunto de arquivos em todos os nós.
- Uma só atividade de cópia faz leituras e gravações no armazenamento de dados usando vários threads.
- O fluxo de controle do ADF pode iniciar várias atividades de cópia em paralelo, por exemplo, usando o loop For Each.
Partições de dados
Se o tamanho total dos dados no Data Lake Storage Gen1 for menor que 10 TB e o número de arquivos for menor que 1 milhão, você poderá copiar todos os dados em uma única execução da atividade de cópia. Particione os dados caso você tenha uma quantidade maior de dados para copiar ou queira a flexibilidade de gerenciar a migração de dados em lotes e fazer com que cada um deles seja concluído em um determinado intervalo de tempo. O particionamento também reduz o risco de algum problema inesperado.
A maneira de particionar os arquivos é usar name range- listAfter/listBefore na propriedade de atividade de cópia. Cada atividade de cópia pode ser configurada para copiar uma partição por vez, para que várias atividades de cópia possam copiar dados de uma única conta do Data Lake Storage Gen1 simultaneamente.
Limitação de taxa
Como melhor prática, realize um POC de desempenho com um conjunto de dados de exemplo representativo, para determinar um tamanho de partição apropriado.
Comece com uma só partição e uma só atividade de cópia com a configuração padrão de DIU. Recomenda-se definir sempre a Cópia paralela como vazia (padrão) . Se a taxa de transferência da cópia não for boa o suficiente, identifique e resolva os gargalos de desempenho seguindo as Etapas de ajuste de desempenho.
Aumente gradualmente a configuração de DIU até atingir o limite de largura de banda da sua rede ou o limite de IOPS/largura de banda dos armazenamentos de dados ou se você tiver atingido o máximo de 256 DIU permitido em uma só atividade de cópia.
Se você maximizou o desempenho de uma única atividade de cópia, mas ainda não atingiu os limites superiores de taxa de transferência do ambiente, execute várias atividades de cópia em paralelo.
Quando você observar um número significativo de erros de limitação no monitoramento de atividade de cópia, você terá atingido o limite de capacidade da conta de armazenamento. O ADF tentará superar cada erro de limitação automaticamente para garantir que não haja perda de dados, mas muitas tentativas também podem prejudicar a taxa de transferência da cópia. Nesse caso, recomenda-se reduzir o número de atividades de cópia em execução simultaneamente para evitar uma quantidade significativa de erros de limitação. Se você tem usado a atividade de cópia única para copiar dados, é recomendado reduzir as DIUs.
Migração de dados delta
Você pode usar várias abordagens para carregar somente arquivos novos ou atualizados do Data Lake Storage Gen1:
- Carregue arquivos novos ou atualizados por tempo, pasta particionada ou nome de arquivo. Um exemplo é /2019/05/13/*.
- Carregue arquivos novos ou atualizados por LastModifiedDate. Se você estiver copiando grandes quantidades de arquivos, faça as partições primeiro para evitar o resultado de baixa taxa de transferência da atividade de cópia única, verificando toda a conta do Data Lake Storage Gen1 para identificar novos arquivos.
- Identifique arquivos novos ou atualizados por qualquer ferramenta ou solução de terceiros. Em seguida, transmita o nome do arquivo ou da pasta ao pipeline do Data Factory por meio de parâmetro, tabela ou arquivo.
A frequência correta para fazer carga incremental depende do total de arquivos no Azure Data Lake Storage Gen1 e do volume de arquivos novos ou atualizados a serem carregados a cada vez.
Segurança de rede
Por padrão, o ADF transfere dados do Azure Data Lake Storage Gen1 para o Gen2 usando a conexão criptografada via protocolo HTTPS. O HTTPS fornece a criptografia de dados em trânsito e impede ataques de interceptação e man-in-the-middle.
Como alternativa, se você não quiser que os dados sejam transferidos pela Internet pública, obtenha maior segurança transferindo os dados a través de uma rede particular.
Preservar ACLs
Se você quiser replicar as ACLs junto com arquivos de dados ao atualizar do Data Lake Storage Gen1 para o Data Lake Storage Gen2, confira Preservar ACLs do Data Lake Storage Gen1.
Resiliência
Em uma só execução de atividade de cópia, o ADF tem um mecanismo de repetição interno para lidar com um certo nível de falhas transitórias nos armazenamentos de dados ou na rede subjacente. Se você migrar mais de 10 TB de dados, será recomendável particionar os dados para reduzir o risco de problemas inesperados.
Você também pode habilitar a tolerância a falhas na atividade de cópia para ignorar erros predefinidos. A verificação adicional da consistência dos dados pode também ser habilitada a fim de garantir que os dados sejam copiados com êxito do repositório de origem para o de destino e também que seja verificada a consistência deles entre os repositórios de origem e de destino.
Permissões
No Data Factory, o conector do Data Lake Storage Gen1 dá suporte a entidade de serviço e identidade gerenciada para autenticações de recursos do Azure. O conector do Data Lake Storage Gen2 dá suporte a chave de conta, entidade de serviço e identidade gerenciada para autenticações de recursos do Azure. Para tornar o Data Factory capaz de navegar e copiar todos os arquivos ou ACLs (listas de controle de acesso), é necessário conceder permissões altas o suficiente à conta para acessar, ler ou gravar todos os arquivos e definir ACLs, se desejado. É necessário conceder à conta uma função de superusuário ou proprietário durante o período de migração e remover as permissões elevadas assim que a migração for concluída.