Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Data Factory no Microsoft Fabric é a próxima geração de Azure Data Factory, com uma arquitetura mais simples, IA interna e novos recursos. Se você não estiver familiarizado com a integração de dados, comece com Fabric Data Factory. As cargas de trabalho existentes do ADF podem ser atualizadas para Fabric para acessar novos recursos em ciência de dados, análise em tempo real e relatórios.
Neste tutorial, você cria um Azure Data Factory com um pipeline que carrega dados delta com base em informações de controle de alterações no banco de dados de origem no Banco de Dados SQL do Azure para um Armazenamento de Blobs do Azure.
Neste tutorial, você realizará os seguintes procedimentos:
- Prepare o armazenamento de dados de origem
- Criar uma fábrica de dados.
- Criar serviços vinculados.
- Crie conjuntos de dados de origem, destino e rastreamento de mudanças.
- Criar, executar e monitorar o pipeline de cópia completo
- Adicionar ou atualizar dados nas tabelas de origem
- Criar, executar e monitorar o fluxo de cópia incremental
Observação
Recomendamos que você use o módulo Azure Az PowerShell para interagir com Azure. Para começar, consulte Instalar Azure PowerShell. Para saber como migrar para o módulo do Az PowerShell, consulte Migrate Azure PowerShell do AzureRM para o Az.
Visão geral
Em uma solução de integração de dados, o carregamento incremental de dados depois de uma carga de dados inicial é um cenário amplamente usado. Em alguns casos, os dados alterados dentro de um período em seu armazenamento de dados de origem podem ser facilmente divididos (por exemplo, LastModifyTime, CreationTime). Em alguns casos, não há uma forma explícita de identificar os dados delta da última vez que você processou os dados. A tecnologia de Controle de Alterações com suporte dos repositórios de dados, como o Banco de Dados SQL do Azure e SQL Server, pode ser usada para identificar os dados delta. Este tutorial descreve como usar Azure Data Factory com a tecnologia de Controle de Alterações do SQL para carregar incrementalmente dados delta de Azure SQL Database em Azure Blob Storage. Para obter informações mais concretas sobre a tecnologia de Controle de Alterações do SQL, consulte Controle de Alterações no SQL Server.
Fluxo de trabalho de ponta a ponta
Estas são as etapas normais de fluxo de trabalho de ponta a ponta para carregar incrementalmente os dados usando a tecnologia de Controle de Alterações.
Observação
Tanto Azure SQL Database quanto SQL Server dão suporte à tecnologia de Controle de Alterações. Este tutorial usa Azure SQL Database como o armazenamento de dados de origem. Você também pode usar uma instância de SQL Server.
-
Carregamento inicial de dados históricos (execução única):
- Habilite a tecnologia controle de alterações no banco de dados de origem no Azure SQL Database.
- Obtenha o valor inicial de SYS_CHANGE_VERSION no banco de dados como a linha de base para capturar os dados alterados.
- Carregue dados completos do banco de dados de origem em um armazenamento de blobs Azure.
-
Carregamento incremental de dados delta em uma agenda (executar periodicamente após o carregamento inicial de dados):
- Obtenha os valores de SYS_CHANGE_VERSION antigos e novos.
- Carregue os dados delta unindo as chaves primárias de linhas alteradas (entre dois valores SYS_CHANGE_VERSION) de sys.change_tracking_tables com os dados na tabela de origem e, em seguida, mova os dados delta para destino.
- Atualize o SYS_CHANGE_VERSION para o carregamento de delta na próxima vez.
Solução de alto nível
Neste tutorial, você cria dois pipelines que executam as duas operações a seguir:
Initial load: você cria um pipeline com uma atividade de cópia que transfere todos os dados do armazenamento de dados de origem (Azure SQL Database) para o armazenamento de dados de destino (Azure Blob Storage).

Carga incremental: crie um pipeline com as seguintes atividades e execute-o periodicamente.
- Crie duas atividades de pesquisa para obter o SYS_CHANGE_VERSION novo e antigo do Banco de Dados SQL do Azure e passe-o para a atividade de cópia.
- Crie uma atividade de cópia para copiar os dados inseridos/atualizados/excluídos entre os dois valores SYS_CHANGE_VERSION do Azure SQL Database para o Azure Blob Storage.
- Crie uma atividade de procedimento armazenado para atualizar o valor de SYS_CHANGE_VERSION para a próxima execução do pipeline.

Se você não tiver uma assinatura Azure, crie uma conta free antes de começar.
Pré-requisitos
- Azure PowerShell. Instale os módulos de Azure PowerShell mais recentes seguindo instruções em Como instalar e configurar Azure PowerShell.
- Azure SQL Database. Você usa o banco de dados como um armazenamento de dados de origem. Se você não tiver um banco de dados no Azure SQL Database, consulte o artigo Criar um banco de dados no Azure SQL Database para ver as etapas para criar um.
- Conta de Armazenamento do Azure. Você usa o Armazenamento de Blobs como um armazenamento de dados de coletor. Se você não tiver uma conta de armazenamento Azure, consulte o artigo Criar uma conta de armazenamento para ver as etapas para criar uma. Crie um contêiner denominado adftutorial.
Criar uma tabela de fonte de dados no banco de dados
Inicie SQL Server Management Studio e conecte-se ao Banco de Dados SQL.
No Gerenciador de Servidores, clique com o botão direito do mouse no banco de dados e escolha Nova Consulta.
Execute o comando SQL a seguir no banco de dados para criar uma tabela chamada
data_source_tablecomo o repositório de fonte de dados.create table data_source_table ( PersonID int NOT NULL, Name varchar(255), Age int PRIMARY KEY (PersonID) ); INSERT INTO data_source_table (PersonID, Name, Age) VALUES (1, 'aaaa', 21), (2, 'bbbb', 24), (3, 'cccc', 20), (4, 'dddd', 26), (5, 'eeee', 22);Habilite o mecanismo de Controle de Alterações em seu banco de dados e na tabela de origem (data_source_table) executando a seguinte consulta SQL:
Observação
- Substitua <seu nome de banco de dados> pelo nome do banco de dados que tenha data_source_table.
- Os dados alterados são mantidos por dois dias no exemplo atual. Se você carregar os dados alterados a cada três dias ou mais, alguns dados alterados não serão incluídos. Você precisa de como alterar o valor de CHANGE_RETENTION para um número maior. Como alternativa, certifique-se de que seu período de carregamento dos dados alterados esteja dentro de dois dias. Para saber mais, consulte Habilitar o controle de alterações de um banco de dados
ALTER DATABASE <your database name> SET CHANGE_TRACKING = ON (CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON) ALTER TABLE data_source_table ENABLE CHANGE_TRACKING WITH (TRACK_COLUMNS_UPDATED = ON)Crie uma nova tabela e armazene o ChangeTracking_version com um valor padrão executando a consulta a seguir:
create table table_store_ChangeTracking_version ( TableName varchar(255), SYS_CHANGE_VERSION BIGINT, ); DECLARE @ChangeTracking_version BIGINT SET @ChangeTracking_version = CHANGE_TRACKING_CURRENT_VERSION(); INSERT INTO table_store_ChangeTracking_version VALUES ('data_source_table', @ChangeTracking_version)Observação
Se os dados não forem alterados após a habilitação do controle de alterações para o Banco de Dados SQL, o valor da versão do controle de alterações será 0.
Execute a consulta a seguir para criar um procedimento armazenado em seu banco de dados. O pipeline chama esse procedimento armazenado para atualizar a versão de rastreio de alterações na tabela criada na etapa anterior.
CREATE PROCEDURE Update_ChangeTracking_Version @CurrentTrackingVersion BIGINT, @TableName varchar(50) AS BEGIN UPDATE table_store_ChangeTracking_version SET [SYS_CHANGE_VERSION] = @CurrentTrackingVersion WHERE [TableName] = @TableName END
Azure PowerShell
Instale os módulos de Azure PowerShell mais recentes seguindo instruções em Como instalar e configurar Azure PowerShell.
Criar uma fábrica de dados (data factory)
Defina uma variável para o nome do grupo de recursos que você usa nos comandos do PowerShell posteriormente. Copie o texto de comando a seguir para o PowerShell, especifique um nome para o grupo de recursos Azure entre aspas duplas e execute o comando. Por exemplo:
"adfrg".$resourceGroupName = "ADFTutorialResourceGroup";Se o grupo de recursos já existir, não convém substituí-lo. Atribua um valor diferente para a variável
$resourceGroupNamee execute o comando novamenteDefina uma variável para o local do data factory:
$location = "East US"Para criar o grupo de recursos Azure, execute o seguinte comando:
New-AzResourceGroup $resourceGroupName $locationSe o grupo de recursos já existir, não convém substituí-lo. Atribua um valor diferente para a variável
$resourceGroupNamee execute o comando novamente.Defina uma variável para o nome do data factory.
Importante
Atualize o nome do data factory para ser globalmente exclusivo.
$dataFactoryName = "IncCopyChgTrackingDF";Para criar o data factory, execute o seguinte cmdlet Set-AzDataFactoryV2:
Set-AzDataFactoryV2 -ResourceGroupName $resourceGroupName -Location $location -Name $dataFactoryName
Observe os seguintes pontos:
O nome do Azure data factory deve ser globalmente exclusivo. Se você receber o erro a seguir, altere o nome e tente novamente.
The specified Data Factory name 'ADFIncCopyChangeTrackingTestFactory' is already in use. Data Factory names must be globally unique.Para criar instâncias do Data Factory, a conta de usuário usada para fazer logon no Azure deve ser membro das funções contributor, owner ou ser um administrador da assinatura do Azure.
Para obter uma lista de Azure regiões em que o Data Factory está disponível no momento, selecione as regiões que lhe interessam na página a seguir e expanda Analytics para localizar Data Factory: Produtos disponíveis por região. Os armazenamentos de dados (Azure Storage, Azure SQL Database etc.) e computação (HDInsight etc.) usados pelo data factory podem estar em outras regiões.
Criar serviços vinculados
Os serviços vinculados são criados em um data factory para vincular seus armazenamentos de dados e serviços de computação ao data factory. Nesta seção, você criará serviços vinculados para sua conta de Azure Storage e seu banco de dados em Azure SQL Database.
Crie serviço vinculado do Azure Storage.
Nesta etapa, você vincula sua conta de Azure Storage ao data factory.
Crie um arquivo JSON AzureStorageLinkedService.json na pasta C:\ADFTutorials\IncCopyChangeTrackingTutorial usando o conteúdo a seguir: (Crie a pasta se ela ainda não existir.) Substitua
<accountName>,<accountKey>pelo nome e pela chave da sua conta de armazenamento Azure antes de salvar o arquivo.{ "name": "AzureStorageLinkedService", "properties": { "type": "AzureStorage", "typeProperties": { "connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountName>;AccountKey=<accountKey>" } } }Em Azure PowerShell, alterne para a pasta C:\ADFTutorials\IncCopyChangeTrackingTutorial.
Execute o cmdlet Set-AzDataFactoryV2LinkedService para criar o serviço vinculado: AzureStorageLinkedService. No exemplo a seguir, você passa valores para os parâmetros ResourceGroupName e DataFactoryName.
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "AzureStorageLinkedService" -File ".\AzureStorageLinkedService.json"Veja o exemplo de saída:
LinkedServiceName : AzureStorageLinkedService ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Properties : Microsoft.Azure.Management.DataFactory.Models.AzureStorageLinkedService
Crie um serviço vinculado de Azure SQL Database.
Nesta etapa, você vincula seu banco de dados ao data factory.
Crie um arquivo JSON chamado AzureSQLDatabaseLinkedService.json na pasta C:\ADFTutorials\IncCopyChangeTrackingTutorial com o seguinte conteúdo: Substitua <nome do seu servidor> e <nome do seu banco de dados> pelo nome do seu servidor e banco de dados antes você salva o arquivo. Você também deve configurar o SQL Server do Azure para conceder acesso à identidade gerenciada da fábrica de dados.
{ "name": "AzureSqlDatabaseLinkedService", "properties": { "type": "AzureSqlDatabase", "typeProperties": { "connectionString": "Server=tcp:<your-server-name>.database.windows.net,1433;Database=<your-database-name>;" }, "authenticationType": "ManagedIdentity", "annotations": [] } }Em Azure PowerShell, execute o cmdlet Set-AzDataFactoryV2LinkedService cmdlet para criar o serviço vinculado: AzureSQLDatabaseLinkedService.
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "AzureSQLDatabaseLinkedService" -File ".\AzureSQLDatabaseLinkedService.json"Veja o exemplo de saída:
LinkedServiceName : AzureSQLDatabaseLinkedService ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlDatabaseLinkedService
Criar conjuntos de dados
Nesta etapa, você criará conjuntos de dados para representar a origem dos dados, o destino dos dados. e o local para armazenar o SYS_CHANGE_VERSION.
Criar um conjunto de dados de origem
Nesta etapa, você cria conjuntos de dados para representar os dados de origem.
Crie um arquivo JSON denominado SourceDataset.json na mesma pasta, com o seguinte conteúdo:
{ "name": "SourceDataset", "properties": { "type": "AzureSqlTable", "typeProperties": { "tableName": "data_source_table" }, "linkedServiceName": { "referenceName": "AzureSQLDatabaseLinkedService", "type": "LinkedServiceReference" } } }Execute o cmdlet Set-AzDataFactoryV2Dataset para criar o conjunto de dados: SourceDataset
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SourceDataset" -File ".\SourceDataset.json"Aqui está a amostra de saída do cmdlet:
DatasetName : SourceDataset ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlTableDataset
Criar um conjunto de dados de destino
Nesta etapa, você cria um conjunto de dados para representar os dados copiados do armazenamento de dados de origem.
Crie um arquivo JSON denominado SinkDataset.json na mesma pasta, com o seguinte conteúdo:
{ "name": "SinkDataset", "properties": { "type": "AzureBlob", "typeProperties": { "folderPath": "adftutorial/incchgtracking", "fileName": "@CONCAT('Incremental-', pipeline().RunId, '.txt')", "format": { "type": "TextFormat" } }, "linkedServiceName": { "referenceName": "AzureStorageLinkedService", "type": "LinkedServiceReference" } } }Você cria o contêiner "adftutorial" em seu Azure Blob Storage como um dos pré-requisitos. Crie o contêiner caso ele não exista ou defina-o para o nome de um contêiner existente. Neste tutorial, o nome do arquivo de saída é gerado dinamicamente pelo uso da expressão: @CONCAT('Incremental-', pipeline().RunId, '.txt').
Execute o cmdlet Set-AzDataFactoryV2Dataset para criar o conjunto de dados: SinkDataset
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SinkDataset" -File ".\SinkDataset.json"Aqui está a amostra de saída do cmdlet:
DatasetName : SinkDataset ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.AzureBlobDataset
Criar um conjunto de dados de controle de alterações
Nesta etapa, você cria um conjunto de dados para armazenar a versão do controle de alterações.
Crie um arquivo JSON denominado ChangeTrackingDataset.json na mesma pasta com o seguinte conteúdo:
{ "name": " ChangeTrackingDataset", "properties": { "type": "AzureSqlTable", "typeProperties": { "tableName": "table_store_ChangeTracking_version" }, "linkedServiceName": { "referenceName": "AzureSQLDatabaseLinkedService", "type": "LinkedServiceReference" } } }Você pode criar a tabela table_store_ChangeTracking_version como parte dos pré-requisitos.
Execute o cmdlet Set-AzDataFactoryV2Dataset para criar o conjunto de dados: ChangeTrackingDataset
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "ChangeTrackingDataset" -File ".\ChangeTrackingDataset.json"Aqui está a amostra de saída do cmdlet:
DatasetName : ChangeTrackingDataset ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlTableDataset
Criar um pipeline para a cópia completa
Nesta etapa, você criará um pipeline com uma atividade de cópia que copia todos os dados do armazenamento de dados de origem (Azure SQL Database) para o armazenamento de dados de destino (Azure Blob Storage).
Criar um arquivo JSON: FullCopyPipeline.json na mesma pasta, com o conteúdo a seguir:
{ "name": "FullCopyPipeline", "properties": { "activities": [{ "name": "FullCopyActivity", "type": "Copy", "typeProperties": { "source": { "type": "SqlSource" }, "sink": { "type": "BlobSink" } }, "inputs": [{ "referenceName": "SourceDataset", "type": "DatasetReference" }], "outputs": [{ "referenceName": "SinkDataset", "type": "DatasetReference" }] }] } }Execute o cmdlet Set-AzDataFactoryV2Pipeline para criar o pipeline: FullCopyPipeline.
Set-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "FullCopyPipeline" -File ".\FullCopyPipeline.json"Veja o exemplo de saída:
PipelineName : FullCopyPipeline ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Activities : {FullCopyActivity} Parameters :
Executar o pipeline de cópia completa
Execute o pipeline FullCopyPipeline utilizando o cmdlet Invoke-AzDataFactoryV2Pipeline.
Invoke-AzDataFactoryV2Pipeline -PipelineName "FullCopyPipeline" -ResourceGroup $resourceGroupName -dataFactoryName $dataFactoryName
Monitorar o pipeline de cópia completa
Faça logon no Azure portal.
Clique em Todos os serviços, pesquise com a palavra-chave
data factoriese selecione Data factories.
Procure seu Data Factory na lista de Data Factories e selecione-o para abrir a página do Data Factory.
Na página Data factory, clique no bloco Monitorar e Gerenciar.
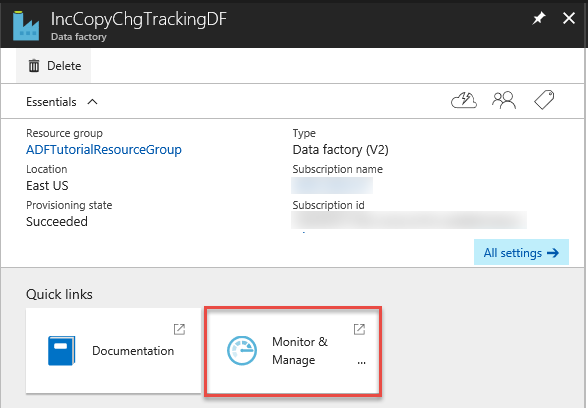
O Aplicativo de Integração de Dados é aberto em uma aba separada. Você pode ver todas as execuções de pipeline e seus status. Observe que, no exemplo a seguir, o status da execução de pipeline é Com Êxito. Você pode verificar os parâmetros passados para o pipeline ao clicar no link da coluna Parâmetros. Se houver um erro, você verá um link na coluna Erro. Clique no link na coluna Ações.
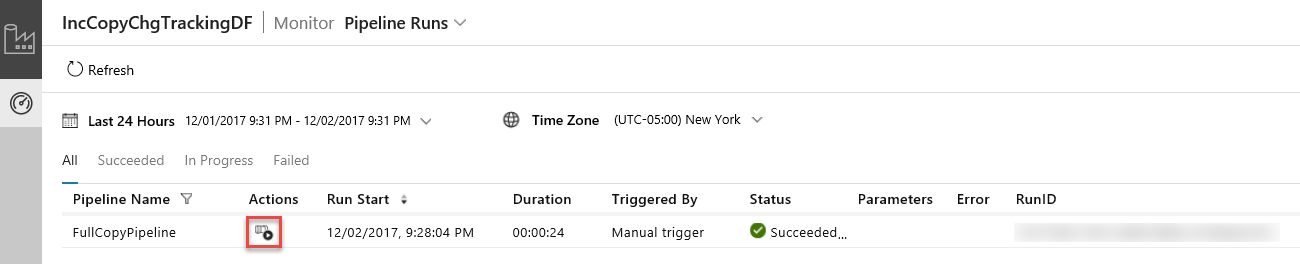
Quando você clicar no link na coluna Ações, verá a página a seguir, que mostra todas as execuções de atividade para o pipeline.
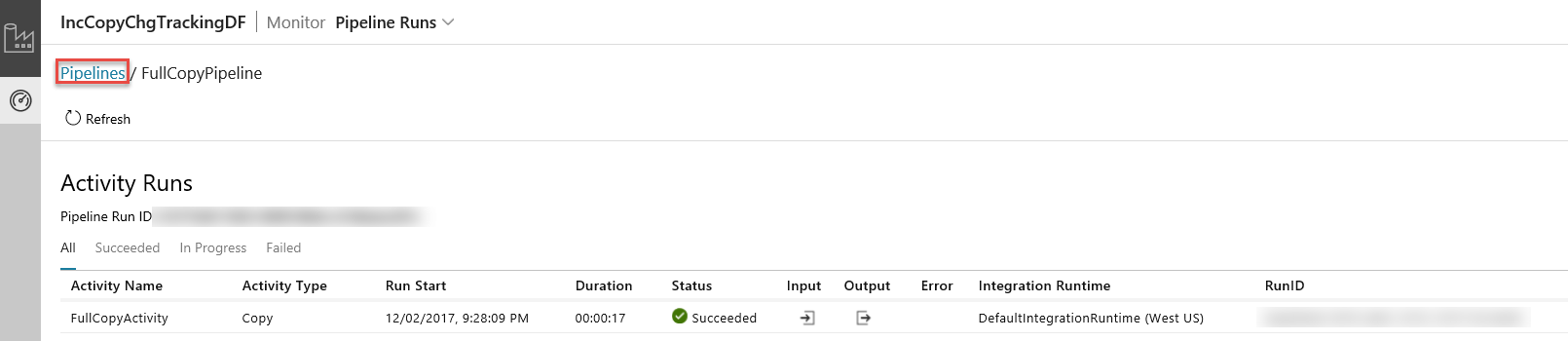
Para alternar novamente para a exibição Pipeline é executado, clique em Pipelines como mostrado na imagem.
Revise os resultados
Você verá um arquivo chamado incremental-<GUID>.txt na pasta incchgtracking do contêiner adftutorial.
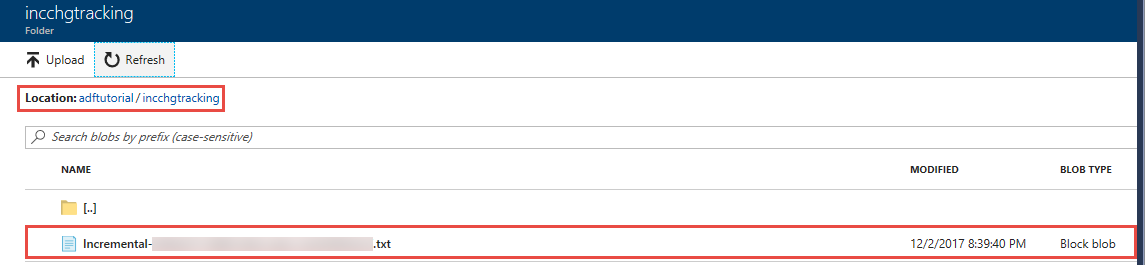
O arquivo deve ter os dados do seu banco de dados:
1,aaaa,21
2,bbbb,24
3,cccc,20
4,dddd,26
5,eeee,22
Adicionar mais dados à tabela de origem
Execute a consulta a seguir no banco de dados para adicionar uma linha e atualizar uma linha.
INSERT INTO data_source_table
(PersonID, Name, Age)
VALUES
(6, 'new','50');
UPDATE data_source_table
SET [Age] = '10', [name]='update' where [PersonID] = 1
Criar um pipeline para a cópia delta
Nesta etapa, você cria um pipeline com as seguintes atividades e execute-o periodicamente. As atividades de pesquisa obtêm o SYS_CHANGE_VERSION novo e antigo do Banco de Dados SQL do Azure e o passa para a atividade de cópia. A atividade de cópia copia os dados inseridos/atualizados/excluídos entre os dois valores SYS_CHANGE_VERSION do Azure SQL Database para o Azure Blob Storage. A atividade de procedimento armazenado atualiza o valor de SYS_CHANGE_VERSION para a próxima execução do pipeline.
Criar um arquivo JSON: IncrementalCopyPipeline.json na mesma pasta, com o conteúdo a seguir:
{ "name": "IncrementalCopyPipeline", "properties": { "activities": [ { "name": "LookupLastChangeTrackingVersionActivity", "type": "Lookup", "typeProperties": { "source": { "type": "SqlSource", "sqlReaderQuery": "select * from table_store_ChangeTracking_version" }, "dataset": { "referenceName": "ChangeTrackingDataset", "type": "DatasetReference" } } }, { "name": "LookupCurrentChangeTrackingVersionActivity", "type": "Lookup", "typeProperties": { "source": { "type": "SqlSource", "sqlReaderQuery": "SELECT CHANGE_TRACKING_CURRENT_VERSION() as CurrentChangeTrackingVersion" }, "dataset": { "referenceName": "SourceDataset", "type": "DatasetReference" } } }, { "name": "IncrementalCopyActivity", "type": "Copy", "typeProperties": { "source": { "type": "SqlSource", "sqlReaderQuery": "select data_source_table.PersonID,data_source_table.Name,data_source_table.Age, CT.SYS_CHANGE_VERSION, SYS_CHANGE_OPERATION from data_source_table RIGHT OUTER JOIN CHANGETABLE(CHANGES data_source_table, @{activity('LookupLastChangeTrackingVersionActivity').output.firstRow.SYS_CHANGE_VERSION}) as CT on data_source_table.PersonID = CT.PersonID where CT.SYS_CHANGE_VERSION <= @{activity('LookupCurrentChangeTrackingVersionActivity').output.firstRow.CurrentChangeTrackingVersion}" }, "sink": { "type": "BlobSink" } }, "dependsOn": [ { "activity": "LookupLastChangeTrackingVersionActivity", "dependencyConditions": [ "Succeeded" ] }, { "activity": "LookupCurrentChangeTrackingVersionActivity", "dependencyConditions": [ "Succeeded" ] } ], "inputs": [ { "referenceName": "SourceDataset", "type": "DatasetReference" } ], "outputs": [ { "referenceName": "SinkDataset", "type": "DatasetReference" } ] }, { "name": "StoredProceduretoUpdateChangeTrackingActivity", "type": "SqlServerStoredProcedure", "typeProperties": { "storedProcedureName": "Update_ChangeTracking_Version", "storedProcedureParameters": { "CurrentTrackingVersion": { "value": "@{activity('LookupCurrentChangeTrackingVersionActivity').output.firstRow.CurrentChangeTrackingVersion}", "type": "INT64" }, "TableName": { "value": "@{activity('LookupLastChangeTrackingVersionActivity').output.firstRow.TableName}", "type": "String" } } }, "linkedServiceName": { "referenceName": "AzureSQLDatabaseLinkedService", "type": "LinkedServiceReference" }, "dependsOn": [ { "activity": "IncrementalCopyActivity", "dependencyConditions": [ "Succeeded" ] } ] } ] } }Execute o cmdlet Set-AzDataFactoryV2Pipeline para criar o pipeline: FullCopyPipeline.
Set-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "IncrementalCopyPipeline" -File ".\IncrementalCopyPipeline.json"Veja o exemplo de saída:
PipelineName : IncrementalCopyPipeline ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Activities : {LookupLastChangeTrackingVersionActivity, LookupCurrentChangeTrackingVersionActivity, IncrementalCopyActivity, StoredProceduretoUpdateChangeTrackingActivity} Parameters :
Executar o pipeline de cópia incremental
Execute o pipeline: IncrementalCopyPipeline por meio do cmdlet Invoke-AzDataFactoryV2Pipeline.
Invoke-AzDataFactoryV2Pipeline -PipelineName "IncrementalCopyPipeline" -ResourceGroup $resourceGroupName -dataFactoryName $dataFactoryName
Monitorar o pipeline de cópia incremental
No Aplicativo de Integração de Dados, atualize a exibição de execuções de pipeline. Confirme que você vê o IncrementalCopyPipeline na lista. Clique no link na coluna Ações.
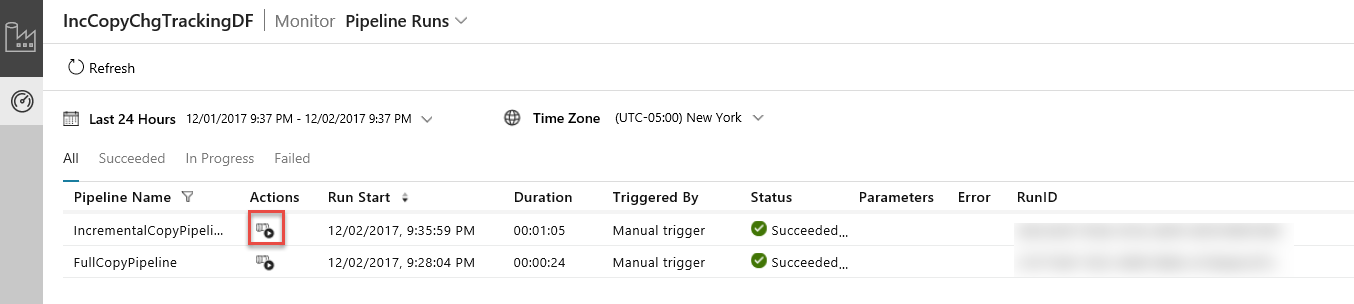
Quando você clicar no link na coluna Ações, verá a página a seguir, que mostra todas as execuções de atividade para o pipeline.
A captura de tela mostra execuções de pipeline de uma fábrica de dados, com várias marcadas como bem-sucedidas.
Para alternar novamente para a exibição Pipeline é executado, clique em Pipelines como mostrado na imagem.
Revise os resultados
Você verá o segundo arquivo na pasta incchgtracking do contêiner adftutorial.
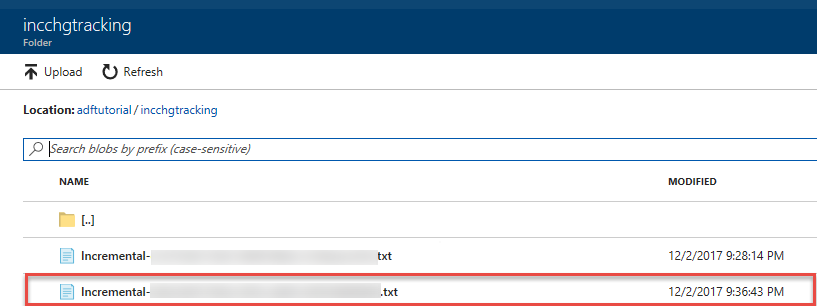
O arquivo deve ter apenas os dados delta do seu banco de dados. O registro com U é a linha atualizada no banco de dados, e I é aquele adicionado à linha.
1,update,10,2,U
6,new,50,1,I
As três primeiras colunas são dados alterados do data_source_table. As duas últimas colunas são os metadados da tabela do sistema de controle de alterações. A quarta coluna é a SYS_CHANGE_VERSION de cada linha alterada. A quinta coluna é a operação: U = atualização, I = inserir. Para obter detalhes sobre as informações de controle de alterações, consulte CHANGETABLE.
==================================================================
PersonID Name Age SYS_CHANGE_VERSION SYS_CHANGE_OPERATION
==================================================================
1 update 10 2 U
6 new 50 1 I
Conteúdo relacionado
Avance para o tutorial seguinte para saber mais sobre como copiar arquivos novos e alterados somente com base na LastModifiedDate: