Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Data Factory no Microsoft Fabric é a próxima geração de Azure Data Factory, com uma arquitetura mais simples, IA interna e novos recursos. Se você não estiver familiarizado com a integração de dados, comece com Fabric Data Factory. As cargas de trabalho existentes do ADF podem ser atualizadas para Fabric para acessar novos recursos em ciência de dados, análise em tempo real e relatórios.
Neste tutorial, você criará um Azure Data Factory com um pipeline que carrega dados delta de várias tabelas em um banco de dados SQL Server para Azure SQL Database.
Neste tutorial, você realizará os seguintes procedimentos:
- Preparar os armazenamentos de dados de origem e destino.
- Criar um data factory.
- Criar um runtime de integração auto-hospedada.
- Instalar o runtime de integração.
- Criar serviços vinculados.
- Criar os conjuntos de dados de origem, de coletor e de marca-d'água.
- Criar, executar e monitorar um pipeline.
- Revisar os resultados.
- Adicionar ou atualizar dados nas tabelas de origem.
- Executar novamente e monitorar o pipeline.
- Examinar os resultados finais.
Visão geral
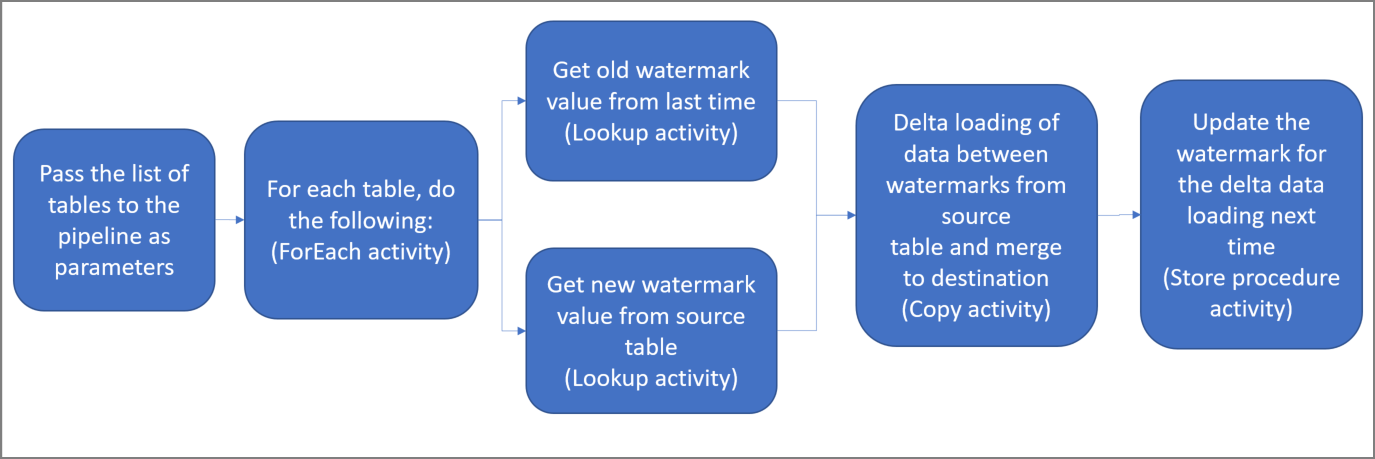
Aqui estão as etapas importantes ao criar essa solução:
Selecione a coluna de marca-d'água.
Selecione uma coluna para cada tabela no armazenamento de dados de origem, na qual você poderá identificar os registros novos ou atualizados de cada execução. Normalmente, os dados nessa coluna selecionada (por exemplo, ID ou last_modify_time) seguem crescendo quando linhas são criadas ou atualizadas. O valor máximo dessa coluna é usado como uma marca-d'água.
Prepare um armazenamento de dados para armazenar o valor de marca-d'água.
Neste tutorial, você armazena o valor de marca-d'água em um banco de dados SQL.
Crie um pipeline com as seguintes atividades:
Crie uma atividade ForEach que itere em uma lista de nomes de tabela de origem passada como um parâmetro para o pipeline. Para cada tabela de origem, são chamadas as próximas atividades necessárias para o carregamento delta.
Crie duas atividades de pesquisa. Use a primeira atividade de Pesquisa para recuperar o último valor de marca-d'água. Use a segunda atividade de Pesquisa para recuperar o novo valor de marca-d'água. Esses valores de marca-d'água são passados para a atividade Copy.
Crie um atividade Copy que copia as linhas do armazenamento de dados de origem com o valor da coluna de marca-d'água maior que o valor da marca-d'água antiga e menor ou igual ao novo valor da marca-d'água. Em seguida, ela copia os dados delta do armazenamento de dados de origem para um Armazenamento de Blobs do Azure como um novo arquivo.
Crie uma atividade de StoredProcedure que atualize o valor de marca-d'água para o pipeline que for executado da próxima vez.
A seguir está o diagrama da solução de alto nível:
Se você não tiver uma assinatura Azure, crie uma conta free antes de começar.
Pré-requisitos
- SQL Server. Você usa um banco de dados SQL Server como o armazenamento de dados de origem neste tutorial.
- Azure SQL Database. Você usa um banco de dados no Banco de Dados SQL do Azure como o armazenamento de dados do coletor. Se você não tiver um banco de dados SQL, consulte Criar um banco de dados no Azure SQL Database para ver as etapas para criar um.
Criar tabelas de origem em seu banco de dados SQL Server
Abra SQL Server Management Studio (SSMS) ou Visual Studio Code e conecte-se ao banco de dados SQL Server.
Em Server Explorer (SSMS) ou no painel Connections (Visual Studio Code), clique com o botão direito do mouse no banco de dados e escolha New Query.
Execute o seguinte comando do SQL no banco de dados para criar as tabelas
customer_tableeproject_table:create table customer_table ( PersonID int, Name varchar(255), LastModifytime datetime ); create table project_table ( Project varchar(255), Creationtime datetime ); INSERT INTO customer_table (PersonID, Name, LastModifytime) VALUES (1, 'John','9/1/2017 12:56:00 AM'), (2, 'Mike','9/2/2017 5:23:00 AM'), (3, 'Alice','9/3/2017 2:36:00 AM'), (4, 'Andy','9/4/2017 3:21:00 AM'), (5, 'Anny','9/5/2017 8:06:00 AM'); INSERT INTO project_table (Project, Creationtime) VALUES ('project1','1/1/2015 0:00:00 AM'), ('project2','2/2/2016 1:23:00 AM'), ('project3','3/4/2017 5:16:00 AM');
Criar tabelas de destino em seu Azure SQL Database
Abra SQL Server Management Studio (SSMS) ou Visual Studio Code e conecte-se ao banco de dados SQL Server.
Em Server Explorer (SSMS) ou no painel Connections (Visual Studio Code), clique com o botão direito do mouse no banco de dados e escolha New Query.
Execute o seguinte comando do SQL no banco de dados para criar as tabelas
customer_tableeproject_table:create table customer_table ( PersonID int, Name varchar(255), LastModifytime datetime ); create table project_table ( Project varchar(255), Creationtime datetime );
Criar outra tabela no Banco de Dados SQL do Azure para armazenar o valor de marca d'água alta
Execute o seguinte comando SQL no banco de dados para criar uma tabela chamada
watermarktablepara armazenar o valor de marca-d'água:create table watermarktable ( TableName varchar(255), WatermarkValue datetime, );Insira valores de marca d'água iniciais para ambas as tabelas de origem na tabela de marca d'água.
INSERT INTO watermarktable VALUES ('customer_table','1/1/2010 12:00:00 AM'), ('project_table','1/1/2010 12:00:00 AM');
Criar um procedimento armazenado no Azure SQL Database
Execute o comando a seguir para criar um procedimento armazenado no banco de dados. Esse procedimento armazenado atualiza o valor de marca d'água após cada execução de pipeline.
CREATE PROCEDURE usp_write_watermark @LastModifiedtime datetime, @TableName varchar(50)
AS
BEGIN
UPDATE watermarktable
SET [WatermarkValue] = @LastModifiedtime
WHERE [TableName] = @TableName
END
Criar tipos de dados e procedimentos armazenados adicionais no Azure SQL Database
Execute a consulta a seguir para criar dois tipos de dados e dois procedimentos armazenados no banco de dados. Eles são usados para mesclar os dados das tabelas de origem nas tabelas de destino.
Para facilitar a jornada de introdução, usamos diretamente esses procedimentos armazenados passando os dados delta por meio de uma variável de tabela e, em seguida, mesclamos esses dados no repositório de destino. Tenha cuidado, pois ele não espera que um número "grande" de linhas delta (mais de 100) seja armazenado na variável de tabela.
Caso precise mesclar um grande número de linhas delta no repositório de destino, sugerimos que você use a atividade Copy para copiar todos os dados delta para uma tabela temporária de "preparo" no repositório de destino primeiro e, em seguida, criar seu próprio procedimento armazenado sem o uso da variável de tabela para mesclá-los da tabela de “preparo” para a tabela “final”.
CREATE TYPE DataTypeforCustomerTable AS TABLE(
PersonID int,
Name varchar(255),
LastModifytime datetime
);
GO
CREATE PROCEDURE usp_upsert_customer_table @customer_table DataTypeforCustomerTable READONLY
AS
BEGIN
MERGE customer_table AS target
USING @customer_table AS source
ON (target.PersonID = source.PersonID)
WHEN MATCHED THEN
UPDATE SET Name = source.Name,LastModifytime = source.LastModifytime
WHEN NOT MATCHED THEN
INSERT (PersonID, Name, LastModifytime)
VALUES (source.PersonID, source.Name, source.LastModifytime);
END
GO
CREATE TYPE DataTypeforProjectTable AS TABLE(
Project varchar(255),
Creationtime datetime
);
GO
CREATE PROCEDURE usp_upsert_project_table @project_table DataTypeforProjectTable READONLY
AS
BEGIN
MERGE project_table AS target
USING @project_table AS source
ON (target.Project = source.Project)
WHEN MATCHED THEN
UPDATE SET Creationtime = source.Creationtime
WHEN NOT MATCHED THEN
INSERT (Project, Creationtime)
VALUES (source.Project, source.Creationtime);
END
Azure PowerShell
Instale os módulos de Azure PowerShell mais recentes seguindo as instruções em Instalar e configurar Azure PowerShell.
Criar uma data factory
Defina uma variável para o nome do grupo de recursos que você usa nos comandos do PowerShell posteriormente. Copie o texto de comando a seguir para o PowerShell, especifique um nome para o grupo de recursos Azure entre aspas duplas e execute o comando. Um exemplo é
"adfrg".$resourceGroupName = "ADFTutorialResourceGroup";Se o grupo de recursos já existir, não convém substituí-lo. Atribua um valor diferente para a variável
$resourceGroupNamee execute o comando novamente.Defina uma variável para o local do data factory.
$location = "East US"Para criar o grupo de recursos Azure, execute o seguinte comando:
New-AzResourceGroup $resourceGroupName $locationSe o grupo de recursos já existir, não convém substituí-lo. Atribua um valor diferente para a variável
$resourceGroupNamee execute o comando novamente.Defina uma variável para o nome do data factory.
Importante
Atualize o nome do data factory para que ele seja globalmente exclusivo. Um exemplo seria ADFIncMultiCopyTutorialFactorySP1127.
$dataFactoryName = "ADFIncMultiCopyTutorialFactory";Para criar o data factory, execute o seguinte cmdlet Set-AzDataFactoryV2:
Set-AzDataFactoryV2 -ResourceGroupName $resourceGroupName -Location $location -Name $dataFactoryName
Observe os seguintes pontos:
O nome do data factory deve ser globalmente exclusivo. Se você receber o erro a seguir, altere o nome e tente novamente:
Set-AzDataFactoryV2 : HTTP Status Code: Conflict Error Code: DataFactoryNameInUse Error Message: The specified resource name 'ADFIncMultiCopyTutorialFactory' is already in use. Resource names must be globally unique.Para criar instâncias do Data Factory, a conta de usuário usada para entrar no Azure deve ser membro de funções de colaborador ou proprietário ou administrador da assinatura Azure.
Para obter uma lista de Azure regiões em que o Data Factory está disponível no momento, selecione as regiões que lhe interessam na página a seguir e expanda Analytics para localizar Data Factory: Produtos disponíveis por região. Os armazenamentos de dados (Azure Storage, Banco de Dados SQL, SQL Managed Instance e assim por diante) e cálculos (Azure HDInsight etc.) usados pelo data factory podem estar em outras regiões.
Criar um runtime de integração auto-hospedada
Nesta seção, você criará um runtime de integração auto-hospedada e o associará a um computador local com o banco de dados SQL Server. O runtime de integração auto-hospedada é o componente que copia dados do SQL Server em seu computador para o Azure SQL Database.
Crie uma variável para o nome do runtime de integração. Use um nome exclusivo e anote-o. Você o usará posteriormente neste tutorial.
$integrationRuntimeName = "ADFTutorialIR"Criar um runtime de integração auto-hospedada.
Set-AzDataFactoryV2IntegrationRuntime -Name $integrationRuntimeName -Type SelfHosted -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupNameVeja o exemplo de saída:
Name : <Integration Runtime name> Type : SelfHosted ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Description : Id : /subscriptions/<subscription ID>/resourceGroups/<ResourceGroupName>/providers/Microsoft.DataFactory/factories/<DataFactoryName>/integrationruntimes/ADFTutorialIRPara recuperar o status do runtime de integração criado, execute o comando a seguir. Confirme se o valor da propriedade Estado está definido como NeedRegistration.
Get-AzDataFactoryV2IntegrationRuntime -name $integrationRuntimeName -ResourceGroupName $resourceGroupName -DataFactoryName $dataFactoryName -StatusVeja o exemplo de saída:
State : NeedRegistration Version : CreateTime : 9/24/2019 6:00:00 AM AutoUpdate : On ScheduledUpdateDate : UpdateDelayOffset : LocalTimeZoneOffset : InternalChannelEncryption : Capabilities : {} ServiceUrls : {eu.frontend.clouddatahub.net} Nodes : {} Links : {} Name : ADFTutorialIR Type : SelfHosted ResourceGroupName : <ResourceGroup name> DataFactoryName : <DataFactory name> Description : Id : /subscriptions/<subscription ID>/resourceGroups/<ResourceGroup name>/providers/Microsoft.DataFactory/factories/<DataFactory name>/integrationruntimes/<Integration Runtime name>Para recuperar as chaves de autenticação usadas para registrar o runtime de integração auto-hospedado com o serviço Azure Data Factory na nuvem, execute o seguinte comando:
Get-AzDataFactoryV2IntegrationRuntimeKey -Name $integrationRuntimeName -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName | ConvertTo-JsonVeja o exemplo de saída:
{ "AuthKey1": "IR@0000000000-0000-0000-0000-000000000000@xy0@xy@xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx=", "AuthKey2": "IR@0000000000-0000-0000-0000-000000000000@xy0@xy@yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy=" }Copie uma das chaves (excluindo as aspas) usadas para registrar o runtime de integração auto-hospedada instalado em seu computador nas próximas etapas.
Instalar a ferramenta Integration Runtime
Se você já tiver o runtime de integração em seu computador, desinstale-o usando Adicionar ou Remover Programas.
Baixe o ambiente de Integration Runtime auto-hospedado em um computador Windows local. Execute a instalação.
Na página Welcome to Microsoft Integration Runtime Setup, selecione Next.
Na página Contrato de Licença do Usuário Final, aceite os termos e o contrato de licença e selecione Avançar.
Na página Pasta de Destino, selecione Avançar.
Na página Pronto para instalar o Microsoft Integration Runtime, selecione Instalar.
Na página Completed the Microsoft Integration Runtime Setup, selecione Finish.
Na página Registrar o Integration Runtime (auto-hospedado), cole a chave que você salvou na seção anterior e selecione Registrar.
Na página Novo nó do Integration Runtime (auto-hospedado), selecione Concluir.
Você verá a seguinte mensagem quando o runtime de integração auto-hospedada for registrado com sucesso:
Na página Registrar Tempo de Execução de Integração (auto-hospedado), selecione Iniciar o Gerenciador de Configuração.
Você verá a página a seguir quando o nó estiver conectado ao serviço de nuvem:
Agora, teste a conectividade com seu banco de dados SQL Server.
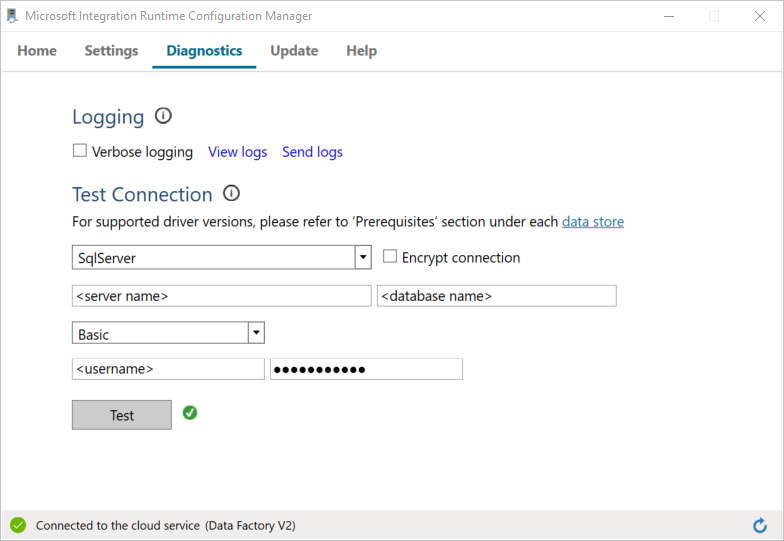
a. Na página Configuration Manager, vá para a guia Diagnostics.
b. Selecione SqlServer para o tipo da fonte de dados.
c. Insira o nome do servidor.
d. Insira o nome do banco de dados.
e. Selecione o modo de autenticação.
f. Insira o nome de usuário.
g. Insira a senha associada ao nome de usuário.
h. Selecione Test para confirmar se o runtime de integração pode se conectar ao SQL Server. Você verá uma marca de seleção verde se a conexão for bem-sucedida. Você verá uma mensagem de erro se a conexão não falhar. Corrija os problemas e verifique se o runtime de integração pode se conectar ao SQL Server.
Observação
Anote os valores de tipo de autenticação, servidor, banco de dados, usuário e senha. Você os usará posteriormente neste tutorial.
Criar serviços vinculados
Os serviços vinculados são criados em um data factory para vincular seus armazenamentos de dados e serviços de computação ao data factory. Nesta seção, você criará serviços vinculados ao banco de dados SQL Server e ao banco de dados em Azure SQL Database.
Criar o serviço vinculado do SQL Server
Nesta etapa, você vincula seu banco de dados SQL Server ao data factory.
Crie um arquivo JSON chamado SqlServerLinkedService.json na pasta C:\ADFTutorials\IncCopyMultiTableTutorial (crie as pastas locais, caso elas ainda não existam) com o conteúdo a seguir. Selecione a seção certa com base na autenticação que você usa para se conectar ao SQL Server.
Importante
Selecione a seção certa com base na autenticação que você usa para se conectar ao SQL Server.
Se você estiver usando uma autenticação do SQL, copie a seguinte definição de JSON:
{ "name":"SqlServerLinkedService", "properties":{ "annotations":[ ], "type":"SqlServer", "typeProperties":{ "connectionString":"integrated security=False;data source=<servername>;initial catalog=<database name>;user id=<username>;Password=<password>" }, "connectVia":{ "referenceName":"<integration runtime name>", "type":"IntegrationRuntimeReference" } } }Se você usar Windows authentication, copie a seguinte definição de JSON:
{ "name":"SqlServerLinkedService", "properties":{ "annotations":[ ], "type":"SqlServer", "typeProperties":{ "connectionString":"integrated security=True;data source=<servername>;initial catalog=<database name>", "userName":"<username> or <domain>\\<username>", "password":{ "type":"SecureString", "value":"<password>" } }, "connectVia":{ "referenceName":"<integration runtime name>", "type":"IntegrationRuntimeReference" } } }Importante
- Selecione a seção certa com base na autenticação que você usa para se conectar ao SQL Server.
- Substitua o <nome do runtime de integração> pelo nome do seu runtime de integração.
- Substitua <servername>, <databasename>, <username> e <password> com valores do banco de dados SQL Server antes de salvar o arquivo.
- Se precisar usar um caractere de barra (
\) em sua conta de usuário e nome do servidor, use o caractere de escape (\). Um exemplo émydomain\\myuser.
No PowerShell, execute o cmdlet a seguir para alternar para a pasta C:\ADFTutorials\IncCopyMultiTableTutorial.
Set-Location 'C:\ADFTutorials\IncCopyMultiTableTutorial'Execute o cmdlet Set-AzDataFactoryV2LinkedService para criar o serviço vinculado AzureStorageLinkedService. No exemplo a seguir, você passa valores para os parâmetros ResourceGroupName e DataFactoryName:
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SqlServerLinkedService" -File ".\SqlServerLinkedService.json"Veja o exemplo de saída:
LinkedServiceName : SqlServerLinkedService ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Properties : Microsoft.Azure.Management.DataFactory.Models.SqlServerLinkedService
Criar um serviço vinculado do Banco de Dados SQL
Crie um arquivo JSON chamado AzureSQLDatabaseLinkedService.json na pasta C:\ADFTutorials\IncCopyMultiTableTutorial com o conteúdo a seguir. (Crie o ADF da pasta se ele ainda não existir.) Substitua <servername>, <database name>, <user name> e <password> com o nome do banco de dados SQL Server, nome do banco de dados, nome de usuário e senha antes de salvar o arquivo.
{ "name":"AzureSQLDatabaseLinkedService", "properties":{ "annotations":[ ], "type":"AzureSqlDatabase", "typeProperties":{ "connectionString":"integrated security=False;encrypt=True;connection timeout=30;data source=<servername>.database.windows.net;initial catalog=<database name>;user id=<user name>;Password=<password>;" } } }No PowerShell, execute o cmdlet Set-AzDataFactoryV2LinkedService para criar o serviço vinculado AzureSQLDatabaseLinkedService.
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "AzureSQLDatabaseLinkedService" -File ".\AzureSQLDatabaseLinkedService.json"Veja o exemplo de saída:
LinkedServiceName : AzureSQLDatabaseLinkedService ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlDatabaseLinkedService
Criar conjuntos de dados
Nesta etapa, você cria conjuntos de dados para representar a fonte de dados, o destino de dados e o local para armazenar a marca d'água.
Criar um conjunto de dados de origem
Crie um arquivo JSON chamado SourceDataset.json na mesma pasta, com o seguinte conteúdo:
{ "name":"SourceDataset", "properties":{ "linkedServiceName":{ "referenceName":"SqlServerLinkedService", "type":"LinkedServiceReference" }, "annotations":[ ], "type":"SqlServerTable", "schema":[ ] } }O Copy activity no pipeline usa uma consulta SQL para carregar os dados em vez de carregar a tabela inteira.
Execute o cmdlet Set-AzDataFactoryV2Dataset para criar o conjunto de dados SourceDataset.
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SourceDataset" -File ".\SourceDataset.json"Aqui está o exemplo de saída do cmdlet:
DatasetName : SourceDataset ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.SqlServerTableDataset
Criar um conjunto de dados do coletor
Crie um arquivo JSON chamado SinkDataset.json na mesma pasta com o conteúdo a seguir. O elemento tableName é definido pelo pipeline dinamicamente no runtime. A atividade ForEach no pipeline itera por meio de uma lista de nomes de tabela e passa o nome da tabela para esse conjunto de dados em cada iteração.
{ "name":"SinkDataset", "properties":{ "linkedServiceName":{ "referenceName":"AzureSQLDatabaseLinkedService", "type":"LinkedServiceReference" }, "parameters":{ "SinkTableName":{ "type":"String" } }, "annotations":[ ], "type":"AzureSqlTable", "typeProperties":{ "tableName":{ "value":"@dataset().SinkTableName", "type":"Expression" } } } }Execute o cmdlet Set-AzDataFactoryV2Dataset para criar o conjunto de dados SinkDataset.
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SinkDataset" -File ".\SinkDataset.json"Aqui está o exemplo de saída do cmdlet:
DatasetName : SinkDataset ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlTableDataset
Criar um conjunto de dados para uma marca-d'água
Nesta etapa, você deve criar um conjunto de dados para armazenar um valor de marca d'água alta.
Crie um arquivo JSON chamado WatermarkDataset.json na mesma pasta com o seguinte conteúdo:
{ "name": " WatermarkDataset ", "properties": { "type": "AzureSqlTable", "typeProperties": { "tableName": "watermarktable" }, "linkedServiceName": { "referenceName": "AzureSQLDatabaseLinkedService", "type": "LinkedServiceReference" } } }Execute o cmdlet Set-AzDataFactoryV2Dataset para criar o conjunto de dados WatermarkDataset.
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "WatermarkDataset" -File ".\WatermarkDataset.json"Aqui está o exemplo de saída do cmdlet:
DatasetName : WatermarkDataset ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlTableDataset
Criar um pipeline
O pipeline usa uma lista de nomes de tabela como um parâmetro. A atividade ForEach itera na lista de nomes de tabela e executa as seguintes operações:
Use a atividade de Pesquisa para recuperar o valor antigo de marca-d'água (o valor inicial ou o que foi usado na última iteração).
Use a atividade de Pesquisa para recuperar o novo valor de marca-d'água (o valor máximo da coluna de marca-d'água na tabela de origem).
Use a atividade Copy para copiar os dados entre esses dois valores de marca-d'água do banco de dados de origem para o banco de dados de destino.
Use a atividade StoredProcedure para atualizar o valor antigo de marca-d'água a ser usado na primeira etapa da próxima iteração.
Criar o pipeline
Crie um arquivo JSON chamado IncrementalCopyPipeline.json na mesma pasta com o seguinte conteúdo:
{ "name":"IncrementalCopyPipeline", "properties":{ "activities":[ { "name":"IterateSQLTables", "type":"ForEach", "dependsOn":[ ], "userProperties":[ ], "typeProperties":{ "items":{ "value":"@pipeline().parameters.tableList", "type":"Expression" }, "isSequential":false, "activities":[ { "name":"LookupOldWaterMarkActivity", "type":"Lookup", "dependsOn":[ ], "policy":{ "timeout":"7.00:00:00", "retry":0, "retryIntervalInSeconds":30, "secureOutput":false, "secureInput":false }, "userProperties":[ ], "typeProperties":{ "source":{ "type":"AzureSqlSource", "sqlReaderQuery":{ "value":"select * from watermarktable where TableName = '@{item().TABLE_NAME}'", "type":"Expression" } }, "dataset":{ "referenceName":"WatermarkDataset", "type":"DatasetReference" } } }, { "name":"LookupNewWaterMarkActivity", "type":"Lookup", "dependsOn":[ ], "policy":{ "timeout":"7.00:00:00", "retry":0, "retryIntervalInSeconds":30, "secureOutput":false, "secureInput":false }, "userProperties":[ ], "typeProperties":{ "source":{ "type":"SqlServerSource", "sqlReaderQuery":{ "value":"select MAX(@{item().WaterMark_Column}) as NewWatermarkvalue from @{item().TABLE_NAME}", "type":"Expression" } }, "dataset":{ "referenceName":"SourceDataset", "type":"DatasetReference" }, "firstRowOnly":true } }, { "name":"IncrementalCopyActivity", "type":"Copy", "dependsOn":[ { "activity":"LookupOldWaterMarkActivity", "dependencyConditions":[ "Succeeded" ] }, { "activity":"LookupNewWaterMarkActivity", "dependencyConditions":[ "Succeeded" ] } ], "policy":{ "timeout":"7.00:00:00", "retry":0, "retryIntervalInSeconds":30, "secureOutput":false, "secureInput":false }, "userProperties":[ ], "typeProperties":{ "source":{ "type":"SqlServerSource", "sqlReaderQuery":{ "value":"select * from @{item().TABLE_NAME} where @{item().WaterMark_Column} > '@{activity('LookupOldWaterMarkActivity').output.firstRow.WatermarkValue}' and @{item().WaterMark_Column} <= '@{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}'", "type":"Expression" } }, "sink":{ "type":"AzureSqlSink", "sqlWriterStoredProcedureName":{ "value":"@{item().StoredProcedureNameForMergeOperation}", "type":"Expression" }, "sqlWriterTableType":{ "value":"@{item().TableType}", "type":"Expression" }, "storedProcedureTableTypeParameterName":{ "value":"@{item().TABLE_NAME}", "type":"Expression" }, "disableMetricsCollection":false }, "enableStaging":false }, "inputs":[ { "referenceName":"SourceDataset", "type":"DatasetReference" } ], "outputs":[ { "referenceName":"SinkDataset", "type":"DatasetReference", "parameters":{ "SinkTableName":{ "value":"@{item().TABLE_NAME}", "type":"Expression" } } } ] }, { "name":"StoredProceduretoWriteWatermarkActivity", "type":"SqlServerStoredProcedure", "dependsOn":[ { "activity":"IncrementalCopyActivity", "dependencyConditions":[ "Succeeded" ] } ], "policy":{ "timeout":"7.00:00:00", "retry":0, "retryIntervalInSeconds":30, "secureOutput":false, "secureInput":false }, "userProperties":[ ], "typeProperties":{ "storedProcedureName":"[dbo].[usp_write_watermark]", "storedProcedureParameters":{ "LastModifiedtime":{ "value":{ "value":"@{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}", "type":"Expression" }, "type":"DateTime" }, "TableName":{ "value":{ "value":"@{activity('LookupOldWaterMarkActivity').output.firstRow.TableName}", "type":"Expression" }, "type":"String" } } }, "linkedServiceName":{ "referenceName":"AzureSQLDatabaseLinkedService", "type":"LinkedServiceReference" } } ] } } ], "parameters":{ "tableList":{ "type":"array" } }, "annotations":[ ] } }Execute o cmdlet Set-AzDataFactoryV2Pipeline para criar o pipeline IncrementalCopyPipeline.
Set-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "IncrementalCopyPipeline" -File ".\IncrementalCopyPipeline.json"Veja o exemplo de saída:
PipelineName : IncrementalCopyPipeline ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Activities : {IterateSQLTables} Parameters : {[tableList, Microsoft.Azure.Management.DataFactory.Models.ParameterSpecification]}
Executar o pipeline
Crie um arquivo de parâmetro chamado Parameters.json na mesma pasta com o seguinte conteúdo:
{ "tableList": [ { "TABLE_NAME": "customer_table", "WaterMark_Column": "LastModifytime", "TableType": "DataTypeforCustomerTable", "StoredProcedureNameForMergeOperation": "usp_upsert_customer_table" }, { "TABLE_NAME": "project_table", "WaterMark_Column": "Creationtime", "TableType": "DataTypeforProjectTable", "StoredProcedureNameForMergeOperation": "usp_upsert_project_table" } ] }Execute o pipeline IncrementalCopyPipeline usando o cmdlet Invoke-AzDataFactoryV2Pipeline. Substitua os espaços reservados com seus próprios nomes de grupo de recursos e de data factory.
$RunId = Invoke-AzDataFactoryV2Pipeline -PipelineName "IncrementalCopyPipeline" -ResourceGroup $resourceGroupName -dataFactoryName $dataFactoryName -ParameterFile ".\Parameters.json"
Monitorar o pipeline
Entre no portal Azure.
Clique em Todos os serviços, pesquise com a palavra-chave Data factories e selecione Data factories.
Procure seu data factory na lista de data factories e selecione-o para abrir a página Data factory.
Na página Data factory, selecione Open no bloco Open Azure Data Factory Studio para iniciar Azure Data Factory em uma guia separada.
Na home page Azure Data Factory, selecione Monitor no lado esquerdo.
Você pode ver todas as execuções de pipeline e seus status. Observe que, no exemplo a seguir, o status da execução de pipeline é Bem-sucedido. Para verificar os parâmetros passados para o pipeline, selecione o link da coluna Parâmetros. Se houver um erro, você verá um link na coluna Erro.

Ao selecionar o link na coluna Ações, você verá todas as execuções de atividade para o pipeline.
Para voltar à exibição Execuções de Pipeline, selecione Todas as Execuções de Pipeline.
Revisar os resultados
Em SQL Server Management Studio, execute as seguintes consultas no banco de dados SQL de destino para verificar se os dados foram copiados de tabelas de origem para tabelas de destino:
Consulta
select * from customer_table
Saída
===========================================
PersonID Name LastModifytime
===========================================
1 John 2017-09-01 00:56:00.000
2 Mike 2017-09-02 05:23:00.000
3 Alice 2017-09-03 02:36:00.000
4 Andy 2017-09-04 03:21:00.000
5 Anny 2017-09-05 08:06:00.000
Consulta
select * from project_table
Saída
===================================
Project Creationtime
===================================
project1 2015-01-01 00:00:00.000
project2 2016-02-02 01:23:00.000
project3 2017-03-04 05:16:00.000
Consulta
select * from watermarktable
Saída
======================================
TableName WatermarkValue
======================================
customer_table 2017-09-05 08:06:00.000
project_table 2017-03-04 05:16:00.000
Observe que os valores de marca d'água para ambas as tabelas foram atualizados.
Adicionar mais dados às tabelas de origem
Execute a consulta a seguir no banco de dados de SQL Server de origem para atualizar uma linha existente no customer_table. Insira uma nova linha em project_table.
UPDATE customer_table
SET [LastModifytime] = '2017-09-08T00:00:00Z', [name]='NewName' where [PersonID] = 3
INSERT INTO project_table
(Project, Creationtime)
VALUES
('NewProject','10/1/2017 0:00:00 AM');
Executar novamente o pipeline
Agora, execute novamente o pipeline ao executar o seguinte comando do PowerShell:
$RunId = Invoke-AzDataFactoryV2Pipeline -PipelineName "IncrementalCopyPipeline" -ResourceGroup $resourceGroupname -dataFactoryName $dataFactoryName -ParameterFile ".\Parameters.json"Monitore as execuções de pipeline seguindo as instruções da seção Monitorar o pipeline. Quando o status do pipeline for Em Andamento, você verá outro link de ação em Ações para cancelar a execução de pipeline.
Selecione Atualizar para atualizar a lista até que a execução de pipeline seja bem-sucedida.
Opcionalmente, clique no link Exibir as execuções de atividade em Ações para ver todas as execuções de atividade associadas a esta execução de pipeline.
Examinar os resultados finais
Em SQL Server Management Studio, execute as consultas a seguir no banco de dados de destino para verificar se os dados atualizados/novos foram copiados de tabelas de origem para tabelas de destino.
Consulta
select * from customer_table
Saída
===========================================
PersonID Name LastModifytime
===========================================
1 John 2017-09-01 00:56:00.000
2 Mike 2017-09-02 05:23:00.000
3 NewName 2017-09-08 00:00:00.000
4 Andy 2017-09-04 03:21:00.000
5 Anny 2017-09-05 08:06:00.000
Observe os novos valores de Name e LastModifytime para PersonID para o número 3.
Consulta
select * from project_table
Saída
===================================
Project Creationtime
===================================
project1 2015-01-01 00:00:00.000
project2 2016-02-02 01:23:00.000
project3 2017-03-04 05:16:00.000
NewProject 2017-10-01 00:00:00.000
Observe que a entrada NewProject foi adicionada a project_table.
Consulta
select * from watermarktable
Saída
======================================
TableName WatermarkValue
======================================
customer_table 2017-09-08 00:00:00.000
project_table 2017-10-01 00:00:00.000
Observe que os valores de marca d'água para ambas as tabelas foram atualizados.
Conteúdo relacionado
Neste tutorial, você realizou os seguintes procedimentos:
- Preparar os armazenamentos de dados de origem e destino.
- Criar um data factory.
- Criar um runtime de integração auto-hospedada (IR).
- Instalar o runtime de integração.
- Criar serviços vinculados.
- Criar os conjuntos de dados de origem, de coletor e de marca-d'água.
- Criar, executar e monitorar um pipeline.
- Revisar os resultados.
- Adicionar ou atualizar dados nas tabelas de origem.
- Executar novamente e monitorar o pipeline.
- Examinar os resultados finais.
Avance para o tutorial a seguir para saber mais sobre como transformar dados usando um cluster Spark no Azure: