Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Importante
Esta funcionalidade está em Pré-visualização Pública. Para obter informações sobre elegibilidade e habilitação, consulte Habilitar computação sem servidor.
Este artigo explica como usar a computação sem servidor para notebooks. Para obter informações sobre como usar a computação sem servidor para fluxos de trabalho, consulte Executar seu trabalho do Azure Databricks com computação sem servidor para fluxos de trabalho.
Para obter informações sobre preços, consulte Preços do Databricks.
Requisitos
Seu espaço de trabalho deve estar habilitado para o Catálogo Unity.
Seu espaço de trabalho deve estar em uma região suportada. Consulte Regiões do Azure Databricks.
Sua conta deve estar habilitada para computação sem servidor. Consulte Ativar computação sem servidor.
Anexar um bloco de notas à computação sem servidor
Se o espaço de trabalho estiver habilitado para computação interativa sem servidor, todos os usuários no espaço de trabalho terão acesso à computação sem servidor para blocos de anotações. Não são necessárias permissões adicionais.
Para anexar à computação sem servidor, clique no menu suspenso Conectar no bloco de anotações e selecione Sem servidor. Para novos blocos de anotações, a computação anexada assume automaticamente como padrão serverless após a execução do código se nenhum outro recurso tiver sido selecionado.
Instalar dependências do bloco de notas
Você pode instalar dependências Python para blocos de anotações sem servidor usando o painel lateral Ambiente , que fornece um único local para editar, visualizar e exportar os requisitos de biblioteca para um bloco de anotações. Essas dependências podem ser adicionadas usando um ambiente base ou individualmente.
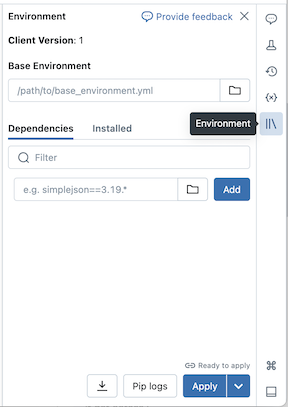
Configurar um ambiente base
Um ambiente base é um arquivo YAML armazenado como um arquivo de espaço de trabalho ou em um volume do Catálogo Unity que especifica dependências de ambiente adicionais. Os ambientes básicos podem ser compartilhados entre notebooks. Para configurar um ambiente base:
Crie um arquivo YAML que define configurações para um ambiente virtual Python. O exemplo a seguir YAML, que é baseado na especificação de ambiente de projetos MLflow, define um ambiente base com algumas dependências de biblioteca:
client: "1" dependencies: - --index-url https://pypi.org/simple - -r "/Workspace/Shared/requirements.txt" - cowsay==6.1Carregue o arquivo YAML como um arquivo de espaço de trabalho ou para um volume do Catálogo Unity. Consulte Importar um arquivo ou Carregar arquivos para um volume do Catálogo Unity.
À direita do bloco de anotações, clique no
 botão para expandir o painel Ambiente . Esse botão só aparece quando um bloco de anotações está conectado à computação sem servidor.
botão para expandir o painel Ambiente . Esse botão só aparece quando um bloco de anotações está conectado à computação sem servidor.No campo Ambiente Base, insira o caminho do arquivo YAML carregado ou navegue até ele e selecione-o.
Clique em Aplicar. Isso instala as dependências no ambiente virtual do notebook e reinicia o processo do Python.
Os usuários podem substituir as dependências especificadas no ambiente base instalando dependências individualmente.
Adicionar dependências individualmente
Você também pode instalar dependências em um bloco de anotações conectado à computação sem servidor usando a guia Dependências do painel Ambiente :
- À direita do bloco de anotações, clique no botão para expandir o painel Ambiente . Esse botão só aparece quando um bloco de anotações está conectado à computação sem servidor.
- Na seção Dependências, clique em Adicionar Dependência e insira o caminho da dependência da biblioteca no campo. Você pode especificar uma dependência em qualquer formato que seja válido em um arquivo requirements.txt .
- Clique em Aplicar. Isso instala as dependências no ambiente virtual do notebook e reinicia o processo do Python.
Nota
Um trabalho usando computação sem servidor instalará a especificação de ambiente do bloco de anotações antes de executar o código do bloco de anotações. Isso significa que não há necessidade de adicionar dependências ao agendar blocos de anotações como trabalhos. Consulte Configurar ambientes e dependências do bloco de anotações.
Exibir dependências instaladas e logs pip
Para visualizar as dependências instaladas, clique em Instalado no painel lateral Ambientes de um bloco de anotações. Os logs de instalação de pip para o ambiente de notebook também estão disponíveis clicando em logs de pip na parte inferior do painel.
Redefinir o ambiente
Se o seu bloco de notas estiver ligado a computação sem servidor, o Databricks armazenará automaticamente em cache o conteúdo do ambiente virtual do bloco de notas. Isso significa que você geralmente não precisa reinstalar as dependências Python especificadas no painel Ambiente quando abre um bloco de anotações existente, mesmo que ele tenha sido desconectado devido à inatividade.
O cache do ambiente virtual Python também se aplica a trabalhos. Isso significa que as execuções subsequentes de trabalhos são mais rápidas, pois as dependências necessárias já estão disponíveis.
Nota
Se você alterar a implementação de um pacote Python personalizado que é usado em um trabalho sem servidor, você também deve atualizar seu número de versão para trabalhos para pegar a implementação mais recente.
Para limpar o cache do ambiente e executar uma nova instalação das dependências especificadas no painel Ambiente de um bloco de anotações conectado à computação sem servidor, clique na seta ao lado de Aplicar e, em seguida, clique em Redefinir ambiente.
Nota
Redefina o ambiente virtual se você instalar pacotes que quebram ou alteram o bloco de anotações principal ou o ambiente Apache Spark. Desanexar o notebook da computação sem servidor e reanexá-lo não necessariamente limpa todo o cache do ambiente.
Ver informações de consulta
A computação sem servidor para blocos de anotações e fluxos de trabalho usa informações de consulta para avaliar o desempenho de execução do Spark. Depois de executar uma célula em um bloco de anotações, você pode exibir informações relacionadas a consultas SQL e Python clicando no link Ver desempenho .
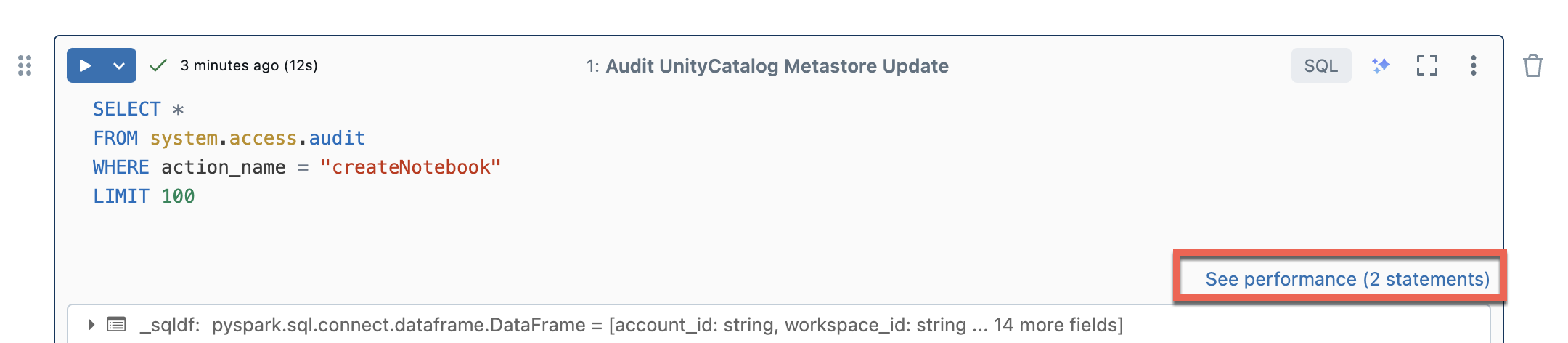
Você pode clicar em qualquer uma das instruções do Spark para visualizar as métricas de consulta. A partir daí, você pode clicar em Ver perfil de consulta para ver uma visualização da execução da consulta. Para obter mais informações sobre perfis de consulta, consulte Perfil de consulta.
Nota
Para exibir informações de desempenho para suas execuções de trabalho, consulte Exibir informações de consulta de execução de trabalho.
Histórico de consultas
Todas as consultas executadas em computação sem servidor também serão registradas na página de histórico de consultas do seu espaço de trabalho. Para obter informações sobre o histórico de consultas, consulte Histórico de consultas.
Limitações do insight de consulta
- O perfil de consulta só estará disponível após o término da execução da consulta.
- As métricas são atualizadas ao vivo, embora o perfil de consulta não seja mostrado durante a execução.
- Somente os seguintes status de consulta são cobertos: EXECUTANDO, CANCELADO, FALHADO, CONCLUÍDO.
- As consultas em execução não podem ser canceladas a partir da página de histórico de consultas. Eles podem ser cancelados em cadernos ou trabalhos.
- Métricas detalhadas não estão disponíveis.
- O download do Perfil de Consulta não está disponível.
- O acesso à interface do usuário do Spark não está disponível.
- O texto da instrução contém apenas a última linha que foi executada. No entanto, pode haver várias linhas que precedem essa linha que foram executadas como parte da mesma instrução.
Limitações
Para obter uma lista de limitações, consulte Limitações de computação sem servidor.