Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Esse artigo descreve como MLOps Stacks permite implementar o processo de desenvolvimento e implantação como código em um repositório controlado por origem. Também descreve os benefícios do desenvolvimento de modelos na plataforma Databricks Data Intelligence, uma plataforma única que unifica cada passo do processo de desenvolvimento e implantação de modelos.
O que é o MLOps Stacks?
Com MLOps Stacks, todo o processo de desenvolvimento do modelo é implementado, salvo e rastreado como código em um repositório controlado por origem. Automatizar o processo dessa forma facilita implantações mais repetíveis, previsíveis e sistemáticas e possibilita a integração com seu processo de CI/CD. Representar o processo de desenvolvimento do modelo como código permite implantar o código em vez de implantar o modelo. A implantação do código automatiza a capacidade de construir o modelo, tornando muito mais fácil treiná-lo novamente quando necessário.
Ao criar um projeto usando MLOps Stacks, você define os componentes do seu processo de desenvolvimento e implantação de ML, como notebooks para usar para engenharia de recursos, treinamento, teste e implantação, pipelines para treinamento e teste, espaços de trabalho para usar em cada estágio e Fluxos de trabalho de CI/CD usando GitHub Actions ou Azure DevOps para testes automatizados e implantação de seu código.
O ambiente criado pelo MLOps Stacks implementa o fluxo de trabalho do MLOps recomendado pelo Databricks. Você pode personalizar o código para criar estruturas para corresponder aos processos ou requisitos da sua organização.
Como funciona o MLOps Stacks?
Você usa a CLI do Databricks para criar uma pilha de MLOps. Para obter instruções passo a passo, consulte Pacotes de Automação Declarativa para Pilhas MLOps.
Quando você inicia um projeto do MLOps Stacks, o software orienta você na inserção dos detalhes de configuração e cria um diretório que contém os arquivos que compõem o projeto. Esse stack implementa o fluxo de trabalho de MLOps de produção recomendado pelo Databricks. Os componentes mostrados no diagrama são criados para você, e só é preciso editar os arquivos para adicionar o código personalizado.
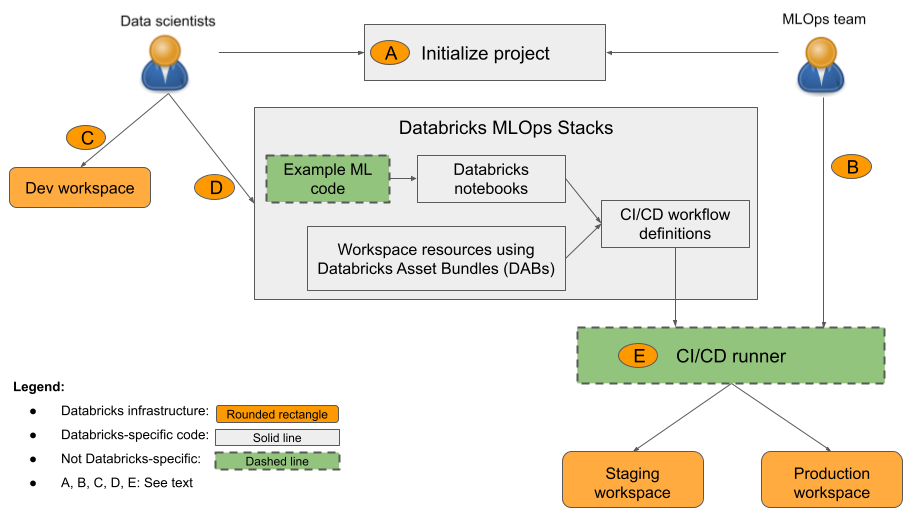
No diagrama:
-
R: Um cientista de dados ou engenheiro de ML inicializa o projeto usando
databricks bundle init mlops-stacks. Ao inicializar o projeto, você pode optar por configurar os componentes de código de ML (normalmente usados por cientistas de dados), os componentes de CI/CD (normalmente usados por engenheiros de ML) ou ambos. - B: Os engenheiros de ML configuram segredos da entidade de serviço do Databricks para CI/CD.
- C: Os cientistas de dados desenvolvem modelos no Databricks ou em seu sistema local.
- D: Os cientistas de dados criam solicitações de pull para atualizar o código de ML.
- E: O executor de CI/CD executa notebooks, cria trabalhos e executa outras tarefas nos espaços de trabalho de preparo e produção.
Sua organização pode usar a pilha padrão ou personalizá-la conforme necessário para adicionar, remover ou revisar componentes para atender às práticas da sua organização. Confira o Leiame do repositório GitHub para ver mais detalhes.
O MLOps Stacks foi projetado com uma estrutura modular para permitir que as diferentes equipes de ML trabalhem de maneira independente em um projeto, seguindo as melhores práticas de engenharia de software e mantendo a CI/CD de nível de produção. Os engenheiros de produção configuram a infraestrutura de ML que permite aos cientistas de dados desenvolver, testar e implantar pipelines e modelos de ML em produção.
Conforme mostrado no diagrama, a pilha MLOps padrão inclui os três componentes a seguir:
- Código de ML. MLOps Stacks cria um conjunto de modelos para um projeto de ML, incluindo notebooks para treinamento, inferência em lote e assim por diante. O modelo padronizado permite que os cientistas de dados comecem rapidamente, unifique a estrutura do projeto entre as equipes e aplique código modularizado pronto para teste.
- Recursos de ML como código. MLOps Stacks define recursos como espaços de trabalho e pipelines para tarefas como treinamento e inferência em lote. Os recursos são definidos em Pacotes de Automação Declarativa para facilitar o teste, a otimização e o controle de versão para o ambiente de ML. Por exemplo, você pode tentar um tipo de instância maior para retreinamento automatizado do modelo e a alteração será rastreada automaticamente para referência futura.
- CI/CD. Você pode usar GitHub Actions ou Azure DevOps para testar e implantar código e recursos de ML, garantindo que todas as alterações de produção sejam realizadas por meio de automação e que apenas o código testado seja implantado na produção.
Fluxo do projeto MLOps
Um projeto padrão de MLOps Stacks inclui um pipeline de ML com fluxos de trabalho de CI/CD para testar e implantar o treinamento automatizado de modelos e os trabalhos de inferência em lote nos espaços de trabalho de desenvolvimento, teste e produção do Databricks. O MLOps Stacks é configurável, portanto, você pode modificar a estrutura do projeto para atender aos processos da sua organização.
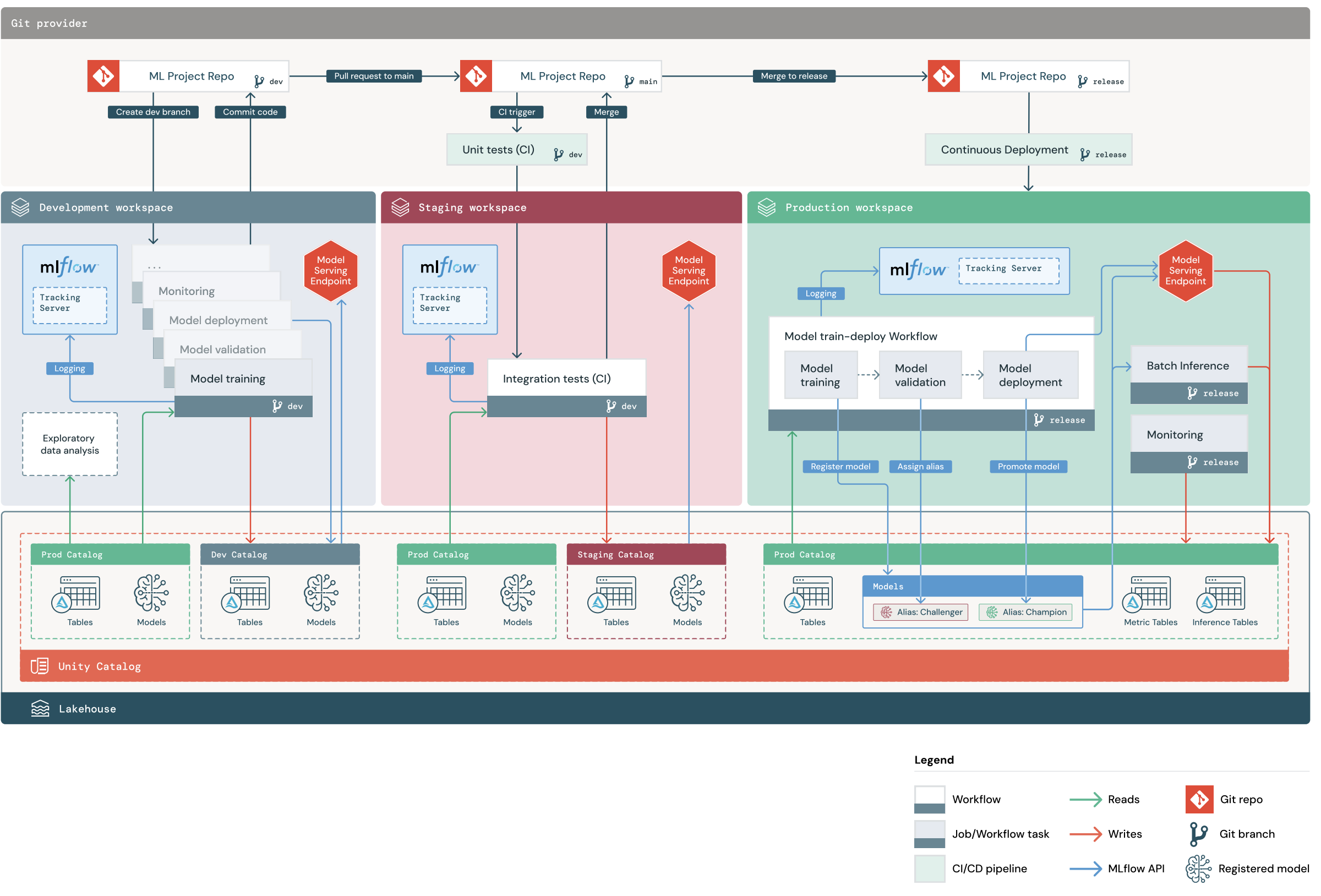
O diagrama mostra o processo que é implementado pela Pilha MLOps padrão. No espaço de trabalho de desenvolvimento, os cientistas de dados iteram sobre o código de ML e enviam pull requests (PRs). Os PRs acionam testes de unidade e testes de integração em um espaço de trabalho de teste isolado do Databricks. Quando um PR é mesclado com o principal, os trabalhos de treinamento de modelo e de inferência em lote executados na preparação são atualizados imediatamente para executar o código mais recente. Depois de mesclar um PR no principal, você pode cortar uma nova ramificação de lançamento como parte do processo de lançamento agendado e implantar as alterações de código na produção.
Estrutura de projeto do MLOps Stacks
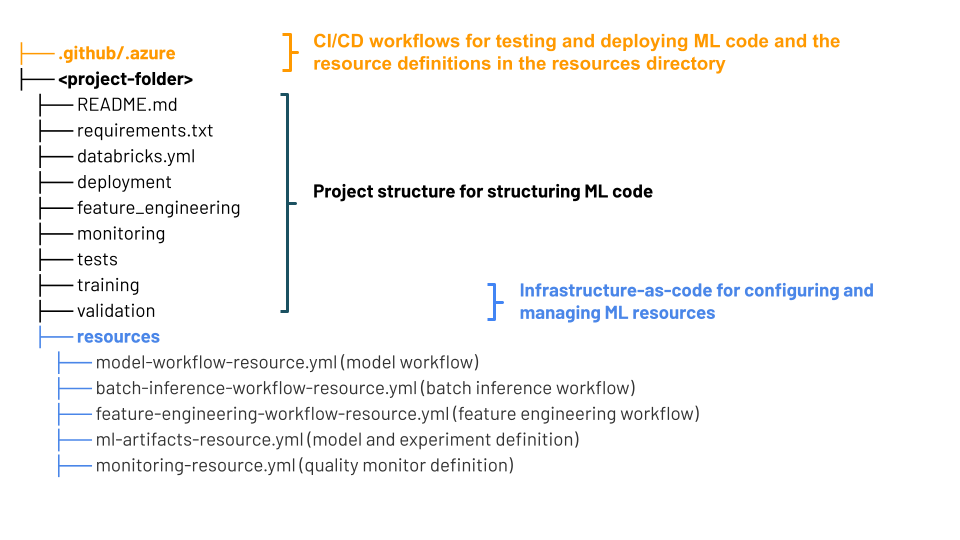
Um MLOps Stack usa Pacotes de Automação Declarativa – uma coleção de arquivos de origem que serve como a definição de ponta a ponta de um projeto. Esses arquivos de origem incluem informações sobre como eles devem ser testados e implantados. Coletar os arquivos como um pacote facilita a codiversão de alterações e o uso das melhores práticas de engenharia de software, como controle de versão, revisão de código, teste e CI/CD.
O diagrama mostra os arquivos criados para a Stack padrão de MLOps. Para obter detalhes sobre os arquivos incluídos na pilha, consulte a documentação no repositório GitHub ou Pacotes de Automação Declarativa para Pilhas de MLOps.
Componentes do MLOps Stacks
Uma “pilha” refere-se ao conjunto de ferramentas usado em um processo de desenvolvimento. A Pilha Padrão de MLOps aproveita a plataforma unificada do Databricks e utiliza as seguintes ferramentas:
| Componente | Ferramenta no Databricks |
|---|---|
| Código de desenvolvimento de modelo de aprendizado de máquina | notebooks do Databricks, MLflow |
| Desenvolvimento e gerenciamento de funcionalidades | Engenharia de recursos |
| Repositório de Modelos de Machine Learning | Modelos no Catálogo do Unity |
| Serviço de modelo de ML | Servir o modelo Mosaic AI |
| Infraestrutura como código | Pacotes de Automação Declarativa |
| Orquestrador | Trabalhos do Lakeflow |
| CI/CD | GitHub Actions, Azure DevOps |
| Monitoramento de desempenho de dados e modelos | Criação de perfil de dados |
Próximas etapas
Para começar, consulte Pacotes de Automação Declarativa para Pilhas MLOps ou o repositório Databricks MLOps Stacks no GitHub.