Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Os Fluxos de Trabalho do Azure Databricks orquestram pipelines de processamento de dados, aprendizado de máquina e análise na Plataforma de Data Intelligence do Databricks. Os fluxos de trabalho têm serviços de orquestração totalmente gerenciados e integrados à plataforma Azure Databricks, incluindo os trabalhos do Azure Databricks para executar código não interativo no workspace do Azure Databricks e Delta Live Tables para criar pipelines de ETL confiáveis e fáceis de manter.
Para saber mais sobre os benefícios de orquestrar seus fluxos de trabalho com a Plataforma do Azure Databricks, confira Fluxos de trabalho do Databricks.
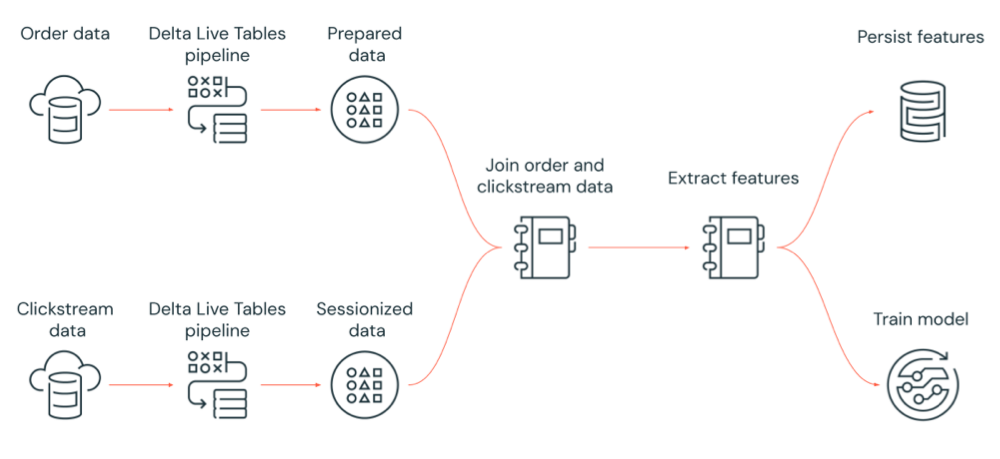
Um exemplo de fluxo de trabalho do Azure Databricks
O diagrama a seguir ilustra um fluxo de trabalho que é orquestrado por um trabalho do Azure Databricks para:
- Executar um pipeline do Delta Live Tables que ingere dados de sequência de cliques brutos do armazenamento em nuvem, limpa e prepara os dados, organiza os dados em sessões e persiste o conjunto final de dados organizados em sessões no Delta Lake.
- Executar um pipeline do Delta Live Tables que ingere dados de pedidos do armazenamento em nuvem, limpa e transforma os dados para processamento e persiste o conjunto de dados final no Delta Lake.
- Juntar a ordem e os dados de fluxo de cliques em sessões para criar um novo conjunto de dados para análise.
- Extrair recursos dos dados preparados.
- Executar tarefas em paralelo para manter os recursos e treinar um modelo de machine learning.
O que são os trabalhos do Azure Databricks?
Um trabalho do Azure Databricks é uma maneira de executar aplicativos de processamento e análise de dados em um workspace do Azure Databricks. Seu trabalho pode consistir em uma única tarefa ou pode ser um grande fluxo de trabalho de várias tarefas com dependências complexas. O Azure Databricks gerencia a orquestração de tarefas, o gerenciamento de clusters, o monitoramento e o relatório de erros para todos os seus trabalhos. Você pode executar seus trabalhos imediatamente, periodicamente por meio de um sistema de agendamento fácil de usar, sempre que novos arquivos chegarem em um local externo ou continuamente para garantir que uma instância do trabalho esteja sempre em execução. Você também pode executar trabalhos interativamente na interface do usuário do notebook.
Você pode criar e executar um trabalho usando a interface do usuário dos trabalhos, a CLI do Databricks ou invocando a API de trabalhos. É possível reparar e executar novamente um trabalho com falha ou cancelado usando a IU ou a API. Você pode monitorar os resultados da execução do trabalho usando a interface do usuário, a CLI, a API e as notificações (por exemplo, email, destino do webhook ou notificações do Slack).
Para saber mais sobre como usar a CLI do Databricks, veja O que é a CLI do Databricks?. Para saber mais sobre como usar a API de Trabalhos, consulte a API de Trabalhos.
As seções a seguir abordam recursos importantes do de trabalhos do Azure Databricks.
Importante
- Um workspace é limitado a 1.000 execuções de tarefas simultâneas. Uma resposta
429 Too Many Requestsé retornada quando você solicita uma execução que não pode ser iniciada imediatamente. - O número de trabalhos que um workspace pode criar em uma hora é limitado a 10.000 (inclui “runs submit”). Esse limite também afeta os trabalhos criados pelos fluxos de trabalho da API REST e do notebook.
Implementar processamento e análise de dados com tarefas de trabalho
Implemente o fluxo de trabalho de processamento e análise de dados usando tarefas. Um trabalho é composto de uma ou mais tarefas. É possível criar tarefas de trabalho usando notebooks, JARS, pipelines do Delta Live Tables, envios de Python, Scala e Spark e aplicativos Java. Suas tarefas de trabalho também podem orquestrar consultas SQL, alertas e painéis do Databricks para criar análises e visualizações, ou você pode usar a tarefa dbt para executar transformações dbt em fluxo de trabalho. Também há suporte a aplicativos de envio do Spark herdados.
Também é possível adicionar uma tarefa a um trabalho que executa um trabalho diferente. Esse recurso permite dividir um processo grande em vários trabalhos menores ou criar módulos generalizados que podem ser reutilizados por vários trabalhos.
Você controla a ordem de execução das tarefas especificando as dependências entre elas. Você pode configurar as tarefas para execução em sequência ou em paralelo.
Executar trabalhos de forma interativa, contínua ou usando gatilhos de trabalho
Você pode executar seus trabalhos interativamente a partir da interface do usuário, da API ou da CLI de trabalhos, ou pode executar um trabalho contínuo. Você pode criar um agendamento para executar seu trabalho periodicamente ou executá-lo quando novos arquivos chegarem em um local externo, como Amazon S3, armazenamento Azure ou armazenamento Google Cloud.
Monitorar o progresso do trabalho com notificações
Você pode receber notificações quando um trabalho ou tarefa for iniciado, concluído ou falhar. Você pode enviar notificações para um ou mais endereços de email ou destinos do sistema (por exemplo, destinos de webhook ou Slack). Confira Adicionar notificações de email e sistema para eventos de trabalho.
Monitorar atividade e custos de trabalho com tabelas do sistema
As tabelas do sistema incluem um esquema workflow em que você pode exibir registros relacionados à atividade de trabalho em sua conta. Confira a Referência da tabela do sistema de trabalhos.
Você também pode ingressar as tabelas do sistema de trabalhos com tabelas de cobrança para monitorar o custo dos trabalhos em sua conta. Confira Monitorar custos de trabalho com tabelas do sistema.
Executar trabalhos com os recursos de computação do Azure Databricks
Os clusters do Databricks e os warehouses SQL fornecem os recursos de computação para seus trabalhos. Você pode executar seus trabalhos com um cluster de trabalho, um cluster para todos os fins ou um warehouse SQL:
- Um cluster de trabalho é um cluster dedicado ao seu trabalho ou a tarefas individuais do trabalho. Seu trabalho pode usar um cluster de trabalho que é compartilhado por todas as tarefas ou você pode configurar um cluster para tarefas individuais ao criar ou editar uma tarefa. Um cluster de trabalho é criado quando o trabalho ou a tarefa é iniciado e encerrado quando o trabalho ou a tarefa termina.
- Um cluster para todos os fins é um cluster compartilhado que é iniciado e encerrado manualmente e pode ser compartilhado por vários usuários e trabalhos.
Para otimizar o uso de recursos, o Databricks recomenda o uso de um cluster de trabalho para seus trabalhos. Para reduzir o tempo de espera pela inicialização do cluster, considere o uso de um cluster para todos os fins. Confira Usar a computação do Azure Databricks com seus trabalhos.
Use um warehouse SQL para executar tarefas SQL do Databricks, como consultas, painéis ou alertas. Você também pode usar um warehouse SQL para executar transformações dbt com a tarefa dbt.
Próximas etapas
Para começar a usar os trabalhos do Azure Databricks:
Crie seu primeiro trabalho do Azure Databricks com o início rápido.
Saiba como criar e executar fluxos de trabalho com a interface de usuário dos trabalhos do Azure Databricks.
Saiba como executar um trabalho sem precisar configurar recursos de computação do Azure Databricks com fluxos de trabalho sem servidor.
Saiba mais sobre o monitoramento de execuções de trabalhos na interface de usuário dos trabalhos do Azure Databricks.
Saiba mais sobre as opções de configuração para trabalhos.
Saiba mais sobre como criar, gerenciar e solucionar problemas de fluxos de trabalho com os trabalhos do Azure Databricks:
- Saiba como comunicar informações entre tarefas em um trabalho do Azure Databricks com valores de tarefa.
- Saiba como passar contexto sobre execuções de trabalho para tarefas de trabalho com variáveis de parâmetro de tarefa.
- Saiba como configurar suas tarefas de trabalho para serem executadas condicionalmente com base no status das dependências da tarefa.
- Saiba como solucionar problemas e corrigir trabalhos com falha.
- Seja notificado quando suas execuções de trabalho começarem, forem concluídas ou falharem com as notificações de execução de trabalho.
- Dispare seus trabalhos em um agendamento personalizado ou execute um trabalho contínuo.
- Saiba como executar seu trabalho do Azure Databricks quando novos dados chegam com gatilhos de chegada de arquivo.
- Saiba como usar os recursos de computação do Databricks para executar trabalhos.
- Saiba mais sobre as atualizações da API de Trabalhos para dar suporte à criação e ao gerenciamento de fluxos de trabalho com os Trabalhos do Azure Databricks.
- Use guias de instruções e tutoriais para saber mais sobre a implementação de fluxos de trabalho de dados com os trabalhos do Azure Databricks.
O que é o Delta Live Tables?
Observação
O Delta Live Tables exige o plano Premium. Entre em contato com sua equipe de conta do Databricks para obter mais informações.
O Delta Live Tables é uma estrutura que simplifica o ETL e o processamento de dados de streaming. O Delta Live Tables fornece ingestão eficiente de dados com suporte integrado para Carregamento Automático, interfaces SQL e Python que dão suporte à implementação declarativa de transformações de dados e suporte para gravação de dados transformados no Delta Lake. Você define as transformações a serem executadas nos dados e o Delta Live Tables gerencia a orquestração de tarefas, o gerenciamento de clusters, o monitoramento, a qualidade dos dados e o tratamento de erro.
Para começar, confira O que é o Delta Live Tables?.
Trabalhos do Azure Databricks e Delta Live Tables
Os trabalhos do Azure Databricks e o Delta Live Tables fornecem uma estrutura abrangente para criar e implantar fluxos de trabalho de análise e processamento de dados de ponta a ponta.
Use o Delta Live Tables para toda a ingestão e transformação de dados. Use os Trabalhos do Azure Databricks para orquestrar cargas de trabalho compostas de uma única tarefa ou de várias tarefas de análise e processamento de dados na plataforma Databricks, incluindo a ingestão e a transformação do Delta Live Tables.
Como um sistema de orquestração de fluxo de trabalho, os trabalhos do Azure Databricks também oferecem suporte a:
- Execução de trabalhos em uma base disparada, por exemplo, execução de um fluxo de trabalho em um agendamento.
- Análise de dados por meio de consultas SQL, aprendizado de máquina e análise de dados com notebooks, scripts ou bibliotecas externas, e assim por diante.
- Execução de um trabalho composto de uma única tarefa, por exemplo, execução de um trabalho do Apache Spark empacotado em um JAR.
Orquestração de fluxo de trabalho com o Apache AirFlow
Embora o Databricks recomende o uso de trabalhos do Azure Databricks para orquestrar fluxos de trabalho de dados, você também pode usar o Apache Airflow para gerenciar e programar seus fluxos de trabalho de dados. Com o Airflow, você define seu fluxo de trabalho em um arquivo Python, e o Airflow gerencia o agendamento e a execução do fluxo de trabalho. Confira Orquestrar trabalhos do Azure Databricks com o Apache Airflow.
Orquestração de fluxo de trabalho com o Azure Data Factory
O ADF (Azure Data Factory) é um serviço de integração de dados na nuvem que permite compor serviços de processamento, de movimentação e de armazenamento de dados em pipelines de dados automatizados. Você pode usar o ADF para orquestrar um trabalho do Azure Databricks como parte de um pipeline do ADF.
Para saber como executar um trabalho usando a atividade da Web do ADF, incluindo como autenticar no Azure Databricks do ADF, consulte Aproveitar a orquestração de trabalhos do Azure Databricks do Azure Data Factory.
O ADF também fornece suporte interno para executar notebooks do Databricks, scripts Python ou código empacotado em JARs em um pipeline do ADF.
Para saber como executar um notebook do Databricks em um pipeline do ADF, consulte Executar um notebook do Databricks com a atividade do notebook do Databricks no Azure Data Factory, seguido por Transformar dados executando um notebook do Databricks.
Para saber como executar um script Python em um pipeline do ADF, consulte Transformar dados executando uma atividade do Python no Azure Databricks.
Para saber como executar um pacote de códigos em JAR em um pipeline do ADF, consulte Transformar dados executando uma atividade JAR no Azure Databricks.