Introdução à avaliação de respostas em um aplicativo de bate-papo em JavaScript
Este artigo mostra como avaliar as respostas de um aplicativo de bate-papo em relação a um conjunto de respostas corretas ou ideais (conhecido como verdade básica). Sempre que você alterar seu aplicativo de bate-papo de uma forma que afete as respostas, execute uma avaliação para comparar as alterações. Este aplicativo de demonstração oferece ferramentas que você pode usar hoje para facilitar a execução de avaliações.
Seguindo as instruções neste artigo, você vai:
- Use prompts de exemplo fornecidos adaptados ao domínio do assunto. Estes já estão no repositório.
- Gere exemplos de perguntas de usuários e fundamente respostas verdadeiras a partir de seus próprios documentos.
- Execute avaliações usando um prompt de exemplo com as perguntas do usuário geradas.
- Análise de revisão das respostas.
Observação
Este artigo usa um ou mais modelos de aplicativo de IA como base para os exemplos e orientações no artigo. Os modelos de aplicativos de IA fornecem implementações de referência bem mantidas e fáceis de implantar que ajudam a garantir um ponto de partida de alta qualidade para seus aplicativos de IA.
Visão geral da arquitetura
Os principais componentes da arquitetura incluem:
- Aplicativo de bate-papo hospedado no Azure: o aplicativo de bate-papo é executado no Serviço de Aplicativo do Azure. O aplicativo de bate-papo está em conformidade com o protocolo de bate-papo, que permite que o aplicativo de avaliações seja executado em qualquer aplicativo de bate-papo que esteja em conformidade com o protocolo.
- Pesquisa de IA do Azure: o aplicativo de bate-papo usa a Pesquisa de IA do Azure para armazenar os dados de seus próprios documentos.
- Gerador de perguntas de exemplo: pode gerar um número de perguntas para cada documento, juntamente com a resposta de verdade básica. Quanto mais perguntas, maior a avaliação.
- O avaliador executa exemplos de perguntas e prompts no aplicativo de bate-papo e retorna os resultados.
- A ferramenta de revisão permite que você revise os resultados das avaliações.
- A ferramenta Diff permite comparar as respostas entre as avaliações.
Quando você implanta essa avaliação no Azure, o ponto de extremidade do Azure OpenAI é criado para o modelo GPT-4 com sua própria capacidade. Ao avaliar aplicativos de bate-papo, é importante que o avaliador tenha seu próprio recurso OpenAI usando GPT-4 com sua própria capacidade.
Pré-requisitos
Assinatura do Azure. Crie um gratuitamente
Acesso permitido ao OpenAI do Azure na assinatura do Azure desejada.
No momento, o acesso a esse serviço é permitido somente por aplicativo. Você pode solicitar acesso ao Serviço OpenAI do Azure preenchendo o formulário em https://aka.ms/oai/access.
Implantar um aplicativo de bate-papo
Esses aplicativos de chat carregam os dados no recurso de Pesquisa de IA do Azure. Esse recurso é necessário para que o aplicativo de avaliações funcione. Não conclua a seção Limpar recursos do procedimento anterior.
Você precisará das seguintes informações de recursos do Azure dessa implantação, que é conhecida como o aplicativo de bate-papo neste artigo:
- URI da API de bate-papo
azd up: o ponto de extremidade de back-end de serviço mostrado no final do processo. - IA do Azure Search. Os seguintes valores são necessários:
- Nome do recurso: o nome do recurso de Pesquisa de IA do Azure, relatado como
Search servicedurante oazd upprocesso. - Nome do índice: o nome do índice da Pesquisa de IA do Azure onde seus documentos estão armazenados. Isso pode ser encontrado no portal do Azure para o serviço de Pesquisa.
- Nome do recurso: o nome do recurso de Pesquisa de IA do Azure, relatado como
A URL da API de bate-papo permite que as avaliações façam solicitações por meio de seu aplicativo de back-end. As informações da Pesquisa de IA do Azure permitem que os scripts de avaliação usem a mesma implantação que seu back-end, carregado com os documentos.
Depois de ter essas informações coletadas, você não precisará usar o ambiente de desenvolvimento de aplicativo de bate-papo novamente. Ele é mencionado mais adiante neste artigo várias vezes para indicar como o aplicativo de bate-papo é usado pelo aplicativo Avaliações. Não exclua os recursos do aplicativo de bate-papo até concluir todo o procedimento neste artigo.
- URI da API de bate-papo
Um ambiente de contêiner de desenvolvimento está disponível com todas as dependências necessárias para concluir este artigo. Você pode executar o contêiner de desenvolvimento em Codespaces do GitHub (em um navegador) ou localmente usando o Visual Studio Code.
Abrir o ambiente de desenvolvimento
Comece agora com um ambiente de desenvolvimento que tenha todas as dependências instaladas para concluir este artigo. Você deve organizar seu espaço de trabalho do monitor para que possa ver essa documentação e o ambiente de desenvolvimento ao mesmo tempo.
Este artigo foi testado com a switzerlandnorth região para a implantação da avaliação.
O GitHub Codespaces executa um contêiner de desenvolvimento gerenciado pelo GitHub com o Visual Studio Code para Web como interface do usuário. Para o ambiente de desenvolvimento mais simples, use os Codespaces do GitHub para que você tenha as ferramentas e dependências de desenvolvedor corretas pré-instaladas para concluir este artigo.
Importante
Todas as contas do GitHub podem usar Codespaces por até 60 horas gratuitas por mês com 2 instâncias principais. Para saber mais, confira Armazenamento e horas por núcleo incluídos mensalmente no GitHub Codespaces.
Inicie o processo para criar um GitHub Codespace no branch
maindo repositório GitHubAzure-Samples/ai-rag-chat-evaluator.Clique com o botão direito do mouse no botão a seguir e selecione Abrir link em nova janela para ter o ambiente de desenvolvimento e a documentação disponíveis ao mesmo tempo.

Na página Criar codespace , analise as definições de configuração do codespace e selecione Criar novo codespace
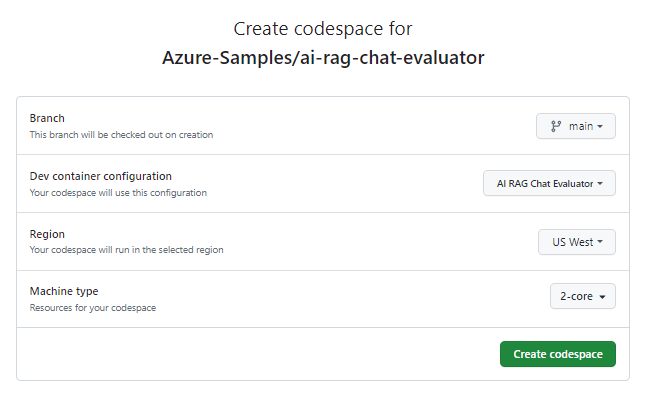
Aguarde até que o codespace seja iniciado. Esse processo de inicialização pode levar alguns minutos.
No terminal na parte inferior da tela, entre no Azure com o Azure Developer CLI.
azd auth login --use-device-codeCopie o código do terminal e cole-o em um navegador. Siga as instruções para autenticar com sua conta do Azure.
Provisione o recurso do Azure necessário, Azure OpenAI, para o aplicativo de avaliações.
azd upIsso não implanta o aplicativo de avaliações, mas cria o recurso Azure OpenAI com uma implantação GPT-4 necessária para executar as avaliações localmente no ambiente de desenvolvimento.
As tarefas restantes neste artigo ocorrem no contexto desse contêiner de desenvolvimento.
O nome do repositório do GitHub é mostrado na barra de pesquisa. Este indicador visual ajuda você a distinguir entre este aplicativo de avaliações do aplicativo de bate-papo. Esse
ai-rag-chat-evaluatorrepositório é conhecido como o aplicativo Avaliações neste artigo.

Preparar valores de ambiente e informações de configuração
Atualize os valores de ambiente e as informações de configuração com as informações coletadas durante os Pré-requisitos para o aplicativo de avaliações.
Use o comando a seguir para obter as informações de recurso do aplicativo Avaliações em um
.envarquivo:azd env get-values > .envAdicione os seguintes valores do aplicativo de bate-papo para sua instância de Pesquisa de IA do Azure ao
.env, que você reuniu na seção de pré-requisitos:AZURE_SEARCH_SERVICE="<service-name>" AZURE_SEARCH_INDEX="<index-name>"O
AZURE_SEARCH_KEYvalor é a chave de consulta para a instância de Pesquisa de IA do Azure.Crie um novo arquivo chamado
my_config.jsone copie o seguinte conteúdo para ele:{ "testdata_path": "my_input/qa.jsonl", "results_dir": "my_results/experiment<TIMESTAMP>", "target_url": "http://localhost:50505/chat", "target_parameters": { "overrides": { "semantic_ranker": false, "prompt_template": "<READFILE>my_input/prompt_refined.txt" } } }O script de avaliação cria a
my_resultspasta.Altere o
target_urlpara o valor de URI do seu aplicativo de bate-papo , que você reuniu na seção de pré-requisitos. O aplicativo de bate-papo deve estar em conformidade com o protocolo de bate-papo. O URI tem o seguinte formatohttps://CHAT-APP-URL/chat. Verifique se o protocolo e achatrota fazem parte do URI.
Gerar dados de exemplo
Para avaliar novas respostas, elas devem ser comparadas a uma resposta de "verdade básica", que é a resposta ideal para uma determinada pergunta. Gere perguntas e respostas a partir de documentos armazenados na Pesquisa de IA do Azure para o aplicativo de bate-papo.
Copie a
example_inputpasta para uma nova pasta nomeadamy_input.Em um terminal, execute o seguinte comando para gerar os dados de exemplo:
python3 -m scripts generate --output=my_input/qa.jsonl --numquestions=14 --persource=2
Os pares pergunta/resposta são gerados e armazenados ( my_input/qa.jsonl em formato JSNOL) como entrada para o avaliador usado na próxima etapa. Para uma avaliação de produção, você geraria mais pares de controle de qualidade, mais de 200 para esse conjunto de dados.
Observação
O pequeno número de perguntas e respostas por fonte destina-se a permitir que você conclua rapidamente este procedimento. Não é para ser uma avaliação de produção que deveria ter mais perguntas e respostas por fonte.
Executar a primeira avaliação com um prompt refinado
Edite as propriedades do
my_config.jsonarquivo de configuração:Propriedade Novo valor results_dir my_results/experiment_refinedprompt_template <READFILE>my_input/prompt_refined.txtO prompt refinado é específico sobre o domínio do assunto.
If there isn't enough information below, say you don't know. Do not generate answers that don't use the sources below. If asking a clarifying question to the user would help, ask the question. Use clear and concise language and write in a confident yet friendly tone. In your answers ensure the employee understands how your response connects to the information in the sources and include all citations necessary to help the employee validate the answer provided. For tabular information return it as an html table. Do not return markdown format. If the question is not in English, answer in the language used in the question. Each source has a name followed by colon and the actual information, always include the source name for each fact you use in the response. Use square brackets to reference the source, e.g. [info1.txt]. Don't combine sources, list each source separately, e.g. [info1.txt][info2.pdf].Em um terminal, execute o seguinte comando para executar a avaliação:
python3 -m scripts evaluate --config=my_config.json --numquestions=14Esse script criou uma nova pasta de experimentos com
my_results/a avaliação. A pasta contém os resultados da avaliação, incluindo:Nome do arquivo Descrição eval_results.jsonlCada pergunta e resposta, juntamente com as métricas GPT para cada par de QA. summary.jsonOs resultados gerais, como as métricas GPT médias.
Executar a segunda avaliação com um prompt fraco
Edite as propriedades do
my_config.jsonarquivo de configuração:Propriedade Novo valor results_dir my_results/experiment_weakprompt_template <READFILE>my_input/prompt_weak.txtEsse prompt fraco não tem contexto sobre o domínio do assunto:
You are a helpful assistant.Em um terminal, execute o seguinte comando para executar a avaliação:
python3 -m scripts evaluate --config=my_config.json --numquestions=14
Executar terceira avaliação com uma temperatura específica
Use um prompt que permita mais criatividade.
Edite as propriedades do
my_config.jsonarquivo de configuração:Existente Propriedade Novo valor Existente results_dir my_results/experiment_ignoresources_temp09Existente prompt_template <READFILE>my_input/prompt_ignoresources.txtNovo temperatura 0.9A temperatura padrão é 0,7. Quanto maior a temperatura, mais criativas são as respostas.
O prompt de ignorar é curto:
Your job is to answer questions to the best of your ability. You will be given sources but you should IGNORE them. Be creative!O objeto config deve gostar do seguinte, exceto usar o seu próprio
results_dir:{ "testdata_path": "my_input/qa.jsonl", "results_dir": "my_results/prompt_ignoresources_temp09", "target_url": "https://YOUR-CHAT-APP/chat", "target_parameters": { "overrides": { "temperature": 0.9, "semantic_ranker": false, "prompt_template": "<READFILE>my_input/prompt_ignoresources.txt" } } }Em um terminal, execute o seguinte comando para executar a avaliação:
python3 -m scripts evaluate --config=my_config.json --numquestions=14
Examinar os resultados da avaliação
Você executou três avaliações com base em diferentes prompts e configurações do aplicativo. Os resultados são armazenados na my_results pasta. Analise como os resultados diferem com base nas configurações.
Use a ferramenta de revisão para ver os resultados das avaliações:
python3 -m review_tools summary my_resultsOs resultados são algo como:

Cada valor é retornado como um número e uma porcentagem.
Use a tabela a seguir para entender o significado dos valores.
Valor Descrição Fundamentação Isso se refere a quão bem as respostas do modelo são baseadas em informações factuais e verificáveis. Uma resposta é considerada fundamentada se for factualmente precisa e refletir a realidade. Relevância Isso mede o quanto as respostas do modelo se alinham com o contexto ou o prompt. Uma resposta relevante aborda diretamente a consulta ou instrução do usuário. Coerência Isso se refere a quão logicamente consistentes são as respostas do modelo. Uma resposta coerente mantém um fluxo lógico e não se contradiz. Citação Isso indica se a resposta foi retornada no formato solicitado no prompt. Length Isso mede o comprimento da resposta. Os resultados devem indicar que todas as 3 avaliações tiveram alta relevância enquanto a
experiment_ignoresources_temp09teve a menor relevância.Selecione a pasta para ver a configuração para a avaliação.
Digite Ctrl + C, saia do aplicativo e retorne ao terminal.
Compare as respostas
Compare as respostas retornadas das avaliações.
Selecione duas das avaliações para comparar e, em seguida, use a mesma ferramenta de revisão para comparar as respostas:
python3 -m review_tools diff my_results/experiment_refined my_results/experiment_ignoresources_temp09Revise os resultados. Os resultados podem variar.

Digite Ctrl + C, saia do aplicativo e retorne ao terminal.
Sugestões para novas avaliações
- Edite os prompts para
my_inputpersonalizar as respostas, como domínio do assunto, comprimento e outros fatores. - Edite o
my_config.jsonarquivo para alterar os parâmetros comotemperatureesemantic_rankerexecutar experimentos novamente. - Compare respostas diferentes para entender como o prompt e a pergunta afetam a qualidade da resposta.
- Gere um conjunto separado de perguntas e respostas verdadeiras básicas para cada documento no índice de Pesquisa de IA do Azure. Em seguida, execute novamente as avaliações para ver como as respostas diferem.
- Altere os prompts para indicar respostas mais curtas ou mais longas adicionando o requisito ao final do prompt. Por exemplo,
Please answer in about 3 sentences.
Limpar os recursos
Limpar recursos do Azure
Os recursos do Azure criados neste artigo são cobrados para sua assinatura do Azure. Se você não espera precisar desses recursos no futuro, exclua-os para evitar incorrer em mais encargos.
Execute o seguinte comando do Azure Developer CLI para excluir os recursos do Azure e remover o código-fonte:
azd down --purge
Limpar GitHub Codespaces
A exclusão do ambiente GitHub Codespaces garante que você possa maximizar a quantidade de horas gratuitas por núcleo que você tem direito na sua conta.
Importante
Para saber mais sobre os direitos da sua conta do GitHub, confira O GitHub Codespaces inclui mensalmente armazenamento e horas de núcleo.
Entre no painel do GitHub Codespaces (https://github.com/codespaces).
Localize seus Codespaces atualmente em execução, originados do repositório
Azure-Samples/ai-rag-chat-evaluatordo GitHub.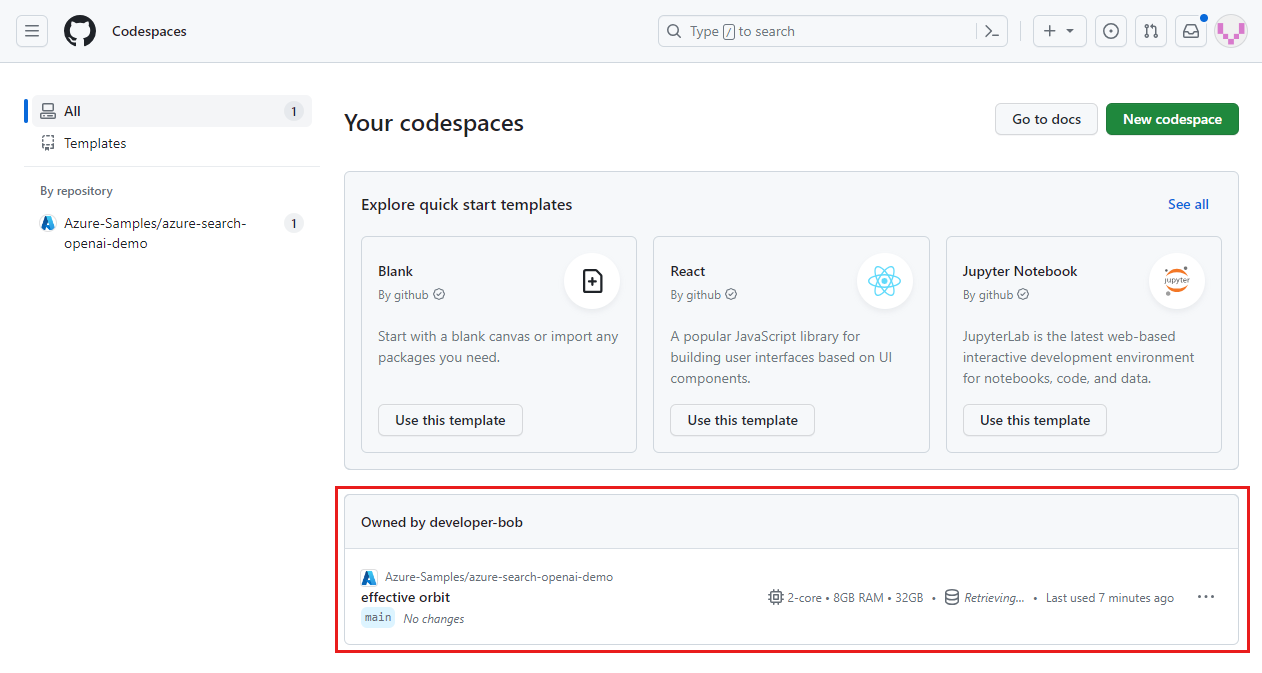
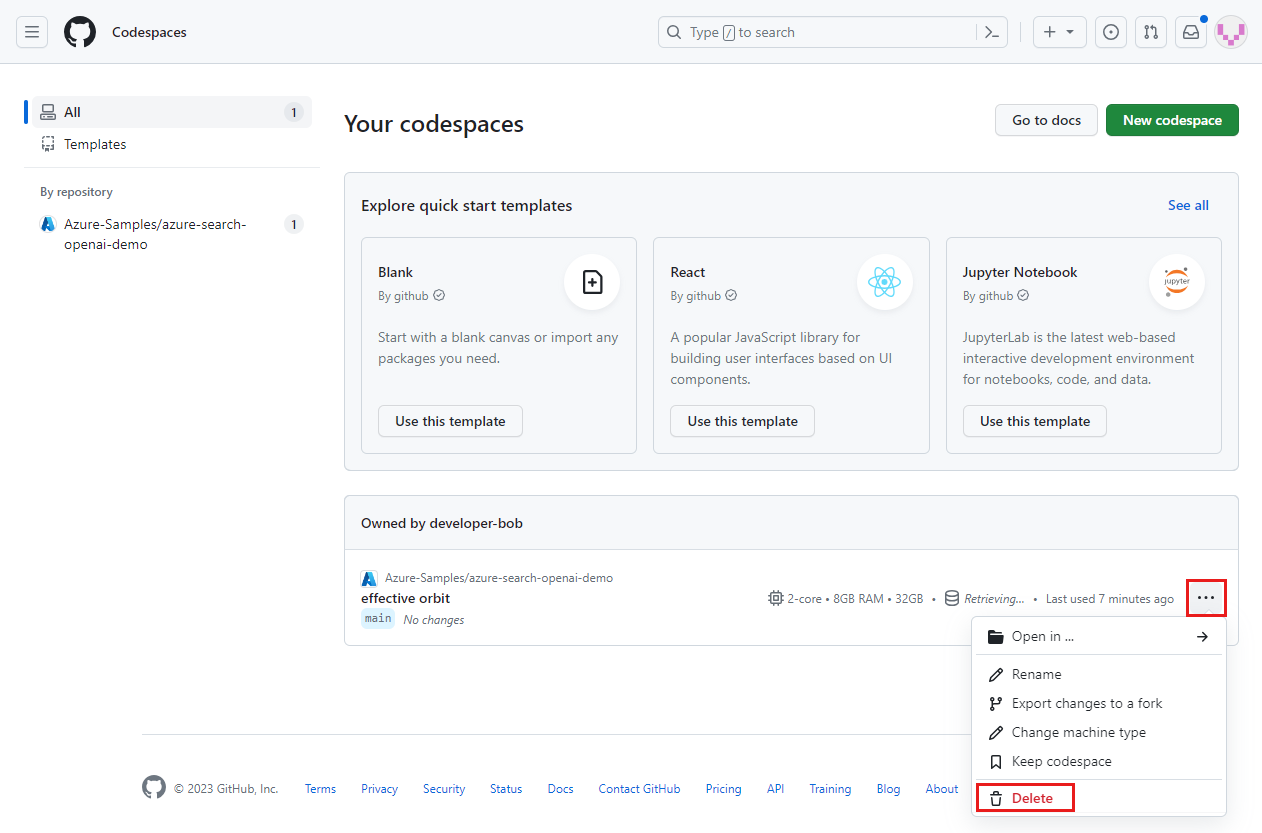
Abra o menu de contexto do codespace e selecione Excluir.
Retorne ao artigo do aplicativo de chat para limpar esses recursos.
Próximas etapas
- Repositório de avaliações
- Repositório GitHub do aplicativo de chat empresarial
- Criar um aplicativo de chat com a arquitetura de solução de práticas recomendadas do Azure OpenAI
- Controle de acesso em aplicativos de IA generativa com a Pesquisa de IA do Azure
- Criar uma solução OpenAI pronta para empresas com o Gerenciamento de API do Azure
- Superando a busca em vetores com recursos de recuperação e classificação híbridas
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de