Use o Apache Ambari Hive View com o Apache Hadoop no HDInsight
Saiba como executar as consultas do Hive usando o Apache Ambari Hive View. A Exibição do Hive permite que você crie, otimize e execute consultas de Hive do seu navegador da Web.
Pré-requisitos
Um cluster Hadoop no HDInsight. Consulte Introdução ao HDInsight no Linux.
Executar um trabalho do Hive
No portal do Azure, selecione o cluster. Veja Listar e mostrar clusters para obter instruções. O cluster é aberto em uma nova exibição do portal.
Em Painéis do cluster, selecione Exibições do Ambari. Quando solicitado a autenticar, use o nome e senha da conta de logon de cluster (padrão
admin) que você forneceu ao criar o cluster. Também é possível navegar atéhttps://CLUSTERNAME.azurehdinsight.net/#/main/viewsno navegador, em queCLUSTERNAMEé o nome do cluster.Na lista de exibições, selecione Exibição de Hive.
A página de exibição do Hive é semelhante à seguinte imagem:
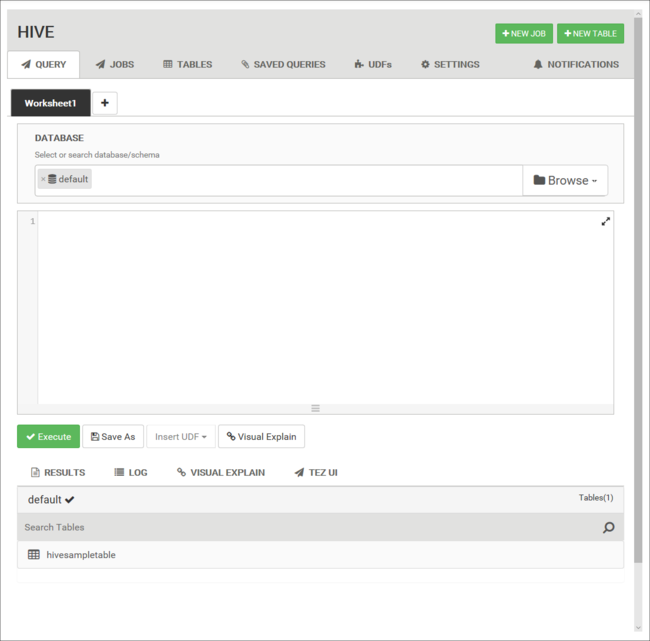
Da guia Consulta, cole as seguintes instruções HiveQL na planilha:
DROP TABLE log4jLogs; CREATE EXTERNAL TABLE log4jLogs( t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '/example/data/'; SELECT t4 AS loglevel, COUNT(*) AS count FROM log4jLogs WHERE t4 = '[ERROR]' GROUP BY t4;Essas instruções executam as seguintes ações:
Instrução Descrição DROP TABLE Exclui a tabela e o arquivo de dados, caso a tabela já exista. CREATE EXTERNAL TABLE Cria uma nova tabela "externa" no Hive. As tabelas externas armazenam apenas a definição da tabela no Hive. Os dados são mantidos no local original. FORMATO DA LINHA Mostra como os dados são formatados. Nesse caso, os campos em cada log são separados por um espaço. ARMAZENADO COMO ARQUIVO DE TEXTO LOCAL Mostra o local em que os dados são armazenados e se estão armazenados como texto. SELECT Seleciona uma contagem de todas as linhas em que a coluna t4 contém o valor [ERROR]. Importante
Deixe a seleção Banco de dados em padrão. Os exemplos neste documento usam o banco de dados padrão incluído no HDInsight.
Para iniciar a consulta, selecione Executar abaixo da planilha. O botão fica laranja e o texto é alterado para Parar.
Depois que a consulta for concluída, a seção Resultados exibirá os resultados da operação. O texto a seguir é o resultado da consulta:
loglevel count [ERROR] 3A guia LOG pode ser usada para exibir as informações de log criadas pelo trabalho.
Dica
Baixe ou salve os resultados na caixa de diálogo suspensa Ações na guia Resultados.
Explicações visuais
Para exibir uma visualização do plano de consulta, selecione a guia Explicações Visuais abaixo da planilha.
A visualização Explicações Visuais da consulta pode ser útil na compreensão do fluxo de consultas complexas.
Interface de usuário do Tez
Para exibir a interface do usuário do Tez para a consulta, selecione a guia IU Tez abaixo da planilha.
Importante
O Tez não é usado para resolver todas as consultas. Muitas consultas podem ser resolvidas sem usar o Tez.
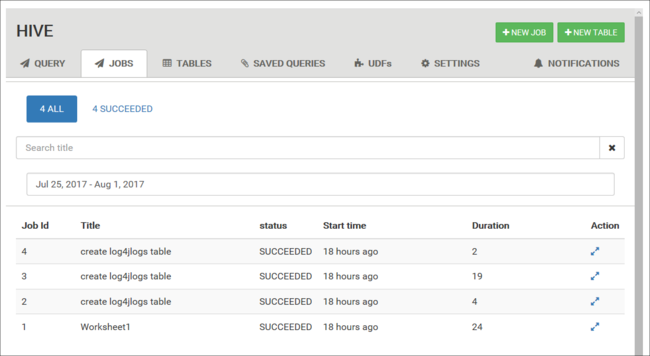
Exibir histórico de trabalho
A guia Trabalhos exibe um histórico das consultas de Hive.
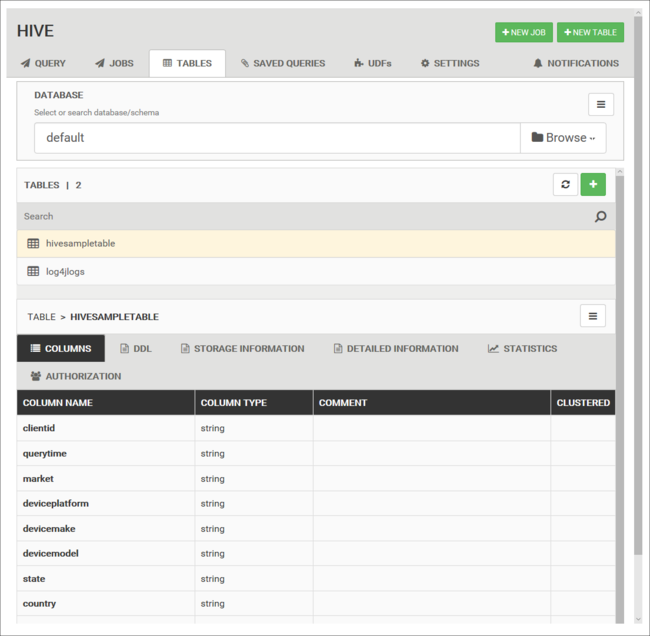
Tabelas de banco de dados
Você pode usar a guia tabelas para trabalhar com tabelas em um banco de dados de Hive.
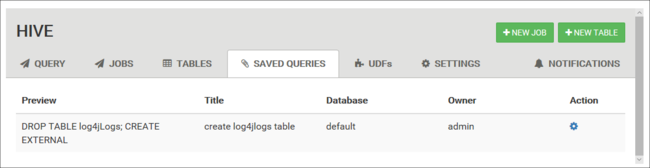
Consultas salvas
Na guia Consulta você pode, opcionalmente, salvar consultas. Depois de salvar uma consulta, você pode reutilizá-la da guia Consultas Salvas.
Dica
Consultas salvas são armazenadas no armazenamento de cluster padrão. Você pode encontrar as consultas salvas no caminho /user/<username>/hive/scripts. Elas são armazenadas como arquivos de texto sem formatação .hql.
Se você excluir o cluster, mas manter o armazenamento, pode usar um utilitário como o Gerenciador de Armazenamento do Microsoft Azure ou o Gerenciador de Armazenamento do Data Lake (do Portal do Azure) para recuperar as consultas.
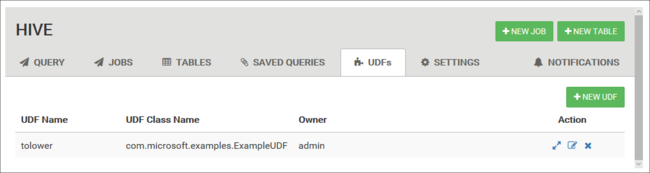
Funções definidas pelo usuário
O Hive pode ser estendido por meio de UDF (funções definidas pelo usuário). Use uma UDF para implementar funcionalidade ou lógica que não é facilmente modelada em HiveQL.
Declare e salve um conjunto de UDFs usando a guia UDF na parte superior da exibição do Hive. Essas UDFs podem ser usadas com o Editor de Consultas.
Um botão Inserir UDFs aparece na parte inferior do Editor de Consultas. Essa entrada mostra uma lista suspensa de UDFs definidas na Exibição do Hive. A seleção de uma UDF adiciona instruções HiveQL à sua consulta para habilitar a UDF.
Por exemplo, se você tiver definido uma UDF com as seguintes propriedades:
Nome de recurso: myudfs
Caminho do recurso: /myudfs.jar
Nome da UDF: myawesomeudf
Nome de classe da UDF: com.myudfs.Awesome
O uso do botão Inserir udfs exibe uma entrada denominada myudfs, com outra lista suspensa para cada UDF definida para esse recurso. Nesse caso, ela é myawesomeudf. A seleção dessa entrada adiciona o seguinte ao início da consulta:
add jar /myudfs.jar;
create temporary function myawesomeudf as 'com.myudfs.Awesome';
Você pode usar a UDF em sua consulta. Por exemplo, SELECT myawesomeudf(name) FROM people;.
Para saber mais sobre como usar UDFs com Hive no HDInsight, consulte os seguintes artigos:
- Usar o Python com Apache Hive e Apache Pig no HDInsight
- Usar um Java UDF com Apache Hive no HDInsight
Configurações do Hive
Você pode alterar diversas configurações do Hive, por exemplo, alterar o mecanismo de execução do Hive de Tez (o padrão) para MapReduce.
Próximas etapas
Para informações gerais sobre o Hive no HDInsight:
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de