O que é o Azure HDInsight?
O Azure HDInsight é um serviço de análise totalmente gerenciado, completo e open-source na nuvem para empresas. Com o HDInsight, você pode usar estruturas de código aberto, como Apache Spark, Apache Hive, LLAP, Apache Kafka, Hadoop e outros em seu ambiente do Azure.
O que é o HDInsight e a pilha de tecnologias do Hadoop?
O Azure HDInsight é uma plataforma de cluster gerenciado que facilita a execução de estruturas de Big Data, como Apache Spark, Apache Hive, LLAP, Apache Kafka, Apache Hadoop e outras no ambiente do Azure. Ele foi projetado para lidar com grandes volumes de dados com alta velocidade e eficiência.
Por que devo usar o Azure HDInsight?
| Funcionalidade | Descrição |
|---|---|
| Nativo de nuvem | O Azure HDInsight permite que você crie clusters otimizados para Spark, Interactive Query (LLAP), Kafka, HBase e Hadoop no Azure. O HDInsight também oferece um SLA de ponta a ponta em todas as suas cargas de trabalho de produção. |
| De baixo custo e escalonável | O HDInsight permite aumentar ou reduzir as cargas de trabalho. É possível reduzir os custos criando clusters sob demanda e pagando apenas pelo que for usado. Você também pode compilar pipelines de dados para operacionalizar seus trabalhos. A computação e o armazenamento desacoplados fornecem melhor desempenho e flexibilidade. |
| Seguro e em conformidade | O HDInsight permite proteger seus ativos de dados corporativos com a Rede Virtual do Azure, a criptografia e a integração com a ID do Microsoft Entra. O HDInsight também atende aos padrões de conformidade mais populares do setor e do governo. |
| Monitoramento | O Azure HDInsight é integrado aos logs do Azure Monitor para fornecer uma interface única com a qual você pode monitorar todos os seus clusters. |
| Disponibilidade global | O HDInsight está disponível em mais regiões do que qualquer outra oferta de análise de Big Data. O Azure HDInsight também está disponível no Azure Governamental, na China e na Alemanha, o que permite atender às necessidades da sua empresa nas principais áreas soberanas. |
| Produtividade | O Microsoft Azure HDInsight permite que você use ferramentas produtivas avançadas para o Hadoop e o Spark com seus ambientes de desenvolvimento preferidos. Esses ambientes de desenvolvimento incluem o Visual Studio, o VS Code, o Eclipse e o IntelliJ para Scala, Python, Java e suporte ao .NET. |
| Extensibilidade | Você pode estender os clusters do HDInsight com componentes instalados (Hue, Presto, etc.) usando ações de script, adicionando nós de borda ou integrando outros aplicativos de Big Data certificados. O HDInsight permite a integração perfeita com as soluções de Big Data mais populares com uma implantação com um clique. |
O que é big data?
Mais do que nunca, o Big Data está sendo coletado em volumes crescentes, em velocidades mais altas e em uma maior variedade de formatos. Ele pode ser histórico (referente a dados armazenados) ou em tempo real (o que significa que é transmitido da fonte). Consulte Cenários de uso do HDInsight para saber mais sobre os casos de uso mais comuns de Big Data.
Tipos de cluster no HDInsight
O HDInsight inclui tipos específicos de cluster e recursos de personalização do cluster, como a capacidade de adicionar componentes, utilitários e idiomas. O HDInsight oferece os seguintes tipos de cluster:
| Tipo de cluster | Descrição | Começar agora |
|---|---|---|
| Apache Hadoop | uma estrutura que usa HDFS, gerenciamento de recursos YARN e um modelo de programação MapReduce simples para processar e analisar dados em lote em paralelo. | Criar um cluster do Apache Hadoop |
| Apache Spark | uma estrutura de processamento paralelo de software livre que dá suporte ao processamento na memória para melhorar o desempenho dos aplicativos de análise de Big Data. Confira O que é o Apache Spark no HDInsight?. | Criar um cluster do Apache Spark |
| HBase no Apache | um banco de dados NoSQL baseado em Hadoop que fornece acesso aleatório e coerência forte para big data não estruturado e semiestruturado (potencialmente, bilhões de linhas vezes milhões de colunas). Confira O que é o HBase em HDInsight? | Criar um cluster do Apache HBase |
| Consulta Interativa do Apache | Caching na memória para consultas de Hive interativas e mais rápidas. Veja Usar a consulta interativa no HDInsight. | Criar um cluster de Consulta Interativa |
| Apache Kafka | Uma plataforma de software livre é usada para criar pipelines e aplicativos de dados de streaming. O Kafka também fornece funcionalidade de fila de mensagens, o que permite que você publique e assine fluxos de dados. Consulte Uma introdução ao Apache Kafka no HDInsight. | Criar um cluster do Apache Kafka |
Cenários de uso do HDInsight
O Azure HDInsight pode ser usado em vários cenários no processamento de Big Data. Estes podem ser dados históricos (dados que já são coletados e armazenados) ou dados em tempo real (dados que são transmitidos diretamente da origem). Os cenários para processar esses dados podem ser resumidos nas seguintes categorias:
Processamento em lotes (ETL)
Extração, transformação e carregamento (ETL) é um processo em que os dados estruturados ou não estruturados são extraídos de fontes de dados heterogêneas. Em seguida, ele é transformado em um formato estruturado e carregado no repositório de dados. Você pode usar os dados transformados para ciência de dados ou data warehousing.
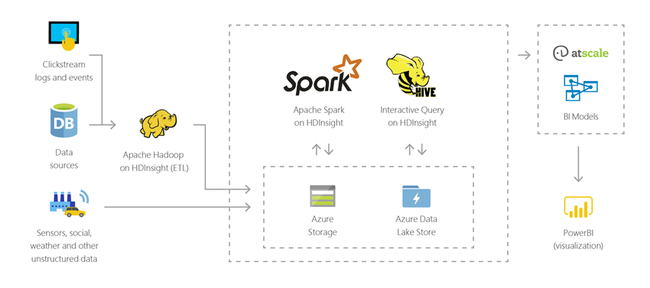
Data warehousing
É possível usar o HDInsight para executar consultas interativas em escalas petabyte sobre dados estruturados ou não estruturados em qualquer formato. Também é possível criar modelos conectando-os a ferramentas de BI.
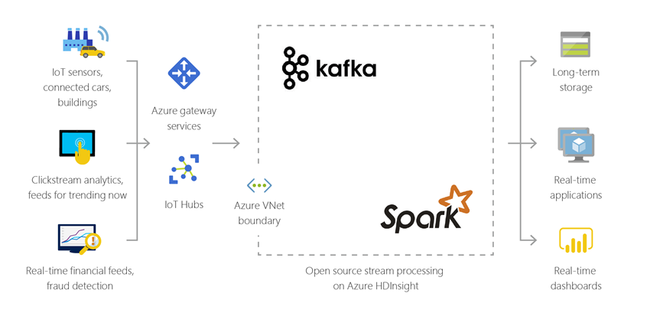
Internet das coisas (IoT)
Você pode usar o HDInsight para processar dados de streaming recebidos em tempo real de diferentes tipos de dispositivos. Para obter mais informações, leia esta postagem de blog do Azure que informa a visualização pública do Apache Kafka no HDInsight com Azure Managed Disks.
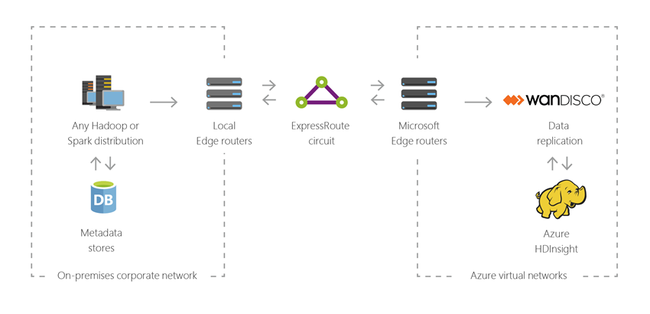
Híbrido
Você pode usar o HDInsight para estender sua infraestrutura de Big Data local existente ao Azure para aplicar os recursos de análise avançada da nuvem.
Componentes de código aberto no HDInsight
O Azure HDInsight permite que você crie clusters com estruturas de software livre como Spark, Hive, LLAP, Kafka, Hadoop e HBase. Por padrão, esses clusters incluem vários componentes de software livre, como Apache Ambari, Avro, Apache Hive 3, HCatalog, Apache Hadoop MapReduce, Apache Hadoop YARN, Apache Phoenix, Apache Pig, Apache Sqoop, Apache Tez, Apache Oozie e Apache ZooKeeper.
Linguagens de programação no HDInsight
Os clusters do HDInsight, incluindo Spark, HBase, Kafka, Hadoop e outros, dão suporte a várias linguagens de programação. Algumas linguagens de programação não são instaladas por padrão. No caso de bibliotecas, módulos ou pacotes que não são instalados por padrão, use uma ação de script para instalar o componente.
| Linguagem de programação | Informações |
|---|---|
| Suporte padrão à linguagem de programação | Por padrão, os clusters HDInsight são compatíveis com:
|
| Linguagens JVM (máquina virtual Java) | Muitas linguagens diferentes do Java podem ser executadas em uma máquina virtual do Java (JVM). No entanto, se você executar algumas dessas linguagens, talvez precise instalar mais componentes no cluster. As seguintes linguagens baseadas em JVM são permitidas nos clusters HDInsight:
|
| Linguagens específicas do Hadoop | Os clusters HDInsight dão suporte às seguintes linguagens que são específicas ao ecossistema da pilha de tecnologias do Hadoop:
|
Ferramentas de desenvolvimento para HDInsight
Você pode usar ferramentas de desenvolvimento do HDInsight, incluindo IntelliJ, Eclipse, Visual Studio Code e Visual Studio, para criar e enviar a consulta de dados do HDInsight e o trabalho com integração perfeita com o Azure.
- Kit de ferramentas do Azure para IntelliJ 10
- Kit de ferramentas do Azure para Eclipse 6
- Ferramentas do Azure HDInsight para VS Code 13
- Ferramentas do Azure Data Lake para Visual Studio 9
Business intelligence no HDInsight
As ferramentas familiares de BI (business intelligence) recuperam, analisam e relatam os dados que estão integrados ao HDInsight usando o suplemento Power Query ou o Driver ODBC do Microsoft Hive:
Apache Spark BI usando ferramentas de visualização de dados com o Azure HDInsight
Visualize dados do Apache Hive com o Microsoft Power BI no Azure HDInsight
Visualizar dados da consulta interativa do Hive com o Power BI no Azure HDInsight
Conectar o Excel ao Apache Hadoop com o Power Query (requer Windows)
Conectar o Excel ao Apache Hadoop com o Driver ODBC do Microsoft Hive (requer Windows)
Residência de dados na região
O Spark, o Hadoop e o LLAP não armazenam dados do cliente, portanto, esses serviços atendem automaticamente aos requisitos de residência de dados na região especificados na Central de confiabilidade.
O Kafka e o HBase armazenam dados do cliente. Esses dados são armazenados automaticamente pelo Kafka e pelo HBase em uma única região, portanto, esse serviço atende aos requisitos de residência de dados na região especificados na Central de Confiabilidade.
As ferramentas conhecidas de BI (business intelligence) recuperam, analisam e relatam os dados integrados ao HDInsight usando o suplemento Power Query ou o Driver ODBC do Microsoft Hive.
Próximas etapas
- Criar cluster do Apache Hadoop no HDInsight
- Criar o cluster do Apache Spark – Portal
- Segurança empresarial no Azure HDInsight