Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Saiba como conectar um cluster Apache Spark no Azure HDInsight com o Banco de Dados SQL do Azure. Em seguida, leia, grave e transmita dados para o banco de dados SQL. As instruções neste artigo usam um Jupyter Notebook para executar os trechos de código do Scala. No entanto, você pode criar um aplicativo autônomo em Scala ou Python e realizar as mesmas tarefas.
Pré-requisitos
Cluster do Azure HDInsight Spark. Siga as instruções em Criar um cluster do Apache Spark no HDInsight .
Banco de Dados SQL do Azure. Siga as instruções em Criar um banco de dados no Banco de Dados SQL do Azure. Certifique-se de criar um banco de dados com o esquema e dados AdventureWorksLT de exemplo. Além disso, certifique-se de criar uma regra de firewall no nível do servidor para permitir que o endereço IP do seu cliente acesse o banco de dados SQL. As instruções para adicionar a regra de firewall estão disponíveis no mesmo artigo. Após criar seu banco de dados SQL, certifique-se de manter os seguintes valores acessíveis. Esses valores serão necessários para se conectar ao banco de dados de um cluster Spark.
- Nome de servidor.
- nome do banco de dados.
- Nome de usuário/senha do administrador do Banco de Dados SQL do Azure.
SSMS (SQL Server Management Studio). Siga as instruções em Usar SSMS para conectar e consultar dados.
Criará um Jupyter Notebook
Comece criando um Jupyter Notebook associado ao cluster do Spark. Você usa esse notebook para executar os snippets de código usados neste artigo.
- Do portal do Azure, abra o seu cluster.
- Selecione o Jupyter Notebook abaixo dos Painéis do cluster no lado direito. Se você não ver Painéis do cluster, selecione Visão geral no menu à esquerda. Se você receber uma solicitação, insira as credenciais de administrador para o cluster.
Observação
Também é possível acessar o Jupyter Notebook no cluster Spark, abrindo a seguinte URL no seu navegador. Substitua CLUSTERNAME pelo nome do cluster:
https://CLUSTERNAME.azurehdinsight.net/jupyter
- No Jupyter Notebook, no canto superior direito, clique em Novo e em Spark para criar um notebook Scala. Os Jupyter Notebooks no cluster do HDInsight Spark também fornecem o kernel PySpark para aplicativos Python2 e o kernel PySpark3 para aplicativos Python3. Para este artigo, criamos um notebook Scala.
Para saber mais sobre os kernels, confira Usar kernels do Jupyter Notebook com clusters do Apache Spark no HDInsight.
Observação
Neste artigo, usamos um kernel (Scala) Spark porque atualmente os dados de streaming do Spark no Banco de Dados SQL têm suporte apenas em Scala e Java. Embora a leitura e gravação em SQL possam ser feitas usando o Python, visando manter a consistência neste artigo nós usamos o Scala para todas as três operações.
Um novo notebook abre com o nome padrão, Sem título. Clique no nome do notebook e insira o nome de sua escolha.
Agora, você pode iniciar a criação do seu aplicativo.
Leitura dos dados do Banco de Dados SQL do Azure
Nesta seção, você faz a leitura dos dados de uma tabela (por exemplo, SalesLT.Address) que existe no banco de dados AdventureWorks.
Em um novo Jupyter Notebook, em uma célula de código, cole o seguinte trecho de código e substitua os valores de espaço reservados pelos valores para seu banco de dados.
// Declare the values for your database val jdbcUsername = "<SQL DB ADMIN USER>" val jdbcPassword = "<SQL DB ADMIN PWD>" val jdbcHostname = "<SQL SERVER NAME HOSTING SDL DB>" //typically, this is in the form or servername.database.windows.net val jdbcPort = 1433 val jdbcDatabase ="<AZURE SQL DB NAME>"Pressione SHIFT + ENTER para executar a célula de código.
Use o trecho a seguir para criar uma URL JDBC que você pode passar para as APIs do dataframe do Spark. O código cria um objeto
Propertiespara manter os parâmetros. Cole o snippet de código a seguir em uma célula de código e pressione SHIFT+ENTER para executar.import java.util.Properties val jdbc_url = s"jdbc:sqlserver://${jdbcHostname}:${jdbcPort};database=${jdbcDatabase};encrypt=true;trustServerCertificate=false;hostNameInCertificate=*.database.windows.net;loginTimeout=60;" val connectionProperties = new Properties() connectionProperties.put("user", s"${jdbcUsername}") connectionProperties.put("password", s"${jdbcPassword}")Use o trecho a seguir para criar um quadro de dados com os dados de uma tabela no seu banco de dados. Neste trecho, usamos uma tabela
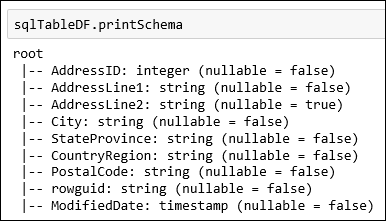
SalesLT.Addressque está disponível como parte do banco de dados AdventureWorksLT. Cole o snippet de código a seguir em uma célula de código e pressione SHIFT+ENTER para executar.val sqlTableDF = spark.read.jdbc(jdbc_url, "SalesLT.Address", connectionProperties)Agora, é possível executar operações no dataframe, como para obter o esquema de dados:
sqlTableDF.printSchemaVocê verá uma saída semelhante à seguinte imagem:
Também é possível executar operações como recuperar as 10 primeiras filas.
sqlTableDF.show(10)Ou, recuperar colunas específicas do conjunto de dados.
sqlTableDF.select("AddressLine1", "City").show(10)
Gravação de dados no Banco de Dados SQL do Azure
Nesta seção, usamos um arquivo CSV de exemplo disponível no cluster para criar uma tabela no banco de dados e preenchê-lo com dados. O arquivo CSV de exemplo (HVAC.csv) está disponível em todos os clusters HDInsight em HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv.
Em um novo Jupyter Notebook, em uma célula de código, cole o seguinte trecho de código e substitua os valores de espaço reservados pelos valores para seu banco de dados.
// Declare the values for your database val jdbcUsername = "<SQL DB ADMIN USER>" val jdbcPassword = "<SQL DB ADMIN PWD>" val jdbcHostname = "<SQL SERVER NAME HOSTING SDL DB>" //typically, this is in the form or servername.database.windows.net val jdbcPort = 1433 val jdbcDatabase ="<AZURE SQL DB NAME>"Pressione SHIFT + ENTER para executar a célula de código.
O trecho a seguir compila uma URL JDBC que você pode passar para as APIs do dataframe do Spark. O código cria um objeto
Propertiespara manter os parâmetros. Cole o snippet de código a seguir em uma célula de código e pressione SHIFT+ENTER para executar.import java.util.Properties val jdbc_url = s"jdbc:sqlserver://${jdbcHostname}:${jdbcPort};database=${jdbcDatabase};encrypt=true;trustServerCertificate=false;hostNameInCertificate=*.database.windows.net;loginTimeout=60;" val connectionProperties = new Properties() connectionProperties.put("user", s"${jdbcUsername}") connectionProperties.put("password", s"${jdbcPassword}")Use o snippet de código abaixo para extrair o esquema dos dados em HVAC.csv e usar o esquema para carregar os dados do CSV em um dataframe,
readDf. Cole o snippet de código a seguir em uma célula de código e pressione SHIFT+ENTER para executar.val userSchema = spark.read.option("header", "true").csv("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv").schema val readDf = spark.read.format("csv").schema(userSchema).load("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv")Use o dataframe
readDfpara criar uma tabela temporária,temphvactable. Em seguida, use a tabela temporária para criar uma tabela de hive,hvactable_hive.readDf.createOrReplaceTempView("temphvactable") spark.sql("create table hvactable_hive as select * from temphvactable")Por fim, use a tabela de hive para criar uma tabela no banco de dados. O trecho a seguir cria
hvactableno Banco de Dados SQL do Azure.spark.table("hvactable_hive").write.jdbc(jdbc_url, "hvactable", connectionProperties)Conecte-se ao Banco de Dados SQL do Azure usando SSMS e verifique se há um
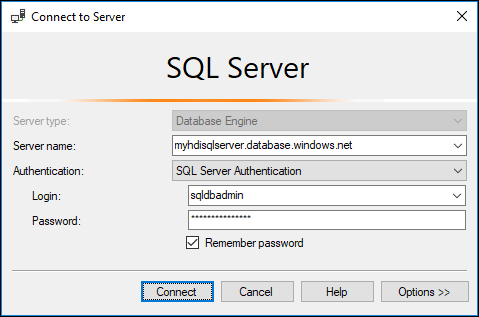
dbo.hvactable.a. Inicie o SSMS e conecte ao Banco de Dados SQL do Azure fornecendo os detalhes da conexão, conforme mostrado na captura de tela a seguir.
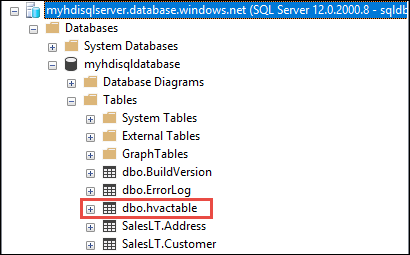
b. No Pesquisador de Objetos, expanda o banco de dados e o nó da tabela para ver o dbo.hvactable criado.
Execute uma consulta no SSMS para ver as colunas na tabela.
SELECT * from hvactable
Transmitir dados no Banco de Dados SQL do Azure
Nesta seção, transmitimos dados para o hvactable que você criou na seção anterior.
Como primeira etapa, verifique se não há registros no
hvactable. Usando SSMS, execute a seguinte consulta na tabela.TRUNCATE TABLE [dbo].[hvactable]Crie um novo Jupyter Notebook no cluster do HDInsight Spark. Em uma célula de código, cole o seguinte snippet de código e, em seguida, pressione SHIFT + ENTER:
import org.apache.spark.sql._ import org.apache.spark.sql.types._ import org.apache.spark.sql.functions._ import org.apache.spark.sql.streaming._ import java.sql.{Connection,DriverManager,ResultSet}Transmitimos os dados do HVAC.csv para o
hvactable. O arquivo HVAC.csv está disponível no cluster em/HdiSamples/HdiSamples/SensorSampleData/HVAC/. No snippet de código a seguir, primeiro recebemos o esquema dos dados a serem transmitidos. Em seguida, criamos um dataframe de transmissão usando esse esquema. Cole o snippet de código a seguir em uma célula de código e pressione SHIFT+ENTER para executar.val userSchema = spark.read.option("header", "true").csv("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv").schema val readStreamDf = spark.readStream.schema(userSchema).csv("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/") readStreamDf.printSchemaA saída mostra o esquema de HVAC.csv. O
hvactabletambém tem o mesmo esquema. A saída lista as colunas na tabela.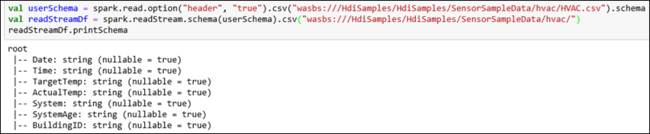
Por fim, use o seguinte trecho para a leitura dos dados do HVAC.csv e transmita-o para o
hvactableno seu banco de dados. Cole o trecho em uma célula de código, substitua os valores de espaço reservado pelos valores do seu banco de dados e pressione SHIFT + ENTER para executar.val WriteToSQLQuery = readStreamDf.writeStream.foreach(new ForeachWriter[Row] { var connection:java.sql.Connection = _ var statement:java.sql.Statement = _ val jdbcUsername = "<SQL DB ADMIN USER>" val jdbcPassword = "<SQL DB ADMIN PWD>" val jdbcHostname = "<SQL SERVER NAME HOSTING SDL DB>" //typically, this is in the form or servername.database.windows.net val jdbcPort = 1433 val jdbcDatabase ="<AZURE SQL DB NAME>" val driver = "com.microsoft.sqlserver.jdbc.SQLServerDriver" val jdbc_url = s"jdbc:sqlserver://${jdbcHostname}:${jdbcPort};database=${jdbcDatabase};encrypt=true;trustServerCertificate=false;hostNameInCertificate=*.database.windows.net;loginTimeout=30;" def open(partitionId: Long, version: Long):Boolean = { Class.forName(driver) connection = DriverManager.getConnection(jdbc_url, jdbcUsername, jdbcPassword) statement = connection.createStatement true } def process(value: Row): Unit = { val Date = value(0) val Time = value(1) val TargetTemp = value(2) val ActualTemp = value(3) val System = value(4) val SystemAge = value(5) val BuildingID = value(6) val valueStr = "'" + Date + "'," + "'" + Time + "'," + "'" + TargetTemp + "'," + "'" + ActualTemp + "'," + "'" + System + "'," + "'" + SystemAge + "'," + "'" + BuildingID + "'" statement.execute("INSERT INTO " + "dbo.hvactable" + " VALUES (" + valueStr + ")") } def close(errorOrNull: Throwable): Unit = { connection.close } }) var streamingQuery = WriteToSQLQuery.start()Verifique se os dados estão sendo transmitidos para o
hvactableexecutando a seguinte consulta no SSMS (SQL Server Management Studio). Toda vez que você executa a consulta, ele mostra o número de linhas na tabela aumentando.SELECT COUNT(*) FROM hvactable