Solucionar problemas do Apache Spark usando o Azure HDInsight
Saiba mais sobre os principais problemas e suas soluções ao trabalhar com cargas de Apache Spark no Apache Ambari.
Como fazer para configurar um aplicativo Apache Spark usando o Ambari nos clusters?
Os valores de configuração do Spark podem ser ajustados para ajudar a evitar uma exceção OutofMemoryError do aplicativo do Apache Spark. As seguintes etapas mostram os valores de configuração padrão do Spark no Azure HDInsight:
Faça logon no Ambari em
https://CLUSTERNAME.azurehdidnsight.netusando suas credenciais do cluster. A tela inicial exibe um painel de visão geral. Existem pequenas diferenças de caráter estético com relação ao HDInsight 4.0.Navegue até configurações>do Spark2.
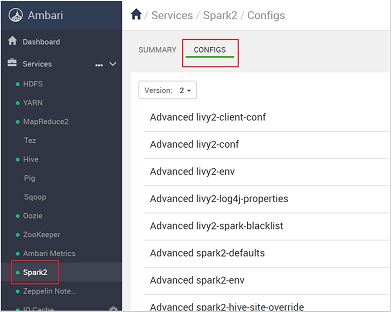
Na lista de configurações, escolha e expanda Custom-spark2-defaults.
Procure a configuração do valor que você precisa ajustar, como spark.executor.memory. Nesse caso, o valor de 9728m é alto demais.
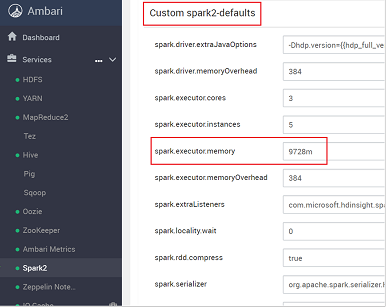
Defina o valor para a configuração recomendada. O valor de 2048m é recomendado para essa configuração.
Salve o valor e, em seguida, salve a configuração. Selecione Salvar.
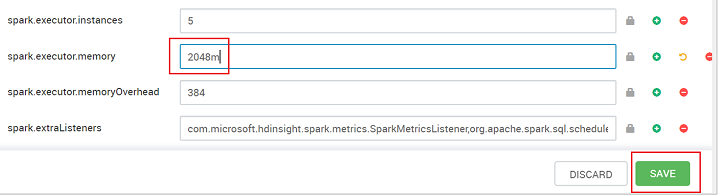
Escreva uma observação sobre as alterações de configuração e selecione Salvar.
Você será notificado se alguma configuração requerer atenção. Observe os itens e, em seguida, selecione Continuar Assim Mesmo.

Sempre que uma configuração é salva, você é solicitado a reiniciar o serviço. Selecione Reiniciar.
Confirme a reinicialização.
Você pode examinar os processos em execução.
Você pode adicionar configurações. Na lista de configurações, selecione Custom-spark2-defaults e, em seguida, selecione Adicionar Propriedade.
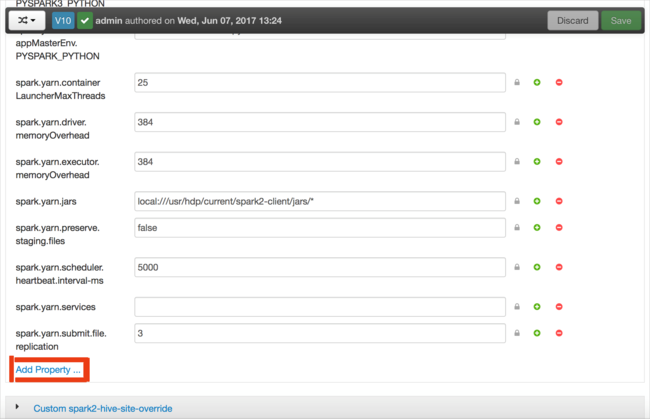
Defina uma nova propriedade. Você pode definir uma única propriedade usando uma caixa de diálogo para configurações específicas, como o tipo de dados. Ou você pode definir várias propriedades usando uma definição por linha.
Neste exemplo, a propriedade spark.driver.memory é definida com um valor de 4g.
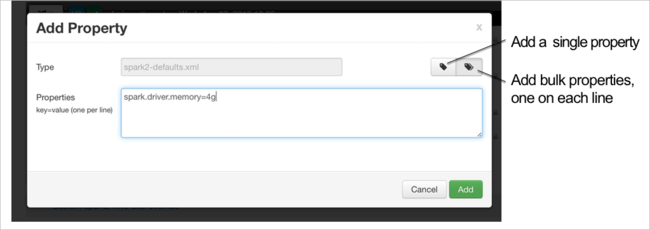
Salve a configuração e, em seguida, reinicie o serviço conforme descrito nas etapas 6 e 7.
Essas alterações valem para todo o cluster, mas podem ser substituídas quando você enviar o trabalho do Spark.
Como fazer para configurar um aplicativo Apache Spark usando um Jupyter Notebook nos clusters?
Na primeira célula do Jupyter Notebook, após a diretiva %%configure, especifique as configurações do Spark em um formato JSON válido. Altere os valores reais conforme necessário:

Como fazer para configurar um aplicativo Apache Spark usando o Apache Livy nos clusters?
Envie o aplicativo Spark ao Livy usando um cliente REST, como cURL. Use um comando semelhante ao seguinte. Altere os valores reais conforme necessário:
curl -k --user 'username:password' -v -H 'Content-Type: application/json' -X POST -d '{ "file":"wasb://container@storageaccountname.blob.core.windows.net/example/jars/sparkapplication.jar", "className":"com.microsoft.spark.application", "numExecutors":4, "executorMemory":"4g", "executorCores":2, "driverMemory":"8g", "driverCores":4}'
Como fazer para configurar um aplicativo Apache Spark usando o envio spark nos clusters?
Inicie o shell do Spark usando um comando semelhante ao seguinte. Altere o valor real das configurações conforme necessário:
spark-submit --master yarn-cluster --class com.microsoft.spark.application --num-executors 4 --executor-memory 4g --executor-cores 2 --driver-memory 8g --driver-cores 4 /home/user/spark/sparkapplication.jar
Leituras adicionais
Envio de trabalho do Apache Spark em clusters do HDInsight
Próximas etapas
Se você não encontrou seu problema ou não conseguiu resolver seu problema, visite um dos seguintes canais para obter mais suporte:
Obtenha respostas de especialistas do Azure por meio do Suporte da Comunidade do Azure.
Conecte-se com @AzureSupport – a conta oficial do Microsoft Azure para aprimorar a experiência do cliente. Como se conectar à comunidade do Azure para os recursos certos: respostas, suporte e especialistas.
Se precisar de mais ajuda, poderá enviar uma solicitação de suporte do portal do Azure. Selecione Suporte na barra de menus ou abra o hub Ajuda + suporte. Para obter informações mais detalhadas, consulte Como criar uma solicitação de Suporte do Azure. O acesso ao Gerenciamento de assinaturas e ao suporte de cobrança está incluído na sua assinatura do Microsoft Azure, e o suporte técnico é fornecido por meio de um dos Planos de suporte do Azure.