Tutorial 2: treinar modelos de risco de crédito – Machine Learning Studio (clássico)
APLICA-SE A: Machine Learning Studio (clássico)
Machine Learning Studio (clássico)  Azure Machine Learning
Azure Machine Learning
Importante
O suporte para o Machine Learning Studio (clássico) terminará em 31 de agosto de 2024. É recomendável fazer a transição para o Azure Machine Learning até essa data.
A partir de 1º de dezembro de 2021, você não poderá criar recursos do Machine Learning Studio (clássico). Até 31 de agosto de 2024, você pode continuar usando os recursos existentes do Machine Learning Studio (clássico).
- Confira informações sobre como mover projetos de machine learning do ML Studio (clássico) para o Azure Machine Learning.
- Saiba mais sobre o Azure Machine Learning
A documentação do ML Studio (clássico) está sendo desativada e pode não ser atualizada no futuro.
Neste tutorial, você analisará de maneira aprofundada o processo de desenvolvimento de uma solução de análise preditiva. Você desenvolverá um modelo simples no Machine Learning Studio (clássico). Em seguida, você implantará o modelo como um serviço Web do Machine Learning. Esse modelo implantado pode fazer previsões usando novos dados. Este tutorial é a segunda parte de uma série de tutoriais de três partes.
Suponha que você precisa prever o risco de crédito de uma pessoa com base nas informações dadas em um aplicativo de crédito.
A avaliação de risco de crédito é um problema complexo, mas este tutorial simplificará um pouco esse tópico. Você usará isso como exemplo da forma de criar uma solução de análise preditiva usando o Machine Learning Studio (clássico). Você usará o Machine Learning Studio (clássico) e um serviço Web do Machine Learning para esta solução.
Neste tutorial de três partes, você começará com os dados de risco de crédito disponíveis publicamente. Em seguida, você desenvolverá e treinará um modelo preditivo. Por fim, você implantará o modelo como um serviço Web.
Na primeira parte do tutorial, você criou um workspace do Machine Learning Studio (clássico), carregou dados e criou um experimento.
Nesta parte do tutorial, você vai:
- Treinar vários modelos
- Pontuar e avaliar os modelos
Na terceira parte do tutorial, você implantará o modelo como um serviço Web.
Pré-requisitos
Conclusão da primeira parte do tutorial.
Treinar vários modelos
Uma das vantagens de usar o Machine Learning Studio (clássico) para criar modelos de machine learning é a capacidade de experimentar mais de um tipo de modelo de cada vez em um teste e comparar os resultados. Esse tipo de experimentação ajuda a encontrar a melhor solução para seu problema.
No experimento que estamos desenvolvendo neste tutorial, você criará dois tipos diferentes de modelos e, em seguida, comparará os resultados de suas pontuações para decidir qual algoritmo desejará usar em nosso experimento final.
Existem diversos modelos dentre os quais você poderá escolher. Para ver os modelos disponíveis, expanda o nó Machine Learning na paleta do módulo e expanda Inicializar Modelo e os nós abaixo dele. Para os fins deste experimento, você selecionará os módulos SVM (Computador de Vetor de Suporte) de Duas Classes e Árvore de Decisão Aumentada de Duas Classes.
Você adicionará os módulos Árvore de Decisão Aumentada de Duas Classes e Computador de Vetor de Suporte de Duas Classes neste experimento.
Árvore de decisão aumentada em duas classes
Primeiro, configure o modelo de árvore de decisão aumentada.
Localize o módulo Árvore de Decisão Aumentada de Duas Classes na paleta do módulo e arraste-o para a tela.
Localize o módulo Modelo de Treinamento, arraste-o até a tela e depois conecte a saída do módulo Árvore de Decisão Aumentada de Duas Classes à porta de entrada esquerda do módulo Modelo de Treinamento.
O módulo Árvore de Decisão Aumentada de Duas Classes inicializa o modelo genérico e o Treinar Modelo usa os dados de treinamento para treinar o modelo.
Conecte a saída esquerda do módulo esquerdo Executar Script R à porta de entrada direita do módulo Treinar Modelo (neste tutorial, você usou os dados provenientes do lado esquerdo do módulo Dividir Dados para o treinamento).
Dica
Você não precisará de duas das entradas e uma das saídas do módulo Executar Script R para este experimento e, portanto, poderá deixá-las desanexadas.
Esta parte do teste se parece um pouco com o seguinte:
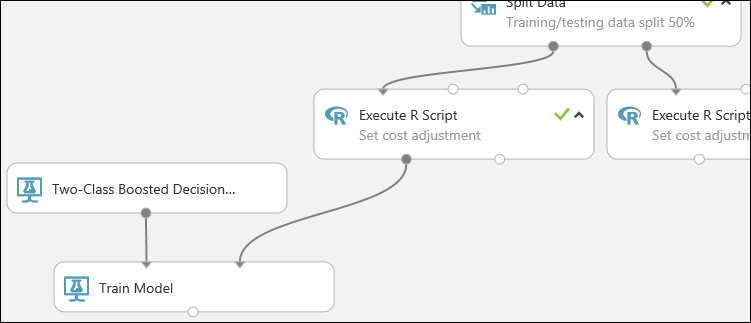
Agora, você precisará informar o módulo Treinar Modelo de que deseja que o modelo preveja o valor do Risco de Crédito.
Selecione o módulo Treinar Modelo. No painel Propriedades, clique em Iniciar seletor de coluna.
Na caixa de diálogo Selecionar uma única coluna, digite "risco de crédito" no campo de pesquisa sob Colunas Disponíveis, selecione "Risco de Crédito" abaixo e clique no botão de seta para a direita ( > ) para mover o "Risco de crédito" para Colunas Selecionadas.
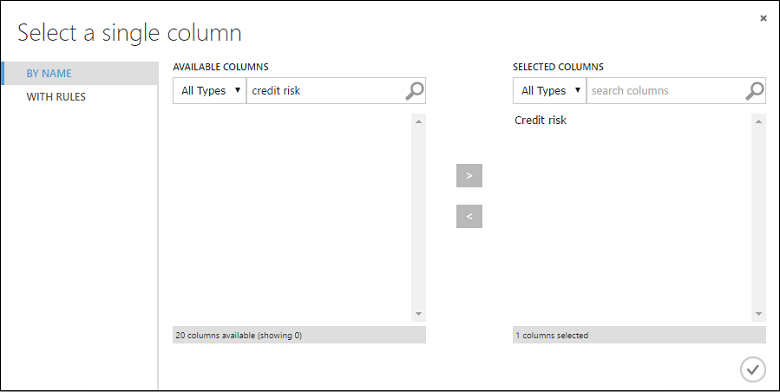
Clique na marca de seleção OK.
Computador de vetor de suporte de duas classes
Em seguida, você configurará o modelo SVM.
Primeiro, uma pequena explicação sobre o SVM. Árvores de decisão aumentadas funcionam bem com recursos de qualquer tipo. No entanto, como o módulo SVM gera um classificador linear, o modelo que ele gera apresenta o melhor erro de teste quando todos os recursos numéricos possuem a mesma escala. Para converter todos os recursos numéricos na mesma escala, use uma transformação "Tanh" (com o módulo Normalizar Dados). Isso transforma nossos números no intervalo [0,1]. O módulo SVM converte os recursos de cadeia de caracteres em recursos categóricos e, em seguida, em recursos binários 0/1. Portanto, não é necessário transformar manualmente os recursos de cadeia de caracteres. Além disso, você não deseja transformar a coluna Risco de Crédito (coluna 21) – ela é numérica, mas é o valor que estamos treinando para o modelo prever e, portanto, você precisa deixá-la inalterada.
Para configurar o modelo SVM, faça o seguinte:
localize o módulo Computador de Vetor de Suporte de Duas Classes na paleta do módulo e arraste-o para a tela.
Clique com o botão direito do mouse no módulo Treinar Modelo, selecione Copiar e, em seguida, clique com o botão direito do mouse na tela e selecione Colar. A cópia do módulo Treinar Modelo tem a mesma seleção de coluna que o original.
Conecte a saída do módulo Computador de Vetor de Suporte de Duas Classes à porta de entrada esquerda do segundo módulo Treinar Modelo.
Localize o módulo Normalizar Dados e arraste-o para a tela.
Conecte a saída esquerda do módulo Executar Script R esquerdo à entrada desse módulo (observe que a porta de saída de um módulo pode ser conectada a mais de um outro módulo).
Conecte a porta de saída esquerda do módulo Normalizar Dados à porta de entrada direita do segundo módulo Treinar Modelo.
Esta parte de nosso teste deve se parecer um pouco com o seguinte:
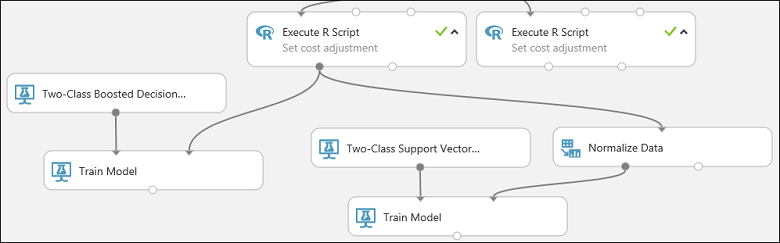
Agora configure o módulo Normalizar Dados:
clique para selecionar o módulo Normalizar Dados. No painel Propriedades, selecione Tanh para o parâmetro Método de transformação.
Clique no Seletor de coluna de inicialização, selecione “Sem colunas” para Começar Com, selecione Incluir na primeira lista suspensa, selecione tipo de coluna na segunda lista suspensa e selecione Numérico na terceira lista suspensa. Isso especifica que todas as colunas numéricas (e somente as numéricas) serão transformadas.
Clique no sinal de adição (+) à direita desta linha - isso cria uma nova linha de listas suspensas. Selecione Excluir na primeira lista suspensa, selecione nomes de coluna na segunda lista suspensa e insira "Risco de Crédito" no campo de texto. Isso especifica que a coluna Risco de Crédito deve ser ignorada (você precisará fazer isso porque essa coluna é numérica e, portanto, será transformada se você não a excluir).
Clique na marca de seleção OK.
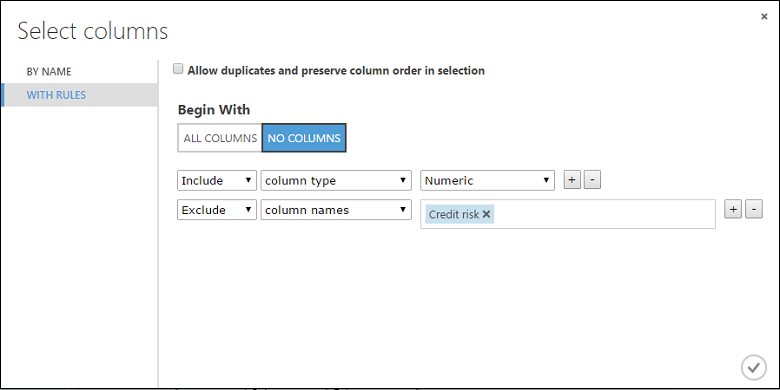
Agora, o módulo Normalizar Dados está definido para executar uma transformação Tanh em todas as colunas numéricas, exceto para a coluna Risco de Crédito.
Pontuar e avaliar os modelos
Você usará os dados de teste que foram separados pelo módulo Dividir Dados a fim de pontuar nossos modelos treinados. Em seguida, você poderá comparar os resultados dos dois modelos para ver qual gerou os melhores resultados.
Adicionar os módulos de Modelo de Pontuação
Localize o módulo Modelo de Pontuação e arraste-o para a tela.
Conecte o módulo Treinar Modelo que está conectado ao módulo Árvore de Decisão Aumentada de Duas Classes à porta de entrada esquerda do módulo Modelo de Pontuação.
Conecte o módulo Executar Script R (nossos dados de teste) à porta de entrada direita do módulo Modelo de Pontuação.
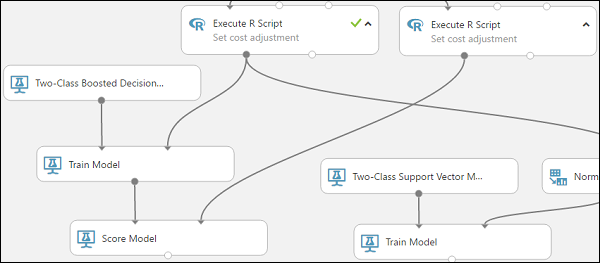
Agora, o módulo Modelo de Pontuação pode pegar as informações de crédito dos dados de teste, executá-las por meio do modelo e comparar as previsões que o modelo gera com a coluna de risco de crédito real dos dados de teste.
Copie e cole o módulo Modelo de Pontuação para criar uma segunda cópia.
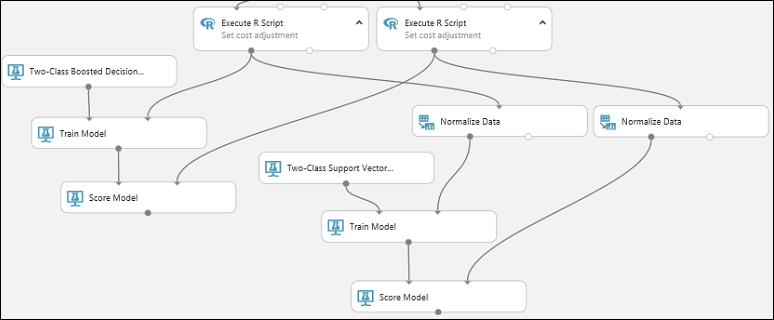
Conecte a saída do modelo SVM (ou seja, a porta de saída do módulo Treinar Modelo que está conectada ao módulo Computador de Vetor de Suporte de Duas Classes) à porta de entrada do segundo módulo Modelo de Pontuação.
Para o modelo SVM, você precisará fazer a mesma transformação nos dados de teste que você fez nos dados de treinamento. Portanto, copie e cole o módulo Normalizar Dados para criar uma segunda cópia e conectá-la ao módulo Executar Script R direito.
Conecte a saída esquerda do segundo módulo Normalizar Dados à porta de entrada direita do segundo módulo Modelo de Pontuação.
Adicionar o módulo Modelo de Avaliação
Para avaliar os dois resultados de pontuação e compará-los entre si, use um módulo Modelo de Avaliação.
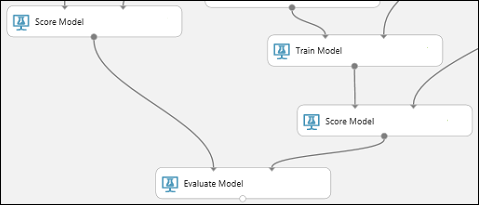
Localize o módulo Modelo de Avaliação e arraste-o para a tela.
Conecte a porta de saída do módulo Modelo de Pontuação associado ao modelo de árvore de decisão aumentada à porta de entrada esquerda do módulo Modelo de Avaliação.
Conecte o outro módulo Modelo de Pontuação à porta de entrada direita.
Execute o teste e verifique os resultados
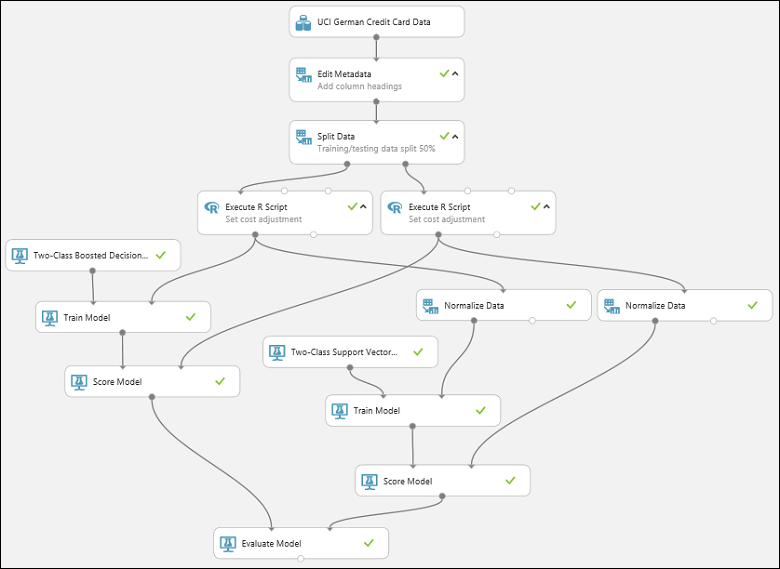
Clique no botão EXECUTAR abaixo das telas para executar o teste. Isso pode levar alguns minutos. Um indicador girando em cada módulo indica que o módulo está em execução e, depois, uma marca de seleção verde mostra quando o módulo foi concluído. Quando todos os modelos tiverem uma marca de seleção, a execução do teste estará concluída.
O teste deve se parecer como o seguinte:
Para verificar os resultados, clique na porta de saída do módulo Modelo de Avaliação e selecione Visualizar.
O módulo Modelo de Avaliação produz um par de curvas e métricas que lhe permitem comparar os resultados dos dois modelos pontuados. Você pode exibir os resultados como curvas ROC (Receiver Operator Characteristic), curvas de Precisão/Repetição, ou curvas de Elevação. Os dados adicionais exibidos incluem uma matriz de confusão, valores cumulativos para a área sob a curva (AUC) e outras métricas. Você pode alterar o valor de limite movendo o controle deslizante para esquerda ou direita e vendo como isso afeta o conjunto de métricas.
À direita do gráfico, clique em Conjunto de dados pontuados ou Conjunto de dados pontuados para comparar para destacar a curva associada e exibir as métricas associadas abaixo. Na legenda das curvas, "Conjunto de dados pontuados" corresponde à porta de entrada esquerda do módulo Modelo de Avaliação - em nosso caso, esse é o modelo de árvore de decisão aumentada. O "Conjunto de dados pontuados para comparar" corresponde à porta de entrada direita - o modelo SVM em nosso caso. Ao clicar em um desses rótulos, a curva desse modelo será destacada e exibirá as métricas correspondentes, como demonstrado no gráfico a seguir.
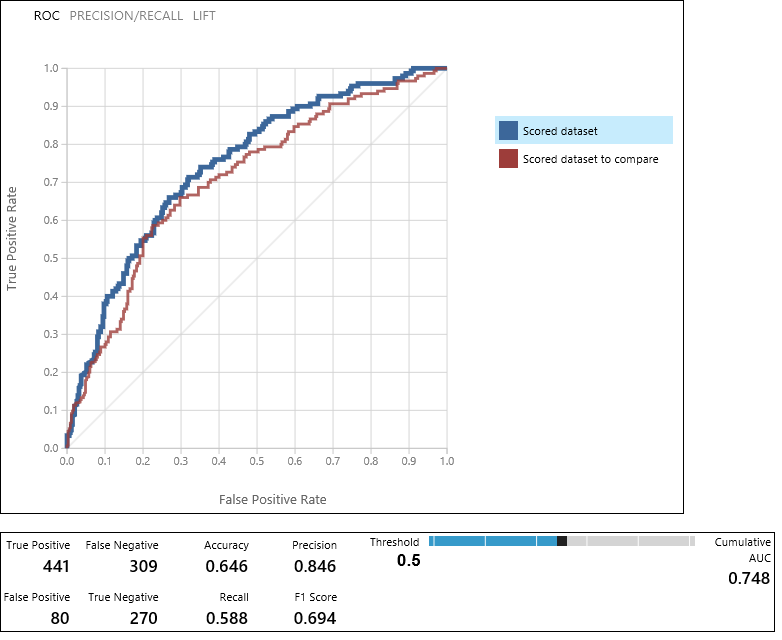
Ao examinar esses valores, você pode decidir qual modelo está mais próximo de fornecer os resultados que você está procurando. Você pode voltar e iterar seu teste alterando os valores de parâmetro nos diferentes modelos.
A ciência e a arte de interpretar esses resultados e ajustar o desempenho do modelo estão fora do escopo deste tutorial. Para obter mais ajuda, leia os artigos a seguir:
- Como avaliar o desempenho do modelo no Machine Learning Studio (clássico)
- Escolher parâmetros para otimizar os algoritmos no Machine Learning Studio (clássico)
- Interpretar os resultados do modelo no Machine Learning Studio (clássico)
Dica
Toda vez que você executar o teste, um registro dessa iteração será mantido no Histórico de Execução. Você pode exibir essas iterações e retornar a qualquer item clicando em EXIBIR HISTÓRICO DE EXECUÇÃO abaixo das telas. Você também pode clicar em Execução Anterior no painel Propriedades para retornar à iteração imediatamente, precedendo aquela que você abriu.
Você pode fazer uma cópia de qualquer iteração de seu teste clicando em SALVAR COMO abaixo das telas. Use as propriedades Resumo e Descrição do teste para manter um registro do que você experimentou em suas iterações de teste.
Para obter mais informações, consulte Gerenciar iterações de teste no Machine Learning Studio (clássico).
Limpar os recursos
Caso não precise mais dos recursos que criou usando este artigo, exclua-os para evitar a geração de encargos. Saiba como fazer isso no artigo Exportar e excluir dados de usuário no produto.
Próximas etapas
Neste tutorial, você concluiu estas etapas:
- Criar uma experiência
- Treinar vários modelos
- Pontuar e avaliar os modelos
Agora você está pronto para implantar modelos para esses dados.