Tutorial 1: prever risco de crédito – Machine Learning Studio (clássico)
APLICA-SE A: Machine Learning Studio (clássico)
Machine Learning Studio (clássico)  Azure Machine Learning
Azure Machine Learning
Importante
O suporte para o Machine Learning Studio (clássico) terminará em 31 de agosto de 2024. É recomendável fazer a transição para o Azure Machine Learning até essa data.
A partir de 1º de dezembro de 2021, você não poderá criar recursos do Machine Learning Studio (clássico). Até 31 de agosto de 2024, você pode continuar usando os recursos existentes do Machine Learning Studio (clássico).
- Confira informações sobre como mover projetos de machine learning do ML Studio (clássico) para o Azure Machine Learning.
- Saiba mais sobre o Azure Machine Learning
A documentação do ML Studio (clássico) está sendo desativada e pode não ser atualizada no futuro.
Neste tutorial, você analisará de maneira aprofundada o processo de desenvolvimento de uma solução de análise preditiva. Você desenvolverá um modelo simples no Machine Learning Studio (clássico). Em seguida, você implantará o modelo como um serviço Web do Machine Learning. Esse modelo implantado pode fazer previsões usando novos dados. Este tutorial é a primeira parte de uma série com três partes.
Suponha que você precisa prever o risco de crédito de uma pessoa com base nas informações dadas em um aplicativo de crédito.
A avaliação de risco de crédito é um problema complexo, mas este tutorial simplificará um pouco esse tópico. Você usará isso como exemplo da forma de criar uma solução de análise preditiva usando o Machine Learning Studio (clássico). Você usará o Machine Learning Studio (clássico) e um serviço Web do Machine Learning para esta solução.
Neste tutorial de três partes, você começará com os dados de risco de crédito disponíveis publicamente. Em seguida, você desenvolverá e treinará um modelo preditivo. Por fim, você implantará o modelo como um serviço Web.
Nesta parte do tutorial, você vai:
- Criar um espaço de trabalho do Machine Learning Studio (clássico)
- Carregar dados existentes
- Criar uma experiência
Depois, você usará esse experimento para treinar modelos na parte 2 e, em seguida implantá-los na parte 3.
Pré-requisitos
Este tutorial pressupõe que você tenha usado o Machine Learning Studio (clássico) pelo menos uma vez e tenha noções básicas sobre os conceitos de aprendizado de máquina. Mas não pressupõe que você seja um especialista em qualquer um deles.
Se você nunca usou o Machine Learning Studio (clássico) antes, inicie pelo guia de início rápido Criar seu primeiro experimento de ciência de dados no Machine Learning Studio (clássico). Esse guia de início rápido leva você a explorar o Machine Learning Studio (clássico) pela primeira vez. Ele mostra os conceitos básicos de como arrastar e soltar módulos no seu experimento, conectá-los, executar o experimento e examinar os resultados.
Dica
Você pode encontrar uma cópia funcional do experimento desenvolvido neste tutorial na Galeria de IA do Azure. Acesse Tutorial – Previsão de risco de crédito e clique em Abrir no Studio para baixar uma cópia do experimento para o seu espaço de trabalho do Machine Learning Studio (clássico).
Criar um espaço de trabalho do Machine Learning Studio (clássico)
Para usar o Machine Learning Studio (clássico), você precisa ter um espaço de trabalho do Machine Learning Studio (clássico). Esse workspace contém as ferramentas necessárias para criar, gerenciar e publicar testes.
Para criar um espaço de trabalho, consulte Criar e compartilhar um espaço de trabalho do Machine Learning Studio (clássico).
Após criar o espaço de trabalho, abra o Microsoft Machine Learning Studio (clássico) (https://studio.azureml.net/Home). Se você tiver mais de um workspace, poderá selecionar o workspace na barra de ferramentas no canto superior direito da janela.
Dica
Se você for proprietário do workspace, será possível compartilhar os experimentos em que está trabalhando convidando outras pessoas para o workspace. Você pode fazer isso no Machine Learning Studio (clássico) na página CONFIGURAÇÕES. Basta ter a conta da Microsoft ou a conta da empresa de cada usuário.
Na página CONFIGURAÇÕES, clique em USUÁRIOS e, em seguida, clique em CONVIDAR MAIS USUÁRIOS na parte inferior da janela.
Carregar dados existentes
Para desenvolver um modelo preditivo para risco de crédito, você precisará de dados que possam ser usados para treinar e testar o modelo. Para este tutorial, usaremos o “Conjunto de Dados Statlog (Dados de Crédito Alemão) UCI” do repositório UC Irvine Machine Learning. Você pode encontrá-lo aqui:
https://archive.ics.uci.edu/ml/datasets/Statlog+(German+Credit+Data)
Use o arquivo chamado german.data. Baixe esse arquivo em sua unidade de disco rígido local.
O conjunto de dados german.data contém linhas de 20 variáveis para 1000 candidatos antigos de crédito. Essas 20 variáveis representam o conjunto de recursos do conjunto de dados (o vetor de recurso), que fornece características de identificação para cada candidato de crédito. Uma coluna adicional em cada linha representa o risco de crédito calculado do candidato, com 700 candidatos identificados como um risco de crédito baixo e 300 como um alto risco.
O website do UCI fornece uma descrição dos atributos do vetor de recurso para esses dados. Esses dados incluem informações financeiras, histórico de crédito, status de emprego e informações pessoais. Para cada candidato, foi dada uma classificação binária indicando se são um risco baixo ou alto de crédito.
Use estes dados para treinar um modelo de análise preditiva. Ao concluir, o modelo deverá ser capaz de aceitar um vetor de recurso para uma nova pessoa e prever se ela tem um risco de crédito alto ou baixo.
Aqui está uma mudança interessante.
A descrição do conjunto de dados no site do UCI menciona quanto custa se classificarmos incorretamente o risco de crédito de uma pessoa. Se o modelo previr um alto risco de crédito para alguém que, de fato, é de baixo risco de crédito, o modelo terá feito uma classificação incorreta.
Porém, a classificação incorreta inversa é cinco vezes mais onerosa para a instituição financeira: se o modelo previr um baixo risco de crédito para alguém que, de fato, é de alto risco de crédito.
Dessa forma, treine o modelo para que o custo desse último tipo de classificação incorreta seja cinco vezes mais alto do que o outro tipo de classificação incorreta.
Uma maneira simples de fazer isso ao treinar o modelo no experimento é duplicando (cinco vezes) as entradas que representam alguém com um alto risco de crédito.
Assim, se o modelo classificar incorretamente alguém como de baixo risco de crédito, quando ele for de fato de risco alto, o modelo fará a mesma classificação incorreta cinco vezes, uma para cada duplicação. Isso aumentará o custo deste erro nos resultados de treinamento.
Converter o formato do conjunto de dados
O conjunto de dados original usa um formato separado por espaço em branco. O Machine Learning Studio (clássico) trabalha melhor com um arquivo CSV (valores separados por vírgula). Então, você converterá o conjunto de dados substituindo espaços por vírgulas.
Há muitas maneiras de converter esses dados. Uma maneira é usar o seguinte comando do Windows PowerShell:
cat german.data | %{$_ -replace " ",","} | sc german.csv
Outra maneira é usar o comando Unix sed:
sed 's/ /,/g' german.data > german.csv
Em ambos os casos, você criou uma versão separada por vírgulas dos dados em um arquivo chamado german.csv que será usado em nosso experimento.
Carregar o conjunto de dados para o Machine Learning Studio (clássico)
Depois que os dados tiverem sido convertidos no formato CSV, você deverá fazer upload deles no Machine Learning Studio (clássico).
Abra a página inicial do Machine Learning Studio (clássico) (https://studio.azureml.net).
Clique no menu
 no canto superior da janela, clique em Azure Machine Learning, selecione Studio e entre.
no canto superior da janela, clique em Azure Machine Learning, selecione Studio e entre.Clique em +NOVO na parte inferior da janela.
Selecione CONJUNTO DE DADOS.
Selecione DO ARQUIVO LOCAL.
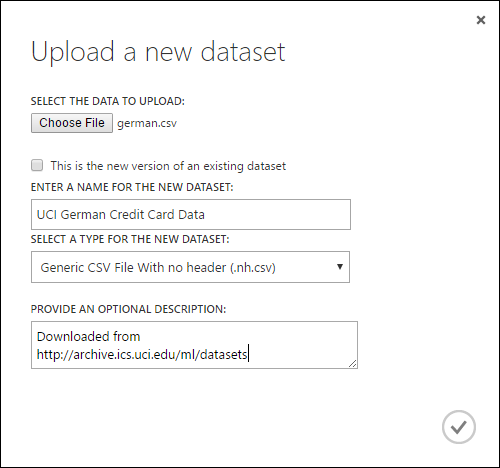
Na caixa de diálogo Carregar um novo conjunto de dados, clique em Pesquisar e localize o arquivo german.csv que você criou.
Insira um nome para o conjunto de dados. Para este tutorial, vamos chamá-lo de "Dados do cartão de crédito alemão UCI".
Para tipo de dados, selecione Arquivo CSV genérico sem cabeçalho (.nh.csv) .
Inclua uma descrição se desejar.
Clique na marca de seleção OK.
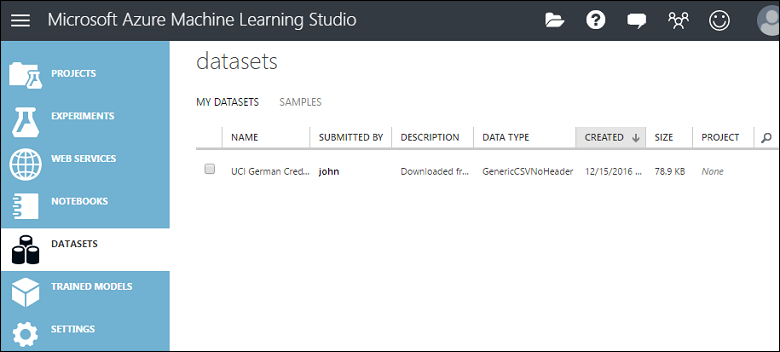
Isso carrega os dados em um módulo de conjunto de dados que você poderá usar em um experimento.
É possível gerenciar conjuntos de dados que você carregou no Studio (clássico) clicando na guia CONJUNTOS DE DADOS à esquerda da janela do Studio (clássico).
Para saber mais sobre como importar outros tipos de dados para um experimento, consulte Importar dados de treinamento para o Machine Learning Studio (clássico).
Criar uma experiência
A próxima etapa do tutorial é criar um experimento no Machine Learning Studio (clássico) que usa o conjunto de dados que você carregou.
No Studio (clássico), clique em +NOVO na parte inferior da janela.
Selecione TESTEe, em seguida, selecione "Teste em branco".
Selecione o nome do teste padrão na parte superior da tela e renomeie-o para algo significativo.

Dica
É uma boa prática preencherResumo e Descrição para o experimento no painel Propriedades. Essas propriedades lhe dão a chance de documentar o experimento para que qualquer pessoa que olhe para ele mais tarde compreenda as suas metas e a metodologia.

Na paleta do módulo à esquerda das telas de teste, expanda Conjuntos de dados salvos.
Localize o conjunto de dados que você criou em Meus Conjuntos de Dados e arraste-o para a tela. Você também pode localizar o conjunto de dados inserindo o nome na caixa Pesquisar acima da paleta.
Preparar os dados
É possível exibir as 100 primeiras linhas dos dados e algumas informações estatísticas de todo o conjunto de dados clicando na porta de saída do conjunto de dados (o círculo pequeno na parte inferior) e selecionando Visualizar.
Como o arquivo de dados não foi fornecido com títulos de coluna, o Studio (clássico) forneceu títulos genéricos (Col1, Col2 etc. ). Bons títulos de coluna não são essenciais para criar um modelo, mas facilitam o trabalho com os dados no teste. Além disso, quando você eventualmente publicar esse modelo em um serviço Web, os títulos ajudarão a identificar as colunas para o usuário do serviço.
Você pode adicionar cabeçalhos de coluna usando o módulo Editar metadados.
O módulo Editar metadados é usado para alterar os metadados associados a um conjunto de dados. Nesse caso, ele fornece nomes mais amigáveis para títulos de coluna.
Para usar o módulo Editar metadados é necessário especificar quais colunas você deseja modificar (nesse caso, todas). Em seguida, especifique a ação a ser executada nessas colunas (nesse caso, alterar os cabeçalhos de coluna.)
Na paleta de módulo, digite "metadados" na caixa Pesquisar . Editar metadados aparecerá na lista de módulos.
Clique e arraste o módulo Editar metadados para a tela e solte-o abaixo do conjunto de dados que você adicionou anteriormente.
Conecte o conjunto de dados ao módulo Editar Metadados: clique na porta de saída do conjunto de dados (o círculo pequeno na parte inferior do conjunto de dados), arraste para a porta de entrada do Editar Metadados (o círculo pequeno na parte superior do módulo) e, em seguida, solte o botão do mouse. O conjunto de dados e o módulo permanecem conectados mesmo se você mover um deles nas telas.
O teste deve se parecer como o seguinte:
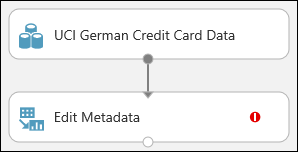
O ponto de exclamação vermelho indica que você ainda não definiu as propriedades deste módulo. Você fará isso em seguida.
Dica
É possível adicionar um comentário em um módulo ao clicar duas vezes nele e inserir o texto. Isso pode ajudar a ver rapidamente o que o módulo está fazendo em seu experimento. Nesse caso, clique duas vezes no módulo Editar metadados e digite o comentário "Adicionar cabeçalhos de coluna". Clique em qualquer lugar na tela para fechar a caixa de texto. Para exibir o comentário, clique na seta para baixo no módulo.
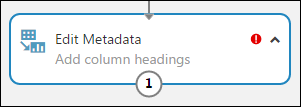
Selecione Editar metadados e, no painel Propriedades, à direita da tela, clique em Iniciar seletor de colunas.
Na caixa de diálogo Selecionar colunas, selecione todas as linhas de Colunas disponíveis e clique em > para movê-las para Colunas selecionadas. A caixa de diálogo deve ter esta aparência:
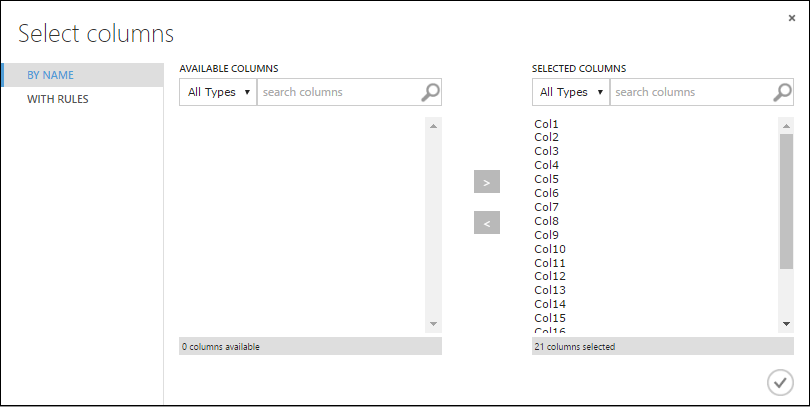
Clique na marca de seleção OK.
Volte ao painel Propriedades, procure o parâmetro Novos nomes de coluna. Neste campo, insira uma lista de nomes para as 21 colunas no conjunto de dados, separadas por vírgulas e na ordem da coluna. Você pode obter os nomes de colunas na documentação do conjunto de dados no site UCI ou, por conveniência, você pode copiar e colar a seguinte lista:
Status of checking account, Duration in months, Credit history, Purpose, Credit amount, Savings account/bond, Present employment since, Installment rate in percentage of disposable income, Personal status and sex, Other debtors, Present residence since, Property, Age in years, Other installment plans, Housing, Number of existing credits, Job, Number of people providing maintenance for, Telephone, Foreign worker, Credit riskO painel de Propriedades tem esta aparência:
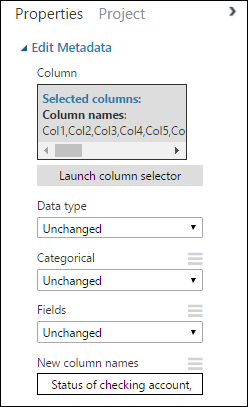
Dica
Se quer verificar os títulos de coluna, execute o teste (clique em EXECUTAR abaixo da tela do teste). Quando ele terminar a execução (uma marca de seleção verde aparecerá em Editar Metadados), clique na porta de saída do módulo Editar Metadados e selecione Visualizar. Você pode exibir a saída de qualquer módulo da mesma maneira para exibir o progresso dos dados durante o teste.
Criar conjuntos de dados de treinamento e teste
Você precisa de alguns dados para treinar o modelo e alguns para testá-lo. Portanto, na próxima etapa do teste, você dividirá o conjunto de dados em dois conjuntos de dados separados: um para treinar nosso modelo e outro para testá-lo.
Para isso, use o módulo Dividir Dados.
Localize o módulo Dividir Dados, arraste-o para a tela e conecte-o ao módulo Editar metadados.
Por padrão, a taxa de divisão é 0,5 e o parâmetro Divisão aleatória é definido. Isso significa que metade dos dados aleatórios sairá por uma porta do módulo Dividir Dados e a outra metade sairá por outra porta. É possível ajustar isso, bem como o parâmetro Semente aleatória, a fim de alterar a divisão entre dados de treinamento e teste. Neste exemplo, deixe no estado em que se encontra.
Dica
A propriedade Fração de linhas no primeiro conjunto de dados de saída determina a quantidade de dados que saem através da porta de saída à esquerda. Por exemplo, se você definir a taxa em 0,7, então, 70% dos dados sairão pela porta esquerda e 30% pela porta direita.
Clique duas vezes no módulo Dividir Dados e insira o comentário, "Divisão de dados de treinamento/teste em 50%".
É possível usar as saídas do módulo Dividir Dados da forma que você quiser, mas vamos escolher usar a saída à esquerda para dados de treinamento e a saída à direita para dados de teste.
Como mencionado na etapa anterior, o custo de uma classificação incorreta de um risco de crédito alto como baixo é cinco vezes maior do que o custo da classificação incorreta de um risco baixo como alto. Para isso, gere um novo conjunto de dados que reflita essa função de custo. No novo conjunto de dados, cada exemplo de alto risco é replicado cinco vezes, enquanto cada exemplo de baixo risco não será replicado.
Você pode fazer essa replicação usando código em R:
Localize e arraste o módulo Executar Script R para a tela de teste.
Conecte a porta de saída à esquerda do módulo Dividir Dados à primeira porta de entrada (“Dataset1”) do módulo Executar Script R.
Clique duas vezes no módulo Executar Script R e insira o comentário "Definir ajuste de custo".
No painel Propriedades, exclua o texto padrão no parâmetro Script R e insira esse script:
dataset1 <- maml.mapInputPort(1) data.set<-dataset1[dataset1[,21]==1,] pos<-dataset1[dataset1[,21]==2,] for (i in 1:5) data.set<-rbind(data.set,pos) maml.mapOutputPort("data.set")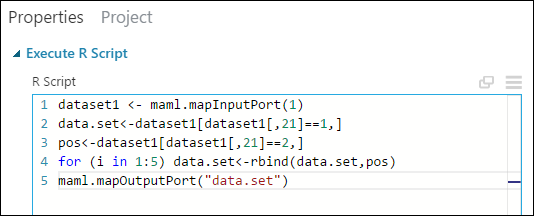
É necessário fazer essa mesma operação de replicação para cada saída do módulo Dividir Dados de forma que os dados de treinamento e teste tenham os mesmos ajustes de custo. A maneira mais fácil de fazer isso é duplicando o módulo Executar Script R que você acabou de criar e conectando-o a outra porta de saída do módulo Dividir Dados.
Clique com o botão direito do mouse no módulo Executar Script R e selecione Copiar.
Clique com o botão direito do mouse nas telas de teste e selecione Colar.
Arraste o novo módulo para a posição correta e, em seguida, conecte a porta de saída à direita do módulo Dividir Dados à primeira porta de entrada desse novo módulo Executar Script R.
Na parte inferior da tela, clique em Executar.
Dica
A cópia do módulo Executar script R contém o mesmo script que o módulo original. Quando você copia e cola um módulo nas telas, a cópia mantém todas as propriedades do original.
Nosso teste agora se parece com esse:
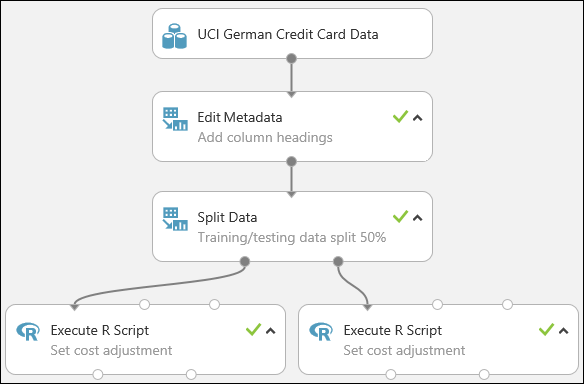
Para obter mais informações sobre como usar scripts R em seus testes, consulte Estender seu teste com R.
Limpar os recursos
Caso não precise mais dos recursos que criou usando este artigo, exclua-os para evitar a geração de encargos. Saiba como fazer isso no artigo Exportar e excluir dados de usuário no produto.
Próximas etapas
Neste tutorial, você concluiu estas etapas:
- Criar um espaço de trabalho do Machine Learning Studio (clássico)
- Carregar dados existentes no workspace
- Criar uma experiência
Agora você está pronto para treinar e avaliar modelos para esses dados.