Pontos de extremidade para inferência na produção
APLICA-SE A: Extensão de ML da CLI do Azure v2 (atual)SDK do Python azure-ai-ml v2 (atual)
Extensão de ML da CLI do Azure v2 (atual)SDK do Python azure-ai-ml v2 (atual)
Depois de treinar modelos ou pipelines de machine learning ou encontrar modelos do catálogo de modelos que atenda às suas necessidades, você precisará implantá-los na produção para que outras pessoas possam usá-los para inferência. Inferência é o processo de aplicação de novos dados de entrada a um modelo ou pipeline de machine learning para gerar saídas. Embora essas saídas normalmente sejam chamadas de "previsões", a inferência pode ser usada para gerar saídas para outras tarefas de aprendizado de máquina, como classificação e clustering. No Azure Machine Learning, você executa a inferência usando pontos de extremidade.
Pontos de extremidade e implantações
Um ponto de extremidade é uma URL estável e durável que poder ser usada para solicitar ou invocar um modelo. Você fornece as entradas necessárias para o ponto de extremidade e obtém as saídas de volta. O Azure Machine Learning permite implementar pontos de extremidade de API sem servidor, pontos de extremidade online e pontos de extremidade em lotes. Um ponto de extremidade fornece:
- uma URL estável e durável (como endpoint-name.region.inference.ml.azure.com),
- um mecanismo de autenticação e
- um mecanismo de autorização.
Uma implantação é um conjunto de recursos e computação necessários para hospedar o modelo ou componente que executa a inferência real. Um ponto de extremidade contém uma implantação e, para pontos de extremidade online e em lotes, um ponto de extremidade pode conter várias implantações. As implantações podem hospedar ativos independentes e consumir recursos diferentes, com base nas necessidades dos ativos. Além disso, um ponto de extremidade tem um mecanismo de roteamento que pode direcionar solicitações para qualquer uma de suas implantações.
Por um lado, alguns tipos de pontos de extremidade no Azure Machine Learning consomem recursos dedicados em suas implantações. Para que esses pontos de extremidade sejam executados, você deve ter a cota de computação em sua assinatura do Azure. Por outro lado, determinados modelos dão suporte a uma implantação sem servidor, permitindo que eles não consumam nenhuma cota de sua assinatura. Para implantação sem servidor, você é cobrado com base no uso.
Intuição
Suponhamos que você está trabalhando em um aplicativo que precisa prever o tipo e a cor de um carro a partir da sua foto. Para esse aplicativo, um usuário com determinadas credenciais faz uma solicitação HTTP para uma URL e fornece uma imagem de um carro como parte da solicitação. Em troca, o usuário obtém uma resposta que inclui o tipo e a cor do carro como valores de cadeia de caracteres. Nesse cenário, a URL serve como um ponto de extremidade.
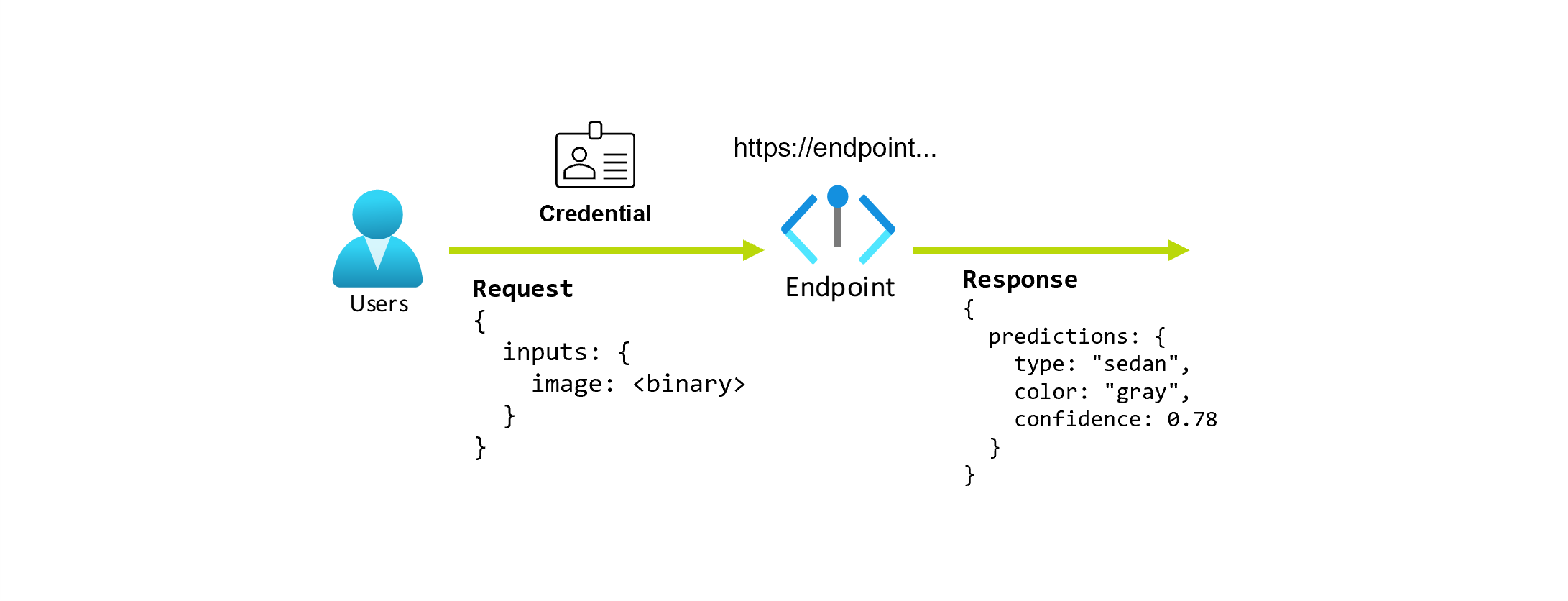
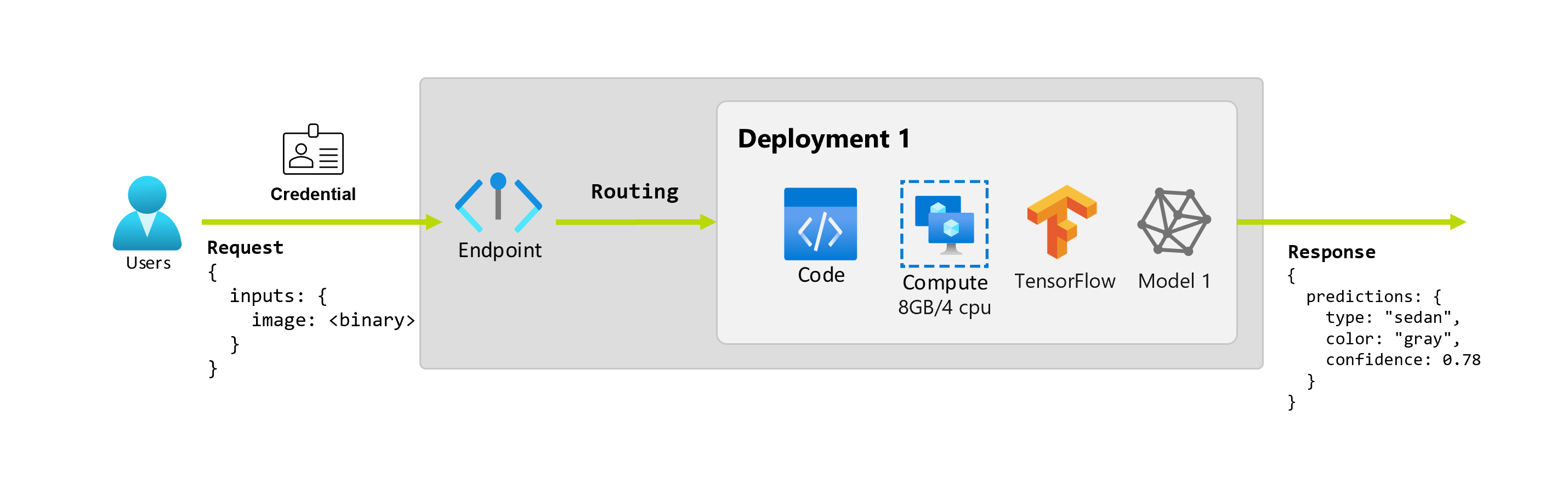
Além disso, digamos que uma cientista de dados, Alice, esteja trabalhando na implementação do aplicativo. Alice sabe muito sobre o TensorFlow e decide implementar o modelo usando um classificador sequencial Keras com uma arquitetura RestNet do TensorFlow Hub. Depois de testar o modelo, Alice fica feliz com seus resultados e decide usar o modelo para resolver o problema de previsão do carro. O modelo é grande em tamanho e requer 8 GB de memória com 4 núcleos para ser executado. Nesse cenário, o modelo de Alice e os recursos, como o código e a computação, que são necessários para executar o modelo compõem uma implantação no ponto de extremidade.
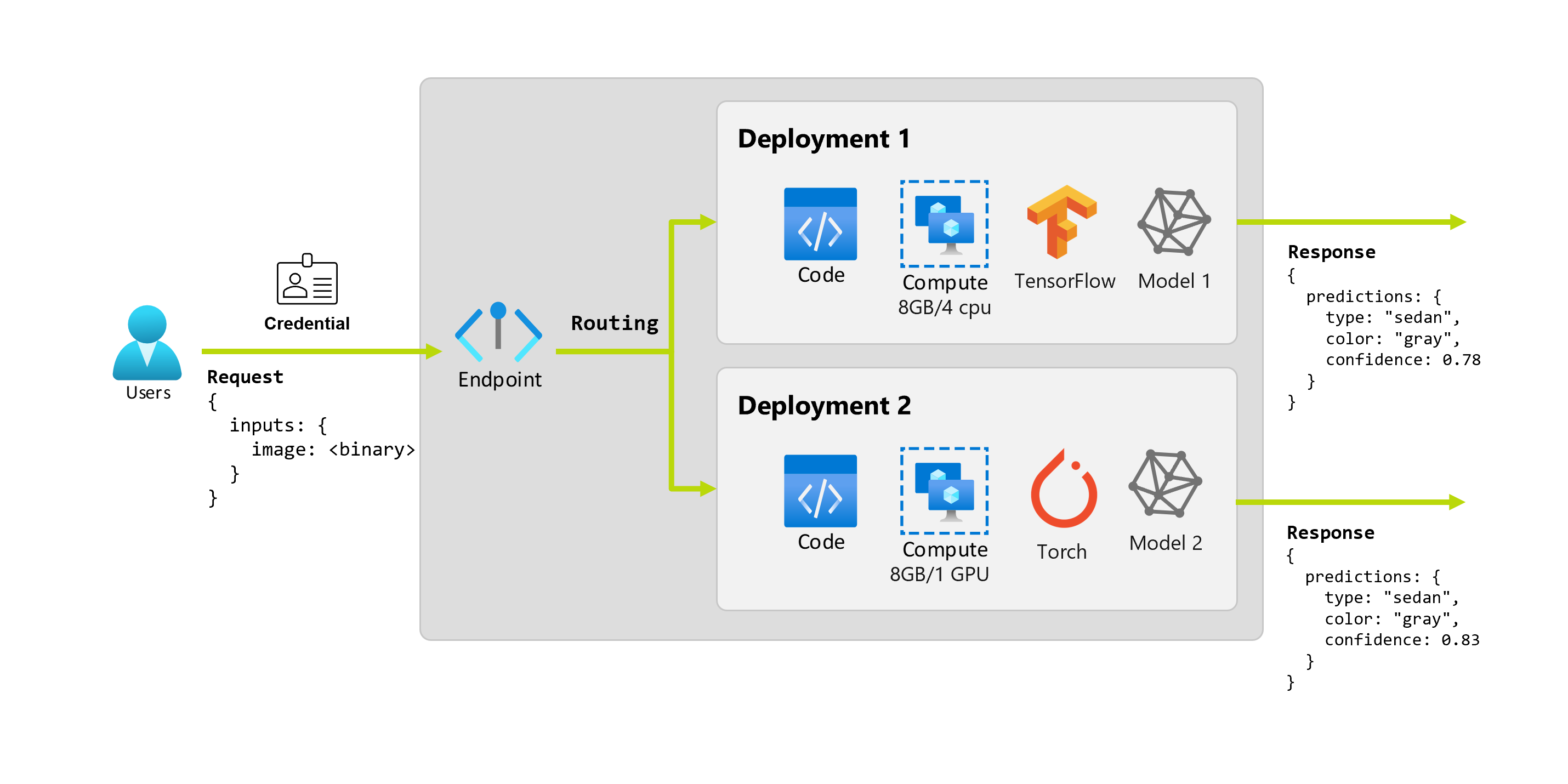
Vamos imaginar que, após alguns meses, a organização descubra que o aplicativo tem um desempenho ruim em imagens com condições de iluminação menores que as ideais. Paulo, outro cientista de dados, tem muito conhecimento sobre técnicas de argumentação de dados que ajudam um modelo a criar robustez nesse fator. No entanto, Paulo se sente mais confortável usando Torch para implementar o modelo e treina um novo modelo com Torch. Paulo deseja experimentar esse modelo em produção gradualmente até que a organização esteja pronta para desativar o modelo antigo. O novo modelo também mostra melhor desempenho quando implantado na GPU, portanto, a implantação precisa incluir uma GPU. Nesse cenário, o modelo de Paulo e os recursos, como o código e a computação, que são necessários para executar o modelo compõem outra implantação no mesmo ponto de extremidade.
Pontos de extremidade: API sem servidor, online e lote
O Azure Machine Learning permite implementar pontos de extremidade de API sem servidor, pontos de extremidade online e pontos de extremidade em lotes.
Pontos de extremidade de API sem servidor e pontos de extremidade online são projetados para inferência em tempo real. Sempre que você invoca o ponto de extremidade, os resultados são retornados na resposta do ponto de extremidade. Os pontos de extremidade de API sem servidor não consomem cota de sua assinatura; em vez disso, eles são cobrados com cobrança paga conforme o uso.
Os pontos de extremidade do lote são projetados para inferência de lote de execução prolongada. Sempre que você invoca um ponto de extremidade em lote, gera um trabalho em lote que executa o trabalho real.
Quando usar pontos de extremidade de API sem servidor, online e em lote
Pontos de extremidade de API sem servidor:
Use pontos de extremidade de API sem servidor para consumir grandes modelos fundamentais para inferência em tempo real fora da prateleira ou para ajustar esses modelos. Nem todos os modelos estão disponíveis para implantação em pontos de extremidade de API sem servidor. É recomendável usar este modo de implantação quando:
- Seu modelo é um modelo fundamental ou uma versão ajustada de um modelo fundamental que está disponível para implantações de API sem servidor.
- Você pode se beneficiar de uma implantação sem cota.
- Você não precisa personalizar a pilha de inferência usada para executar o modelo.
Pontos de extremidade online:
Use os pontos de extremidade online para operacionalizar modelos para inferência em tempo real em solicitações síncronas de baixa latência. Recomendamos usá-los quando:
- Seu modelo é um modelo fundamental ou uma versão ajustada de um modelo fundamental, mas não tem suporte em pontos de extremidade de API sem servidor.
- Você tem requisitos de baixa latência.
- Seu modelo pode responder à solicitação em um período relativamente curto de tempo.
- As entradas do modelo se encaixam no conteúdo HTTP da solicitação.
- Você precisa escalar verticalmente em termos de número de solicitações.
Pontos de extremidade do lote:
Use pontos de extremidade em lote para operacionalizar modelos ou pipelines para inferência assíncrona de longa execução. Recomendamos usá-los quando:
- Você tem modelos ou pipelines caros que exigem mais tempo de execução.
- Você deseja operacionalizar pipelines de aprendizado de máquina e reutilizar componentes.
- Você precisa executar a inferência em grandes quantidades de dados, distribuídas em vários arquivos.
- Você não tem requisitos de baixa latência.
- As entradas do modelo são armazenadas em uma conta de armazenamento ou em um ativo de dados do Azure Machine Learning.
- Você pode aproveitar a paralelização.
Comparação de pontos de extremidade de API sem servidor, online e em lotes
Todos os pontos de extremidade de API, online e lote sem servidor são baseados na ideia de pontos de extremidade, portanto, você pode fazer a transição facilmente de um para o outro. Pontos de extremidade online e em lote também são capazes de gerenciar várias implantações para o mesmo ponto de extremidade.
Pontos de extremidade
A tabela a seguir mostra um resumo dos diferentes recursos disponíveis para pontos de extremidade de API, online e em lotes sem servidor no nível do ponto de extremidade.
| Recurso | Pontos de extremidade de API sem servidor | Pontos de extremidade online | Pontos de extremidade em lotes |
|---|---|---|---|
| URL de invocação estável | Sim | Sim | Yes |
| Suporte para várias implantações | Não | Sim | Sim |
| Roteamento da implantação | Nenhum | Divisão de tráfego | Alternar para o padrão |
| Tráfego de espelhamento para uma distribuição segura | Não | Sim | Não |
| Suporte para o Swagger | Sim | Sim | No |
| Autenticação | Chave | Key e Microsoft Entra ID (versão prévia) | Microsoft Entra ID |
| Suporte à rede privada (herdado) | Não | Sim | Yes |
| Isolamento de rede gerenciada | Sim | Yes | Sim (confira a configuração adicional necessária) |
| Chaves gerenciadas pelo cliente | NA | Sim | Yes |
| Base de custo | Por ponto de extremidade, por minuto1 | Nenhum | Nenhum |
1Uma pequena fração é cobrada por pontos de extremidade de API sem servidor por minuto. Confira a seção de implantações para ver os encargos relacionados ao consumo, que são cobrados por token.
Implantações
A tabela a seguir mostra um resumo dos diferentes recursos disponíveis para pontos de extremidade de API sem servidor, online e em lotes no nível de implantação. Esses conceitos se aplicam a cada implantação no ponto de extremidade (para pontos de extremidade online e em lotes) e se aplicam a pontos de extremidade de API sem servidor (em que o conceito de implantação é integrado ao ponto de extremidade).
| Recurso | Pontos de extremidade de API sem servidor | Pontos de extremidade online | Pontos de extremidade em lotes |
|---|---|---|---|
| Tipos de implantação | Modelos | Modelos | Modelos e componentes do Pipeline |
| Implantação de modelo do MLflow | Não, apenas modelos específicos no catálogo | Sim | Yes |
| Implantação do modelo personalizado | Não, apenas modelos específicos no catálogo | Sim, com script de pontuação | Sim, com script de pontuação |
| Implantação do pacote de modelo 2 | Interno | Sim (versão prévia) | Não |
| Servidor de inferência 3 | API de Inferência do Modelo de IA do Azure | - Servidor de Inferência do Azure Machine Learning - Triton - Personalizado (por meio do BYOC) |
Inferência de lote |
| Recurso de computação consumido | Nenhum (sem servidor) | Instâncias ou recursos granulares | Instâncias de cluster |
| Tipo de computação | Nenhum (sem servidor) | Computação gerenciada e Kubernetes | Computação gerenciada e Kubernetes |
| Computação de baixa prioridade | NA | Não | Sim |
| Dimensionar a computação para zero | Interno | Não | Sim |
| Dimensionamento automático de computação4 | Interno | Sim, com base no uso de recursos | Sim, com base na contagem de trabalhos |
| Gerenciamento de excesso de capacidade | Limitação | Limitação | Colocando na fila |
| Base de custo5 | Por token | Por implantação: instâncias de computação em execução | Por trabalho: computação consumida no trabalho (limitada ao número máximo de instâncias do cluster) |
| Teste local de implantações | Não | Sim | No |
2 A implantação de modelos de MLflow em pontos de extremidade sem conectividade de saída com a Internet ou redes privadas requer o empacotamento do modelo primeiro.
3 Servidor de inferência refere-se à tecnologia de serviço que aceita solicitações, processa-as e cria respostas. O servidor de inferência também determina o formato da entrada e as saídas esperadas.
4 Dimensionamento automático é a capacidade de escalar ou reduzir dinamicamente os recursos alocados da implantação com base na carga dela. As implantações online e em lote usam estratégias diferentes para dimensionamento automático. Enquanto as implantações online escalam e reduzem verticalmente com base na utilização de recursos (como CPU, memória, solicitações etc.), os pontos de extremidade em lote são escalados verticalmente ou reduzidos com base no número de trabalhos criados.
5 As implantações online e em lote são cobradas pelos recursos consumidos. Em implantações online, os recursos são provisionados no momento da implantação. Na implantação em lote, os recursos não são consumidos no tempo de implantação, mas no momento em que o trabalho é executado. Portanto, não há nenhum custo associado à implantação em lote em si. Da mesma forma, os trabalhos enfileirados também não consomem recursos.
Interfaces do desenvolvedor
Os pontos de extremidade foram projetados para ajudar a organização a operacionalizar cargas de trabalho de nível de produção no Azure Machine Learning. Os pontos de extremidade são recursos robustos e escalonáveis e fornecem os melhores recursos para implementar fluxos de trabalho de MLOps.
Você pode criar e gerenciar pontos de extremidade em lotes e online com várias ferramentas de desenvolvedor:
- A CLI do Azure e o SDK do Python
- Azure Resource Manager/API REST
- Portal da Web do estúdio do Azure Machine Learning
- Portal do Azure (TI/administrador)
- Suporte para pipelines de CI/CD do MLOps usando a interface da CLI do Azure e as interfaces REST/ARM