Implantar modelos para pontuação em pontos de extremidade em lotes
APLICA-SE A: Extensão de ML da CLI do Azure v2 (atual)SDK do Python azure-ai-ml v2 (atual)
Extensão de ML da CLI do Azure v2 (atual)SDK do Python azure-ai-ml v2 (atual)
Os pontos de extremidade oferecem um modo conveniente de implantar modelos que executam a inferência em grandes volumes de dados. Esses pontos de extremidade simplificam o processo de hospedagem de seus modelos para pontuação em lote, de modo que você se concentre no aprendizado de máquina, em vez da infraestrutura.
Use pontos de extremidade em lote para implantação de modelo quando:
- Você tem modelos caros que exigem mais tempo para executar a inferência.
- Você precisa executar a inferência em grandes quantidades de dados que são distribuídos em vários arquivos.
- Você não tem requisitos de baixa latência.
- Você pode aproveitar a paralelização.
Neste artigo, você usará um ponto de extremidade em lote para implantar um modelo de machine learning que resolve o problema de reconhecimento de dígito clássico do MNIST (Modified National Institute of Standards and Technology). Em seguida, o modelo implantado executa inferência em lotes em grandes quantidades de dados. Nesse caso, arquivos de imagem. Você começa criando uma implantação em lote de um modelo que foi criado usando o Torch. Essa implantação se torna a padrão no ponto de extremidade. Posteriormente, você cria uma segunda implantação de um modo que foi criado com o TensorFlow (Keras), testa a segunda implantação e a defini como a implantação padrão do ponto de extremidade.
Para acompanhar os exemplos de código e os arquivos necessários para executar os comandos neste artigo localmente, consulte a seção Clonar o repositório de exemplos. Os exemplos de código e os arquivos estão contidos no repositório azureml-examples.
Pré-requisitos
Antes de seguir as etapas neste artigo, verifique se você tem os seguintes pré-requisitos:
Uma assinatura do Azure. Caso não tenha uma assinatura do Azure, crie uma conta gratuita antes de começar. Experimente a versão gratuita ou paga do Azure Machine Learning.
Um Workspace do Azure Machine Learning. Se você não tiver um, use as etapas do artigo Como gerenciar espaços de trabalho para criar um.
Para executar as seguintes tarefas, certifique-se de ter essas permissões no espaço de trabalho:
Para criar/gerenciar pontos de extremidade e implantações em lotes: use as funções proprietário, colaborador ou uma função personalizada que permita
Microsoft.MachineLearningServices/workspaces/batchEndpoints/*.Para criar implantações do ARM no grupo de recursos do espaço de trabalho: use as funções Proprietário, Colaborador ou uma função personalizada que permita
Microsoft.Resources/deployments/writeno grupo de recursos em que o espaço de trabalho está implantado.
Você precisa instalar o software a seguir para trabalhar com o Azure Machine Learning:
APLICA-SE A:
Extensão de ML da CLI do Azurev2 (atual)A CLI do Azure e a
mlextensão do Azure Machine Learning.az extension add -n ml
Clone o repositório de exemplos
O exemplo neste artigo é baseado em exemplos de códigos contidos no repositório azureml-examples . Para executar os comandos localmente sem precisar copiar/colar o YAML e outros arquivos, primeiro clone o repositório e altere os diretórios para a pasta:
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples/cli/endpoints/batch/deploy-models/mnist-classifier
Preparar seu sistema
Conectar-se ao workspace
Primeiro, conecte-se ao workspace do Azure Machine Learning no qual você trabalhará.
Se você ainda não definiu os padrões da CLI do Azure, salve as configurações padrão. Para evitar passar os valores para sua assinatura, espaço de trabalho, grupo de recursos e localização várias vezes, execute este código:
az account set --subscription <subscription>
az configure --defaults workspace=<workspace> group=<resource-group> location=<location>
Criar computação
Os pontos de extremidade do lote são executados em clusters de computação e dão suporte a clusters de Computação do Azure Machine Learning (AmlCompute) e clusters do Kubernetes. Os clusters são um recurso compartilhado, portanto, um cluster pode hospedar uma ou várias implantações em lote (juntamente com outras cargas de trabalho, se desejado).
Crie uma computação chamada batch-cluster, conforme mostrado no código a seguir. Você pode ajustar conforme necessário e fazer referência à sua computação usando o azureml:<your-compute-name>.
az ml compute create -n batch-cluster --type amlcompute --min-instances 0 --max-instances 5
Observação
Você não será cobrado pela computação neste momento, já que o cluster permanecerá com 0 nós até que um ponto de extremidade de lote seja invocado e um trabalho de pontuação de lote seja enviado. Para obter mais informações sobre os custos de computação, consulte Gerenciar e otimizar o custo do AmlCompute.
Criar um ponto de extremidade em lote
Um ponto de extremidade em lote é um ponto de extremidade HTTPS que os clientes podem chamar para disparar um trabalho de pontuação em lotes. Um trabalho de pontuação em lote é um trabalho que pontua várias entradas. Uma implantação em lote é um conjunto de recursos de computação que hospedam o modelo que executa a pontuação em lote real (ou inferência em lote). Um ponto de extremidade em lote pode ter várias implantações em lote. Para obter mais informações sobre os pontos de extremidade em lote, confira O que são pontos de extremidade em lote.
Dica
Uma das implantações em lote serve como a implantação padrão para o ponto de extremidade. Quando o ponto de extremidade é invocado, a implantação padrão faz a pontuação em lote real. Para obter mais informações sobre pontos de extremidade em lote e implantações, consulte pontos de extremidade em lote e implantação em lote.
Nomeie o ponto de extremidade. O nome do ponto de extremidade deve ser exclusivo em uma região do Azure, já que o nome está incluído no URI do ponto de extremidade. Por exemplo, pode haver apenas um ponto de extremidade em lote com o nome
mybatchendpointemwestus2.Coloque o nome do ponto de extremidade em uma variável para que possamos referenciá-lo facilmente mais tarde.
ENDPOINT_NAME="mnist-batch"Configurar o ponto de extremidade em lote
O arquivo YAML a seguir define um ponto de extremidade em lote. Você pode usar este arquivo com o comando da CLI para a criação de ponto de extremidade em lote.
endpoint.yml
$schema: https://azuremlschemas.azureedge.net/latest/batchEndpoint.schema.json name: mnist-batch description: A batch endpoint for scoring images from the MNIST dataset. tags: type: deep-learningA tabela a seguir descreve as principais propriedades do ponto de extremidade. Para o esquema YAML completo do ponto de extremidade em lote, consulte Esquema YAML do ponto de extremidade em lote da CLI (v2).
Chave Descrição nameO nome do ponto de extremidade em lote. Deve ser exclusivo no nível da região do Azure. descriptionA descrição do ponto de extremidade em lote. Essa propriedade é opcional. tagsAs marcas a serem incluídas no ponto de extremidade. Essa propriedade é opcional. Criar o ponto de extremidade:
Execute o código a seguir para criar um ponto de extremidade em lote.
az ml batch-endpoint create --file endpoint.yml --name $ENDPOINT_NAME
Criar uma implantação em lote
Uma implantação de modelo é um conjunto de recursos necessários para hospedar o modelo que executa a inferência real. Para criar uma implantação de modelo em lote, você precisa dos itens a seguir:
- Um modelo registrado no workspace
- O código para pontuar o modelo
- Um ambiente com as dependências do modelo instaladas
- A computação criada previamente e as configurações do recurso
Comece registrando o modelo a ser implantado—um modelo Torch para o popular problema de reconhecimento de dígito (MNIST). As Implantações em Lote só podem implantar modelos registrados no workspace. Você poderá pular essa etapa se o modelo que deseja implantar já estiver registrado.
Dica
Os modelos são associados à implantação em vez do ponto de extremidade. Isso significa que um só ponto de extremidade pode atender a modelos diferentes (ou versões de modelo) no mesmo ponto de extremidade, desde que os diferentes modelos (ou versões de modelo) sejam implantados em diferentes implantações.
MODEL_NAME='mnist-classifier-torch' az ml model create --name $MODEL_NAME --type "custom_model" --path "deployment-torch/model"Agora é hora de criar um script de pontuação. As implantações em lote exigem um script de pontuação que indica como determinado modelo precisa ser executado e como os dados de entrada precisam ser processados. Os pontos de extremidade em lote dão suporte a scripts criados no Python. Nesse caso, você implanta um modelo que lê arquivos de imagem que representam dígitos e gera o dígito correspondente. O script de pontuação é o seguinte:
Observação
Para modelos MLflow, o Azure Machine Learning gera automaticamente o script de pontuação, ou seja, você não precisa fornecê-lo. Se o modelo for um modelo do MLflow, você poderá ignorar esta etapa. Para saber mais sobre como os pontos de extremidade em lote funcionam com modelos do MLflow, confira o artigo Usando modelos do MLflow em implantações em lote.
Aviso
Se você estiver implantando um modelo de AutoML (machine learning automatizado) automatizado em um ponto de extremidade em lote, observe que o script de pontuação que o AutoML fornece funciona somente para pontos de extremidade online e não foi projetado para execução em lote. Para obter informações sobre como criar um script de pontuação para sua implantação em lote, consulte Criar scripts de pontuação para implantações em lotes.
deployment-torch/code/batch_driver.py
import os import pandas as pd import torch import torchvision import glob from os.path import basename from mnist_classifier import MnistClassifier from typing import List def init(): global model global device # AZUREML_MODEL_DIR is an environment variable created during deployment # It is the path to the model folder model_path = os.environ["AZUREML_MODEL_DIR"] model_file = glob.glob(f"{model_path}/*/*.pt")[-1] model = MnistClassifier() model.load_state_dict(torch.load(model_file)) model.eval() device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") def run(mini_batch: List[str]) -> pd.DataFrame: print(f"Executing run method over batch of {len(mini_batch)} files.") results = [] with torch.no_grad(): for image_path in mini_batch: image_data = torchvision.io.read_image(image_path).float() batch_data = image_data.expand(1, -1, -1, -1) input = batch_data.to(device) # perform inference predict_logits = model(input) # Compute probabilities, classes and labels predictions = torch.nn.Softmax(dim=-1)(predict_logits) predicted_prob, predicted_class = torch.max(predictions, axis=-1) results.append( { "file": basename(image_path), "class": predicted_class.numpy()[0], "probability": predicted_prob.numpy()[0], } ) return pd.DataFrame(results)Crie um ambiente em que a implantação em lote será executada. O ambiente deve incluir os pacotes
azureml-coreeazureml-dataset-runtime[fuse], que são necessários para os pontos de extremidade em lote, além de qualquer dependência que o código exigir para execução. Nesse caso, as dependências foram capturadas em um arquivoconda.yaml:deployment-torch/environment/conda.yaml
name: mnist-env channels: - conda-forge dependencies: - python=3.8.5 - pip<22.0 - pip: - torch==1.13.0 - torchvision==0.14.0 - pytorch-lightning - pandas - azureml-core - azureml-dataset-runtime[fuse]Importante
Os pacotes
azureml-coreeazureml-dataset-runtime[fuse]são exigidos por implantações em lote e devem ser incluídos nas dependências do ambiente.Especifique o ambiente da seguinte maneira:
A definição de ambiente será incluída na própria definição de implantação como um ambiente anônimo. Você exibirá nas seguintes linhas na implantação:
environment: name: batch-torch-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yamlAviso
Não há suporte para ambientes coletados em implantações em lote. Você precisa especificar seu próprio ambiente. Você sempre pode usar a imagem base de um ambiente coletado como o seu para simplificar o processo.
Criar uma definição de implantação
deployment-torch/deployment.yml
$schema: https://azuremlschemas.azureedge.net/latest/modelBatchDeployment.schema.json name: mnist-torch-dpl description: A deployment using Torch to solve the MNIST classification dataset. endpoint_name: mnist-batch type: model model: name: mnist-classifier-torch path: model code_configuration: code: code scoring_script: batch_driver.py environment: name: batch-torch-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yaml compute: azureml:batch-cluster resources: instance_count: 1 settings: max_concurrency_per_instance: 2 mini_batch_size: 10 output_action: append_row output_file_name: predictions.csv retry_settings: max_retries: 3 timeout: 30 error_threshold: -1 logging_level: infoA tabela a seguir descreve as principais propriedades da implantação em lote. Para o esquema YAML completo da implantação em lote, consulte Esquema YAML da implantação em lote da CLI (v2).
Chave Descrição nameO nome da implantação. endpoint_nameO nome do ponto de extremidade no qual criar a implantação. modelO modelo a ser usado para a pontuação em lote. O exemplo define um modelo embutido usando path. Esta definição permite que os arquivos de modelo sejam carregados e registrados automaticamente com um nome e uma versão gerados automaticamente. Confira o Esquema do modelo para obter mais opções. Como prática recomendada para cenários de produção, você deve criar o modelo separadamente e fazer referência a ele aqui. Para referenciar um modelo existente, use a sintaxeazureml:<model-name>:<model-version>.code_configuration.codeO diretório local que contém todo o código-fonte do Python usado para pontuar o modelo. code_configuration.scoring_scriptO arquivo Python no diretório code_configuration.code. Esse arquivo precisa ter uma funçãoinit()e uma funçãorun(). Use a funçãoinit()para qualquer preparação cara ou comum (por exemplo, para carregar o modelo na memória).init()será chamado apenas uma vez no início do processo. Userun(mini_batch)para pontuar cada entrada; o valor demini_batché uma lista de caminhos de arquivo. A funçãorun()deve retornar um DataFrame do Pandas ou uma matriz. Cada elemento retornado indica uma execução bem-sucedida de um elemento de entrada nomini_batch. Para obter mais informações sobre como criar um script de pontuação, confira Noções básicas sobre o script de pontuação.environmentO ambiente para pontuar o modelo. O exemplo define um ambiente em linha usando conda_fileeimage. As dependências deconda_fileserão instaladas na parte superior deimage. O ambiente será registrado automaticamente com um nome e uma versão gerados automaticamente. Confira o Esquema do ambiente para obter mais opções. Como prática recomendada para cenários de produção, você deve criar o ambiente separadamente e fazer referência a ele aqui. Para referenciar um ambiente existente, use a sintaxeazureml:<environment-name>:<environment-version>.computeA computação para executar a pontuação em lote. O exemplo usa o batch-clustercriado no início e faz referência a ele usando a sintaxeazureml:<compute-name>.resources.instance_countO número de instâncias a serem usadas para cada trabalho de pontuação em lotes. settings.max_concurrency_per_instanceO número máximo de execuções de scoring_scriptparalelas por instância.settings.mini_batch_sizeO número de arquivos que o scoring_scriptpode processar em uma chamadarun().settings.output_actionComo a saída deve ser organizada no arquivo de saída. append_rowirá mesclar todos os resultados de saída retornadosrun()em um único arquivo chamadooutput_file_name.summary_onlynão irá mesclar os resultados da saída e calculará apenaserror_threshold.settings.output_file_nameO nome do arquivo de saída de pontuação em lote para append_rowoutput_action.settings.retry_settings.max_retriesO número de tentativas máximas para uma falha scoring_scriptrun().settings.retry_settings.timeoutO tempo limite em segundos para um scoring_scriptrun()para pontuar um mini lote.settings.error_thresholdO número de falhas na pontuação do arquivo de entrada que devem ser ignoradas. Se a contagem de erros de toda a entrada ficar acima desse valor, o trabalho de pontuação em lote será terminado. O exemplo usa -1, que indica que qualquer número de falhas é permitido sem encerrar o trabalho de pontuação em lote.settings.logging_levelDetalhamento do log. Os valores no detalhamento crescente são: WARNING, INFO e DEBUG. settings.environment_variablesDicionário de pares nome-valor da variável de ambiente a definir para cada trabalho de pontuação em lotes. Criar a implantação:
Execute o código a seguir para criar uma implantação em lote sob o ponto de extremidade de lote e defina-la como a implantação padrão.
az ml batch-deployment create --file deployment-torch/deployment.yml --endpoint-name $ENDPOINT_NAME --set-defaultDica
O parâmetro
--set-defaultdefine a implantação recém-criada como a implantação padrão do ponto de extremidade. É uma maneira conveniente de criar uma nova implantação padrão do ponto de extremidade, especialmente para a primeira criação da implantação. Como prática recomendada para cenários de produção, talvez você queira criar uma nova implantação sem defini-la como padrão. Verifique se a implantação funciona conforme o esperado e atualize a implantação padrão mais tarde. Para obter mais informações sobre a implementação deste processo, consulte a seção Implantar um novo modelo.Verificar detalhes de implantação e ponto de extremidade do lote.
Use
showpara verificar detalhes de implantação e ponto de extremidade. Para verificar uma implantação em lote, execute o seguinte código:DEPLOYMENT_NAME="mnist-torch-dpl" az ml batch-deployment show --name $DEPLOYMENT_NAME --endpoint-name $ENDPOINT_NAME

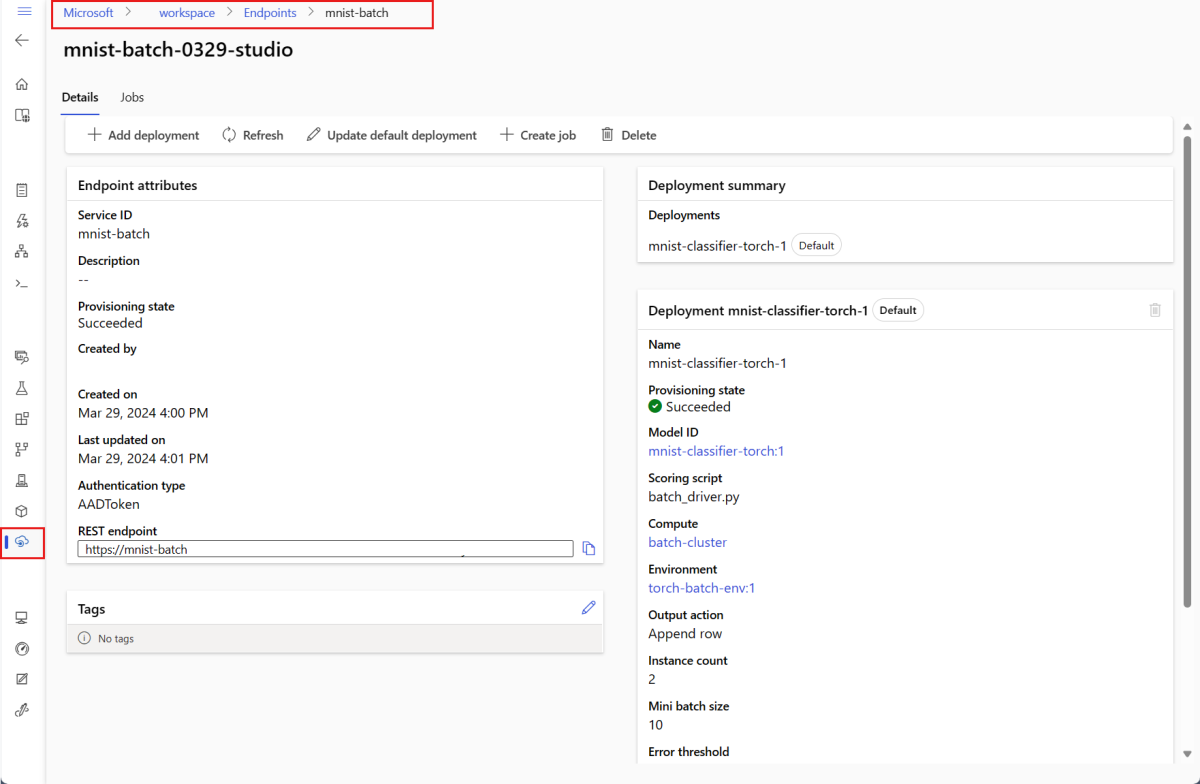
Executar pontos de extremidade em lote e resultados de acesso
A invocação de um ponto de extremidade em lote dispara um trabalho de pontuação em lotes. O trabalho name é retornado da resposta da invocação e poderá ser usado para acompanhar o andamento da pontuação em lote. Ao executar modelos de pontuação em pontos de extremidade em lote, você precisa especificar o caminho para os dados de entrada para que os pontos de extremidade possam encontrar os dados que você deseja pontuar. O exemplo a seguir mostra como iniciar um novo trabalho sobre uma amostra de dados do conjunto de dados do MNIST armazenados em uma Conta de Armazenamento do Microsoft Azure.
Você pode executar e invocar um ponto de extremidade em lote usando a CLI do Azure, o SDK do Azure Machine Learning ou pontos de extremidade REST. Para obter mais detalhes sobre essas opções, consulte Criar trabalhos e dados de entrada para pontos de extremidade em lotes.
Observação
Como funciona a paralelização?
As implantações em lote distribuem o trabalho no nível do arquivo, o que significa que uma pasta que contém 100 arquivos com minilotes de 10 arquivos gerará 10 lotes de 10 arquivos cada. Observe que isso acontece independentemente do tamanho dos arquivos envolvidos. Se os arquivos forem grandes demais para serem processados em minilotes grandes, sugerimos que você divida os arquivos em arquivos menores para obter um nível mais alto de paralelismo ou diminuir o número de arquivos por minilote. Atualmente, as implantações em lote não podem considerar distorções na distribuição de tamanho de um arquivo.
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --input-type uri_folder --query name -o tsv)



Os pontos de extremidade de lote dão suporte para a leitura de arquivos ou pastas localizados em diferentes locais. Para saber mais sobre os tipos com suporte e como especificá-los, confira Como acessar dados a partir de trabalhos de ponto de extremidade em lotes.
Monitorar o progresso da execução do trabalho em lotes
Os trabalhos de pontuação em lote geralmente levam algum tempo para processar todo o conjunto de entradas.
O código a seguir verifica o status do trabalho e gera um link para o Estúdio do Azure Machine Learning para mostrar mais detalhes.
az ml job show -n $JOB_NAME --web

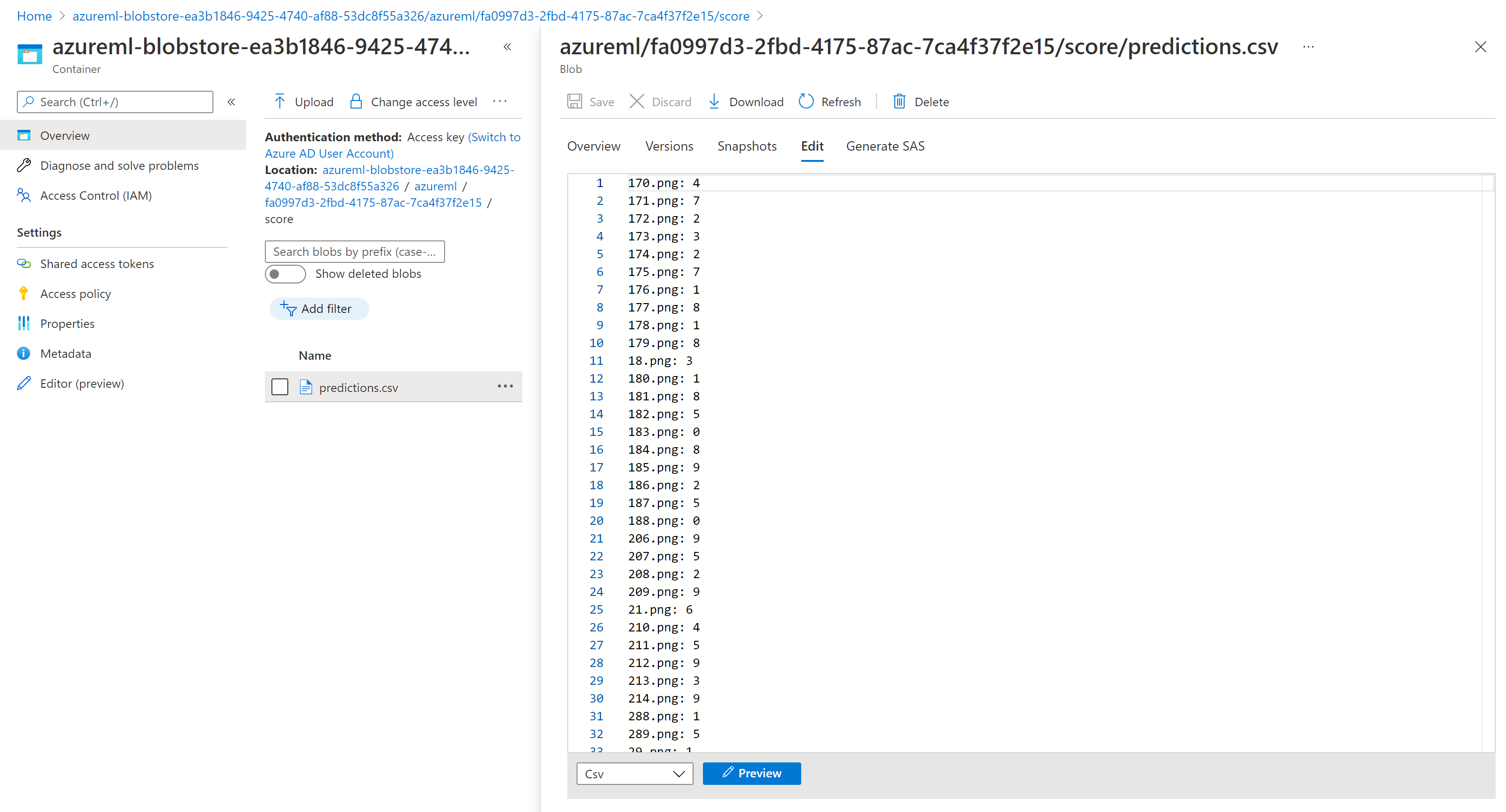
Verificar os resultados da pontuação em lote
As saídas do trabalho são armazenadas no armazenamento em nuvem, seja no armazenamento padrão de blobs do espaço de trabalho, ou no armazenamento especificado por você. Para saber como alterar os padrões, consulte Configurar o local de saída. As etapas a seguir permitem que você exiba os resultados da pontuação no Gerenciador de Armazenamento do Microsoft Azure quando o trabalho for concluído:
Execute o código a seguir para abrir o trabalho de pontuação em lotes no Estúdio do Azure Machine Learning. O link do estúdio do trabalho também está incluído na resposta de
invoke, como o valor deinteractionEndpoints.Studio.endpoint.az ml job show -n $JOB_NAME --webNo grafo do trabalho, selecione a etapa
batchscoring.Selecione a guia Saídas + logs e, em seguida, selecione Mostrar saídas de dados.
Em Saídas de dados, selecione o ícone para abrir Gerenciador de Armazenamento.

Os resultados da pontuação no Gerenciador de Armazenamento são semelhantes à seguinte página de exemplo:


Configurar a localização de saída
Por padrão, os resultados da pontuação em lote são armazenados no armazenamento de blobs padrão do workspace dentro de uma pasta nomeada por nome do trabalho (um GUID gerado pelo sistema). Você poderá configurar o local em que as saídas de pontuação serão armazenadas ao invocar o ponto de extremidade em lote.
Use output-path para configurar qualquer pasta em um conjunto de dados registrado do Azure Machine Learning. A sintaxe para a --output-path é a mesma --input ao especificar uma pasta, ou seja, azureml://datastores/<datastore-name>/paths/<path-on-datastore>/. Use --set output_file_name=<your-file-name> para configurar um novo nome de arquivo de saída.
OUTPUT_FILE_NAME=predictions_`echo $RANDOM`.csv
OUTPUT_PATH="azureml://datastores/workspaceblobstore/paths/$ENDPOINT_NAME"
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --output-path $OUTPUT_PATH --set output_file_name=$OUTPUT_FILE_NAME --query name -o tsv)

Aviso
Você precisa usar uma localização de saída exclusiva. Se o arquivo de saída existir, o trabalho de pontuação em lote falhará.
Importante
Ao contrário das entradas, as saídas só podem ser armazenadas em armazenamentos de dados do Azure Machine Learning executados em contas de armazenamento de blobs.
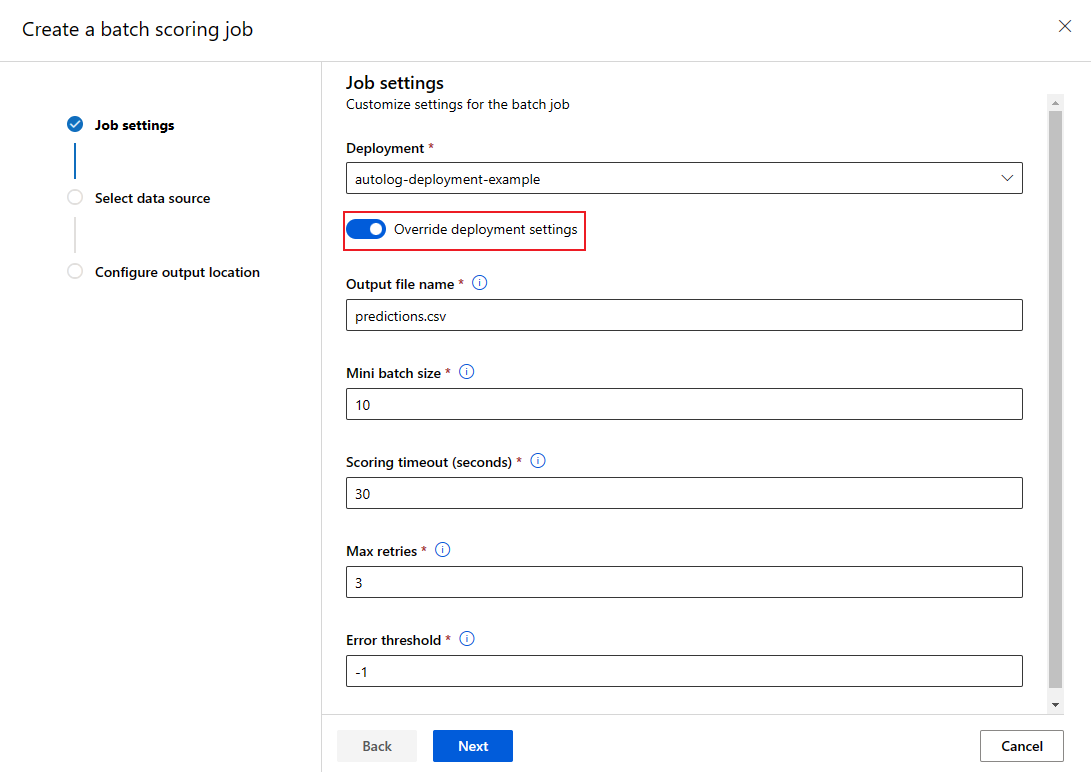
Substituir a configuração de implantação para cada trabalho
Quando você invoca um ponto de extremidade em lote, algumas configurações podem ser substituídas para fazer o melhor uso dos recursos de computação e melhorar o desempenho. As seguintes configurações podem ser definidas por trabalho:
- Contagem de instâncias: use essa configuração para substituir o número de instâncias a serem solicitadas do cluster de computação. Por exemplo, para um volume maior de entradas de dados, talvez você queira usar mais instâncias para acelerar a pontuação em lote de ponta a ponta.
- Tamanho do minilote: use esta configuração para substituir o número de arquivos a serem incluídos em cada minilote. O número de minilotes é decidido pelo total de contagens de arquivo de entrada e tamanho do minilote. Um minilote menor gera mais minilotes. Mini lotes podem ser executados em paralelo, mas pode haver sobrecarga extra de agendamento e invocação.
- Outras configurações, como tentativas máximas, tempo limite e limite de erro podem ser substituídas. Essas configurações podem afetar o tempo de pontuação em lote de ponta a ponta para diferentes cargas de trabalho.
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --mini-batch-size 20 --instance-count 5 --query name -o tsv)
Adicionar implantações a um ponto de extremidade
Quando você tiver um ponto de extremidade em lote com uma implantação, poderá continuar refinando seu modelo e adicionando novas implantações. Os pontos de extremidade do lote continuarão atendendo à implantação padrão enquanto você desenvolve e implanta novos modelos no mesmo ponto de extremidade. As implantações não afetam uma à outra.
Neste exemplo, você adiciona uma segunda implantação que usa um modelo criado com o Keras e o TensorFlow para resolver o mesmo problema do MNIST.
Adicionar uma segunda implantação
Crie um ambiente em que a implantação em lote será executada. Inclua no ambiente qualquer dependência que seu código exija para execução. Você também precisa adicionar a biblioteca
azureml-core, pois ela é necessária para que as implantações em lote funcionem. A definição de ambiente a seguir tem as bibliotecas necessárias para executar um modelo com o TensorFlow.A definição de ambiente é incluída na própria definição de implantação como um ambiente anônimo.
environment: name: batch-tensorflow-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yamlO arquivo Conda usado tem a seguinte aparência:
deployment-keras/environment/conda.yaml
name: tensorflow-env channels: - conda-forge dependencies: - python=3.8.5 - pip - pip: - pandas - tensorflow - pillow - azureml-core - azureml-dataset-runtime[fuse]Crie um script de pontuação para o modelo:
deployment-keras/code/batch_driver.py
import os import numpy as np import pandas as pd import tensorflow as tf from typing import List from os.path import basename from PIL import Image from tensorflow.keras.models import load_model def init(): global model # AZUREML_MODEL_DIR is an environment variable created during deployment model_path = os.path.join(os.environ["AZUREML_MODEL_DIR"], "model") # load the model model = load_model(model_path) def run(mini_batch: List[str]) -> pd.DataFrame: print(f"Executing run method over batch of {len(mini_batch)} files.") results = [] for image_path in mini_batch: data = Image.open(image_path) data = np.array(data) data_batch = tf.expand_dims(data, axis=0) # perform inference pred = model.predict(data_batch) # Compute probabilities, classes and labels pred_prob = tf.math.reduce_max(tf.math.softmax(pred, axis=-1)).numpy() pred_class = tf.math.argmax(pred, axis=-1).numpy() results.append( { "file": basename(image_path), "class": pred_class[0], "probability": pred_prob, } ) return pd.DataFrame(results)Criar uma definição de implantação
deployment-keras/deployment.yml
$schema: https://azuremlschemas.azureedge.net/latest/modelBatchDeployment.schema.json name: mnist-keras-dpl description: A deployment using Keras with TensorFlow to solve the MNIST classification dataset. endpoint_name: mnist-batch type: model model: name: mnist-classifier-keras path: model code_configuration: code: code scoring_script: batch_driver.py environment: name: batch-tensorflow-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yaml compute: azureml:batch-cluster resources: instance_count: 1 settings: max_concurrency_per_instance: 2 mini_batch_size: 10 output_action: append_row output_file_name: predictions.csvCriar a implantação:
Execute o código a seguir para criar uma implantação em lote sob o ponto de extremidade de lote e defina-la como a implantação padrão.
az ml batch-deployment create --file deployment-keras/deployment.yml --endpoint-name $ENDPOINT_NAMEDica
O parâmetro
--set-defaultestá ausente nesse caso. Como prática recomendada para cenários de produção, crie uma nova implantação sem defini-la como padrão. Em seguida, verifique e atualize a implantação padrão mais tarde.
Testar uma implantação em lote não padrão
Para testar a nova implantação não padrão, você precisa saber o nome da implantação que deseja executar.
DEPLOYMENT_NAME="mnist-keras-dpl"
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --deployment-name $DEPLOYMENT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --input-type uri_folder --query name -o tsv)
Observe que --deployment-name é usado para especificar a implantação para execução. Esse parâmetro permite invoke uma implantação não padrão sem atualizar a implantação padrão do ponto de extremidade em lote.
Atualizar a implantação em lote padrão
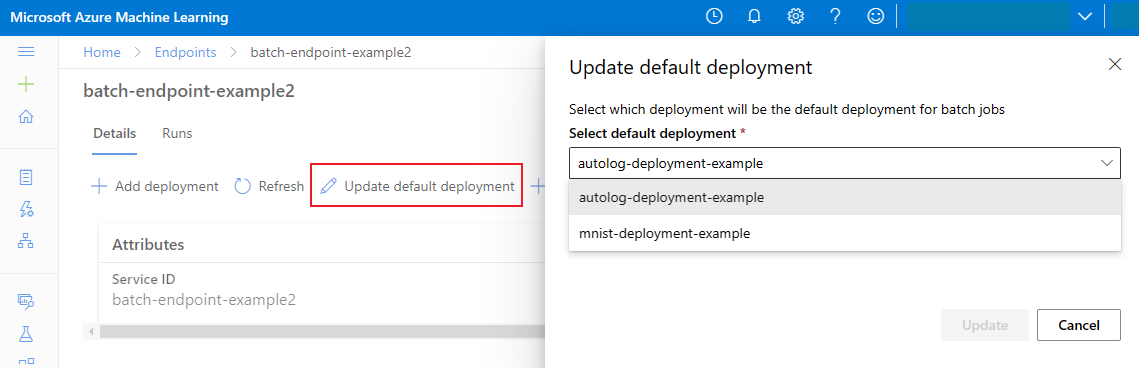
Embora você possa invocar uma implantação específica dentro de um ponto de extremidade, geralmente desejará invocar o ponto de extremidade em si e permitir que o ponto de extremidade decida qual implantação usar - a implantação padrão. Você pode alterar a implantação padrão (e, consequentemente, alterar o modelo que atende à implantação) sem alterar seu contrato com o usuário invocando o ponto de extremidade. Use o seguinte código para atualizar a implantação padrão:
az ml batch-endpoint update --name $ENDPOINT_NAME --set defaults.deployment_name=$DEPLOYMENT_NAME
Excluir o ponto de extremidade em lote e a implantação
Se você não usar a implantação em lote antiga, exclua-a executando o código a seguir. --yes é usado para confirmar a exclusão.
az ml batch-deployment delete --name mnist-torch-dpl --endpoint-name $ENDPOINT_NAME --yes
Execute o código a seguir para excluir o ponto de extremidade em lote e todas as implantações subjacentes. Os trabalhos de pontuação em lote não serão excluídos.
az ml batch-endpoint delete --name $ENDPOINT_NAME --yes