Estruturação de dados com pools do Apache Spark (preterida)
APLICA-SE A:  SDK do Python azureml v1
SDK do Python azureml v1
Aviso
A integração do Azure Synapse Analytics com o Azure Machine Learning, disponível no SDK do Python v1, foi preterida. Os usuários ainda podem usar o workspace do Synapse, registrado no Azure Machine Learning, como um serviço vinculado. No entanto, um novo workspace do Synapse não pode mais ser registrado no Azure Machine Learning como um serviço vinculado. Recomendamos o uso de computação do Spark sem servidor e Pools do Spark do Synapse anexados, disponíveis na CLI v2 e no SDK do Python v2. Para obter mais informações, visite https://aka.ms/aml-spark.
Neste artigo, você vai aprender a realizar tarefas de estruturação de dados de maneira interativa em uma sessão dedicada do Synapse, com a plataforma Azure Synapse Analytics, em um notebook Jupyter. Essas tarefas dependem do SDK do Azure Machine Learning para Python. Para obter mais informações sobre os pipelines do Azure Machine Learning, acesse Como usar o Apache Spark (da plataforma Azure Synapse Analytics) no seu pipeline de machine learning (versão prévia). Para saber mais como usar o Azure Synapse Analytics com um workspace do Azure Synapse, acesse a série de introdução ao Azure Synapse Analytics.
Integração entre o Azure Machine Learning e o Azure Synapse Analytics
Com a integração entre o Azure Synapse Analytics e o Azure Machine Learning (versão prévia), você pode anexar um pool do Apache Spark, com o suporte do Azure Synapse, para exploração e preparação interativas de dados. Com essa integração, você pode ter um recurso de computação dedicado para a estruturação de dados em escala, tudo no mesmo notebook do Python usado para treinar seus modelos de machine learning.
Pré-requisitos
Configurar o ambiente de desenvolvimento para instalar o SDK do Azure Machine Learning ou usar uma instância de computação do Azure Machine Learning com o SDK já instalado
Instalar o SDK de Python do Azure Machine Learning
Criar um pool do Apache Spark usando o portal do Azure, as ferramentas da Web ou o Synapse Studio
Instale o pacote
azureml-synapse(versão prévia) com este código:pip install azureml-synapseVincule seu workspace do Azure Machine Learning e o workspace do Azure Synapse Analytics com o SDK do Azure Machine Learning para Python ou com o Estúdio do Azure Machine Learning
Anexar um pool do Synapse Spark como um destino de computação
Iniciar pool do Spark do Azure Synapse para tarefas de estruturação de dados
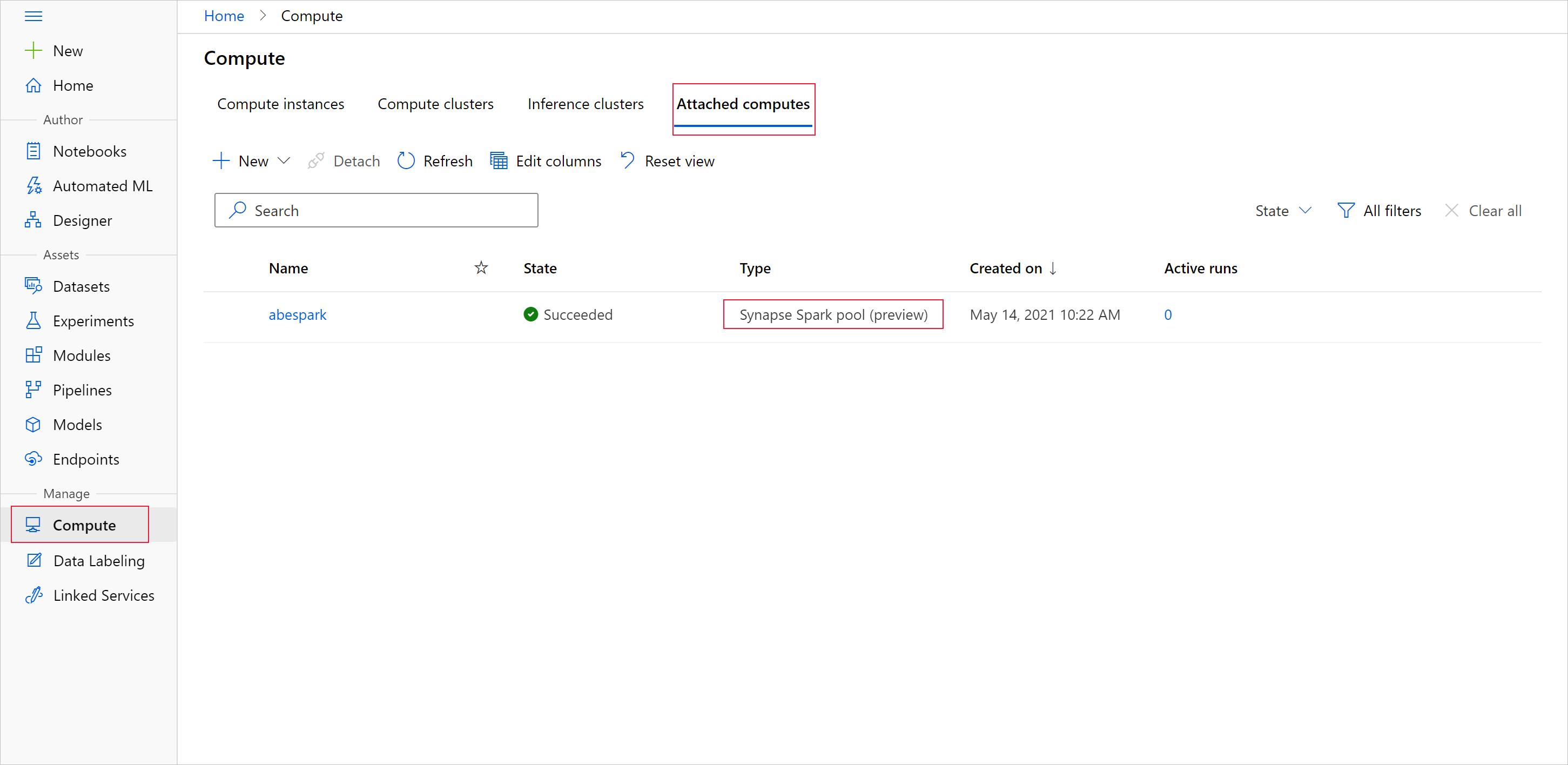
Para iniciar a preparação de dados com o pool do Apache Spark, especifique o nome de computação do Spark Synapse anexado. Encontre o nome com o Estúdio do Azure Machine Learning na guia Computações anexadas.
Importante
Para continuar o uso do pool do Apache Spark, você precisa indicar qual recurso de computação será usado em suas tarefas de estruturação de dados. Use %synapse para linhas simples de código e %%synapse para várias linhas:
%synapse start -c SynapseSparkPoolAlias
Após a sessão ser iniciada, você poderá verificar os metadados da sessão:
%synapse meta
Você pode especificar um ambiente do Azure Machine Learning a ser usado durante a sessão do Apache Spark. Somente as dependências Conda especificadas no ambiente terão efeito. Não há suporte para imagens do Docker.
Aviso
Não há suporte para dependências do Python especificadas em dependências Conda no ambiente em pools do Apache Spark. Atualmente, só há suporte para versões fixas do Python. Inclua sys.version_info no script para verificar sua versão do Python
Esse código criará a variável de ambiente myenv para instalar o azureml-core versão 1.20.0 e o numpy versão 1.17.0 antes do início da sessão. Em seguida, você pode incluir esse ambiente em sua instrução de sessão do Apache Spark start.
from azureml.core import Workspace, Environment
# creates environment with numpy and azureml-core dependencies
ws = Workspace.from_config()
env = Environment(name="myenv")
env.python.conda_dependencies.add_pip_package("azureml-core==1.20.0")
env.python.conda_dependencies.add_conda_package("numpy==1.17.0")
env.register(workspace=ws)
Para iniciar a preparação de dados com o pool do Apache Spark em seu ambiente personalizado, especifique o nome do pool do Apache Spark e o ambiente a ser usado durante a sessão do Apache Spark. Você pode fornecer a ID da assinatura, o grupo de recursos do workspace de machine learning e o nome do workspace de machine learning.
Importante
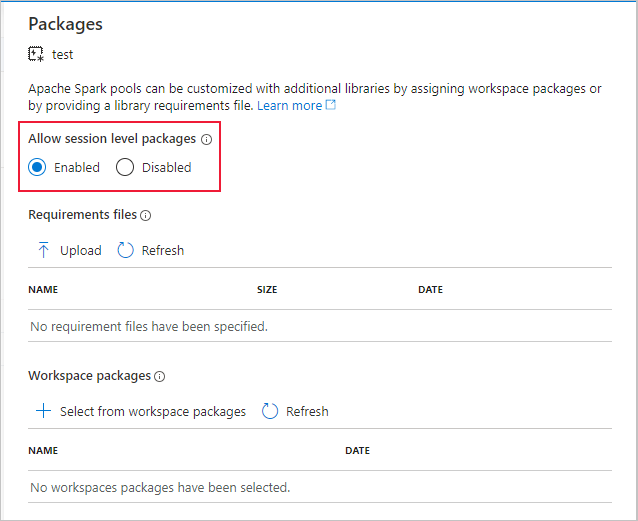
Habilite a opção Permitir pacotes no nível da sessão no workspace do Azure Synapse vinculado.
%synapse start -c SynapseSparkPoolAlias -e myenv -s AzureMLworkspaceSubscriptionID -r AzureMLworkspaceResourceGroupName -w AzureMLworkspaceName
Carregar dados do armazenamento
Após a sessão do Apache Spark ser iniciada, transmita os dados que você deseja preparar. O carregamento de dados tem suporte para o Armazenamento de Blobs do Azure e para o Azure Data Lake Storage, gerações 1 e 2.
Você tem duas opções para carregar os dados desses serviços de armazenamento:
Carregar os dados diretamente do armazenamento usando o caminho do HDFS (Sistema de Arquivos Distribuído Hadoop)
Transmitir os dados de um conjunto de dados do Azure Machine Learning existente
Para acessar esses serviços de armazenamento, você precisa de permissões de Leitor de Dados do Storage Blob. Para fazer write-back dos dados nesses serviços de armazenamento, você precisa das permissões de Colaborador de Dados do Blob de Armazenamento. Saiba mais sobre funções e permissões de armazenamento.
Carregar dados com o caminho do Sistema de Arquivos Distribuído Hadoop (HDFS)
Para carregar e transmitir dados do armazenamento com o caminho correspondente do HDFS, você precisa das suas credenciais de autenticação de acesso a dados disponíveis. Essas credenciais são diferentes, dependendo do tipo de armazenamento. Este código de exemplo mostra como transmitir dados de um Armazenamento de Blobs do Azure para um dataframe do Spark com seu token SAS (Assinatura de Acesso Compartilhado) ou a chave de acesso:
%%synapse
# setup access key or SAS token
sc._jsc.hadoopConfiguration().set("fs.azure.account.key.<storage account name>.blob.core.windows.net", "<access key>")
sc._jsc.hadoopConfiguration().set("fs.azure.sas.<container name>.<storage account name>.blob.core.windows.net", "<sas token>")
# read from blob
df = spark.read.option("header", "true").csv("wasbs://demo@dprepdata.blob.core.windows.net/Titanic.csv")
Este código de exemplo mostra como transmitir dados do ADLS Gen 1 (Azure Data Lake Storage Generation 1) com suas credenciais de entidade de serviço:
%%synapse
# setup service principal which has access of the data
sc._jsc.hadoopConfiguration().set("fs.adl.account.<storage account name>.oauth2.access.token.provider.type","ClientCredential")
sc._jsc.hadoopConfiguration().set("fs.adl.account.<storage account name>.oauth2.client.id", "<client id>")
sc._jsc.hadoopConfiguration().set("fs.adl.account.<storage account name>.oauth2.credential", "<client secret>")
sc._jsc.hadoopConfiguration().set("fs.adl.account.<storage account name>.oauth2.refresh.url",
"https://login.microsoftonline.com/<tenant id>/oauth2/token")
df = spark.read.csv("adl://<storage account name>.azuredatalakestore.net/<path>")
Este código de exemplo mostra como transmitir dados do ADLS Gen 2 (Azure Data Lake Storage Generation 2) com suas credenciais de entidade de serviço:
%%synapse
# setup service principal which has access of the data
sc._jsc.hadoopConfiguration().set("fs.azure.account.auth.type.<storage account name>.dfs.core.windows.net","OAuth")
sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth.provider.type.<storage account name>.dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider")
sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth2.client.id.<storage account name>.dfs.core.windows.net", "<client id>")
sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth2.client.secret.<storage account name>.dfs.core.windows.net", "<client secret>")
sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth2.client.endpoint.<storage account name>.dfs.core.windows.net",
"https://login.microsoftonline.com/<tenant id>/oauth2/token")
df = spark.read.csv("abfss://<container name>@<storage account>.dfs.core.windows.net/<path>")
Transmitir dados de conjuntos de dados registrados
Você também pode colocar um conjunto de dados registrado existente no seu workspace e fazer a preparação de dados nele, convertendo-o em um dataframe do Spark. Este exemplo faz a autenticação no workspace, obtém um TabularDataset registrado, blob_dset, que referencia arquivos no armazenamento de blobs e converte o TabularDataset em um dataframe do Spark. Ao converter seus conjuntos de dados em dataframes do Spark, você pode usar as bibliotecas de exploração e preparação de dados do pyspark.
%%synapse
from azureml.core import Workspace, Dataset
subscription_id = "<enter your subscription ID>"
resource_group = "<enter your resource group>"
workspace_name = "<enter your workspace name>"
ws = Workspace(workspace_name = workspace_name,
subscription_id = subscription_id,
resource_group = resource_group)
dset = Dataset.get_by_name(ws, "blob_dset")
spark_df = dset.to_spark_dataframe()
Executar tarefas de estruturação de dados
Após recuperar e explorar seus dados, realize tarefas de estruturação de dados. Este exemplo de código expande o exemplo do HDFS da seção anterior. Com base na coluna Sobrevivente, ela filtra os dados no dataframe df do Spark e nos grupos que listam o conteúdo por Idade:
%%synapse
from pyspark.sql.functions import col, desc
df.filter(col('Survived') == 1).groupBy('Age').count().orderBy(desc('count')).show(10)
df.show()
Salvar dados para armazenamento e interromper uma sessão do Spark
Após concluir a exploração e a preparação dos dados, armazene seus dados preparados para uso posterior em sua conta de armazenamento no Azure. Neste exemplo de código, os dados preparados são gravados de volta no Armazenamento de Blobs do Azure substituindo o arquivo Titanic.csv original do diretório training_data. Para fazer write-back no armazenamento, você precisa ter permissões de Colaborador de Dados do Storage Blob. Para saber mais, acesse Atribuir uma função do Azure para acesso aos dados de blob.
%% synapse
df.write.format("csv").mode("overwrite").save("wasbs://demo@dprepdata.blob.core.windows.net/training_data/Titanic.csv")
Depois de concluir a preparação de dados e salvar os dados preparados no armazenamento, encerre o uso do pool do Apache Spark com este comando:
%synapse stop
Criar um conjunto de dados para representar os dados preparados
Quando estiver pronto para consumir seus dados preparados para o treinamento de modelo, conecte-se ao armazenamento com um armazenamento de dados do Azure Machine Learning e especifique o arquivo que deseja usar com um conjunto de dados do Azure Machine Learning.
Este exemplo de código
- Pressupõe que você já tenha criado um armazenamento de dados que se conecta ao serviço de armazenamento no qual você salvou os dados preparados
- Recupera o armazenamento de dados existente,
mydatastore, do workspacewscom o método get(). - Cria um FileDataset,
train_ds, que referencia os arquivos de dados preparados, localizados no diretóriomydatastoretraining_data - Cria a variável
input1. Mais tarde, essa variável para pode disponibilizar os arquivos de dados do conjunto de dadostrain_dspara um destino de computação para suas tarefas de treinamento.
from azureml.core import Datastore, Dataset
datastore = Datastore.get(ws, datastore_name='mydatastore')
datastore_paths = [(datastore, '/training_data/')]
train_ds = Dataset.File.from_files(path=datastore_paths, validate=True)
input1 = train_ds.as_mount()
Usar um ScriptRunConfig para enviar uma execução de experimento para um pool do Spark do Azure Synapse
Se estiver pronto para automatizar e colocar em produção suas tarefas de estruturação de dados, você poderá enviar uma execução de experimento para um Pool do Synapse Spark anexado com o objeto ScriptRunConfig. De uma forma similar, se você tiver um pipeline do Azure Machine Learning, use o SynapseSparkStep para especificar o pool do Synapse Spark como o destino de computação para a etapa de preparação de dados em seu pipeline. A disponibilidade dos seus dados para o pool do Spark Synapse depende do tipo de conjunto de dados.
- Para um Filedataset, você pode usar o método
as_hdfs(). Quando a execução é enviada, o conjunto de dados é disponibilizado para o pool do Synapse Spark como um HFDS (Sistema de Arquivos Distribuído Hadoop) - No caso de um TabularDataset, você pode usar o método
as_named_input()
O exemplo de código a seguir
- Cria a variável
input2com base no FileDatasettrain_ds, criado no exemplo de código anterior - Cria a variável
outputcom a classeHDFSOutputDatasetConfiguration. Depois que a execução é concluída, essa classe nos permite salvar a saída da execução como o conjunto de dados,test, no armazenamento de dadosmydatastore. No workspace do Azure Machine Learning, o conjunto de dadostesté registrado sob o nomeregistered_dataset - Define as configurações que a execução deve usar para execução no pool do Synapse Spark
- Define os parâmetros de ScriptRunConfig para
- Usar o script
dataprep.pypara a execução - Especificar os dados que serão usados como entrada e como disponibilizá-los para o pool do Spark Synapse
- Especificar o local de armazenamento dos dados de saída
output
- Usar o script
from azureml.core import Dataset, HDFSOutputDatasetConfig
from azureml.core.environment import CondaDependencies
from azureml.core import RunConfiguration
from azureml.core import ScriptRunConfig
from azureml.core import Experiment
input2 = train_ds.as_hdfs()
output = HDFSOutputDatasetConfig(destination=(datastore, "test").register_on_complete(name="registered_dataset")
run_config = RunConfiguration(framework="pyspark")
run_config.target = synapse_compute_name
run_config.spark.configuration["spark.driver.memory"] = "1g"
run_config.spark.configuration["spark.driver.cores"] = 2
run_config.spark.configuration["spark.executor.memory"] = "1g"
run_config.spark.configuration["spark.executor.cores"] = 1
run_config.spark.configuration["spark.executor.instances"] = 1
conda_dep = CondaDependencies()
conda_dep.add_pip_package("azureml-core==1.20.0")
run_config.environment.python.conda_dependencies = conda_dep
script_run_config = ScriptRunConfig(source_directory = './code',
script= 'dataprep.py',
arguments = ["--file_input", input2,
"--output_dir", output],
run_config = run_config)
Para obter mais informações sobre run_config.spark.configuration e a configuração geral do Spark, acesse Classe SparkConfiguration e Documentação da configuração do Apache Spark.
Depois que você configurar o objeto ScriptRunConfig, você poderá enviar a execução.
from azureml.core import Experiment
exp = Experiment(workspace=ws, name="synapse-spark")
run = exp.submit(config=script_run_config)
run
Para obter mais informações, incluindo informações sobre o script dataprep.py usado neste exemplo, confira o notebook de exemplo.
Depois que você preparar os dados, use-os como entrada para seus trabalhos de treinamento. No exemplo de código acima, você especificará o registered_dataset como dados de entrada para os trabalhos de treinamento.
Notebooks de exemplo
Confira estes notebooks de exemplo para ver mais conceitos e demonstrações das funcionalidades de integração do Azure Synapse Analytics e do Azure Machine Learning:
- Execute uma sessão interativa do Spark a partir de um notebook no seu workspace do Azure Machine Learning.
- Envie uma execução de experimento do Azure Machine Learning com um pool do Spark Synapse como seu destino de computação.