Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Os agentes de IA estão transformando como os aplicativos interagem com os dados combinando LLMs (grandes modelos de linguagem) com ferramentas externas e bancos de dados. Os agentes habilitam a automação de fluxos de trabalho complexos, aprimoram a precisão da recuperação de informações e facilitam interfaces de linguagem natural para bancos de dados.
Este artigo explora como criar agentes inteligentes de IA que podem pesquisar e analisar seus dados no Banco de Dados do Azure para PostgreSQL. Ele percorre a instalação, a implementação e o teste usando um assistente de pesquisa legal como exemplo.
O que são agentes de IA?
Os agentes de IA vão além de chatbots simples combinando LLMs com ferramentas externas e bancos de dados. Ao contrário de LLMs autônomas ou sistemas RAG (geração aumentada de recuperação padrão), os agentes de IA podem:
- Plano: dividir tarefas complexas em etapas menores e sequenciais.
- Usar ferramentas: usar APIs, execução de código e sistemas de pesquisa para coletar informações ou executar ações.
- Percepção: entenda e processe entradas de várias fontes de dados.
- Lembre-se: armazene e lembre-se das interações anteriores para uma melhor tomada de decisão.
Ao conectar agentes de IA a bancos de dados como o Banco de Dados do Azure para PostgreSQL, os agentes podem fornecer respostas mais precisas e com reconhecimento de contexto com base em seus dados. Os agentes de IA vão além da conversa humana básica para executar tarefas com base na linguagem natural. Essas tarefas tradicionalmente exigiam lógica codificada. No entanto, os agentes podem planejar as tarefas necessárias para serem executadas com base no contexto fornecido pelo usuário.
Implementação de agentes de IA
A implementação de agentes de IA com o Banco de Dados do Azure para PostgreSQL envolve a integração de recursos avançados de IA com funcionalidades robustas de banco de dados para criar sistemas inteligentes e com reconhecimento de contexto. Usando ferramentas como pesquisa de vetor, inserções e Serviço do Foundry Agent, os desenvolvedores podem criar agentes que entendam consultas de linguagem natural, recuperem dados relevantes e forneçam insights acionáveis.
As seções a seguir descrevem o processo passo a passo para configurar, configurar e implantar agentes de IA. Esse processo permite a interação perfeita entre modelos de IA e seu banco de dados PostgreSQL.
Estruturas
Várias estruturas e ferramentas podem facilitar o desenvolvimento e a implantação de agentes de IA. Todas essas estruturas dão suporte ao uso do Banco de Dados do Azure para PostgreSQL como uma ferramenta:
- Serviço de Agente
- LangChain/LangGraph
- LlamaIndex
- Kernel Semântico
- AutoGen
- API de Assistentes do OpenAI
Exemplo de implementação
O exemplo deste artigo usa o Serviço de Agente para planejamento de agente, uso de ferramentas e percepção. Ele usa o Banco de Dados do Azure para PostgreSQL como uma ferramenta para recursos de pesquisa semântica e de banco de dados vetor.
As seções a seguir explicam a criação de um agente de IA que ajuda as equipes jurídicas a pesquisar casos relevantes para dar suporte a seus clientes no estado de Washington. O agente:
- Aceita consultas de linguagem natural sobre situações legais.
- Usa a pesquisa de vetor no Banco de Dados do Azure para PostgreSQL para encontrar precedentes de caso relevantes.
- Analisa e resume os resultados em um formato útil para profissionais jurídicos.
Pré-requisitos
Habilite e configure as extensões
azure_aiepg_vector.Implantar modelos
gpt-4o-minietext-embedding-small.Instalar o Visual Studio Code.
Instale a extensão do Python .
Instale o Python 3.11.x.
Instale a CLI do Azure (versão mais recente).
Observação
Você precisa da chave e do ponto de extremidade dos modelos implantados criados para o agente.
Como começar
Todos os conjuntos de dados de código e de exemplo estão disponíveis neste repositório GitHub.
Etapa 1: Configurar a pesquisa de vetor no Banco de Dados do Azure para PostgreSQL
Primeiro, prepare seu banco de dados para armazenar e pesquisar dados de casos legais usando inserções de vetor.
Configurar o ambiente
Se você estiver usando macOS e Bash, execute estes comandos:
python -m venv .pg-azure-ai
source .pg-azure-ai/bin/activate
pip install -r requirements.txt
Se você estiver usando o Windows e o PowerShell, execute estes comandos:
python -m venv .pg-azure-ai
.pg-azure-ai \Scripts\Activate.ps1
pip install -r requirements.txt
Se você estiver usando o Windows e cmd.exe, então executar estes comandos:
python -m venv .pg-azure-ai
.pg-azure-ai \Scripts\activate.bat
pip install -r requirements.txt
Configurar variáveis de ambiente
Crie um .env arquivo com suas credenciais:
AZURE_OPENAI_API_KEY=""
AZURE_OPENAI_ENDPOINT=""
EMBEDDING_MODEL_NAME=""
AZURE_PG_CONNECTION=""
Carregar documentos e vetores
O arquivo Python load_data/main.py serve como o ponto de entrada central para carregar dados no Banco de Dados do Azure para PostgreSQL. O código processa os dados para casos de exemplo, incluindo informações sobre casos em Washington.
O arquivo main.py:
- Cria extensões necessárias, define as configurações da API OpenAI e gerencia tabelas de banco de dados descartando as existentes e criando novas para armazenar dados de caso.
- Lê dados de um arquivo CSV e insere-os em uma tabela temporária e, em seguida, processa e transfere-os para a tabela principal.
- Adiciona uma nova coluna para inserções na tabela de casos e gera inserções para opiniões de caso usando a API do OpenAI. Ele armazena as inserções na nova coluna. O processo de inserção leva cerca de 3 a 5 minutos.
Para iniciar o processo de carregamento de dados, execute o seguinte comando no load_data diretório:
python main.py
Aqui está a saída de main.py:
Extensions created successfully
OpenAI connection established successfully
The case table was created successfully
Temp cases table created successfully
Data loaded into temp_cases_data table successfully
Data loaded into cases table successfully.
Adding Embeddings will take a while, around 3-5 mins.
Embeddings added successfully All Data loaded successfully!
Etapa 2: Criar uma ferramenta postgres para o agente
Em seguida, configure as ferramentas do agente de IA para recuperar dados do Postgres. Em seguida, use o SDK do Serviço do Agente para conectar seu agente de IA ao banco de dados postgres.
Defina uma função para o agente chamar
Comece definindo uma função para o agente chamar descrevendo sua estrutura e todos os parâmetros necessários em uma docstring. Inclua todas as definições de função em um único arquivo , legal_agent_tools.py. Em seguida, você pode importar o arquivo para o script principal.
def vector_search_cases(vector_search_query: str, start_date: datetime ="1911-01-01", end_date: datetime ="2025-12-31", limit: int = 10) -> str:
"""
Fetches the case information in Washington State for the specified query.
:param query(str): The query to fetch cases specifically in Washington.
:type query: str
:param start_date: The start date for the search defaults to "1911-01-01"
:type start_date: datetime, optional
:param end_date: The end date for the search, defaults to "2025-12-31"
:type end_date: datetime, optional
:param limit: The maximum number of cases to fetch, defaults to 10
:type limit: int, optional
:return: Cases information as a JSON string.
:rtype: str
"""
db = create_engine(CONN_STR)
query = """
SELECT id, name, opinion,
opinions_vector <=> azure_openai.create_embeddings(
'text-embedding-3-small', %s)::vector as similarity
FROM cases
WHERE decision_date BETWEEN %s AND %s
ORDER BY similarity
LIMIT %s;
"""
# Fetch case information from the database
df = pd.read_sql(query, db, params=(vector_search_query,datetime.strptime(start_date, "%Y-%m-%d"), datetime.strptime(end_date, "%Y-%m-%d"),limit))
cases_json = json.dumps(df.to_json(orient="records"))
return cases_json
Etapa 3: Criar e configurar o agente de IA com o Postgres
Agora, configure o agente de IA e integre-o à ferramenta Postgres. O src/simple_postgres_and_ai_agent.py do arquivo Python serve como o ponto de entrada central para criar e usar seu agente.
O arquivo simple_postgres_and_ai_agent.py:
- Inicializa o agente em seu projeto Foundry com um modelo específico.
- Adiciona a ferramenta Postgres para pesquisa de vetor em seu banco de dados durante a inicialização do agente.
- Configura um thread de comunicação. Esse thread é usado para enviar mensagens ao agente para processamento.
- Processa a consulta do usuário usando o agente e as ferramentas. O agente pode planejar com ferramentas para obter a resposta correta. Nesse caso de uso, o agente chama a ferramenta Postgres com base na assinatura da função e docstring para fazer uma pesquisa de vetor e recuperar os dados relevantes para responder à pergunta.
- Exibe a resposta do agente à consulta do usuário.
Localizar a cadeia de conexão do projeto na Foundry
Em seu projeto do Foundry, você encontra a cadeia de conexão do projeto na página de visão geral do projeto. Essa cadeia de caracteres é usada para conectar o projeto ao SDK do Serviço do Agente. Adicione essa cadeia de caracteres ao .env arquivo.
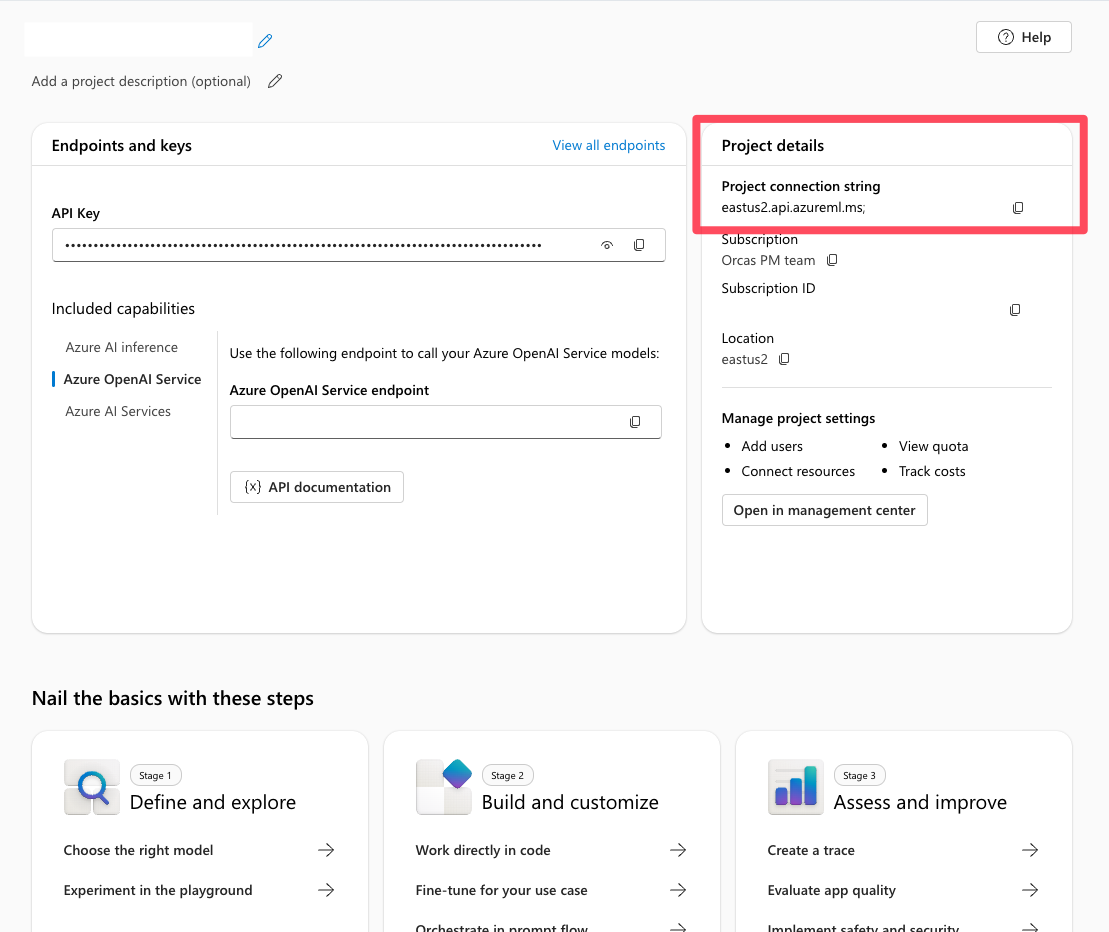
Configurar a conexão
Adicione essas variáveis ao arquivo .env no diretório raiz:
PROJECT_CONNECTION_STRING=" "
MODEL_DEPLOYMENT_NAME="gpt-4o-mini"
AZURE_TRACING_GEN_AI_CONTENT_RECORDING_ENABLED="true"
### Create the agent with tool access
We created the agent in the Foundry project and added the Postgres tools needed to query the database. The code snippet below is an excerpt from the file [simple_postgres_and_ai_agent.py](https://github.com/Azure-Samples/postgres-agents/blob/main/azure-ai-agent-service/src/simple_postgres_and_ai_agent.py).
# Create a Foundry client
project_client = AIProjectClient.from_connection_string(
credential=DefaultAzureCredential(),
conn_str=os.environ["PROJECT_CONNECTION_STRING"],
)
# Initialize the agent toolset with user functions
functions = FunctionTool(user_functions)
toolset = ToolSet()
toolset.add(functions)
agent = project_client.agents.create_agent(
model= os.environ["MODEL_DEPLOYMENT_NAME"],
name="legal-cases-agent",
instructions= "You are a helpful legal assistant who can retrieve information about legal cases.",
toolset=toolset
)
Criar um thread de comunicação
Este trecho de código mostra como criar uma thread do agente e uma mensagem, que o agente processa durante a execução.
# Create a thread for communication
thread = project_client.agents.create_thread()
# Create a message to thread
message = project_client.agents.create_message(
thread_id=thread.id,
role="user",
content="Water leaking into the apartment from the floor above. What are the prominent legal precedents in Washington regarding this problem in the last 10 years?"
)
Processar a solicitação
O snippet de código a seguir cria uma execução para o agente processar a mensagem e usar as ferramentas apropriadas para fornecer o melhor resultado.
Usando as ferramentas, o agente pode chamar o Postgres e realizar a pesquisa vetorial na consulta "Vazamento de água no apartamento do andar acima" para recuperar os dados necessários e responder melhor à pergunta.
from pprint import pprint
# Create and process an agent run in the thread with tools
run = project_client.agents.create_and_process_run(
thread_id=thread.id,
agent_id=agent.id
)
# Fetch and log all messages
messages = project_client.agents.list_messages(thread_id=thread.id)
pprint(messages['data'][0]['content'][0]['text']['value'])
Executar o agente
Para executar o agente, execute o seguinte comando no src diretório:
python simple_postgres_and_ai_agent.py
O agente produz um resultado semelhante usando a ferramenta Banco de Dados do Azure para PostgreSQL para acessar dados de caso salvos no banco de dados Postgres.
Aqui está um snippet de saída do agente:
1. Pham v. Corbett
Citation: Pham v. Corbett, No. 4237124
Summary: This case involved tenants who counterclaimed against their landlord for relocation assistance and breached the implied warranty of habitability due to severe maintenance issues, including water and sewage leaks. The trial court held that the landlord had breached the implied warranty and awarded damages to the tenants.
2. Hoover v. Warner
Citation: Hoover v. Warner, No. 6779281
Summary: The Warners appealed a ruling finding them liable for negligence and nuisance after their road grading project caused water drainage issues affecting Hoover's property. The trial court found substantial evidence supporting the claim that the Warners' actions impeded the natural water flow and damaged Hoover's property.
Etapa 4: testar e depurar com o playground do agente
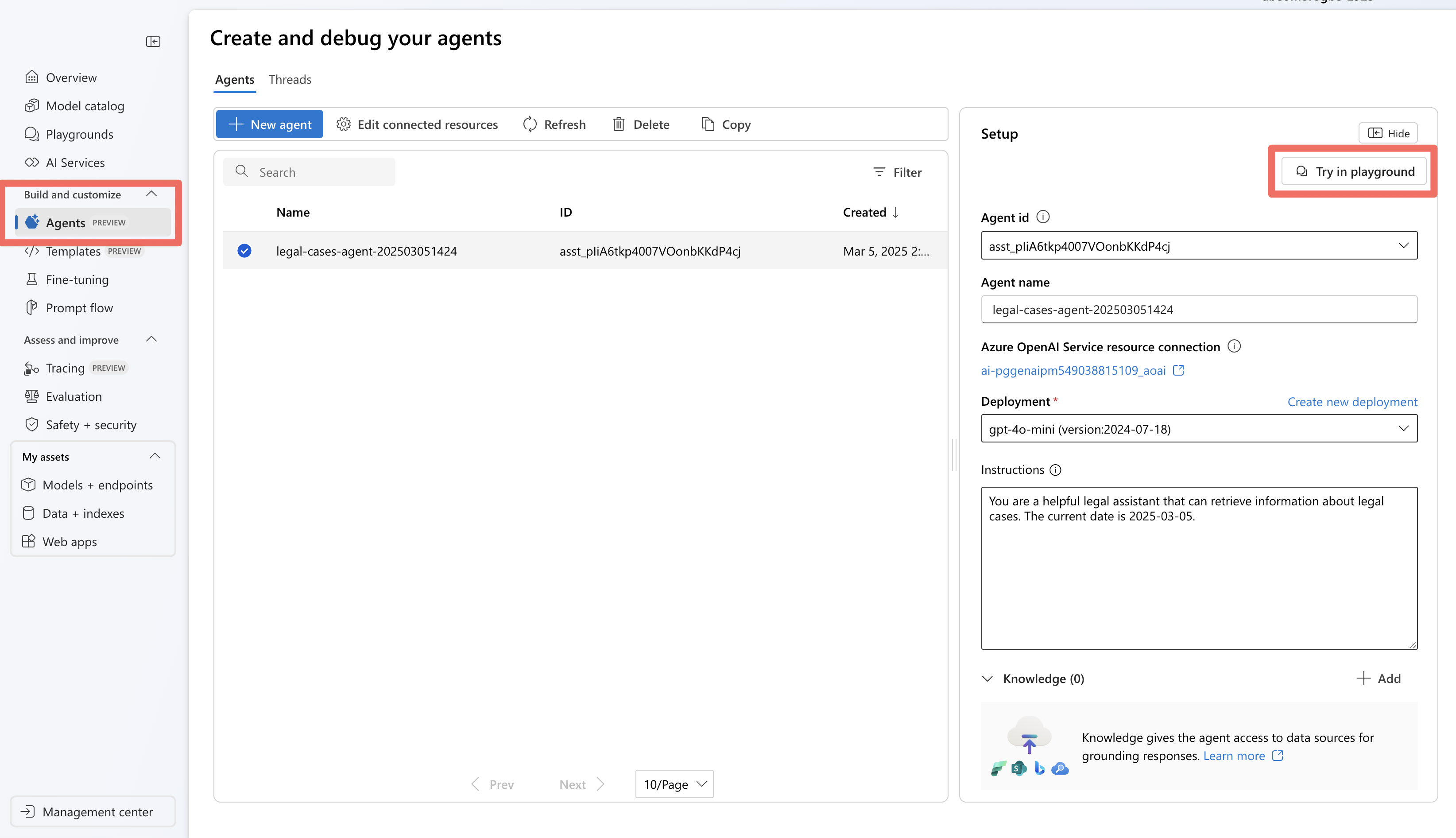
Depois de executar seu agente usando o SDK do Serviço do Agente, o agente será armazenado em seu projeto. É possível experimentar o agente no playground do agente:
Na Foundry, vá para a seção Agentes .
Encontre seu agente na lista e selecione-o para abri-lo.
Use a interface do playground para testar várias consultas jurídicas.
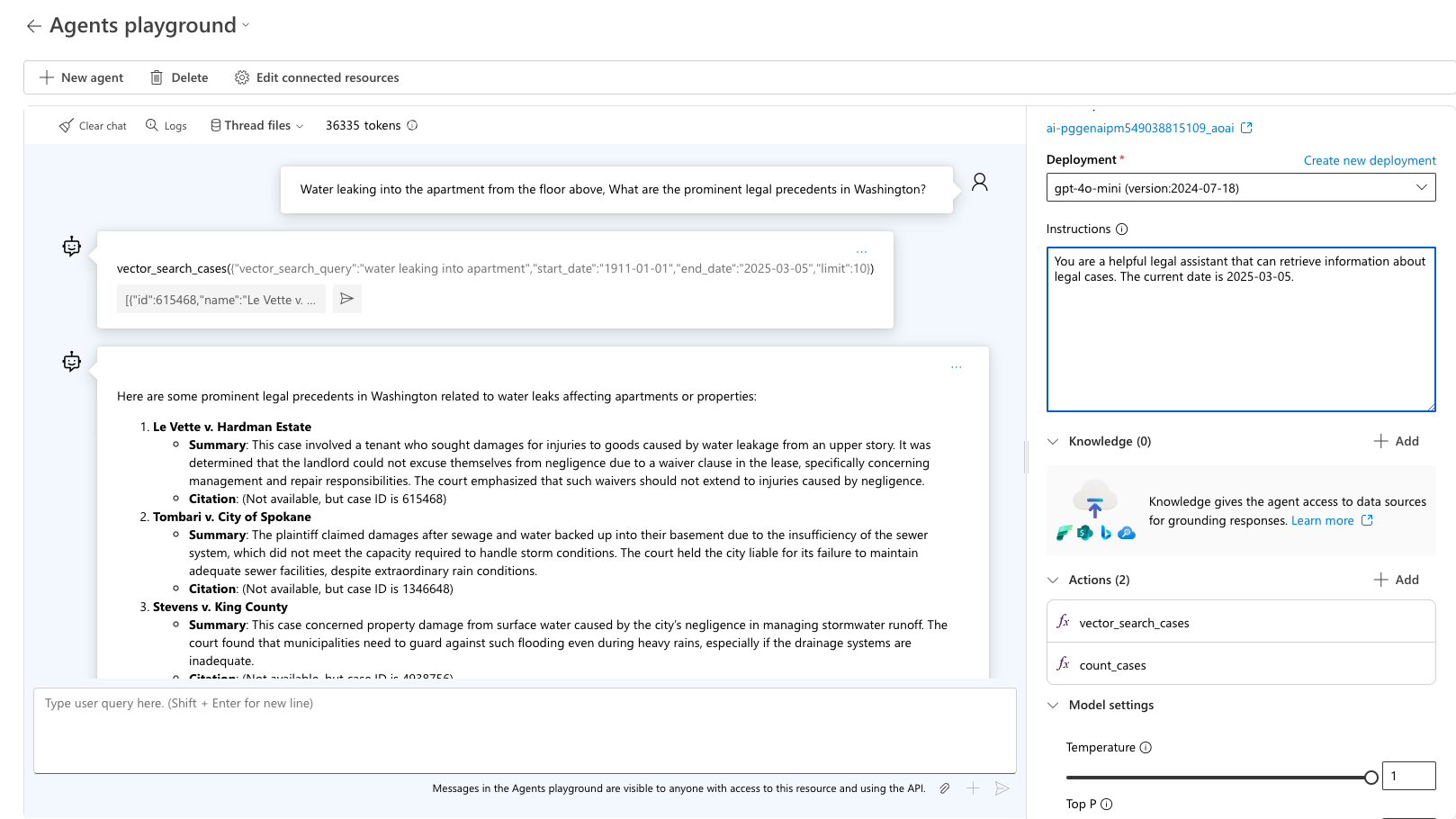
Teste a consulta "Água vazando para o apartamento do chão acima, Quais são os proeminentes precedentes legais em Washington?" O agente escolhe a ferramenta certa a ser usada e solicita a saída esperada para essa consulta. Use sample_vector_search_cases_output.json como a saída de exemplo.
Etapa 5: Depurar com rastreamento do Foundry
Quando for desenvolver o agente usando o SDK do Serviço do Agente, você pode depurar o agente com o rastreamento. O rastreamento permite que você depure as chamadas para ferramentas como o Postgres e veja como o agente orquestra cada tarefa.
No Foundry, vá para Rastreamento.
Para criar um novo recurso do Application Insights, selecione Criar novo. Para conectar um recurso existente, selecione um na caixa de nome de recurso do Application Insights e, em seguida, selecione Conectar.
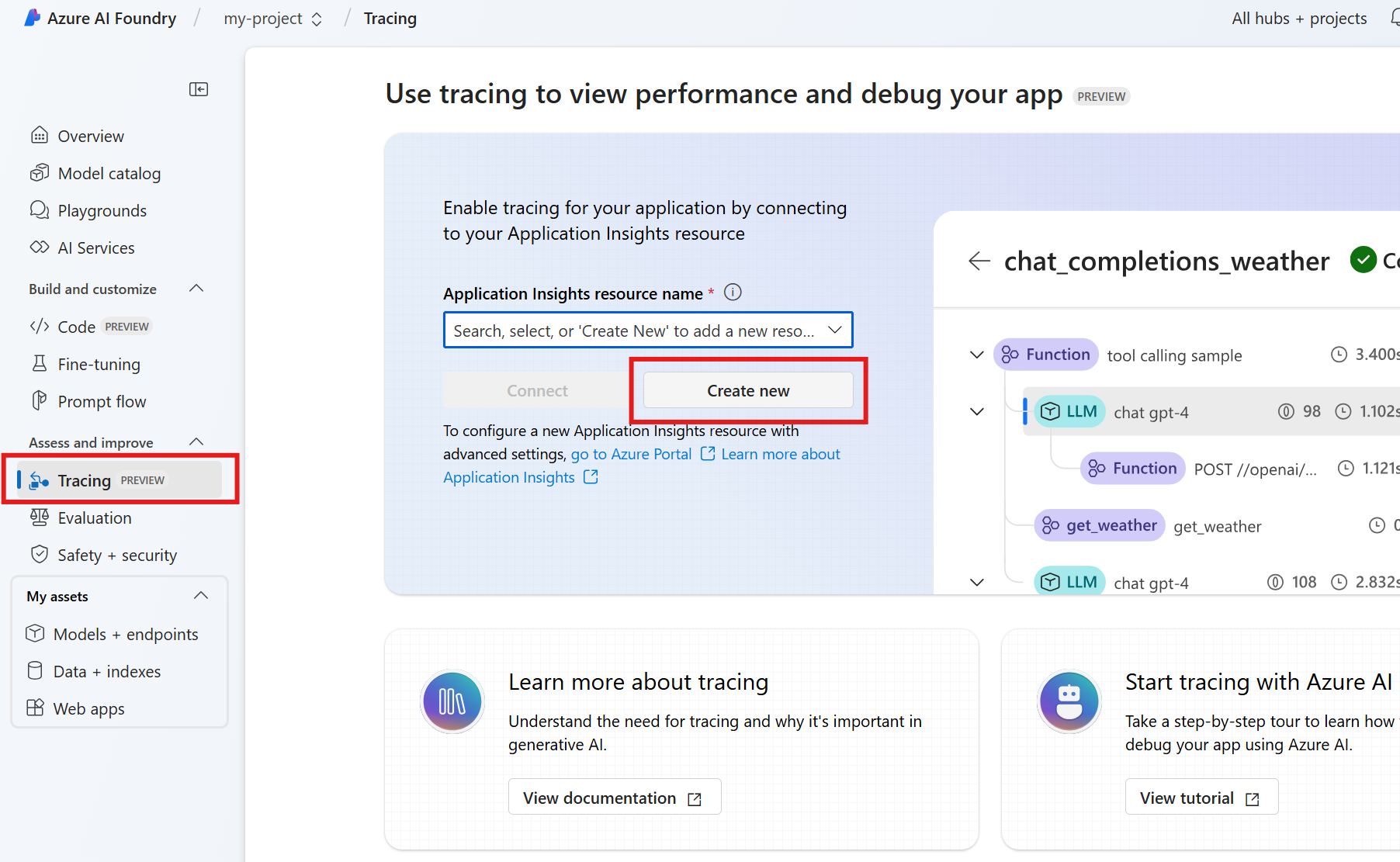
Exiba rastreamentos detalhados das operações do agente.
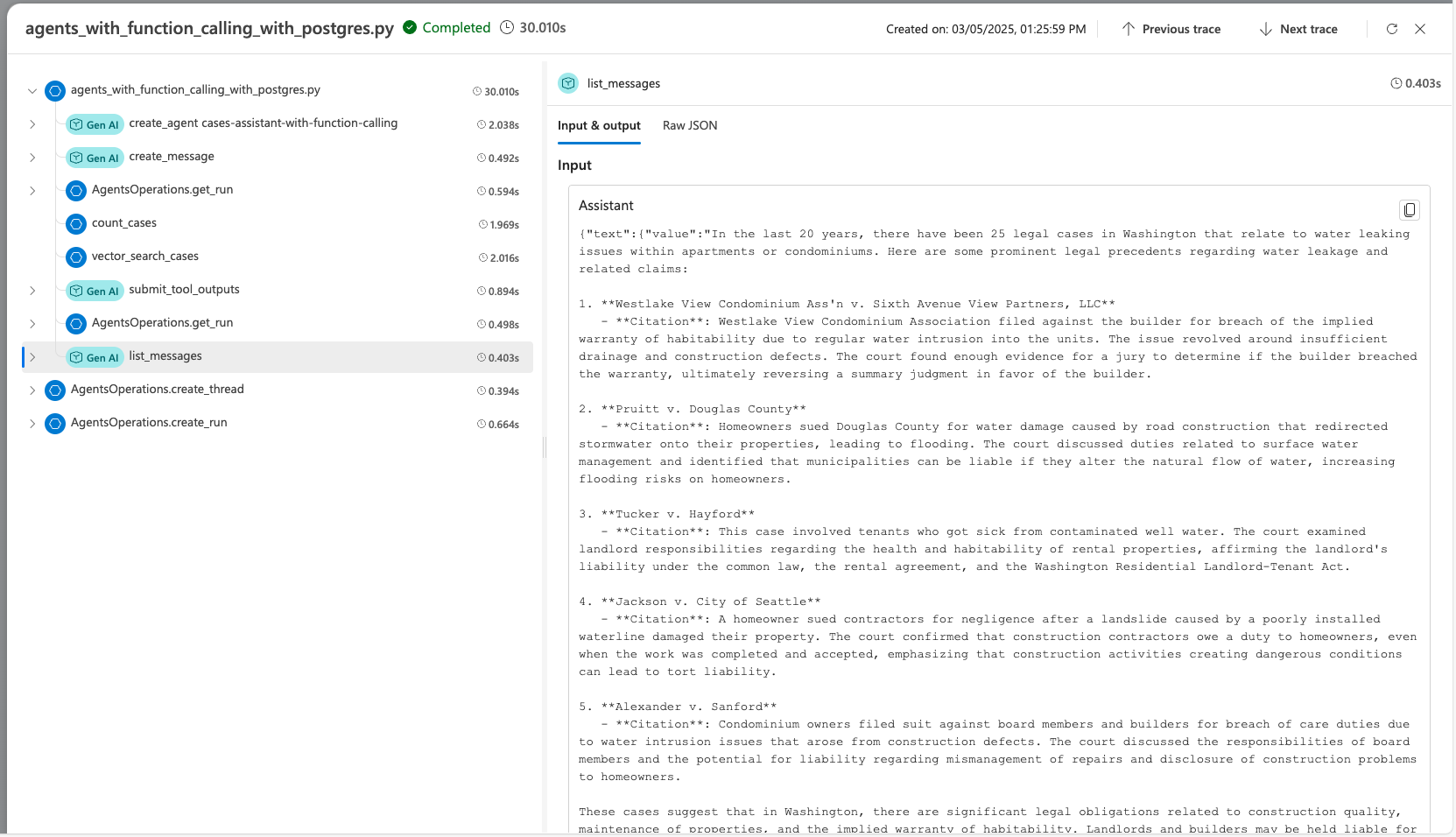
Saiba mais sobre como configurar o rastreamento com o agente de IA e o Postgres no arquivo advanced_postgres_and_ai_agent_with_tracing.py no GitHub.
Conteúdo relacionado
- Integrações do Banco de Dados do Azure para PostgreSQL para aplicativos de IA
- Usar LangChain com o Banco de Dados do Azure para PostgreSQL
- Gerar inserções de vetor com o Azure OpenAI no Banco de Dados do Azure para PostgreSQL
- Extensão de IA do Azure no Banco de Dados do Azure para PostgreSQL
- Criar uma pesquisa semântica com o Banco de Dados do Azure para PostgreSQL e o Azure OpenAI
- Habilitar e usar pgvector no Banco de Dados do Azure para PostgreSQL