Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Importante
O suporte do indexador do Microsoft Office SharePoint Online está em versão prévia pública. Ele é oferecido "no estado em que se encontra", sob termos de uso complementares e com suporte apenas de melhor esforço. As versões prévias do recurso não são recomendadas para cargas de trabalho de produção e não têm garantia de se tornarem disponíveis em geral.
Consulte a seção limitações conhecidas antes de começar.
Preencha este formulário para se registrar na versão prévia. Todas as solicitações são aprovadas automaticamente. Depois de preencher o formulário, use uma API REST de visualização para indexar seu conteúdo.
O artigo explica como configurar um indexador de pesquisa para indexar documentos armazenados em bibliotecas de documentos do SharePoint para pesquisa de texto completo do Azure AI Search. As etapas de configuração são as primeiras, seguidas por comportamentos e cenários
No Azure AI Search, um indexador extrai dados pesquisáveis e metadados de uma fonte de dados. O indexador do Microsoft Office SharePoint Online se conecta ao seu site do Microsoft Office SharePoint Online e indexa documentos de uma ou mais bibliotecas de documentos. O indexador fornece as seguintes funcionalidades:
- Indexa arquivos e metadados de uma ou mais bibliotecas de documentos.
- Indexa incrementalmente, pegando apenas os arquivos e metadados novos e alterados.
- Detecta o conteúdo excluído automaticamente. A exclusão de documentos na biblioteca é captada na próxima execução do indexador e o documento de pesquisa correspondente é removido do índice.
- Extrai texto e imagens normalizadas de documentos indexados automaticamente. Opcionalmente, você pode adicionar um conjunto de habilidades para enriquecimento de IA mais profundo, como OCR ou tradução de texto.
Pré-requisitos
Azure AI Search, tipo de preço básico ou superior.
SharePoint no serviço de nuvem do Microsoft 365 (o OneDrive não é uma fonte de dados com suporte).
Arquivos em uma biblioteca de documentos.
Formatos de documento com suporte
O indexador do Microsoft Office SharePoint Online pode extrair texto dos seguintes formatos de documento:
- CSV (consulte Indexando BLOBs CSV)
- EML
- EPUB
- GZ
- HTML
- JSON (consulte Como indexar blobs JSON)
- KML (XML para representações geográficas)
- Formatos do Microsoft Office: DOCX/DOC/DOCM, XLSX/XLS/XLSM, PPTX/PPT/PPTM, MSG (emails do Outlook) e XML (WORD XML 2003 e 2006)
- Abrir formatos de documento: ODT, ODS, ODP
- Arquivos de texto sem formatação (consulte também Como indexar texto sem formatação)
- RTF
- XML
- ZIP
Limitações e considerações
Estas são as limitações desse recurso:
O indexador pode indexar o conteúdo de formatos de documento com suporte em uma biblioteca de documentos. Não há suporte para indexador para Listas do SharePoint, conteúdo do site .ASPX ou arquivos do bloco de anotações do OneNote. Além disso, não há suporte para indexação de sub-sites recursivamente de um site específico.
Limitações incrementais de indexação:
Renomear uma pasta do SharePoint interrompe a indexação incremental. Uma pasta renomeada é tratada como novo conteúdo.
Os processos do Microsoft 365 que atualizam metadados do sistema de arquivos do SharePoint podem disparar a indexação incremental, mesmo que não haja outras alterações no conteúdo. Certifique-se de testar sua configuração e entender a contagem de processamento de documentos antes de usar o indexador e qualquer enriquecimento de IA.
Limitações de segurança:
Não há suporte para Private endpoint.
Não há suporte para bibliotecas de documentos ou conteúdo configurado para Acesso Condicional do Microsoft Entra ID.
Não há suporte para arquivos criptografados pelo usuário, arquivos protegidos pelo IRM (Information Rights Management), arquivos ZIP com senhas ou conteúdo criptografado semelhante.
Não há suporte para o modelo de autorização granular do SharePoint que determina o acesso por usuário no nível do documento. O indexador não integra essas permissões no índice. O conteúdo está disponível para qualquer pessoa que tenha acesso de leitura ao índice. Se você precisar de permissões no nível do documento, considere filtros de segurança para cortar resultados e automatizar a cópia das permissões em um nível de arquivo para um campo no índice.
Aqui estão algumas considerações ao usar este recurso:
Se você precisar criar um aplicativo Copilot ou RAG personalizado (Recuperação de Geração Aumentada) para conversar com dados do SharePoint, a Microsoft recomenda usar o Microsoft Copilot Studio em vez desse recurso de visualização.
Se você ainda precisar de uma solução personalizada de indexação de conteúdo do SharePoint Online usando o Azure AI Search em um ambiente de produção, apesar da recomendação de usar o Microsoft Copilot Studio, considere:
Criando um conector personalizado utilizando Webhooks do SharePoint, chamando a API do Microsoft Graph para exportar os dados para um contêiner de Blob do Azure e, em seguida, usar o indexador de blobs do Azure para indexação incremental.
Criando seu próprio fluxo de trabalho dos Aplicativos Lógicos do Azure usando o conector do SharePoint dos Aplicativos Lógicos do Azure e o conector de pesquisa de IA do Azure ao alcançar a Disponibilidade Geral. Você pode usar o fluxo de trabalho gerado pelo assistente do portal do Azure como ponto de partida e personalizá-lo no designer de Aplicativos Lógicos do Azure para incluir as etapas de transformação necessárias. O fluxo de trabalho do aplicativo lógico do Azure criado ao usar o assistente de pesquisa de IA do Azure para indexar dados do SharePoint Online é um fluxo de trabalho de consumo. Se você estiver configurando cargas de trabalho de produção, alterne para um fluxo de trabalho de aplicativo lógico padrão e aproveite seus recursos empresariais adicionais.
Independentemente da abordagem escolhida, seja criando um conector personalizado com ganchos do SharePoint ou criando um fluxo de trabalho dos Aplicativos Lógicos do Azure, certifique-se de implementar medidas de segurança robustas. Essas medidas incluem a configuração de links privados compartilhados, a configuração de firewalls, a preservação das permissões de usuário da origem e a honra dessas permissões no momento da consulta, entre outras. Você também deve auditar e monitorar regularmente o pipeline.
Configurar o indexador do SharePoint Online
Para configurar o indexador do SharePoint Online, use uma API REST de visualização. Esta seção fornece as etapas para isso.
Etapa 1 (opcional): habilitar identidade gerenciada atribuída pelo sistema
Habilite uma identidade gerenciada atribuída pelo sistema para detectar automaticamente o locatário no qual o serviço de pesquisa é provisionado.
Execute esta etapa se o site do SharePoint estiver no mesmo locatário que o serviço de pesquisa. Ignore-a se o site do SharePoint estiver em um locatário diferente. A identidade não é usada para indexação, apenas detecção de locatário. Você também pode ignorar esta etapa se quiser colocar a ID do locatário na cadeia de conexão.
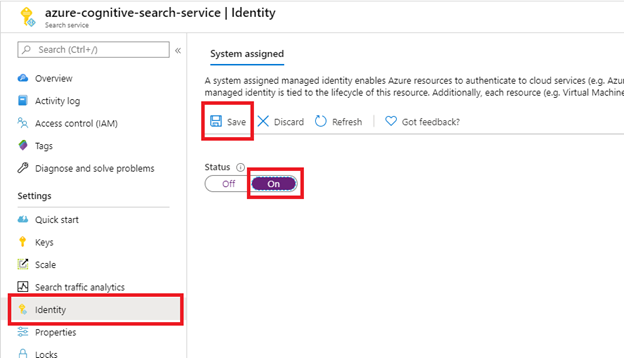
Depois de selecionar Salvar, você verá uma ID do objeto que foi atribuída ao seu serviço de pesquisa.
Etapa 2: decidir que permissões o indexador requer
O indexador do SharePoint Online oferece suporte a permissões delegadas e de aplicativo. Escolha quais permissões você deseja usar com base no seu cenário.
Recomendamos permissões baseadas em aplicativo. Consulte limitações para problemas conhecidos relacionados a permissões delegadas.
Permissões de aplicativo (recomendado), nas quais o indexador é executado sob a identidade do locatário do SharePoint com acesso a todos os sites e arquivos. O indexador requer um segredo do cliente. O indexador também exigirá aprovação do administrador de locatários para poder indexar qualquer conteúdo.
Permissões delegadas, em que o indexador é executado sob a identidade do usuário ou do aplicativo que envia a solicitação. O acesso a dados é limitado aos sites e arquivos aos quais o chamador tem acesso. Para dar suporte a permissões delegadas, o indexador exige um prompt de código de dispositivo para entrar em nome do usuário. As permissões delegadas pelo usuário impõem a expiração do token a cada 75 minutos, de acordo com as bibliotecas de segurança mais recentes usadas para implementar esse tipo de autenticação. Esse não é um comportamento que pode ser ajustado. Um token expirado requer indexação manual usando Executar Indexador (versão prévia). Por esse motivo, você deve usar permissões baseadas em aplicativos.
Etapa 3: criar um registro de aplicativo do Microsoft Entra
O indexador do SharePoint Online usa um aplicativo do Microsoft Entra para autenticação. Crie o registro do aplicativo no mesmo locatário que o Azure AI Search.
Entre no portal do Azure.
Pesquise ou navegue até Microsoft Entra ID e selecione Adicionar>Registros de Aplicativo.
Selecione + Novo Registro:
- Insira um nome para seu aplicativo.
- Selecione Único locatário.
- Ignore a etapa de designação de URI. Nenhuma URI de redirecionamento necessária.
- Selecione Registrar.
No painel de navegação em Gerenciar, selecione permissões de API e, em seguida, Adicione uma permissão e, em seguida, Microsoft Graph.
Se o indexador estiver usando permissões de aplicativo de API, selecione Permissões de aplicativo e adicione o seguinte:
- Aplicativo - Files.Read.All
- Aplicativo - Sites.Read.All

O uso de permissões de aplicativo significa que o indexador acessará o site do SharePoint no contexto do usuário. Portanto, quando você executar o indexador, ele terá acesso a todo o conteúdo no locatário do SharePoint, o que requer aprovação do administrador de locatários. Um segredo do cliente também é necessário para autenticação. A configuração do segredo do cliente é descrita posteriormente neste artigo.
Se o indexador estiver usando permissões delegadas de API, selecione Permissões delegadas e adicione o seguinte:
- Delegada - Files.Read.All
- Delegada - Sites.Read.All
- Delegada - User.Read
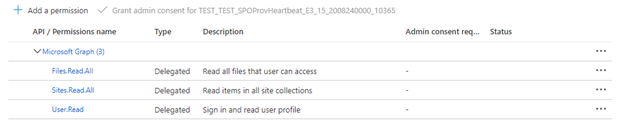
Permissões delegadas permitem que o cliente de pesquisa se conecte ao SharePoint sob a identidade de segurança do usuário atual.
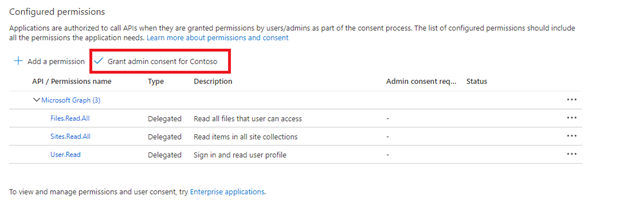
Dê o consentimento do administrador.
O consentimento do administrador de locatários é necessário ao usar permissões de aplicativo de API. Alguns locatários são bloqueados de tal forma que o consentimento do administrador de locatários também é necessário para essas permissões delegadas de API. Se uma dessas condições se aplicar, você precisará que um administrador de locatários conceda permissão para este aplicativo do Microsoft Entra antes de criar o indexador.
Selecione a guia Autenticação.
Defina Permitir fluxos de cliente público como Sim e, em seguida, selecione Salvar.
Selecione + Adicionar uma plataforma, em seguida, Aplicativos móveis e de área de trabalho, em seguida, verificação
https://login.microsoftonline.com/common/oauth2/nativecliente, em seguida, Configurar.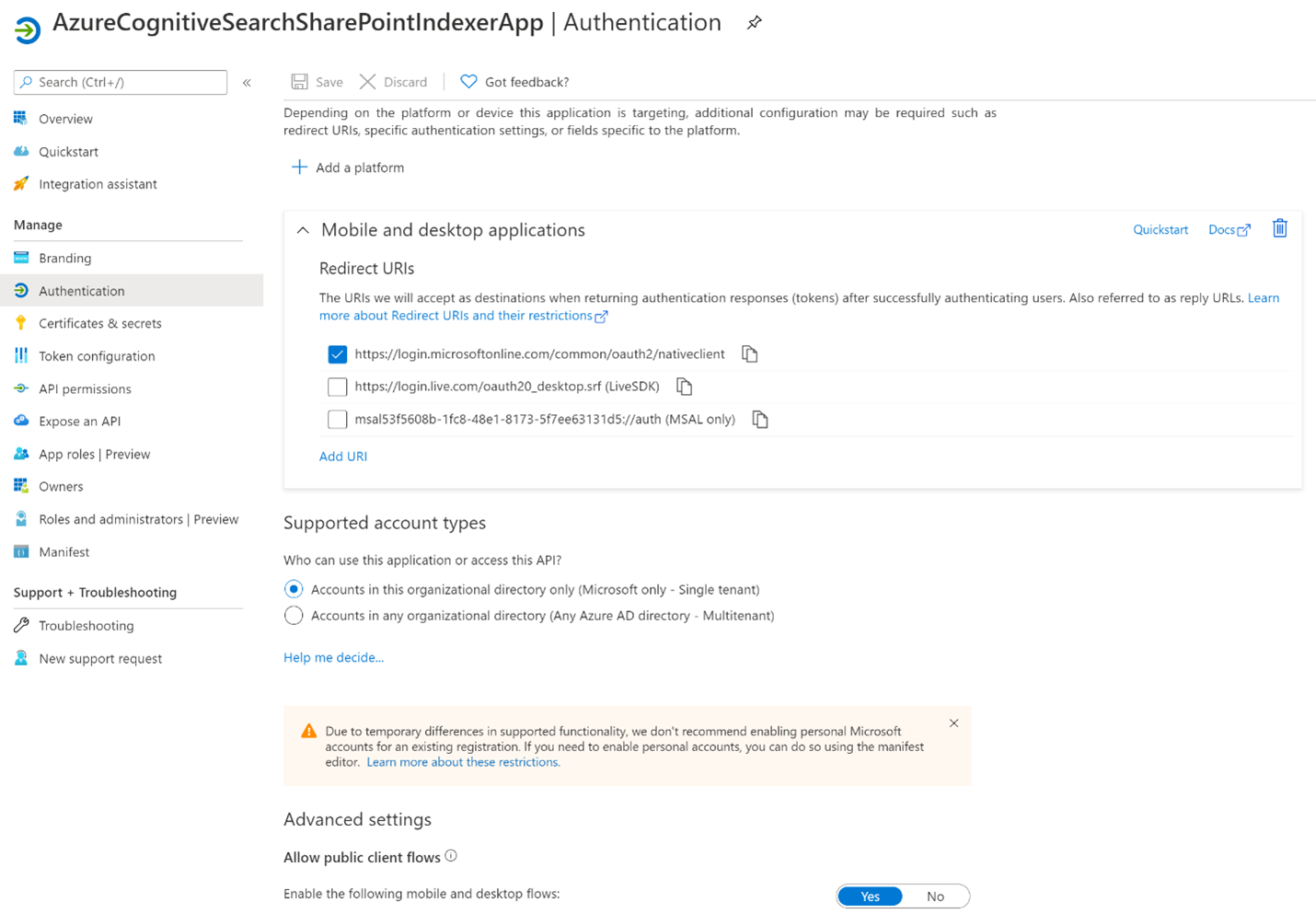
(Somente permissões de aplicativo de API) Para autenticação no aplicativo do Microsoft Entra usando permissões de aplicativo, o indexador requer um segredo do cliente.
Selecione Certificados e Segredos no menu à esquerda e, em seguida, Segredos do cliente e, por fim, Novo segredo do cliente.

No menu que aparece, insira uma descrição para o novo segredo do cliente. Ajuste a data de validade, se necessário. Se o segredo expirar, ele precisará ser recriado e o indexador precisará ser atualizado com o novo segredo.
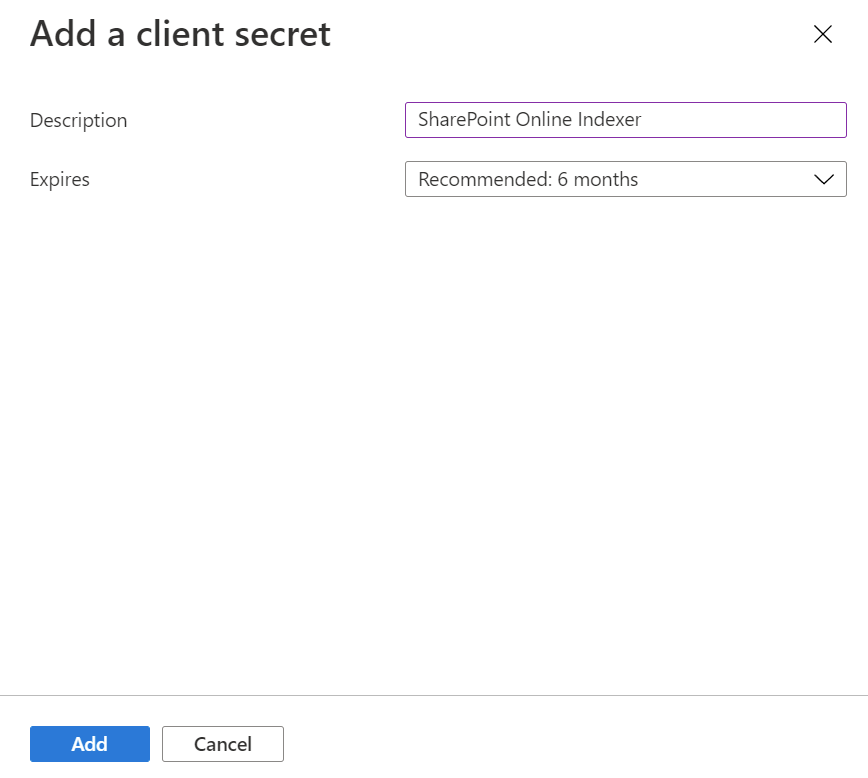
O novo segredo do cliente aparecerá na lista de segredos. Depois que você sair da página, o segredo não ficará mais visível, portanto, copie-o usando o botão copiar e salve-o em um local seguro.

Etapa 4: criar uma fonte de dados
A partir desta seção, use uma API REST de versão prévia para as etapas restantes. Recomendamos a API de versão prévia mais recente.
Uma fonte de dados especifica quais dados indexar, as credenciais e as políticas que identificam com eficiência as alterações nos dados (linhas novas, modificadas ou excluídas). Uma fonte de dados pode ser usada por vários indexadores no mesmo serviço de pesquisa.
Para a indexação do SharePoint, a fonte de dados deve ter as seguintes propriedades obrigatórias:
- name é o nome exclusivo da fonte de dados dentro de seu serviço de pesquisa.
- tipo deve ser "sharePoint". Esse valor diferencia maiúsculas de minúsculas.
- As credenciais fornecem o ponto de extremidade do SharePoint e a ID do aplicativo do Microsoft Entra (cliente). Um exemplo de ponto de extremidade do SharePoint é
https://microsoft.sharepoint.com/teams/MySharePointSite. Você pode obter o ponto de extremidade navegando até a página inicial do site do SharePoint e copiando a URL do navegador. - contêiner especifica qual biblioteca de documentos a indexar. As propriedades controlam quais documentos são indexados.
Para criar uma fonte de dados, chame Criar Fonte de Dados (versão prévia).
POST https://[service name].search.windows.net/datasources?api-version=2025-05-01-preview
Content-Type: application/json
api-key: [admin key]
{
"name" : "sharepoint-datasource",
"type" : "sharepoint",
"credentials" : { "connectionString" : "[connection-string]" },
"container" : { "name" : "defaultSiteLibrary", "query" : null }
}
Formato da cadeia de conexão
O formato da cadeia de conexão muda se o indexador estiver usando permissões delegadas de API ou permissões de aplicativo de API
Formato de cadeia de conexão de permissões delegadas de API
SharePointOnlineEndpoint=[SharePoint site url];ApplicationId=[Azure AD App ID];TenantId=[SharePoint site tenant id]Formato de cadeia de conexão de permissões de aplicativo de API
SharePointOnlineEndpoint=[SharePoint site url];ApplicationId=[Azure AD App ID];ApplicationSecret=[Azure AD App client secret];TenantId=[SharePoint site tenant id]
Observação
Se o site do SharePoint estiver no mesmo locatário que o serviço de pesquisa e a identidade gerenciada atribuída pelo sistema estiver habilitada, o TenantId não precisará ser incluído na cadeia de conexão. Se o site do SharePoint estiver em um locatário diferente do serviço de pesquisa, o TenantId precisará ser incluído.
Etapa 5: criar um índice
O índice especifica os campos em um documento, atributos e outras construções que modelam a experiência de pesquisa.
Para criar um índice, chame Criar Índice (versão prévia):
POST https://[service name].search.windows.net/indexes?api-version=2025-05-01-preview
Content-Type: application/json
api-key: [admin key]
{
"name" : "sharepoint-index",
"fields": [
{ "name": "id", "type": "Edm.String", "key": true, "searchable": false },
{ "name": "metadata_spo_item_name", "type": "Edm.String", "key": false, "searchable": true, "filterable": false, "sortable": false, "facetable": false },
{ "name": "metadata_spo_item_path", "type": "Edm.String", "key": false, "searchable": false, "filterable": false, "sortable": false, "facetable": false },
{ "name": "metadata_spo_item_content_type", "type": "Edm.String", "key": false, "searchable": false, "filterable": true, "sortable": false, "facetable": true },
{ "name": "metadata_spo_item_last_modified", "type": "Edm.DateTimeOffset", "key": false, "searchable": false, "filterable": false, "sortable": true, "facetable": false },
{ "name": "metadata_spo_item_size", "type": "Edm.Int64", "key": false, "searchable": false, "filterable": false, "sortable": false, "facetable": false },
{ "name": "content", "type": "Edm.String", "searchable": true, "filterable": false, "sortable": false, "facetable": false }
]
}
Importante
Somente metadata_spo_site_library_item_id pode ser usado como o campo-chave em um índice preenchido pelo indexador do SharePoint Online. Se um campo-chave não existir na fonte de dados, metadata_spo_site_library_item_id será mapeado automaticamente para o campo-chave.
Etapa 6: criar um indexador
Um indexador conecta uma fonte de dados a um índice de pesquisa de destino e fornece um agendamento para automatizar a atualização de dados. Após o índice e a fonte de dados terem sido criados, você poderá criar o indexador.
Se você estiver usando permissões delegadas, durante esta etapa, será solicitado que você entre com as credenciais da organização que têm acesso ao site do SharePoint. Se possível, é recomendável criar uma nova conta de usuário organizacional e dar a esse novo usuário as permissões exatas que deseja que o indexador tenha.
Há algumas etapas para criar o indexador:
Envie uma solicitação de Criar indexador (versão prévia):
POST https://[service name].search.windows.net/indexers?api-version=2025-05-01-preview Content-Type: application/json api-key: [admin key] { "name" : "sharepoint-indexer", "dataSourceName" : "sharepoint-datasource", "targetIndexName" : "sharepoint-index", "parameters": { "batchSize": null, "maxFailedItems": null, "maxFailedItemsPerBatch": null, "base64EncodeKeys": null, "configuration": { "indexedFileNameExtensions" : ".pdf, .docx", "excludedFileNameExtensions" : ".png, .jpg", "dataToExtract": "contentAndMetadata" } }, "schedule" : { }, "fieldMappings" : [ { "sourceFieldName" : "metadata_spo_site_library_item_id", "targetFieldName" : "id", "mappingFunction" : { "name" : "base64Encode" } } ] }Se você estiver usando as permissões do aplicativo, será necessário aguardar até que a execução inicial seja concluída antes de começar a consultar o índice. As instruções a seguir fornecidas nesta etapa pertencem especificamente às permissões delegadas e não são aplicáveis às permissões do aplicativo.
Ao criar o indexador pela primeira vez, a solicitação Criar indexador (versão prévia) aguarda até que a próxima etapa seja concluída. Você deve chamar Obter Status do Indexador para obter o link e inserir o novo código do dispositivo.
GET https://[service name].search.windows.net/indexers/sharepoint-indexer/status?api-version=2025-05-01-preview Content-Type: application/json api-key: [admin key]Se você não executar o Obter Status do Indexador dentro de dez minutos, o código expirará e você precisará recriar a fonte de dados.
Copie o código de logon do dispositivo da resposta Obter Status do Indexador. O logon do dispositivo pode ser encontrado na "errorMessage".
{ "lastResult": { "status": "transientFailure", "errorMessage": "To sign in, use a web browser to open the page https://microsoft.com/devicelogin and enter the code <CODE> to authenticate." } }Forneça o código que foi incluído na mensagem de erro.
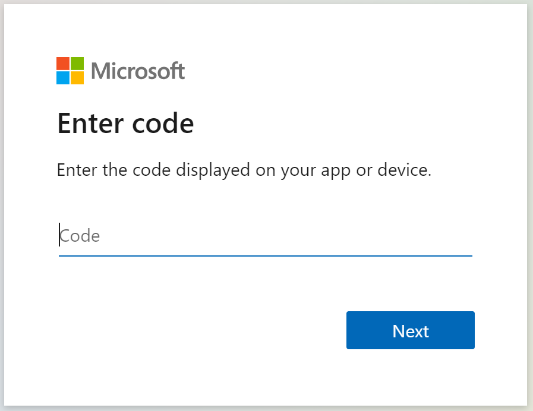
O indexador do SharePoint Online acessará o conteúdo do SharePoint como usuário conectado. O usuário que faz logon durante esta etapa será o usuário conectado. Portanto, se você entrar com uma conta de usuário que não tenha acesso a um documento na Biblioteca de Documentos que deseja indexar, o indexador não terá acesso a esse documento.
Se possível, é recomendável criar uma nova conta de usuário e dar a esse novo usuário as permissões exatas que deseja que o indexador tenha.
Aprove as permissões que estão sendo solicitadas.
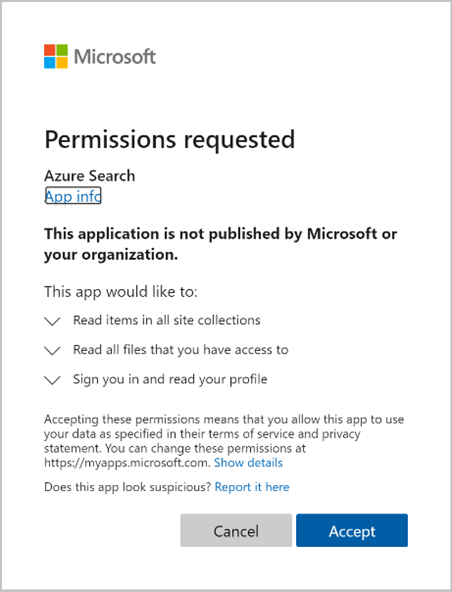
A solicitação inicial Criar Indexador (versão prévia) será concluída se todas as permissões fornecidas acima estiverem corretas e dentro do período de dez minutos.
Observação
Se o aplicativo do Microsoft Entra exigir aprovação do administrador e não tiver sido aprovado antes de fazer logon, é possível que você veja a tela a seguir. A aprovaçao do administrador é necessária para continuar.
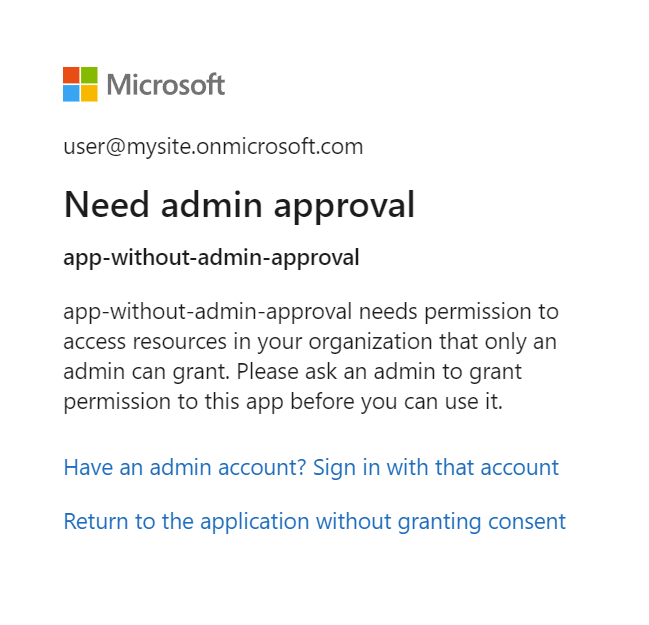
Etapa 7: verificar o status do indexador
Depois que o indexador tiver sido criado, você poderá chamar Obter Status do Indexador:
GET https://[service name].search.windows.net/indexers/sharepoint-indexer/status?api-version=2025-05-01-preview
Content-Type: application/json
api-key: [admin key]
Atualização da fonte de dados
Se não houver nenhuma atualização para o objeto da fonte de dados, o indexador será executado em um agendamento, sem nenhuma interação do usuário.
No entanto, se você modificar o objeto da fonte de dados enquanto o código do dispositivo estiver expirado, você precisará entrar novamente para que o indexador seja executado. Por exemplo, se você alterar a consulta da fonte de dados, faça logon novamente usando o https://microsoft.com/devicelogin e obtenha um novo código de dispositivo.
Estas são as etapas para atualizar uma fonte de dados, supondo que você tenha um código de dispositivo expirado:
Chame Executar Indexador (versão prévia) para iniciar manualmente a execução do indexador.
POST https://[service name].search.windows.net/indexers/sharepoint-indexer/run?api-version=2025-05-01-preview Content-Type: application/json api-key: [admin key]Verifique o status do indexador.
GET https://[service name].search.windows.net/indexers/sharepoint-indexer/status?api-version=2025-05-01-preview Content-Type: application/json api-key: [admin key]Se você receber um erro solicitando que você visite
https://microsoft.com/devicelogin, abra a página e copie o novo código.Cole o código na caixa de diálogo.
Execute manualmente o indexador novamente e verifique o status do indexador. Desta vez, a execução do indexador deve ser iniciada com sucesso.
Indexar metadados de documento
Caso você esteja indexando metadados de documento ("dataToExtract": "contentAndMetadata"), os metadados a seguir estarão disponíveis para indexação.
| Identificador | Tipo | Descrição |
|---|---|---|
| metadata_spo_site_library_item_id | Edm.String | A chave de combinação da ID do site, ID da biblioteca e ID do item que identifica exclusivamente um item em uma biblioteca de documentos para um site. |
| metadata_spo_site_id | Edm.String | A ID do site do SharePoint. |
| metadata_spo_library_id | Edm.String | A ID da biblioteca de documentos. |
| metadata_spo_item_id | Edm.String | A ID do (documento) item na biblioteca. |
| metadata_spo_item_last_modified | Edm. DateTimeOffset | A data/hora da última modificação (UTC) do item. |
| metadata_spo_item_name | Edm.String | O nome do item. |
| metadata_spo_item_size | Edm.Int64 | O tamanho (em bytes) do item. |
| metadata_spo_item_content_type | Edm.String | O tipo de conteúdo do item. |
| metadata_spo_item_extension | Edm.String | A extensão do item. |
| metadata_spo_item_weburi | Edm.String | O URI do item. |
| metadata_spo_item_path | Edm.String | A combinação do caminho pai e o nome do item. |
O indexador do SharePoint Online também dá suporte a metadados específicos para cada tipo de documento. Veja mais em Propriedades de metadados de conteúdo usadas no Azure AI Search.
Observação
Para indexar metadados personalizados, "additionalColumns" precisa ser especificado no parâmetro de consulta da fonte de dados.
Incluir ou excluir por tipo de arquivo
Você pode controlar quais arquivos são indexados definindo critérios de inclusão e exclusão na seção "parâmetros" da definição do indexador.
Inclua extensões de arquivo específicas definindo "indexedFileNameExtensions" como uma lista separada por vírgulas de extensões de arquivo (com um ponto à esquerda). Exclua as extensões de arquivo específicas definindo "excludedFileNameExtensions" nas extensões que devem ser ignoradas. Se a mesma extensão estiver nas duas listas, ela será excluída da indexação.
PUT /indexers/[indexer name]?api-version=2025-05-01-preview
{
"parameters" : {
"configuration" : {
"indexedFileNameExtensions" : ".pdf, .docx",
"excludedFileNameExtensions" : ".png, .jpeg"
}
}
}
Controlar quais documentos são indexados
Um único indexador do SharePoint Online pode indexar conteúdo de uma ou mais bibliotecas de documentos. Use o parâmetro "container" na definição da fonte de dados para indicar de quais sites e bibliotecas de documentos indexar.
A seção "container" da fonte de dados tem duas propriedades para esta tarefa: "name" e "query".
Nome
A propriedade "name" é exigida e precisa ter um destes três valores:
| Valor | Descrição |
|---|---|
| defaultSiteLibrary | Indexar todo o conteúdo da biblioteca de documentos padrão do site. |
| allSiteLibraries | Indexar todo o conteúdo de todas as bibliotecas de documentos em um site. As bibliotecas de documentos de um subsite estão fora do escopo/ Se você precisar de conteúdo de subsites, escolha "useQuery" e especifique "includeLibrariesInSite". |
| useQuery | Indexar somente o conteúdo definido na “consulta”. |
Consulta
O parâmetro "query" da fonte de dados é feito de pares palavra-chave/valor. Seguem as palavras-chave que podem ser usadas. Os valores são URLs de site ou URLs de biblioteca de documentos.
Observação
Para obter o valor de uma palavra-chave específica, é recomendável navegar até a biblioteca de documentos que você está tentando incluir/excluir e copiar o URI do navegador. Esta é a maneira mais fácil de obter o valor a ser usado com uma palavra-chave na consulta.
| Palavra-chave | Exemplos e descrição do valor |
|---|---|
| nulo | Se for nula ou vazia, indexe a biblioteca de documentos padrão ou todas as bibliotecas de documentos, dependendo do nome do contêiner. Exemplo: "container" : { "name" : "defaultSiteLibrary", "query" : null } |
| includeLibrariesInSite | Indexe o conteúdo de todas as bibliotecas no site especificado na cadeia de conexão. O valor deve ser o URI do site ou subsite. Exemplo 1: "container" : { "name" : "useQuery", "query" : "includeLibrariesInSite=https://mycompany.sharepoint.com/mysite" } Exemplo 2 (inclua apenas alguns subsites): "container" : { "name" : "useQuery", "query" : "includeLibrariesInSite=https://mycompany.sharepoint.com/sites/TopSite/SubSite1;includeLibrariesInSite=https://mycompany.sharepoint.com/sites/TopSite/SubSite2" } |
| includeLibrary | Indexe todo o conteúdo desta biblioteca. O valor é o caminho totalmente qualificado para a biblioteca, que pode ser copiado do navegador: Exemplo 1 (caminho totalmente qualificado): "container" : { "name" : "useQuery", "query" : "includeLibrary=https://mycompany.sharepoint.com/mysite/MyDocumentLibrary" } Exemplo 2 (URI copiado do seu navegador): "container" : { "name" : "useQuery", "query" : "includeLibrary=https://mycompany.sharepoint.com/teams/mysite/MyDocumentLibrary/Forms/AllItems.aspx" } |
| Excluir Biblioteca | Não indexe o conteúdo desta biblioteca. O valor é o caminho totalmente qualificado para a biblioteca, que pode ser copiado do navegador: Exemplo 1 (caminho totalmente qualificado): "container" : { "name" : "useQuery", "query" : "includeLibrariesInSite=https://mysite.sharepoint.com/subsite1; excludeLibrary=https://mysite.sharepoint.com/subsite1/MyDocumentLibrary" } Exemplo 2 (URI copiado do seu navegador): "container" : { "name" : "useQuery", "query" : "includeLibrariesInSite=https://mycompany.sharepoint.com/teams/mysite; excludeLibrary=https://mycompany.sharepoint.com/teams/mysite/MyDocumentLibrary/Forms/AllItems.aspx" } |
| Colunas adicionais | Indexe colunas da biblioteca de documentos. O valor é uma lista separada por vírgulas de nomes de coluna que você deseja indexar. Use uma barra invertida dupla como caractere de escape de ponto-e-vírgulas e vírgulas em nomes de coluna: Exemplo 1 (additionalColumns=MyCustomColumn,MyCustomColumn2): "container" : { "name" : "useQuery", "query" : "includeLibrary=https://mycompany.sharepoint.com/mysite/MyDocumentLibrary;additionalColumns=MyCustomColumn,MyCustomColumn2" } Exemplo 2 (caracteres de escape usando duas barras invertidas): "container" : { "name" : "useQuery", "query" : "includeLibrary=https://mycompany.sharepoint.com/teams/mysite/MyDocumentLibrary/Forms/AllItems.aspx;additionalColumns=MyCustomColumnWith\\,,MyCustomColumnWith\\;" } |
Tratar erros
Por padrão, o indexador do SharePoint Online é interrompido assim que encontra um documento com um tipo de conteúdo sem suporte (por exemplo, uma imagem). É possível usar o parâmetro excludedFileNameExtensions para ignorar alguns tipos de conteúdo. No entanto, talvez você precise indexar documentos sem conhecer todos os possíveis tipos de conteúdo com antecedência. Para continuar a indexação quando um tipo de conteúdo sem suporte é encontrado, defina o failOnUnsupportedContentType parâmetro de configuração como falso:
PUT https://[service name].search.windows.net/indexers/[indexer name]?api-version=2025-05-01-preview
Content-Type: application/json
api-key: [admin key]
{
... other parts of indexer definition
"parameters" : { "configuration" : { "failOnUnsupportedContentType" : false } }
}
Para alguns documentos, o Azure AI Search não é capaz de determinar o tipo de conteúdo ou não é capaz de processar um documento com tipo de conteúdo compatível. Para ignorar este modo de falha, defina o parâmetro de configuração failOnUnprocessableDocument como false:
"parameters" : { "configuration" : { "failOnUnprocessableDocument" : false } }
O Azure AI Search limita o tamanho de documentos que são indexados. Esses limites são documentados em Limites de serviço no Azure AI Search. Por padrão, os documentos superdimensionados são tratados como erros. No entanto, você ainda pode indexar os metadados de armazenamento de documentos superdimensionados se você definir o indexStorageMetadataOnlyForOversizedDocuments parâmetro de configuração como true:
"parameters" : { "configuration" : { "indexStorageMetadataOnlyForOversizedDocuments" : true } }
Também é possível continuar a indexação se ocorrem erros a qualquer momento do processamento, ao analisar documentos ou ao adicionar documentos a um índice. Para ignorar um número específico de erros, defina os parâmetros de configuração maxFailedItems e maxFailedItemsPerBatch como os valores desejados. Por exemplo:
{
... other parts of indexer definition
"parameters" : { "maxFailedItems" : 10, "maxFailedItemsPerBatch" : 10 }
}
Se um arquivo no site do SharePoint tiver a criptografia habilitada, pode ser que você veja a seguinte mensagem de erro:
Code: resourceModified Message: The resource has changed since the caller last read it; usually an eTag mismatch Inner error: Code: irmEncryptFailedToFindProtector
A mensagem de erro também incluirá a ID do site do SharePoint, a ID da unidade e a ID do item de unidade no seguinte padrão: <sharepoint site id> :: <drive id> :: <drive item id>. Essas informações podem ser usadas para identificar qual item está falhando na extremidade do SharePoint. Em seguida, o usuário pode remover a criptografia do item para resolver o problema.