Gerenciando o consumo e a carga de recursos no Service Fabric com métricas
Métricas são os recursos que são importantes para seus serviços e que são fornecidas pelos nós no cluster. Uma métrica é tudo o que você deseja gerenciar para melhorar ou monitorar o desempenho de seus serviços. Por exemplo, você pode observar o consumo de memória para saber se o serviço está sobrecarregado. Outro uso é para descobrir se o serviço pode ser movido para outro lugar onde a memória seja menos restrita para obter um melhor desempenho.
Itens como Memória, Disco e Uso de CPU são exemplos de métricas. Essas métricas são métricas físicas, recursos que correspondem aos recursos físicos no nó que precisam ser gerenciados. As métricas também podem ser (e normalmente são) métricas lógicas. Métricas lógicas são itens como "MyWorkQueueDepth", "MessagesToProcess" ou "TotalRecords". Métricas lógicas são definidas pelo aplicativo e indiretamente correspondem a algum consumo de recursos físicos. Métricas lógicas são comuns, pois pode ser difícil medir e relatar o consumo de recursos físicos por serviço. A complexidade de medir e relatar suas próprias métricas também é o motivo pelo qual o Service Fabric fornece algumas métricas padrão prontas.
Digamos que você deseja começar a escrever e implantar seu serviço. Neste ponto, você não sabe quais recursos físicos ou lógicos serão consumidos. Sem problemas! O Gerenciador de Recursos de Cluster do Service Fabric usa algumas métricas padrão quando não há nenhuma outra métrica especificadas. Eles são:
- PrimaryCount - contagem de réplicas Primárias no nó
- ReplicaCount - contagem total de réplicas com estado do nó
- Count - contagem de todos os objetos de serviço (com e sem estado) no nó
| Métrica | Carga de Instância Sem Estado | Carga Secundária com Estado | Carga Primária com Estado | Peso |
|---|---|---|---|---|
| PrimaryCount | 0 | 0 | 1 | Alto |
| ReplicaCount | 0 | 1 | 1 | Médio |
| Contagem | 1 | 1 | 1 | Baixo |
Para cargas de trabalho básicas, as métricas padrão fornecem uma distribuição razoável de trabalho no cluster. No exemplo a seguir, vamos ver o que acontece quando criamos dois serviços e dependemos das métricas padrão para balanceamento. O primeiro serviço é um serviço com estado com três partições e um tamanho de conjunto de réplicas de destino de três. O segundo serviço é um serviço sem estado com uma partição e uma contagem de instâncias de três.
Veja o que você obtém:
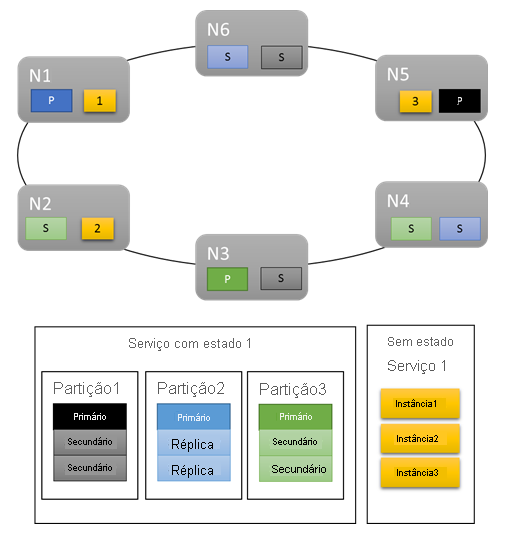
Algumas coisas a serem observadas:
- As réplicas primárias para o serviço com estado são distribuídas por vários nós
- As réplicas da mesma partição estão em nós diferentes
- O número total de primários e de secundários é distribuído no cluster
- O número total de objetos de serviço é alocado uniformemente em cada nó
Ótimo!
As métricas padrão funcionam muito bem como ponto de partida. No entanto, as métricas padrão só serão úteis até certo ponto. Por exemplo: Qual é a probabilidade de que o esquema de particionamento que você escolheu resulte na utilização perfeitamente uniforme por todas as partições? Qual é a chance de que a carga de determinado serviço seja constante ao longo do tempo ou que seja uniforme entre várias partições neste momento?
Você pode executar somente com as métricas padrão. No entanto, isso geralmente significa que a utilização do cluster é menor e mais irregular que o desejado. Isso ocorre porque as métricas padrão não são adaptáveis e presumem que tudo seja equivalente. Por exemplo, uma réplica Primária está ocupada e uma que não está contribuem ambas com "1" para a métrica de PrimaryCount. Na pior das hipóteses, usar apenas as métricas padrão também pode resultar em nós com agendamento excessivo, causando problemas de desempenho. Se você está interessado em obter o máximo de seu cluster e evitar problemas de desempenho, você precisa usar as métricas personalizadas e o relatório de carga dinâmico.
As métricas são configuradas por instância de serviço nomeado ao criar o serviço.
Qualquer métrica possui propriedades que a descrevem: um nome, um peso e uma carga padrão.
- Nome da Métrica: o nome da métrica. O nome da métrica é um identificador exclusivo para a métrica do cluster da perspectiva do Gerenciador de Recursos.
Observação
O nome de métrica personalizado não deve ser nenhum dos nomes de métrica do sistema, ou seja, servicefabric:/_CpuCores ou servicefabric:/_MemoryInMB, pois pode levar a um comportamento indefinido. No Service Fabric versão 9.1 e posteriores, para serviços existentes com esses nomes de métrica personalizados, um aviso de integridade é emitido para indicar que o nome da métrica está incorreto.
- Peso: o peso da métrica define o quanto ela é importante em relação as outras métricas para esse serviço.
- Default Load: A carga padrão é representada de maneira diferente dependendo se o serviço está com ou sem estado.
- Para serviços sem estado cada métrica tem uma propriedade única chamada DeafultLoad
- Para serviços com estado, você define:
- PrimaryDefaultLoad: o valor padrão dessa métrica que esse serviço consome quando é primário
- SecondaryDefaultLoad: o valor padrão dessa métrica que esse serviço consome quando é secundário
Observação
Se definir métricas personalizadas e também desejar usar as métricas padrão, você precisa adicionar explicitamente as métricas padrão e definir os pesos e valores para elas. Isso ocorre porque você deve definir a relação entre as métricas padrão e as métricas personalizadas. Por exemplo, talvez você se preocupe mais com ConnectionCount ou WorkQueueDepth do que com a distribuição Principal. Por padrão o peso da métrica PrimaryCount é Alto, portanto, você deseja reduzi-lo para Médio, quando você adiciona as outras métricas para garantir que eles tenham precedência.
Digamos que você deseja a configuração a seguir:
- O serviço relata uma métrica denominada “ConnectionCount”
- Você também deseja usar as métricas padrão
- Você fez algumas medições e sabe que normalmente uma réplica Primária desse serviço requer 20 unidades de “ConnectionCount”
- As secundárias usam 5 unidades de "ConnectionCount"
- Você sabe que a memória é a métrica mais importante em termos de gerenciamento de desempenho desse serviço específico
- Você ainda deseja que as réplicas Principais sejam balanceadas. Balancear réplicas primárias geralmente é uma boa ideia. Isso ajuda a evitar que a perda de algum nó ou domínio de falha afete a maioria das réplicas primárias.
- Caso contrário, as métricas padrão não representam um problema
Aqui está o código que você escreveria para criar um serviço com essa configuração de métrica:
Código:
StatefulServiceDescription serviceDescription = new StatefulServiceDescription();
StatefulServiceLoadMetricDescription connectionMetric = new StatefulServiceLoadMetricDescription();
connectionMetric.Name = "ConnectionCount";
connectionMetric.PrimaryDefaultLoad = 20;
connectionMetric.SecondaryDefaultLoad = 5;
connectionMetric.Weight = ServiceLoadMetricWeight.High;
StatefulServiceLoadMetricDescription primaryCountMetric = new StatefulServiceLoadMetricDescription();
primaryCountMetric.Name = "PrimaryCount";
primaryCountMetric.PrimaryDefaultLoad = 1;
primaryCountMetric.SecondaryDefaultLoad = 0;
primaryCountMetric.Weight = ServiceLoadMetricWeight.Medium;
StatefulServiceLoadMetricDescription replicaCountMetric = new StatefulServiceLoadMetricDescription();
replicaCountMetric.Name = "ReplicaCount";
replicaCountMetric.PrimaryDefaultLoad = 1;
replicaCountMetric.SecondaryDefaultLoad = 1;
replicaCountMetric.Weight = ServiceLoadMetricWeight.Low;
StatefulServiceLoadMetricDescription totalCountMetric = new StatefulServiceLoadMetricDescription();
totalCountMetric.Name = "Count";
totalCountMetric.PrimaryDefaultLoad = 1;
totalCountMetric.SecondaryDefaultLoad = 1;
totalCountMetric.Weight = ServiceLoadMetricWeight.Low;
serviceDescription.Metrics.Add(connectionMetric);
serviceDescription.Metrics.Add(primaryCountMetric);
serviceDescription.Metrics.Add(replicaCountMetric);
serviceDescription.Metrics.Add(totalCountMetric);
await fabricClient.ServiceManager.CreateServiceAsync(serviceDescription);
PowerShell:
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName –Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton –Metric @("ConnectionCount,High,20,5”,"PrimaryCount,Medium,1,0”,"ReplicaCount,Low,1,1”,"Count,Low,1,1”)
Observação
Os exemplos anteriores e o restante deste documento descrevem as métricas de gerenciamento por serviço nomeado. Também é possível definir as métricas para os serviços no nível do tipo de serviço. Isso é feito especificando-as em seus manifestos de serviço. Não é recomendável definir as métricas do nível de tipo por vários motivos. O primeiro motivo é que os nomes de métrica são frequentemente específicos do ambiente. A menos que haja um contrato sólido em vigor, você não pode ter certeza que a métrica "Núcleos" em um ambiente não é "MiliNúcelos" ou "NúClEoS" em outros. Se suas métricas são definidas em seu manifesto, você precisa criar novos manifestos por ambiente. Isso geralmente resulta em uma proliferação de manifestos diferentes com apenas algumas pequenas diferenças, que podem levar a problemas de gerenciamento.
Cargas de métricas normalmente são atribuídas por instância de serviço nomeada. Por exemplo, digamos que você crie uma instância do serviço para ClienteA que planeja usá-lo pouco. Digamos que você também crie outra para ClienteB que tem uma carga de trabalho maior. Nesse caso, você provavelmente iria querer ajustar as cargas padrão para esses serviços. Se você tiver as métricas e as cargas definidas por meio de manifestos e você deseja oferecer suporte a esse cenário, é necessário diferentes aplicativos e tipos de serviço para cada cliente. Os valores definidos no momento da criação de serviço substituem aqueles definidos no manifesto, para que você possa usá-los para definir os padrões específicos. No entanto, isso faz com que os valores declarados nos manifestos não coincidam aqueles onde o serviço é realmente executado. Isso pode causar confusão.
Lembre-se: se você quiser usar as métricas padrão, não precisará sequer encostar na coleção de métricas ou fazer algo especial ao criar o seu serviço. As métricas padrão são usadas automaticamente quando nenhuma outra métrica é definida.
Agora, vamos percorrer cada uma dessas configurações mais detalhadamente e falar sobre o comportamento que ela influencia.
O objetivo da definição de métricas é representar alguma carga. Carga é a quantidade de determinada métrica consumida por alguma instância de serviço ou réplica em determinado nó. A carga pode ser configurada em praticamente qualquer ponto. Por exemplo:
- A carga pode ser definida quando um serviço é criado. Esse tipo de configuração de carga é chamado de carga padrão.
- É possível atualizar as informações das métricas, inclusive as cargas padrão, de um serviço depois que o serviço é criado. Essa atualização da métricas é feita atualizando um serviço.
- As cargas de uma determinada partição podem ser redefinidas com os valores padrão para o serviço. Essa atualização das métricas é chamada de redefinição da carga de partição.
- É possível registrar a carga por objeto de serviço dinamicamente durante o runtime. Essa atualização das métricas é chamada de relatório de carga.
- Também é possível atualizar a carga das réplicas ou instâncias da partição com o relatório de valores de carga por meio de uma chamada à API do Service Fabric. Essa atualização das métricas é chamada de relatório de carga de uma partição.
Todas essas estratégias podem ser usadas dentro do mesmo serviço durante o seu tempo de vida.
Carga padrão é o quanto de métrica cada objeto de serviço (instância sem estado ou réplica com estado) desse serviço consome. O Gerenciador de Recursos de Cluster usa esse número para a carga do objeto do serviço até receber outra informação, como um relatório de carga dinâmico. Para serviços mais simples, a carga padrão é uma definição estática. A carga padrão nunca é atualizada e é usada ao longo de todo o tempo de vida do serviço. As cargas padrão funcionam muito bem em cenários simples de planejamento de capacidade nos quais determinadas quantidades de recursos são dedicadas a diferentes cargas de trabalho e não são alteradas.
Observação
Para obter mais informações sobre o gerenciamento de capacidade e definição de capacidades para os nós no cluster, consulte este artigo.
O Gerenciador de Recursos de Cluster permite que os serviços com monitoração de estado especifiquem uma carga padrão diferente para cargas Primárias e Secundárias. Serviços sem estado só podem especificar um valor que se aplica a todas as instâncias. Para serviços com monitoração de estado, a carga padrão para réplicas Primárias e Secundárias normalmente é diferente, pois as réplicas realizam diferentes tipos de trabalho em cada função. Por exemplo, as Primárias normalmente lidam com leituras e gravações, e a maior parte da carga computacional, enquanto as secundárias não o fazem. Normalmente, a carga padrão para uma réplica primária é maior que a carga padrão para réplicas secundárias. Os números reais dependem de suas próprias medidas.
Digamos que você esteja executando o serviço há algum tempo. Com o monitoramento, você observou que:
- Algumas partições ou instâncias de determinado serviço consomem mais recursos do que outras
- Alguns serviços têm carga que varia ao longo do tempo.
Há muitos itens que podem causar esses tipos de flutuações de carga. Por exemplo, serviços ou partições diferentes estão associadas com diferentes clientes com diferentes requisitos. A carga também pode alterar porque a quantidade de trabalho do serviço varia ao longo do dia. Independentemente do motivo, há um número único que você pode usar para a carga padrão. Isso é especialmente verdadeiro se você deseja utilizar ao máximo o cluster. Qualquer valor que você escolher para a carga padrão estará errado durante parte do tempo. Cargas padrão incorretas fazem com que o Gerenciador de Recursos de Cluster aloque recursos a mais ou a menos. Como resultado, você tem nós com utilização acima ou abaixo do esperado, mesmo que o Gerenciador de Recursos de Cluster pense que o cluster está equilibrado. As cargas padrão ainda são válidas, pois fornecem algumas informações para o posicionamento inicial, mas não dão a visão completa das cargas de trabalho reais. Para capturar com precisão a alteração dos requisitos do recurso o Gerenciador de Recursos de Cluster permite que cada objeto de serviço atualize sua própria carga em runtime. Isso é chamado de relatório dinâmico de carga.
Relatórios de carga dinâmicos permitem que réplicas ou instâncias ajustem sua carga de métricas de alocação/relatadas durante o ciclo de vida. Uma réplica de serviço ou uma instância inoperante e que não realizasse trabalho normalmente informaria que estava usando valores baixos de determinada métrica. Uma réplica ou instância ocupada relataria que está usando mais.
Os relatórios por réplica ou instância permitem que o Gerenciador de Recursos de Cluster reorganize os objetos de serviço individuais no cluster. Reorganizar os serviços ajuda a garantir que eles obtenham os recursos que exigem. Serviços ocupados efetivamente podem "recuperar" recursos de outras réplicas ou instâncias que estão atualmente inoperantes ou executando menos trabalho.
No Reliable Services, o código para relatar a carga dinamicamente teria esta aparência:
Código:
this.Partition.ReportLoad(new List<LoadMetric> { new LoadMetric("CurrentConnectionCount", 1234), new LoadMetric("metric1", 42) });
Um serviço pode relatar qualquer uma das métricas definidas para ela no momento da criação. Se um serviço relatar uma carga para uma métrica que ele não está configurado para usar, o Service Fabric ignora esse relatório. Se houver outras métricas relatadas ao mesmo tempo que sejam válidas, esses relatórios serão aceitos. O código do serviço pode medir e relatar todas as métricas que ele sabe relatar, e os operadores podem especificar a configuração de métrica para uso sem ter que alterar o código do serviço.
A seção anterior descreve como as réplicas ou as instâncias de serviço registram a carga. Há uma opção adicional para relatar dinamicamente a carga para réplicas ou instâncias de uma partição por meio da API do Service Fabric. Ao registrar a carga de uma partição, é possível registrar várias partições ao mesmo tempo.
Esses relatórios serão usados exatamente da mesma forma que os relatórios de carga provenientes das próprias réplicas ou instâncias. Os valores registrados serão válidos até que novos valores de carga sejam registrados, seja pela réplica ou instância, ou registrando um novo valor de carga para uma partição.
Com essa API, há várias maneiras de atualizar a carga no cluster:
- Uma partição de serviço com estado pode atualizar a carga de sua réplica primária.
- Os serviços com e sem estado podem atualizar a carga de todas as suas réplicas ou instâncias secundárias.
- Os serviços com e sem estado podem atualizar a carga de uma réplica ou instância específica em um nó.
Também é possível combinar qualquer uma dessas atualizações por partição ao mesmo tempo. A combinação de atualizações de carga para uma partição específica deve ser especificada por meio do objeto PartitionMetricLoadDescription, que pode conter a lista correspondente de atualizações de carga, conforme mostrado no exemplo abaixo. As atualizações de carga são representadas por meio do objeto MetricLoadDescription, que pode conter o valor de carga atual ou previsto para uma métrica, especificado com um nome de métrica.
Observação
Atualmente, os valores de carga de métrica previstos são uma versão prévia do recurso. Ele permite que os valores de carga previstos sejam relatados e usados no lado do Service Fabric, mas esse recurso não está habilitado no momento.
A atualização de cargas para várias partições é possível com uma única chamada à API; nesse caso, a saída conterá uma resposta por partição. Caso a atualização da partição não seja aplicada com êxito por qualquer motivo, as atualizações dessa partição serão ignoradas e o código de erro correspondente para uma partição de destino será fornecido:
- PartitionNotFound – a ID da partição especificada não existe.
- ReconfigurationPending – a partição está sendo reconfigurada no momento.
- InvalidForStatelessServices – foi feita uma tentativa de alterar a carga de uma réplica primária de uma partição que pertence a um serviço sem estado.
- ReplicaDoesNotExist – a réplica ou instância secundária não existe em um nó especificado.
- InvalidOperation – pode acontecer em dois casos: a atualização da carga de uma partição que pertence ao Aplicativo do sistema ou a atualização da carga prevista não está habilitada.
Se alguns desses erros forem retornados, será possível atualizar a entrada de uma partição específica e tentar novamente a atualização dela.
Código:
Guid partitionId = Guid.Parse("53df3d7f-5471-403b-b736-bde6ad584f42");
string metricName0 = "CustomMetricName0";
List<MetricLoadDescription> newPrimaryReplicaLoads = new List<MetricLoadDescription>()
{
new MetricLoadDescription(metricName0, 100)
};
string nodeName0 = "NodeName0";
List<MetricLoadDescription> newSpecificSecondaryReplicaLoads = new List<MetricLoadDescription>()
{
new MetricLoadDescription(metricName0, 200)
};
OperationResult<UpdatePartitionLoadResultList> updatePartitionLoadResults =
await this.FabricClient.UpdatePartitionLoadAsync(
new UpdatePartitionLoadQueryDescription
{
PartitionMetricLoadDescriptionList = new List<PartitionMetricLoadDescription>()
{
new PartitionMetricLoadDescription(
partitionId,
newPrimaryReplicaLoads,
new List<MetricLoadDescription>(),
new List<ReplicaMetricLoadDescription>()
{
new ReplicaMetricLoadDescription(nodeName0, newSpecificSecondaryReplicaLoads)
})
}
},
this.Timeout,
cancellationToken);
Com este exemplo, você executará uma atualização da última carga registrada de uma partição 53df3d7f-5471-403b-b736-bde6ad584f42. A carga da réplica primária para uma métrica CustomMetricName0 será atualizada com o valor 100. Ao mesmo tempo, a carga para a mesma métrica de uma réplica secundária específica, localizada no nó NodeName0, será atualizada com o valor 200.
A lista de métricas associadas ao serviço e as propriedades dessas métricas podem ser atualizadas dinamicamente enquanto o serviço está ativo. Isso permite flexibilidade e a oportunidade de fazer experimentos. Alguns exemplos de quando isso é útil são:
- ao desabilitar uma métrica com um relatório com bugs para um serviço específico
- ao reconfigurar os pesos de métricas com base no comportamento desejado
- ao habilitar uma métrica nova somente depois que o código já foi implantado e validado por meio de outros mecanismos
- ao alterar a carga padrão para um serviço com base no consumo e comportamento observado
As principais APIs para alterar a configuração de métrica são FabricClient.ServiceManagementClient.UpdateServiceAsync em C# e Update-ServiceFabricService no PowerShell. Quaisquer informações que você especificar com essas APIs substituem as informações existentes de métrica para o serviço imediatamente.
Carga padrão e cargas dinâmicas podem ser usadas para o mesmo serviço. Quando o serviço utiliza os relatórios de carga padrão e carga dinâmica carga padrão serve como uma estimativa até os relatórios dinâmicos serem gerados. A carga padrão é boa porque fornece ao Gerenciador de Recursos de Cluster algo com o qual trabalhar. A carga padrão permite que o Gerenciador de Recursos de Cluster coloque os objetos de serviço em locais adequados quando eles são criados. Se nenhuma informação de carga padrão for fornecida, o posicionamento dos serviços será efetivamente aleatório. Quando os relatórios de carga chegam mais tarde o posicionamento aleatório inicial geralmente é incorreto e o Gerenciador de Recursos de Cluster precisará mover serviços.
Vamos conferir nosso exemplo anterior e ver o que acontece quando adicionamos algumas métricas personalizadas e relatórios dinâmicos de carga. Neste exemplo, usamos "MemoryInMb" como uma métrica de exemplo.
Observação
Memória é uma das métricas de sistema a qual o Service Fabric pode controlar os recursos, e relatá-las você mesmo normalmente é difícil. Não esperamos que você gere relatórios de consumo de Memória; a Memória é usada como um auxílio para saber mais sobre os recursos do Gerenciador de Recursos de Cluster.
Vamos pressupor que tenhamos criado inicialmente o serviço com estado com o seguinte comando:
PowerShell:
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName –Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton –Metric @("MemoryInMb,High,21,11”,"PrimaryCount,Medium,1,0”,"ReplicaCount,Low,1,1”,"Count,Low,1,1”)
Como lembrete, essa sintaxe é ("MetricName, MetricWeight, PrimaryDefaultLoad, SecondaryDefaultLoad").
Vamos ver qual poderia ser a aparência de um layout de cluster:
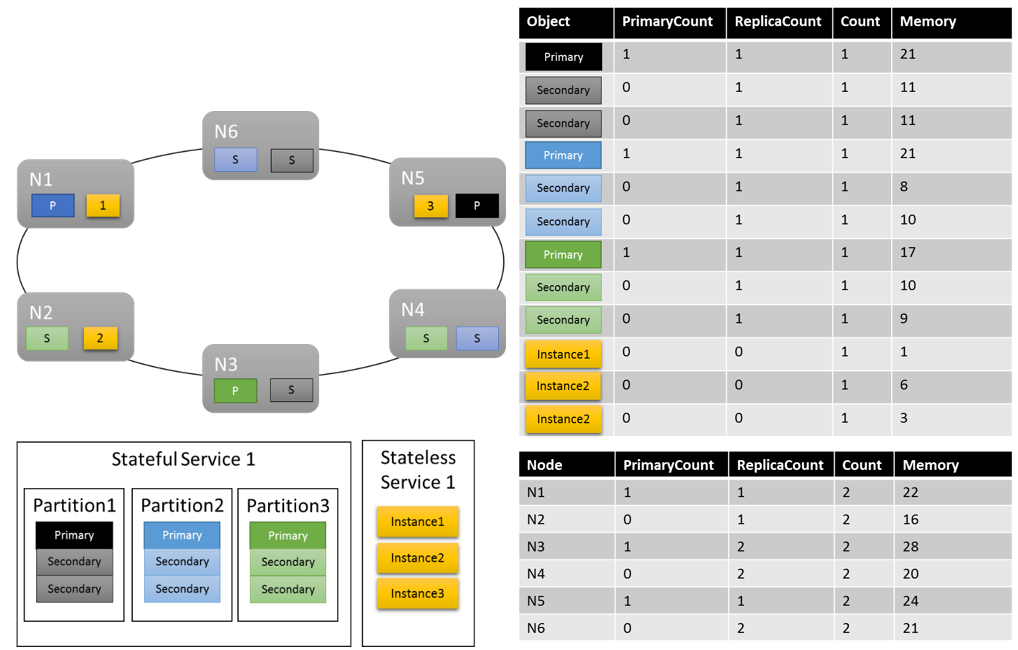
Algumas coisas que vale a pena observar:
- As réplicas secundárias dentro de uma partição podem ter cada uma a sua própria carga
- Em geral, as métricas parecem equilibradas. Para a Memória, a proporção entre a carga máxima e a mínima é de 1,75 (o nó com o máximo de carga é N3, o que tem o mínimo é N2 e 28/16 = 1,75).
Há alguns itens que precisamos explicar:
- O que determinou se uma taxa de 1,75 é razoável ou não? Como o Gerenciador de Recursos de Cluster sabe se isso é bom o suficiente ou se há mais trabalho a fazer?
- Quando o balanceamento acontece?
- O que significa que a memória foi ponderada como "Alta"?
Controlar as mesmas métricas em serviços diferentes é importante. Essa exibição global é o que permite que o Gerenciador de Recursos de Cluster rastreie o consumo do cluster, equilibre o consumo entre os nós e garanta que os nós não ultrapassem a capacidade. No entanto, os serviços podem ter diferentes opiniões sobre a importância da mesma métrica. Além disso, em um cluster com várias métricas e muitos serviços, talvez não existam soluções perfeitamente equilibradas para todas as métricas. Como o Gerenciador de Recursos de Cluster deve lidar com essas situações?
Os pesos das métricas permitem que o Gerenciador de Recursos de Cluster decida como equilibrar o cluster quando não houver uma resposta perfeita. Os pesos das métricas também permitem que o Gerenciador de Recursos de Cluster equilibre serviços específicos de maneira diferente. As métricas podem ter quatro níveis de peso diferente: zero, baixa, média e alta. Uma métrica com um peso Zero não contribui em nada ao considerar se as coisas estão balanceadas ou não. No entanto, sua carga ainda contribui para o gerenciamento da capacidade. Métricas com peso Zero ainda são úteis e costumam ser usadas como parte do monitoramento de desempenho e do comportamento de serviço. Este artigo fornece mais informações sobre o uso de métricas para monitoramento e diagnóstico dos seus serviços.
O impacto real de pesos de métricas diferentes no cluster é que o Gerenciador de Recursos de Cluster gera diferentes soluções. Os pesos das métricas informam ao Gerenciador de Recursos de Cluster que determinadas métricas são mais importantes do que outras. Quando não há uma solução perfeita, o Gerenciador de Recursos de Cluster pode preferir soluções que equilibrem melhor as métricas ponderadas mais elevadas. Se um serviço achar que uma métrica específica não é importante, ele poderá considerar seu uso dessa métrica desequilibrado. Isso permite que outro serviço obtenha uma distribuição uniforme de alguma métrica que seja importante para ele.
Vamos conferir um exemplo de alguns relatórios de carga para ver como os pesos de métrica diferentes resultam em alocações diferentes no cluster. Neste exemplo, podemos ver que alternar o peso relativo das métricas faz com que o Gerenciador de Recursos de Cluster crie diferentes disposições de serviços.
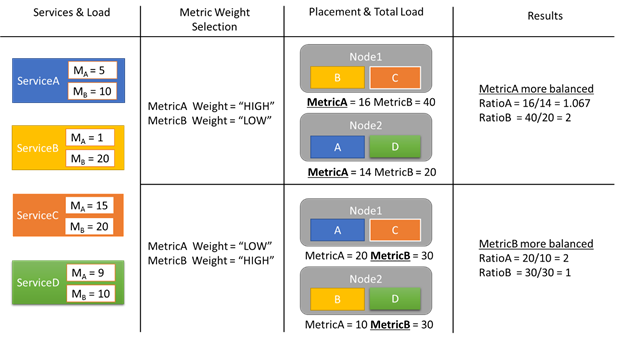
Neste exemplo, há quatro serviços diferentes, todos relatando diferentes valores para duas métricas diferentes, Métrica A e Métrica B. Em um caso, todos os serviços definem a Métrica A como a mais importante (Peso = Alto) e a Métrica B como não importante (Peso = Baixo). Nesse caso, vemos que o Gerenciador de Recursos de Cluster dispõe os serviços para que a Métrica A seja mais equilibrada que a Métrica B. "Melhor equilibrada" significa que a Métrica A tem um desvio padrão menor que a Métrica B. No segundo caso, invertemos os pesos de métrica. Como resultado, o Gerenciador de Recursos de Cluster troca os serviços A e B para propor uma alocação em que a Métrica B seja mais equilibrada do que a Métrica A.
Observação
Os pesos das métricas determinam como o Gerenciador de recursos de Cluster deve fazer o balanceamento, mas não quando este balanceamento deve ocorrer. Para saber mais sobre balanceamento, leia este artigo
Digamos que o Serviço A define a Métrica A com peso Alto e o Serviço B define o peso para a Métrica A como Baixo ou Zero. O que é o peso real que acaba sendo usado?
Há vários pesos que são rastreados para cada métrica. O primeiro peso é definido para a métrica quando o serviço é criado. O outro peso é um peso global, que é calculado automaticamente. O Gerenciador de Recursos de Cluster usa ambos os pesos para a pontuação de soluções. Considerar ambos os pesos é importante. Isso permite que o Gerenciador de Recursos de Cluster possa equilibrar cada serviço de acordo com suas próprias prioridades e também garante que o cluster como um todo seja alocado corretamente.
O que aconteceria se o Gerenciador de Recursos de Cluster não se importasse com o balanceamento global e local? Bem, é fácil criar soluções que são balanceadas globalmente, mas que resultam em um balanceamento de recursos inadequado para serviços individuais. No exemplo a seguir, vamos examinar um serviço configurado somente com as métricas padrão e ver o que acontece quando apenas o balanceamento global é considerado:
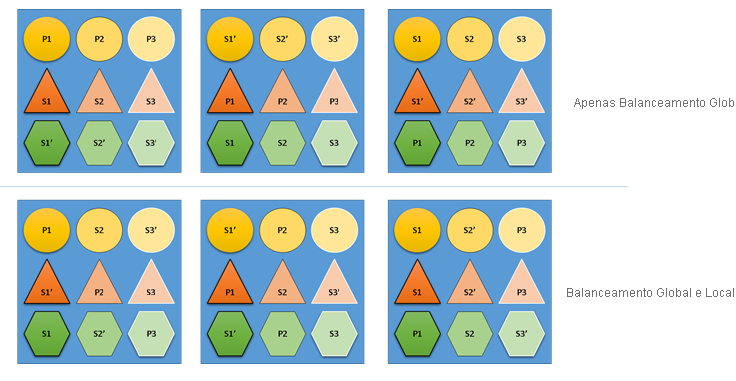
No exemplo acima, baseado somente em balanceamento global, o cluster como um todo é realmente balanceado. Todos os nós têm a mesma contagem de primárias e o mesmo número total de réplicas. Entretanto, se você examinar o impacto real dessa alocação, isso não é tão bom: a perda de qualquer nó afeta uma determinada carga de trabalho desproporcionalmente, já que leva todos seus primários. Por exemplo, se o primeiro nó falhasse, as três primárias para as três partições diferentes do serviço Círculo seriam todas perdidas. Por outro lado, as partições dos serviços Triangle e Hexagon perdem uma réplica. Isso não causa uma interrupção, só é necessário recuperar a réplica que foi derrubada.
No exemplo inferior, o Gerenciador de Recursos de Cluster distribuiu as réplicas com base no balanceamento global e por serviço. Ao calcular a pontuação da solução, ele fornece a maioria do peso para a solução global e uma parte (configurável) para serviços individuais. O balanceamento global é calculado com base na média dos pesos das métricas definidos para cada serviço. Cada serviço é balanceado de acordo com seus próprios pesos de métricas definidos. Isso garante que os serviços sejam balanceados em si mesmos de acordo com suas próprias necessidades. Como resultado, se o mesmo primeiro nó falhar, a falha é distribuída entre todas as partições de todos os serviços. O impacto para cada um é igual.
- Para obter mais informações sobre a configuração de serviços, Saiba mais sobre como configurar serviços(service-fabric-cluster-resource-manager-configure-services.md)
- A definição de métricas de desfragmentação é uma maneira de consolidar a carga em nós em vez de difundir. Para saber como configurar a desfragmentação, veja este artigo
- Para descobrir como o Gerenciador de Recursos de Cluster gerencia e balanceia carga no cluster, confira o artigo sobre como balancear carga
- Comece do princípio e veja uma introdução ao Resource Manager de Cluster do Service Fabric
- O Custo de Movimento é uma forma de sinalizar para o Gerenciador de Recursos de Cluster que a movimentação de determinados serviços é mais cara do que para outros. Para saber mais sobre o custo de movimento, consulte este artigo