Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Você pode migrar dados de um armazenamento HDFS local do seu cluster Hadoop para o Armazenamento do Microsoft Azure (armazenamento de blobs ou Data Lake Storage) usando um dispositivo Data Box. Você pode escolher entre o Data Box Disk, um Data Box com uma capacidade de 80, 120 ou 525 TiB ou um Data Box Heavy de 770 TiB.
Este artigo mostra como realizar as tarefas abaixo:
- Preparar-se para migrar os dados
- Copiar os dados para um dispositivo Data Box Disk, Data Box ou Data Box Heavy
- Enviar o dispositivo de volta à Microsoft
- Aplicar permissões de acesso a arquivos e diretórios (somente Data Lake Storage)
Pré-requisitos
Você precisa dos itens abaixo para realizar a migração.
Uma conta de armazenamento do Azure.
Um cluster Hadoop local que contém os dados de origem.
Um dispositivo Azure Data Box.
Instale o cabeamento e conecte o Data Box ou o Data Box Heavy a uma rede local.
Se você estiver pronto, vamos começar.
Copiar os dados para um dispositivo Data Box
Se os dados couberem em um só dispositivo Data Box, você copiará os dados para ele.
Se o tamanho dos dados exceder a capacidade do dispositivo Data Box, use o procedimento opcional para dividir os dados em mais de um dispositivo Data Box e depois realize esta etapa.
Para copiar os dados do repositório HDFS local para um dispositivo Data Box, você definirá algumas coisas e usará a ferramenta DistCp.
Siga estas etapas para copiar dados por meio das APIs REST do Armazenamento de blobs/objetos para o dispositivo Data Box. A interface da API REST fará com que o dispositivo apareça como um repositório HDFS para o cluster.
Antes de copiar os dados por REST, identifique os primitivos de segurança e de conexão para a conexão com a interface REST no Data Box ou Data Box Heavy. Entre na IU da Web local do Data Box e abra a página Conectar e copiar. Na conta de armazenamento do Azure do seu dispositivo, em Configurações de acesso, localize e selecione REST.
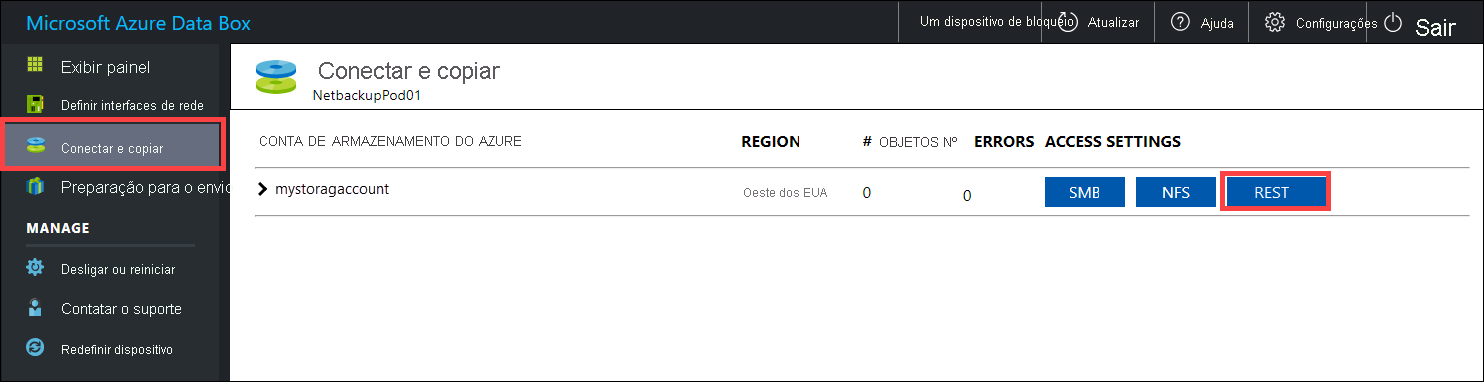
Na caixa de diálogo Acessar a conta de armazenamento e carregar os dados, copie o ponto de extremidade do serviço Blob e a chave de conta de armazenamento. No ponto de extremidade do serviço Blob, omita o
https://e a barra final.Neste caso, o ponto de extremidade é:
https://mystorageaccount.blob.mydataboxno.microsoftdatabox.com/. A parte do host do URI que você usa é:mystorageaccount.blob.mydataboxno.microsoftdatabox.com. Veja o exemplo em Conectar a REST por HTTP.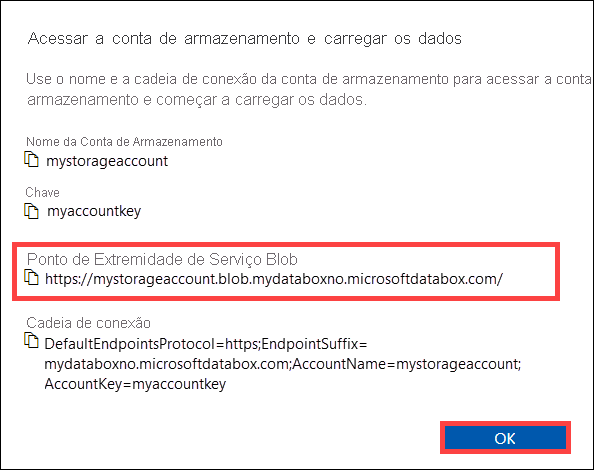
Adicione o ponto de extremidade e o endereço IP do nó do Data Box ou do Data Box Heavy a
/etc/hostsem cada nó.10.128.5.42 mystorageaccount.blob.mydataboxno.microsoftdatabox.comSe você usar outro mecanismo para o DNS, verifique se o ponto de extremidade do Data Box pode ser resolvido.
Defina a variável
azjarsdo shell como o local dos arquivos jarhadoop-azureeazure-storage. Esses arquivos estão no diretório de instalação do Hadoop.Para determinar se eles existem, use o seguinte comando:
ls -l $<hadoop_install_dir>/share/hadoop/tools/lib/ | grep azure. Substitua o espaço reservado<hadoop_install_dir>pelo caminho do diretório em que você instalou o Hadoop. Use caminhos totalmente qualificados.Exemplos:
azjars=$hadoop_install_dir/share/hadoop/tools/lib/hadoop-azure-2.6.0-cdh5.14.0.jarazjars=$azjars,$hadoop_install_dir/share/hadoop/tools/lib/microsoft-windowsazure-storage-sdk-0.6.0.jarCrie o contêiner de armazenamento que você deseja usar para a cópia de dados. Você também deve especificar um diretório de destino como parte desse comando. Pode ser um diretório de destino fictício por enquanto.
hadoop fs -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint>=<account_key> \ -mkdir -p wasb://<container_name>@<blob_service_endpoint>/<destination_directory>Substitua o espaço reservado
<blob_service_endpoint>pelo nome do ponto de extremidade do serviço Blob.Substitua o espaço reservado
<account_key>pela chave de acesso da sua conta.Substitua o espaço reservado
<container-name>pelo nome do contêiner.Substitua o espaço reservado
<destination_directory>pelo nome do diretório no qual você deseja copiar os dados.
Execute um comando de lista para confirmar a criação do contêiner e do diretório.
hadoop fs -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint>=<account_key> \ -ls -R wasb://<container_name>@<blob_service_endpoint>/Substitua o espaço reservado
<blob_service_endpoint>pelo nome do ponto de extremidade do serviço Blob.Substitua o espaço reservado
<account_key>pela chave de acesso da sua conta.Substitua o espaço reservado
<container-name>pelo nome do contêiner.
Copie os dados do HDFS do Hadoop para o armazenamento de blobs do Data Box, no contêiner que você criou. Se o diretório de destino da cópia não for encontrado, o comando o criará automaticamente.
hadoop distcp \ -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint<>=<account_key> \ -filters <exclusion_filelist_file> \ [-f filelist_file | /<source_directory> \ wasb://<container_name>@<blob_service_endpoint>/<destination_directory>Substitua o espaço reservado
<blob_service_endpoint>pelo nome do ponto de extremidade do serviço Blob.Substitua o espaço reservado
<account_key>pela chave de acesso da sua conta.Substitua o espaço reservado
<container-name>pelo nome do contêiner.Substitua o espaço reservado
<exclusion_filelist_file>pelo nome do arquivo que contém a lista de exclusões de arquivo.Substitua o espaço reservado
<source_directory>pelo nome do diretório que contém os dados que você quer copiar.Substitua o espaço reservado
<destination_directory>pelo nome do diretório no qual você deseja copiar os dados.
A opção
-libjarsé usada para disponibilizar ohadoop-azure*.jare os arquivos dependentes deazure-storage*.jaraodistcp. Talvez isso já ocorra em alguns clusters.O exemplo a seguir mostra como usar o comando
distcppara copiar dados.hadoop distcp \ -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.mystorageaccount.blob.mydataboxno.microsoftdatabox.com=myaccountkey \ -filter ./exclusions.lst -f /tmp/copylist1 -m 4 \ /data/testfiles \ wasb://hdfscontainer@mystorageaccount.blob.mydataboxno.microsoftdatabox.com/dataPara melhorar a velocidade de cópia:
Altere o número de mapeadores. (O número padrão de mapeadores é 20. O exemplo acima usa
m= 4 mapeadores.)Experimente
-D fs.azure.concurrentRequestCount.out=<thread_number>. Substitua<thread_number>pelo número de threads por mapeador. O produto do número de mapeadores e o número de threads por mapeador,m*<thread_number>, não deve exceder 32.Execute vários
distcpem paralelo.Lembre-se de que arquivos grandes têm desempenho melhor do que arquivos pequenos.
Caso você tenha arquivos maiores que 200 GB, recomendamos alterar o tamanho do bloco para 100 MB com os seguintes parâmetros:
hadoop distcp \ -libjars $azjars \ -Dfs.azure.write.request.size= 104857600 \ -Dfs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -Dfs.azure.account.key.<blob_service_endpoint<>=<account_key> \ -strategy dynamic \ -Dmapreduce.map.memory.mb=16384 \ -Dfs.azure.concurrentRequestCount.out=8 \ -Dmapreduce.map.java.opts=-Xmx8196m \ -m 4 \ -update \ /data/bigfile wasb://hadoop@mystorageaccount.blob.core.windows.net/bigfile
Enviar o Data Box à Microsoft
Siga estas etapas para preparar e enviar o dispositivo Data Box à Microsoft.
Primeiro, prepare-se para enviar o Data Box ou o Data Box Heavy.
Após a preparação do dispositivo, baixe os arquivos de BOM. Você usa esses arquivos de manifesto ou de BOM posteriormente para verificar os dados carregados no Azure.
Desligue o dispositivo e remova os cabos.
Agende uma retirada com a UPS.
Para dispositivos Data Box, confira Enviar sua Data Box.
Para dispositivos Data Box Heavy, confira Enviar sua Data Box Heavy.
Quando a Microsoft recebe o dispositivo, ele é conectado à rede do data center, e os dados são carregados na conta de armazenamento que você especificou quando fez o pedido do dispositivo. Confirme que todos os dados foram carregados no Azure usando os arquivos de BOM.
Aplicar permissões de acesso a arquivos e diretórios (somente Data Lake Storage)
Você já tem os dados em sua conta do Armazenamento do Azure. Agora, você aplica permissões de acesso aos arquivos e aos diretórios.
Observação
Essa etapa é necessária somente se você estiver usando o Azure Data Lake Storage como seu armazenamento de dados. Se você usa apenas uma conta de armazenamento de blobs sem namespace hierárquico como armazenamento de dados, ignore esta seção.
Crie uma entidade de serviço para sua conta habilitada para o Azure Data Lake Storage
Para criar uma entidade de serviço, confira Como usar o portal para criar um aplicativo do Microsoft Entra e uma entidade de serviço que possam acessar recursos.
Ao executar as etapas da seção Atribuir o aplicativo a uma função do artigo, atribua a função Colaborador dos Dados do Storage Blob à entidade de serviço.
Ao seguir as etapas da seção Obter valores para se conectar do artigo, salve a ID do aplicativo e o segredo do cliente em um arquivo de texto. Você precisará deles em breve.
Gerar uma lista dos arquivos copiados com as respectivas permissões
No cluster Hadoop local, execute este comando:
sudo -u hdfs ./copy-acls.sh -s /{hdfs_path} > ./filelist.json
O comando gera a lista dos arquivos copiados com as respectivas permissões.
Observação
Dependendo do número de arquivos no HDFS, a execução do comando pode demorar.
Gerar uma lista de identidades e mapeá-las para identidades do Microsoft Entra
Baixe o script
copy-acls.py. Confira a seção Baixar scripts auxiliares e configurar o nó de borda para executá-los deste artigo.Execute este comando para gerar uma lista de identidades exclusivas.
./copy-acls.py -s ./filelist.json -i ./id_map.json -gO script gera um arquivo chamado
id_map.json, que contém as identidades que você precisa mapear às identidades do ADD.Abra o arquivo
id_map.jsonem um editor de texto.Para cada objeto JSON que aparece no arquivo, atualize o atributo
targetde um nome UPN ou OID (ObjectId) do Microsoft Entra, com a identidade mapeada apropriada. Salve o arquivo quando terminar. Você precisará dele na próxima etapa.
Aplicar permissões a arquivos copiados e aplicar mapeamentos de identidade
Execute esse comando para aplicar permissões aos dados que você copiou para a conta habilitada para o Data Lake Storage:
./copy-acls.py -s ./filelist.json -i ./id_map.json -A <storage-account-name> -C <container-name> --dest-spn-id <application-id> --dest-spn-secret <client-secret>
Substitua o espaço reservado
<storage-account-name>pelo nome da sua conta de armazenamento.Substitua o espaço reservado
<container-name>pelo nome do contêiner.Substitua os espaços reservados
<application-id>e<client-secret>pela ID do aplicativo e o segredo do cliente que você anotou ao criar a entidade de serviço.
Apêndice: dividir dados em mais de um dispositivo Data Box
Antes de mover os dados para o dispositivo Data Box, você precisa baixar alguns scripts auxiliares, organizar os dados para que caibam no dispositivo e excluir os arquivos desnecessários.
Baixar scripts auxiliares e configurar o nó de borda para executá-los
No nó de borda ou principal do cluster Hadoop local, execute este comando:
git clone https://github.com/jamesbak/databox-adls-loader.git cd databox-adls-loaderO comando clona o repositório do GitHub que contém os scripts auxiliares.
Verifique se o pacote jq está instalado no computador local.
sudo apt-get install jqInstale o pacote de Python Requests.
pip install requestsDefina as permissões de execução nos scripts necessários.
chmod +x *.py *.sh
Organizar os dados para que caibam em um dispositivo Data Box
Se o tamanho dos dados exceder o tamanho de um dispositivo Data Box, divida os arquivos em grupos para armazená-los em mais de um dispositivo.
Se os dados não excederem o tamanho de um único dispositivo Data Box, você poderá prosseguir para a próxima seção.
Com permissões elevadas, execute o script
generate-file-listque você baixou na seção anterior.Aqui está uma descrição dos parâmetros de comando:
sudo -u hdfs ./generate-file-list.py [-h] [-s DATABOX_SIZE] [-b FILELIST_BASENAME] [-f LOG_CONFIG] [-l LOG_FILE] [-v {DEBUG,INFO,WARNING,ERROR}] path where: positional arguments: path The base HDFS path to process. optional arguments: -h, --help show this help message and exit -s DATABOX_SIZE, --databox-size DATABOX_SIZE The size of each Data Box in bytes. -b FILELIST_BASENAME, --filelist-basename FILELIST_BASENAME The base name for the output filelists. Lists will be named basename1, basename2, ... . -f LOG_CONFIG, --log-config LOG_CONFIG The name of a configuration file for logging. -l LOG_FILE, --log-file LOG_FILE Name of file to have log output written to (default is stdout/stderr) -v {DEBUG,INFO,WARNING,ERROR}, --log-level {DEBUG,INFO,WARNING,ERROR} Level of log information to output. Default is 'INFO'.Copie as listas de arquivos geradas para o HDFS, de modo que o trabalho do DistCp possa acessá-las.
hadoop fs -copyFromLocal {filelist_pattern} /[hdfs directory]
Excluir arquivos desnecessários
Você precisa excluir alguns diretórios do trabalho do DistCp. Por exemplo, exclua os diretórios que contêm informações de estado que mantêm o cluster em operação.
No cluster Hadoop local em que você iniciará o trabalho do DistCp, crie um arquivo que especifique a lista dos diretórios a serem excluídos.
Aqui está um exemplo:
.*ranger/audit.*
.*/hbase/data/WALs.*
Próximas etapas
Saiba como o Data Lake Storage funciona com clusters HDInsight. Para obter mais informações, veja Usar o Azure Data Lake Storage com clusters do Azure HDInsight.