Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Este tutorial mostra como coletar estatísticas sobre seus contêineres usando o inventário do Armazenamento de Blobs do Azure junto com o Azure Databricks.
Neste tutorial, você aprenderá como:
- Gerar um relatório de inventário
- Crie um workspace do Azure Databricks e um notebook
- Ler o arquivo de inventário de blobs
- Obter o número e o tamanho total de blobs, instantâneos e versões
- Obter o número de blobs por tipo de blob e tipo de conteúdo
Pré-requisitos
Uma assinatura do Azure – criar uma conta gratuitamente
Uma conta de armazenamento do Azure – criar uma conta de armazenamento
Verifique se a sua identidade de usuário tem a função Colaborador de Dados do Storage Blob atribuída a ela.
Gerar um relatório de inventário
Habilite os relatórios de inventário de blobs para a sua conta de armazenamento. Consulte Habilitar relatórios de inventário de blobs do Armazenamento do Azure.
Use as seguintes configurações:
| Configuração | Valor |
|---|---|
| Nome da regra | blobinventory |
| Contêiner | <nome do contêiner> |
| Tipo de objeto para inventário | Blob |
| Tipos de blobs | Blobs de blocos, blobs de páginas e blobs de acréscimo |
| Subtipos | incluir versões de blob, incluir instantâneos, incluir blobs excluídos |
| Campos de inventário de blobs | Todos |
| Frequência de inventário | Diariamente |
| Formato de exportação | CSV |
Talvez seja necessário aguardar até 24 horas depois de habilitar os relatórios de inventário para que o seu primeiro relatório seja gerado.
Configurar o Azure Databricks
Nesta seção, você criará um workspace e um notebook do Azure Databricks. Posteriormente neste tutorial, você colará snippets de código em células de notebook e, em seguida, os executará para coletar estatísticas de contêiner.
Criar um workspace do Azure Databricks. Consulte Criar um workspace do Azure Databricks.
Criar um notebook novo. Consulte Criar um notebook.
Escolha Python como o idioma padrão do notebook.
Ler o arquivo de inventário de blobs
Copie e cole o bloco de código a seguir na primeira célula, mas não execute esse código ainda.
from pyspark.sql.types import StructType, StructField, IntegerType, StringType import pyspark.sql.functions as F storage_account_name = "<storage-account-name>" storage_account_key = "<storage-account-key>" container = "<container-name>" blob_inventory_file = "<blob-inventory-file-name>" hierarchial_namespace_enabled = False if hierarchial_namespace_enabled == False: spark.conf.set("fs.azure.account.key.{0}.blob.core.windows.net".format(storage_account_name), storage_account_key) df = spark.read.csv("wasbs://{0}@{1}.blob.core.windows.net/{2}".format(container, storage_account_name, blob_inventory_file), header='true', inferSchema='true') else: spark.conf.set("fs.azure.account.key.{0}.dfs.core.windows.net".format(storage_account_name), storage_account_key) df = spark.read.csv("abfss://{0}@{1}.dfs.core.windows.net/{2}".format(container, storage_account_name, blob_inventory_file), header='true', inferSchema='true')Neste bloco de código, substitua os seguintes valores:
Substitua o valor de espaço reservado
<storage-account-name>pelo nome da sua conta de armazenamento.Substitua o valor de espaço reservado
<storage-account-key>pelo nome da sua conta de armazenamento.Substitua o valor do espaço reservado
<container-name>pelo contêiner que contém os relatórios de inventário.Substitua o espaço reservado
<blob-inventory-file-name>pelo nome totalmente qualificado do arquivo de inventário (por exemplo:2023/02/02/02-16-17/blobinventory/blobinventory_1000000_0.csv).Se sua conta tiver um namespace hierárquico, defina a variável
hierarchical_namespace_enabledcomoTrue.
Pressione o botão Executar para executar o código nesta célula.
Obter contagem e tamanho de blobs
Em uma nova célula, cole o seguinte código:
print("Number of blobs in the container:", df.count()) print("Number of bytes occupied by blobs in the container:", df.agg({'Content-Length': 'sum'}).first()['sum(Content-Length)'])Pressione o botão Executar para executar a célula.
O notebook exibe o número de blobs em um contêiner e o número de bytes ocupados por blobs no contêiner.

Obter contagem e tamanho de instantâneos
Em uma nova célula, cole o seguinte código:
from pyspark.sql.functions import * print("Number of snapshots in the container:", df.where(~(col("Snapshot")).like("Null")).count()) dfT = df.where(~(col("Snapshot")).like("Null")) print("Number of bytes occupied by snapshots in the container:", dfT.agg({'Content-Length': 'sum'}).first()['sum(Content-Length)'])Pressione o botão Executar para executar a célula.
O notebook exibe o número de instantâneos e o número total de bytes ocupados por instantâneos de blob.

Obter a contagem e o tamanho das versões
Em uma nova célula, cole o seguinte código:
from pyspark.sql.functions import * print("Number of versions in the container:", df.where(~(col("VersionId")).like("Null")).count()) dfT = df.where(~(col("VersionId")).like("Null")) print("Number of bytes occupied by versions in the container:", dfT.agg({'Content-Length': 'sum'}).first()['sum(Content-Length)'])Pressione SHIFT + ENTER para executar a célula.
O notebook exibe o número de versões de blob e o número total de bytes ocupados por versões de blob.

Obter contagem de blobs por tipo de blob
Em uma nova célula, cole o seguinte código:
display(df.groupBy('BlobType').count().withColumnRenamed("count", "Total number of blobs in the container by BlobType"))Pressione SHIFT + ENTER para executar a célula.
O notebook exibe o número de tipos de blob por tipo.

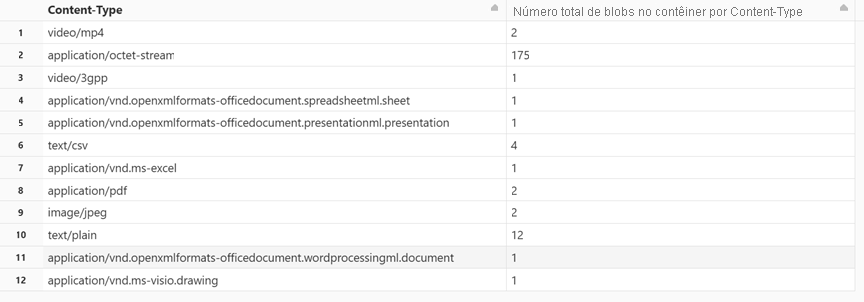
Obter contagem de blobs por tipo de conteúdo
Em uma nova célula, cole o seguinte código:
display(df.groupBy('Content-Type').count().withColumnRenamed("count", "Total number of blobs in the container by Content-Type"))Pressione SHIFT + ENTER para executar a célula.
O notebook exibe o número de blobs associados a cada tipo de conteúdo.
Encerrar o cluster
Para evitar cobrança desnecessária, encerre o recurso de computação. Consulte Encerrar uma computação.
Próximas etapas
Saiba como usar o Azure Synapse para calcular a contagem de blobs e o tamanho total de blobs por contêiner. Confira Calcular a contagem de blobs e o tamanho total por contêiner usando o inventário de Armazenamento do Azure
Saiba como gerar e visualizar estatísticas que descrevem contêineres e blobs. Confira Tutorial: analisar relatórios de inventário de blobs
Saiba mais sobre maneiras de otimizar seus custos de acordo com a análise de seus blobs e contêineres. Consulte estes artigos:
Planejar e gerenciar custos do Armazenamento de Blobs do Azure
Estimar o custo de arquivamento de dados
Otimizar os custos gerenciando automaticamente o ciclo de vida dos dados