Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Neste artigo, você aprenderá a modificar um banco de dados do Lake existente no Azure Synapse usando o designer de banco de dados. Veja como os dados serão extraídos sem escrever nenhum código.
Pré-requisitos
- As permissões de Administrador do Azure Synapse ou de Colaborador do Azure Synapse são necessárias no Workspace do Azure Synapse para criar um banco de dados do Lake.
- As permissões de Colaborador de Dados de Blob de Armazenamento serão necessárias no data lake ao usar a opção criar tabela Do data lake.
Modificar as propriedades de banco de dados
No seu hub inicial do Workspace do Azure Synapse Analytics, selecione a guia Dados à esquerda. A guia Dados será aberta. Você verá a lista de bancos de dados que já existem em seu workspace.
Passe o mouse sobre a seção Bancos de Dados e selecione as reticências ... ao lado do banco de dados que você deseja modificar e, em seguida, escolha Abrir.
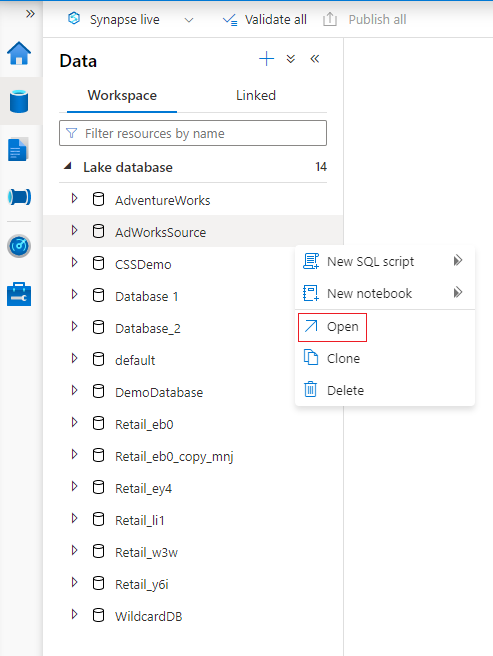
A guia designer de banco de dados será aberta com o banco de dados selecionado carregado na tela.
O designer de banco de dados possui o painel Propriedades que pode ser aberto selecionando o ícone Propriedades no canto superior direito da guia.
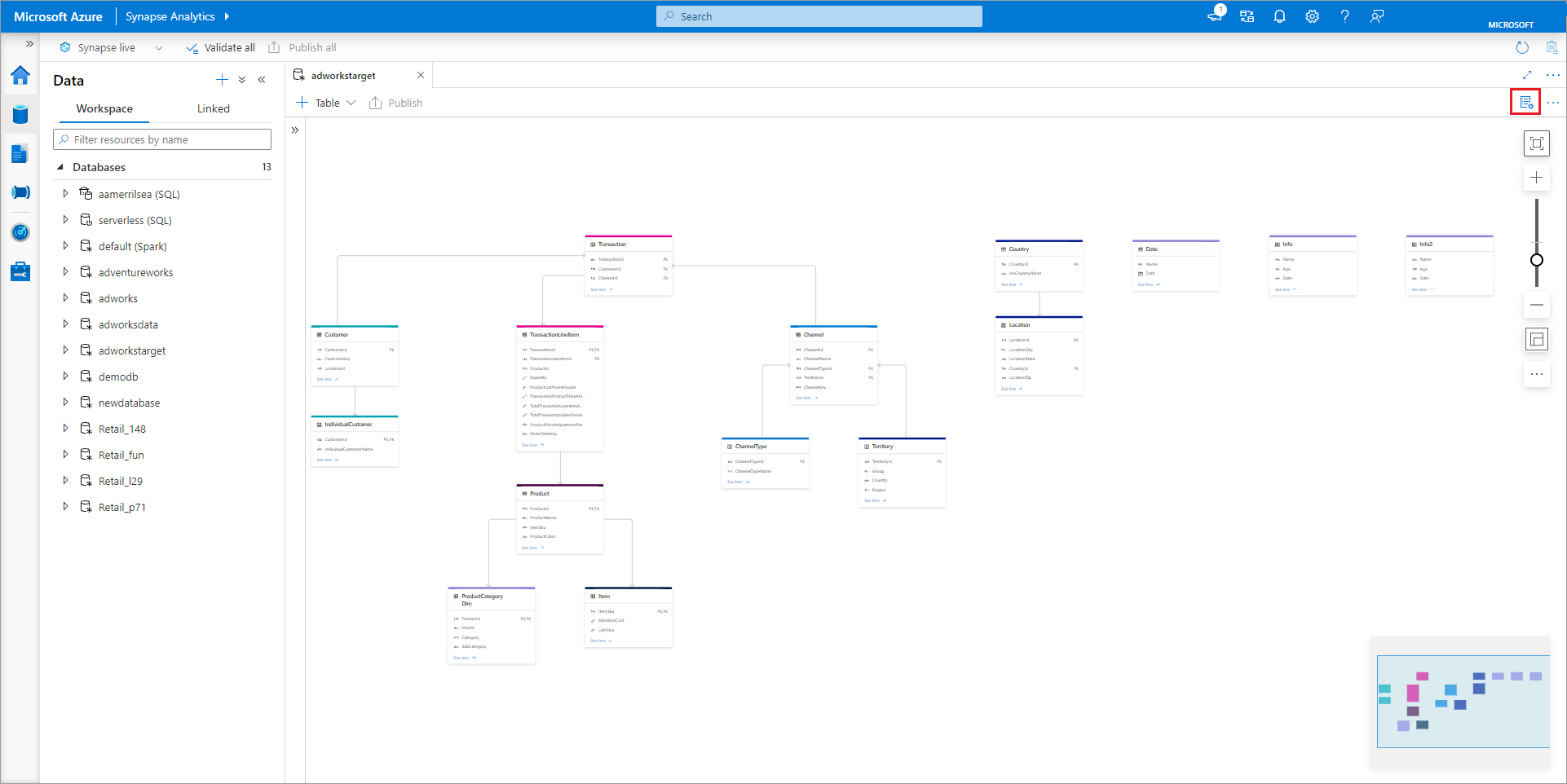
- Nome Os nomes não podem ser editados depois que o banco de dados é publicado, portanto, certifique-se de que o nome escolhido está correto.
- Descrição O fornecimento de uma descrição ao banco de dados é opcional, mas permite que os usuários entendam a finalidade do banco de dados.
- Configurações de armazenamento para o banco de dados é uma seção que contém as informações de armazenamento padrão para tabelas no banco de dados. As configurações padrão são aplicadas a cada tabela no banco de dados, a menos que sejam substituídas na própria tabela.
- O serviço vinculado é o serviço vinculado padrão usado para armazenar seus dados no Azure Data Lake Storage. O serviço vinculado padrão associado ao Workspace do Synapse será mostrado, mas você poderá alterar o Serviço Vinculado em qualquer conta de armazenamento do ADLS desejada.
- A pasta de entrada usada para definir o caminho padrão do contêiner e da pasta nesse serviço vinculado usando o navegador de arquivos ou editando manualmente o caminho com o ícone de lápis.
- Formato de dados Os bancos de dados do Lake no Azure Synapse dão suporte a Parquet e textos delimitados como formatos de armazenamento para dados.
Para adicionar uma tabela ao banco de dados, selecione o botão + Tabela.
- Personalizado adicionará uma nova tabela à tela.
- Do modelo abrirá a galeria e permitirá que você selecione um modelo de banco de dados a ser usado ao adicionar uma nova tabela. Para mais informações, consulte Criar um banco de dados Lake a partir de um modelo de banco de dados.
- Do Data Lake é possível importar um esquema de tabela usando dados que já estão em seu Lake.
selecione Personalizado. Uma nova tabela será exibida na tela chamada Table_1.
Em seguida, você pode personalizar Table_1, incluindo o nome da tabela, a descrição, as configurações de armazenamento, as colunas e as relações. Consulte a seção Personalizar tabelas em um banco de dados abaixo.
Adicione uma nova tabela do Data Lake selecionando + Tabela e, em seguida, Do Data Lake.
O painel Criar tabela externa do Data Lake aparecerá. Preencha o painel com os detalhes abaixo e selecione Continuar.
- Nome da tabela externa o nome que você deseja fornecer à tabela que está criando.
- Serviço vinculado o serviço vinculado que contém o local do Azure Data Lake Storage onde seu arquivo de dados reside.
-
Pasta ou arquivo de entrada use o navegador de arquivos para navegar e selecionar um arquivo no seu Lake que você deseja usar para criar uma tabela.
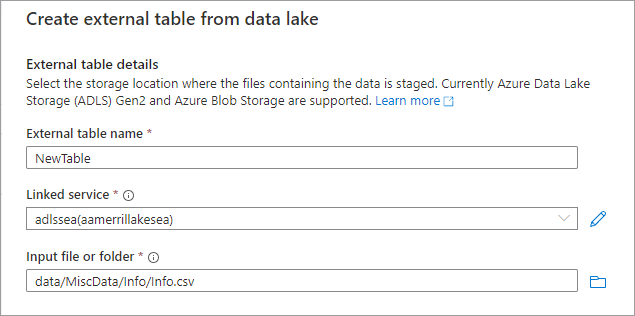
- Na próxima tela, o Azure Synapse visualizará o arquivo e detectará o esquema.
- Você irá acessar a página Nova tabela externa, na qual poderá atualizar as configurações relacionadas ao formato de dados e Visualizar Dados para verificar se o Azure Synapse identificou o arquivo corretamente.
- Quando terminar, selecione Criar.
- Uma nova tabela com o nome selecionado será adicionada à tela e a seção Configurações de armazenamento da tabela mostrará o arquivo especificado.
Com o banco de dados personalizado, agora é hora de publicá-lo. Se você estiver usando a integração do Git ao workspace do Synapse, você deverá confirmar as alterações e mesclá-las na branch de colaboração. Saiba mais sobre o controle do código-fonte no Azure Synapse. Se você estiver usando o modo Dinâmico do Synapse, poderá selecionar "publicar".
Seu banco de dados será validado para erros antes de ser publicado. Todos os erros encontrados serão exibidos na guia de notificações com instruções sobre como corrigir o erro.
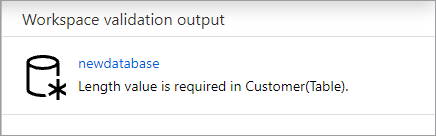
A publicação criará o esquema de banco de dados no Metastore do Azure Synapse. Após a publicação, os objetos do banco de dados e da tabela estarão visíveis para outros serviços do Azure e permitirão que os metadados do banco de dados fluam para aplicativos como o Power BI ou o Microsoft Purview.
Personalizar tabelas em um banco de dados
O designer de banco de dados permite personalizar totalmente qualquer uma das tabelas em seu banco de dados. Quando você seleciona uma tabela, há três guias disponíveis, cada uma contendo configurações relacionadas ao esquema ou aos metadados da tabela.
Geral
A guia Geral contém informações específicas da própria tabela.
Nome o nome da tabela. O nome da tabela pode ser personalizado para qualquer valor exclusivo no banco de dados. Não são permitidas várias tabelas com o mesmo nome.
Herdado de (opcional) esse valor estará presente se a tabela tiver sido criada a partir de um modelo de banco de dados. Ele não pode ser editado e informa ao usuário de qual tabela de modelo foi derivado.
Descrição uma descrição da tabela. Se a tabela tiver sido criada com base em um modelo de banco de dados, ela conterá uma descrição do conceito representado por esta tabela. Esse campo é editável e pode ser alterado para corresponder à descrição que corresponde aos seus requisitos de negócios.
Pasta de exibição fornece o nome da pasta da área de negócios em que essa tabela foi agrupada como parte do modelo de banco de dados. Para tabelas personalizadas, esse valor será "Outros".
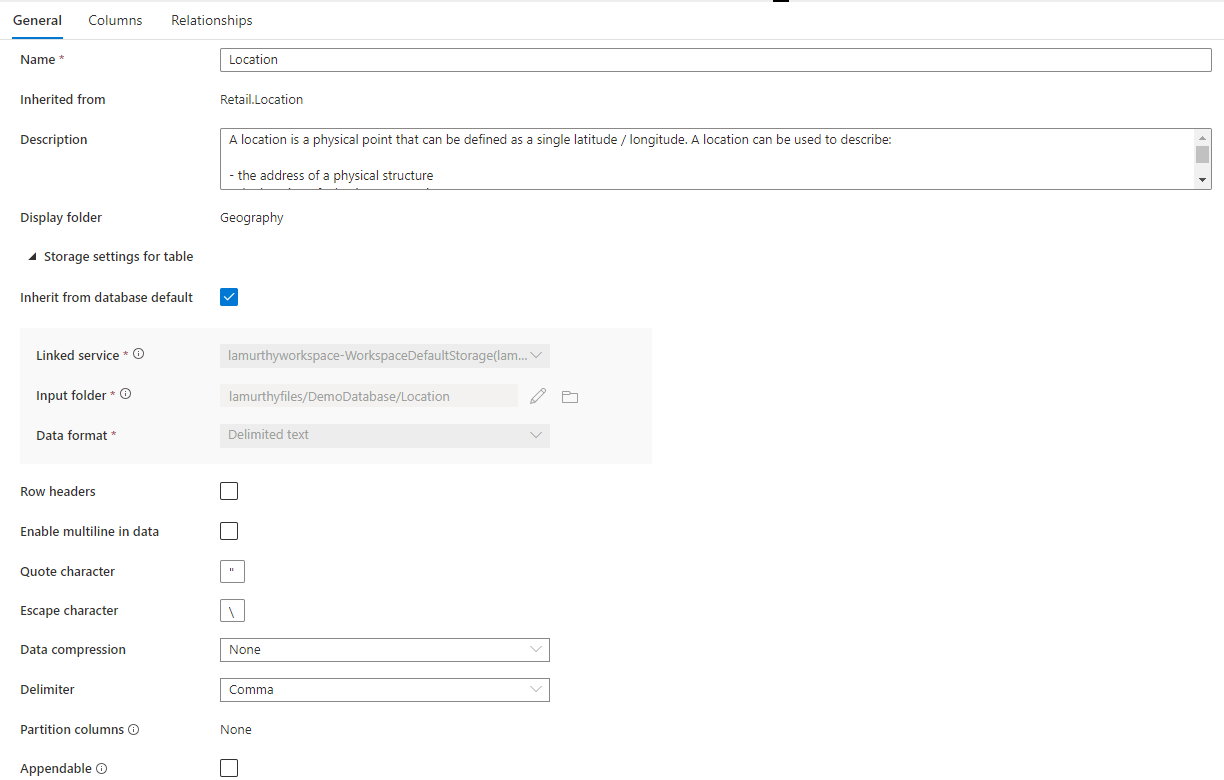
Além disso, há uma seção recolhível chamada Configurações de armazenamento da tabela que fornece configurações para as informações de armazenamento subjacentes usadas pela tabela.
Herdar do padrão do banco de dados uma caixa de seleção que determina se as configurações de armazenamento abaixo são herdadas dos valores definidos na guia Propriedades do banco de dados ou são definidas individualmente. Se você quiser personalizar os valores de armazenamento, desmarque essa caixa.
- O serviço vinculado é o serviço vinculado padrão usado para armazenar seus dados no Azure Data Lake Storage. Altere isso para escolher uma conta do ADLS diferente.
- Pasta de entrada da pasta no ADLS em que os dados carregados nesta tabela residirão. Você pode navegar pelo local da pasta ou editá-la manualmente usando o ícone de lápis.
- Formato de dados o formato dos dados na Pasta de entrada Os bancos de dados do Lake no Azure Synapse dão suporte a Parquet e textos delimitados como formatos de armazenamento para dados. Se o formato de dados não corresponder aos dados na pasta, as consultas à tabela falharão.
Para um Formato de dados de Texto delimitado, há outras configurações:
- Cabeçalhos de linha marque essa caixa se os dados tiverem cabeçalhos de linha.
- Habilitar multilinha em dados marque essa caixa se os dados tiverem várias linhas em uma coluna de cadeia de caracteres.
- Caractere de aspas especifica o caractere de aspas personalizado para um arquivo de texto delimitado.
- Caractere de escape especifica o caractere de escape personalizado para um arquivo de texto delimitado.
- Compactação de dados o tipo de compactação usado nos dados.
- Delimitador o campo delimitador usado nos arquivos de dados. Os valores com suporte são: Vírgula (,), tabulação (\t) e barra vertical (|).
- Colunas de partição a lista de colunas de partição será exibida aqui.
- Anexável marque essa caixa se você estiver consultando dados do Dataverse do SQL sem servidor.
Para dados Parquet, há a seguinte configuração:
- Compactação de dados o tipo de compactação usado nos dados.
Colunas
A guia Colunas é onde as colunas da tabela são listadas e podem ser modificadas. Nessa guia, há duas listas de colunas: Colunas padrão e Colunas de partição. As colunas padrão são qualquer coluna que armazena dados, é uma chave primária e não é usada para o particionamento dos dados. As colunas de partição também armazenam dados, mas são usadas para particionar os dados subjacentes em pastas com base nos valores contidos na coluna. Cada coluna possui as propriedades a seguir.
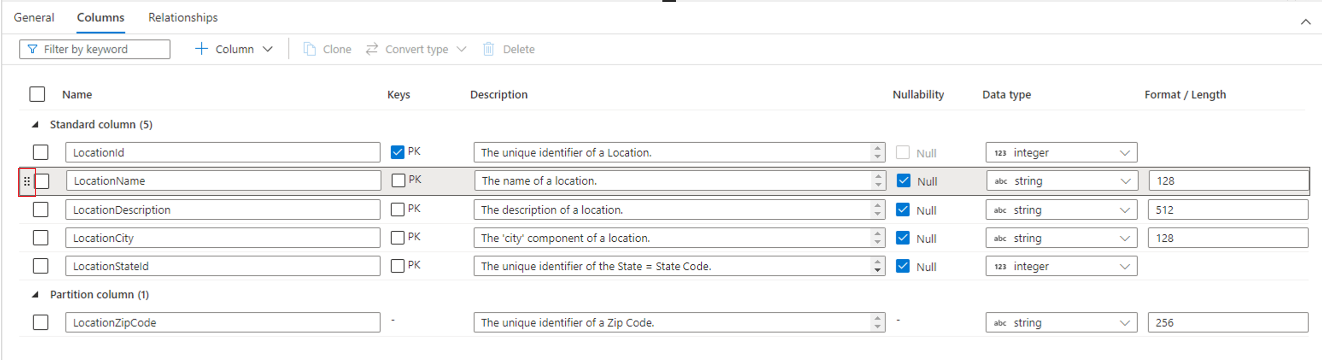
- Nome o nome da coluna. Deve ser exclusivo na tabela.
- Chaves indica se a coluna é uma chave primária (PK) e/ou chave estrangeira (FK) para a tabela. Não aplicável a colunas de partição.
- Descrição uma descrição da coluna. Se a coluna tiver sido criada com base em um modelo de banco de dados, a descrição do conceito representado por essa coluna será vista. Esse campo é editável e pode ser alterado para corresponder à descrição que corresponde aos seus requisitos de negócios.
- Nulidade indica se pode haver valores nulos nesta coluna. Não aplicável a colunas de partição.
- Tipo de dados define o tipo de dados da Coluna com base na lista disponível de tipos de dados do Spark.
- Formato/comprimento permite personalizar o formato ou o comprimento máximo da coluna, dependendo do tipo de dados. Os tipos de dados data e carimbo de data/hora possuem lista suspensa de formato e outros tipos, como cadeia de caracteres, possuem um campo de comprimento máximo. Nem todos os tipos de dados têm um valor, pois alguns tipos têm comprimento fixo. Na parte superior da guia Colunas, há uma barra de comandos que pode ser usada para interagir com as colunas.
- Filtrar por palavra-chave filtra a lista de colunas para itens que correspondam à palavra-chave especificada.
-
+ Coluna permite que você adicione uma nova coluna. Há três opções possíveis.
- Nova coluna cria uma nova coluna padrão personalizada.
- Do modelo abre o painel exploração e permite que você identifique colunas de um modelo de banco de dados para incluir em sua tabela. Se o banco de dados não foi criado usando um modelo de banco de dados, essa opção não será exibida.
- Coluna de partição adiciona uma nova coluna de partição personalizada.
- Clonar duplica a coluna selecionada. As colunas clonadas são sempre do mesmo tipo que a coluna selecionada.
- Converter tipo é usado para alterar a coluna padrão selecionada para uma coluna de partição e vice-versa. Essa opção ficará esmaecida se você tiver selecionado várias colunas de tipos diferentes ou se a coluna selecionada não estiver qualificada para ser convertida devido a um sinalizador de PK ou de Nulidade definido na coluna.
- Excluir exclui as colunas selecionadas da tabela. Essa ação é irreversível.
Também é possível reorganizar a ordem das colunas ao arrastar e soltar usando as reticências verticais duplas que aparecem à esquerda do nome da coluna quando você passa o mouse ou clica na coluna, conforme mostrado na imagem acima.
Colunas de Partição
Colunas de partição são usadas para particionar os dados físicos em seu banco de dado com base nos valores nessas colunas. As colunas de partição fornecem uma maneira fácil de distribuir dados em disco em partes mais eficazes. As colunas de partição no Azure Synapse sempre estão no final do esquema da tabela. Além disso, elas são usadas de cima para baixo ao criar as pastas de partição. Por exemplo, se suas colunas de partição eram Ano e Mês, você acabaria com uma estrutura no ADLS como esta:
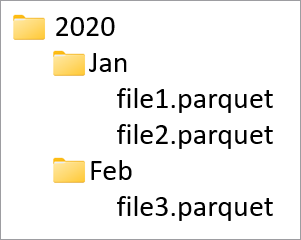
Onde file1 e file2 continham todas as linhas em que os valores de Ano e Mês eram 2020 e Jan respectivamente. Conforme mais colunas de partição são adicionadas a uma tabela, mais arquivos são adicionados a essa hierarquia, tornando o tamanho geral do arquivo das partições menores.
O Azure Synapse não impõe nem cria essa hierarquia adicionando colunas de partição a uma tabela. Os dados devem ser carregados na tabela usando o Synapse Pipelines ou um notebook do Spark para que a estrutura de partição seja criada.
Relações
A guia relações permite especificar relações entre tabelas no banco de dados. As relações no designer de banco de dados são informativas e não impõem nenhuma restrição nos dados subjacentes. Elas são lidas por outros aplicativos da Microsoft que podem ser usados para acelerar as transformações ou fornecer aos usuários empresariais insights sobre como as tabelas são conectadas. O painel Relações tem as seguintes informações.
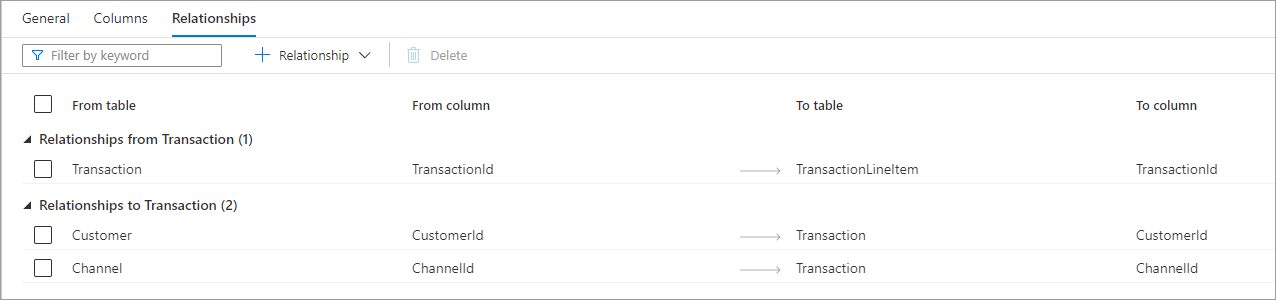
- Relações de (Tabela) é quando uma ou mais tabelas têm chaves estrangeiras conectadas a esta tabela. Isso às vezes é chamado de relação de pai.
- Relações para (Tabela) é quando uma tabela com chave estrangeira é conectada a outra tabela. Isso às vezes é chamado de relação de filho.
- Ambos os tipos de relação têm as propriedades a seguir.
- Da tabela a tabela pai na relação ou o lado "um".
- Da coluna a coluna na tabela pai na qual a relação se baseia.
- Para a tabela a tabela filho na relação ou o lado "muitos".
- Para a coluna a coluna na tabela filho na qual a relação se baseia. Na parte superior da guia Relações, está a barra de comandos que pode ser usada para interagir com as relações
- Filtrar por palavra-chave filtra a lista de colunas para itens que correspondam à palavra-chave especificada.
-
+ Relação permite que você adicione uma nova relação. Há duas opções.
- Da tabela cria uma nova relação da tabela na qual você está trabalhando para uma tabela diferente.
- Para a tabela cria uma nova relação de uma tabela diferente para aquela na qual você está trabalhando.
- Do modelo abre o painel exploração e permite que você escolha das relações no modelo de banco de dados para incluir no banco de dados. Se o banco de dados não foi criado usando um modelo de banco de dados, essa opção não será exibida.
Próximas etapas
Continue explorando os recursos do designer de banco de dados usando os links abaixo.