White paper de segurança do Azure Synapse Analytics: Introdução
Resumo:o Azure Synapse Analytics é uma plataforma de análise ilimitada da Microsoft que integra o data warehousing corporativo e o processamento de Big Data em um ambiente gerenciado sem necessidade de integração do sistema. O Azure Synapse fornece as ferramentas de ponta a ponta para seu ciclo de vida de análise com:
- Pipelines para integração de dados.
- Pool do Apache Spark para processamento de Big Data.
- Data Explorer para análise de log e série temporal.
- Pool de SQL sem servidor para exploração de dados no Azure Data Lake.
- Pool de SQL dedicado (antigo SQL DW) para data warehousing corporativo.
- Integração profunda com o Power BI, o Azure Cosmos DB e o Azure Machine Learning.
A segurança e a privacidade de dados do Azure Synapse não são negociáveis. A finalidade deste white paper é fornecer uma visão geral abrangente dos recursos de segurança do Azure Synapse, que são de nível corporativo e líderes do setor. O white paper inclui uma série de artigos que abrangem as seguintes cinco camadas de segurança:
- Proteção de dados
- Controle de acesso
- Autenticação
- Segurança de rede
- Proteção contra ameaças
Este white paper é direcionado para todos os stakeholders de segurança corporativa. Ele inclui administradores de segurança, de rede, do Azure, de workspace e de banco de dados.
Autores: Vengatesh Parasuraman, Fretz Nuson, Ron Dunn, Khendr'a Reid, John Hoang, Nithesh Krishnappa, Mykola Kovalenko, Brad Schacht, Pedro Martinez, Mark Pryce-Maher e Arshad Ali.
Revisores técnicos: Nandita Valsan, Rony Thomas, Abhishek Narain, Daniel Crawford e Tammy Richter Jones.
Aplica-se a: Azure Synapse Analytics, pool de SQL dedicado (antigo SQL DW), pool de SQL sem servidor e pool do Apache Spark.
Importante
Este white paper não se aplica ao Banco de Dados SQL do Azure, à Instância Gerenciada de SQL do Azure, ao Azure Machine Learning nem ao Azure Databricks.
Introdução
Títulos frequentes de violações de dados, infecções de malware e injeção de código mal-intencionado estão entre uma ampla lista de preocupações de segurança para empresas que buscam a modernização de nuvem. O cliente corporativo requer um provedor de nuvem ou uma solução de serviço que possa resolver essas preocupações, pois ele não pode se dar ao luxo de errar.
Algumas perguntas comuns de segurança incluem:
- Como posso controlar quem pode ver quais dados?
- Quais são as opções para verificar a identidade de um usuário?
- Como meus dados são protegidos?
- Qual tecnologia de segurança de rede posso usar para proteger a integridade, a confidencialidade e o acesso de minhas redes e dados?
- Quais são as ferramentas que detectam e me notificam de ameaças?
A finalidade deste white paper é fornecer respostas a essas perguntas comuns de segurança e muitas outras.
Arquitetura de componente
O Azure Synapse é um serviço de análise de PaaS (Plataforma como serviço) que reúne vários componentes independentes, como pools de SQL dedicados, pools de SQL sem servidor, pools do Apache Spark e pipelines de integração de dados. Esses componentes foram projetados para trabalhar em conjunto a fim de fornecer uma experiência de plataforma analítica perfeita.
Pools de SQL dedicados são clusters provisionados que fornecem recursos de data warehouse corporativos para cargas de trabalho do SQL. Os dados são ingeridos no armazenamento gerenciado da plataforma de Armazenamento do Azure, que também é um serviço de PaaS. A computação é isolada do armazenamento, permitindo que os clientes dimensionem a computação de modo independente de seus dados. Os pools de SQL dedicados também permitem consultar arquivos de dados diretamente em contas de Armazenamento do Azure gerenciadas pelo cliente usando tabelas externas.
Pools de SQL sem servidor são clusters sob demanda que fornecem uma interface SQL para consultar e analisar dados diretamente em contas de Armazenamento do Azure gerenciadas pelo cliente. Como eles estão sem servidor, não há um armazenamento gerenciado e os nós de computação são dimensionados automaticamente em resposta à carga de trabalho de consulta.
O Apache Spark no Azure Synapse é uma das implementações da Microsoft do Apache Spark de código aberto na nuvem. As instâncias do Spark são provisionadas sob demanda com base nas configurações de metadados definidas nos pools do Spark. Cada usuário obtém a própria instância do Spark dedicada para executar seus trabalhos. Os arquivos de dados processados pelas instâncias do Spark são gerenciados pelo cliente nas próprias contas do Armazenamento do Azure.
Pipelines são um agrupamento lógico de atividades que executam a movimentação de dados e transformação de dados em escala. O fluxo de dados é uma atividade de transformação em um pipeline desenvolvido usando uma interface de usuário com pouco código. Ele pode executar transformações de dados em escala. Nos bastidores, os fluxos de dados usam clusters do Apache Spark do Azure Synapse para executar código gerado automaticamente. Pipelines e fluxos de dados são serviços somente de computação e não têm um armazenamento gerenciado associado.
Pipelines usam o IR (Integration Runtime) como a infraestrutura de computação escalonável para executar atividades de expedição e movimentação de dados. As atividades de movimentação de dados são executadas no IR, enquanto as atividades de expedição são executadas em vários outros mecanismos de computação, incluindo o Banco de Dados SQL do Azure, o Azure HDInsight, o Azure Databricks, clusters do Apache Spark do Azure Synapse, entre outros. O Azure Synapse dá suporte a dois tipos de IR: o Azure Integration Runtime e o IR auto-hospedado. O Azure IR fornece uma infraestrutura de computação totalmente gerenciada, escalonável e sob demanda. O IR auto-hospedado é instalado e configurado pelo cliente na rede dele, seja em máquinas locais ou em máquinas virtuais de nuvem do Azure.
Os clientes podem optar por associar seu workspace do Synapse a uma rede virtual de workspace gerenciada. Quando associados a uma rede virtual de workspace gerenciado, Azure IRs e clusters do Apache Spark que são usados por pipelines, fluxos de dados e pools do Apache Spark são implantados dentro da rede virtual do workspace gerenciado. Essa configuração garante o isolamento de rede entre os workspaces para pipelines e cargas de trabalho do Apache Spark.
O diagrama a seguir ilustra os vários componentes do Azure Synapse.
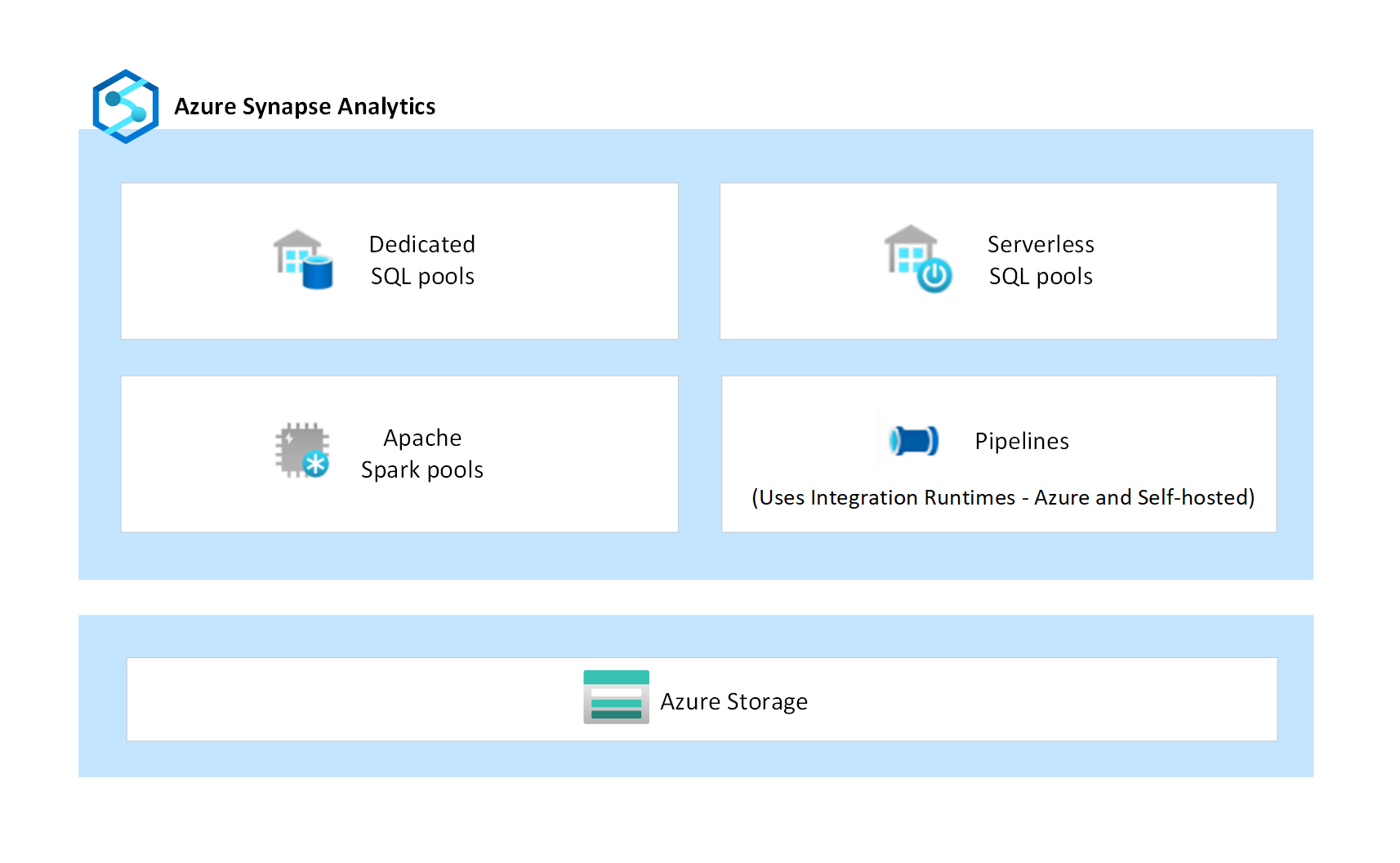
Isolamento de componentes
Cada componente individual do Azure Synapse ilustrado no diagrama fornece os próprios recursos de segurança. Os recursos de segurança fornecem proteção de dados, controle de acesso, autenticação, segurança de rede e proteção contra ameaças para proteger a computação e os dados associados processados. Além disso, o Armazenamento do Azure, sendo um serviço de PaaS, fornece segurança adicional própria, que é configurada e gerenciada pelo cliente nas próprias contas de armazenamento. Esse nível de isolamento de componentes limita e minimiza a exposição caso haja uma vulnerabilidade de segurança em qualquer um dos componentes.
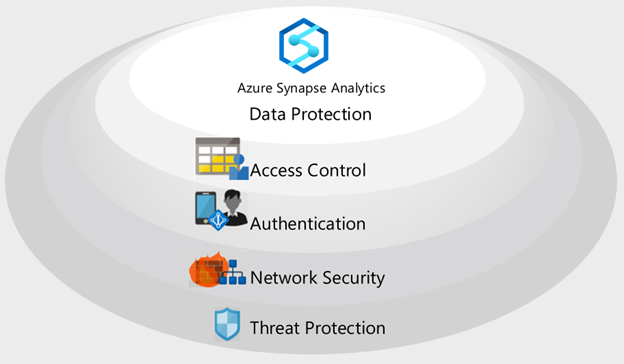
Camadas de segurança
O Azure Synapse implementa uma arquitetura de segurança de várias camadas para proteção de ponta a ponta dos seus dados. Há cinco camadas:
- Proteção de dados para identificar e classificar dados confidenciais e criptografar dados inativos e em movimento.
- Controle de acesso para determinar o direito do usuário de interagir com os dados.
- Autenticação para provar a identidade de usuários e aplicativos.
- Segurança de rede para isolar o tráfego de rede com pontos de extremidade privados e redes virtuais privadas.
- Proteção contra ameaças para identificar possíveis ameaças à segurança, como locais de acesso incomuns, ataques de injeção de SQL, ataques de autenticação e muito mais.
Próximas etapas
No próximo artigo desta série de white papers, saiba mais sobre a proteção de dados.
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de