Além da migração do Netezza, implemente um banco de dados de data warehouse moderno no Microsoft Azure
Este artigo é a sétima parte de uma série de sete partes que oferece diretrizes para fazer a migração do Netezza para o Azure Synapse Analytics. O foco deste artigo são as melhores práticas para implementar banco de dados de data warehouse modernos.
Além da migração do data warehouse para o Azure
Um dos principais motivos para migrar seu data warehouse existente para o Azure Synapse Analytics é utilizar um banco de dados analítico globalmente seguro, escalonável, de baixo custo, nativo de nuvem e pago conforme o uso. Com o Azure Synapse, integre seu data warehouse migrado ao ecossistema analítico completo do Microsoft Azure para aproveitar outras tecnologias da Microsoft e modernizar o data warehouse migrado. Essas tecnologias incluem:
O Azure Data Lake Storage, para ingestão, preparo, limpeza e transformação de dados com boa relação custo-benefício. O Data Lake Storage pode liberar a capacidade do data warehouse ocupada por tabelas de preparo de rápido crescimento.
O Azure Data Factory, para TI colaborativa e integração de dados de autoatendimento com conectores para fontes de dados locais e de nuvem e dados de streaming.
O Common Data Model, para compartilhar dados confiáveis consistentes em várias tecnologias, como as seguintes:
- Azure Synapse
- Azure Synapse Spark
- Azure HDInsight
- Power BI
- Adobe Customer Experience Platform
- IoT do Azure
- Parceiros ISV da Microsoft
As tecnologias de ciência de dados da Microsoft, como as seguintes:
- Azure Machine Learning Studio
- Azure Machine Learning
- Azure Synapse Spark (Spark como serviço)
- Jupyter Notebooks
- RStudio
- ML.NET
- O .NET para Apache Spark, que permite que cientistas de dados usem dados do Azure Synapse para treinar modelos de machine learning em escala.
O Azure HDInsight, para processar grandes quantidades de dados e unir Big Data a dados do Azure Synapse criando um data warehouse lógico usando o PolyBase.
Os Hubs de Eventos do Azure, o Azure Stream Analytics e o Apache Kafka, para fazer a integração a dados de transmissão ao vivo do Azure Synapse.
O crescimento de Big Data levou a uma demanda aguda pelo machine learning para habilitar modelos de machine learning personalizados e treinados para uso no Azure Synapse. Os modelos de machine learning permitem que a análise no banco de dados seja executada em escala, em lotes, de maneira controlada por eventos e sob demanda. A capacidade de aproveitar a análise no banco de dados no Azure Synapse usando várias ferramentas e aplicativos de BI também garante previsões e recomendações consistentes.
Além disso, você pode integrar o Azure Synapse a ferramentas de parceiros da Microsoft no Azure para reduzir o tempo de retorno.
Vamos examinar com mais detalhes como você pode aproveitar as tecnologias do ecossistema analítico da Microsoft para modernizar seu data warehouse após a migração para o Azure Synapse.
Descarregar o preparo de dados e o processamento de ETL no Data Lake Storage e no Azure Data Factory
A transformação digital criou um desafio fundamental para as empresas com a geração de uma torrente de novos dados para captura e análise. Um bom exemplo são os dados de transação criados pela abertura de sistemas de OLTP (processamento transacional online) ao acesso de serviço de dispositivos móveis. Grande parte desses dados chega aos data warehouses, e os sistemas OLTP são a fonte principal. Com clientes impulsionando a taxa de transações em vez de funcionários, o volume de dados nas tabelas de preparo do data warehouse tem crescido rapidamente.
Com o rápido influxo de dados na empresa, juntamente com novas fontes de dados, como a IoT (Internet das Coisas), as empresas precisam encontrar maneiras de ampliar o processamento de ETL de integração de dados. Um método é descarregar a ingestão, a limpeza de dados, a transformação e a integração em um data lake e processar os dados em escala nele, como parte de um programa de modernização de data warehouse.
Após você migrar seu data warehouse para o Azure Synapse, a Microsoft pode modernizar o processamento de ETL ao ingerir e preparar dados no Data Lake Storage. Depois, você poderá limpar, transformar e integrar dados em escala usando o Data Factory e então carregá-los no Azure Synapse em paralelo usando o PolyBase.
Para estratégias de ELT, considere descarregar o processamento de ELT no Data Lake Storage para escalar facilmente à medida que o volume ou a frequência de dados aumenta.
Microsoft Azure Data Factory
O Azure Data Factory é um serviço de integração de dados híbrido, pago conforme o uso, para o processamento altamente escalonável de ETL e ELT. O Data Factory fornece uma interface do usuário baseada na Web para criar pipelines de integração de dados sem código. Com o Data Factory, você pode:
Criar pipelines de integração de dados escalonáveis sem código.
Adquirir dados facilmente em escala.
Pague apenas pelo que usar.
Conectar-se a fontes de dados locais, em nuvem e baseadas em SaaS.
Ingerir, mover, limpar, transformar, integrar e analisar dados locais e em nuvem em escala.
Criar, monitorar e gerenciar pipelines que abrangem armazenamentos de dados locais e na nuvem.
Habilite a expansão do pagamento conforme o uso em alinhamento com o crescimento do cliente.
Você pode usar esses recursos sem escrever nenhum código ou pode adicionar código personalizado aos pipelines do Data Factory. A captura de tela a seguir mostra um exemplo de pipeline do Data Factory.

Dica
O Data Factory permite que você crie pipelines de integração de dados escalonáveis sem código.
Implemente o desenvolvimento de pipeline do Data Factory de diferentes locais, como os seguintes:
Portal do Microsoft Azure.
Microsoft Azure PowerShell.
Programaticamente com o .NET e o Python usando um SDK de várias linguagens.
Modelos do Azure Resource Manager (ARM).
APIs REST.
Dica
O Data Factory pode se conectar a dados locais, em nuvem e de SaaS.
Os desenvolvedores e cientistas de dados que preferem escrever código podem criar pipelines do Data Factory facilmente com Java, Python e .NET usando os SDKs (kits de desenvolvimento de software) disponíveis para essas linguagens de programação. Os pipelines do Data Factory podem ser pipelines de dados híbridos, pois podem se conectar, ingerir, limpar, transformar e analisar dados em data centers locais, no Microsoft Azure, em outras nuvens e em ofertas SaaS.
Depois de desenvolver pipelines do Data Factory para integrar e analisar dados, implante esses pipelines globalmente e agende-os para serem executados em lotes, invoque-os sob demanda como um serviço ou execute-os em tempo real de maneira controlada por eventos. Um pipeline do Data Factory também pode ser executado em um ou mais mecanismos de execução e monitorar a execução para garantir o desempenho e rastrear erros.
Dica
No Azure Data Factory, os pipelines controlam a integração e a análise de dados. O Data Factory é um software de integração de dados de nível empresarial voltado para profissionais de TI e tem capacidade de estruturação de dados para usuários empresariais.
Casos de uso
O Data Factory dá suporte a vários casos de uso, como:
Preparar, integrar e enriquecer dados de fontes de dados locais e de nuvem para popular o data warehouse e os data marts migrados no Microsoft Azure Synapse.
Preparar, integrar e enriquecer dados de fontes de dados locais e de nuvem para produzir dados de treinamento a serem usados no desenvolvimento de modelos de machine learning e no retreinamento de modelos analíticos.
Orquestrar a preparação e a análise de dados para criar pipelines analíticos preditivos e prescritivos visando processar e analisar dados em lote, como na análise de sentimento. Agir com base nos resultados da análise ou popular o data warehouse com os resultados.
Preparar, integrar e enriquecer dados para aplicativos de negócios controlados por dados em execução na nuvem do Azure além de armazenamentos de dados operacionais como o Azure Cosmos DB.
Dica
Crie conjuntos de dados de treinamento em ciência de dados para desenvolver modelos de machine learning.
Fontes de dados
O Data Factory permite usar conectores de fontes de dados locais e de nuvem. O software de agente, conhecido como runtime de integração auto-hospedada, acessa com segurança fontes de dados locais e dá suporte à transferência de dados segura e escalonável.
Transformar dados usando o Azure Data Factory
Dentro de um pipeline do Data Factory, é possível ingerir, limpar, transformar, integrar e analisar todos os tipos de dados dessas fontes. Os dados podem ser estruturados, semiestruturados como JSON ou Avro ou não estruturados.
Sem escrever nenhum código, desenvolvedores profissionais de ETL podem usar os fluxos de dados de mapeamento do Data Factory para filtrar, dividir, ingressar vários tipos, pesquisar, dinamizar, transformar colunas em linhas, classificar, unir e agregar dados. Além disso, o Data Factory dá suporte a chaves alternativas, várias opções de processamento de gravação, como inserção, execução de upsert, atualização, recriação de tabela e truncamento de tabela, além de vários tipos de armazenamentos de dados de destino, também conhecidos como coletores. Os desenvolvedores de ETL também podem criar agregações, incluindo agregações de série temporal que exigem que uma janela seja colocada em colunas de dados.
Dica
Desenvolvedores profissionais de ETL podem usar os fluxos de dados de mapeamento do Data Factory para limpar, transformar e integrar dados sem precisar escrever código.
Você pode executar fluxos de dados de mapeamento que transformam dados como atividades em um pipeline do Data Factory e, se necessário, incluir vários fluxos de dados de mapeamento em um pipeline. Dessa forma, você pode gerenciar a complexidade dividindo tarefas desafiadoras de transformação e integração de dados em fluxos de dados de mapeamento menores que podem ser combinados. E, quando necessário, você pode adicionar código personalizado. Além dessa funcionalidade, os fluxos de dados de mapeamento do Data Factory incluem a habilidade de:
Definir expressões para limpar e transformar dados, computar agregações e enriquecer dados. Por exemplo, essas expressões podem executar a engenharia de recursos em um campo de data para dividi-lo em vários campos a fim de criar dados de treinamento durante o desenvolvimento do modelo de machine learning. Você pode construir expressões usando um conjunto avançado de funções que incluem operações matemáticas e temporais, divisão, mesclagem, concatenação de cadeias de caracteres, condições, correspondência de padrões, substituição e várias outras.
Processar automaticamente o descompasso de esquema para evitar que os pipelines de transformação de dados sejam afetados por alterações de esquema nas fontes de dados. Essa habilidade é importante principalmente para transmitir dados de IoT, em que alterações de esquema poderão ocorrer sem aviso prévio se os dispositivos forem atualizados ou quando ocorrer perda de leituras dos dispositivos de gateway que coletam dados de IoT.
Particionar dados para permitir que as transformações sejam executadas em paralelo em escala.
Inspecione os dados de streaming para exibir os metadados de um fluxo que você está transformando.
Dica
O Data Factory dá suporte à capacidade de detectar e gerenciar automaticamente as alterações de esquema em dados de entrada, como nos dados de streaming.
A captura de tela a seguir mostra um exemplo de fluxo de dados de mapeamento do Data Factory.

Engenheiros de dados podem analisar a qualidade dos dados e exibir os resultados de transformações de dados individuais habilitando uma funcionalidade de depuração durante o desenvolvimento.
Dica
O Data Factory também pode particionar dados para permitir que o processamento de ETL seja executado em escala.
Se necessário, estenda a funcionalidade de transformação e análise do Data Factory adicionando um serviço vinculado que contém seu código a um pipeline. Por exemplo, um notebook do Pool do Spark do Azure Synapse pode conter código Python que usa um modelo treinado para pontuar os dados integrados por um fluxo de dados de mapeamento.
Você pode armazenar dados integrados e os resultados da análise em um pipeline do Data Factory em um ou mais armazenamentos de dados, como o Data Lake Storage, o Azure Synapse ou tabelas do Hive no HDInsight. Você também pode invocar outras atividades para agir com base nos insights produzidos por um pipeline analítico do Data Factory.
Dica
Os pipelines do Data Factory são extensíveis porque o Data Factory permite que você escreva seu código e o execute dentro de um pipeline.
Utilizar o Spark para dimensionar a integração de dados
Em tempo de execução, o Data Factory usa internamente os Pools do Spark do Azure Synapse, a oferta de Spark como serviço da Microsoft, para limpar e integrar dados na nuvem do Azure. Você pode limpar, integrar e analisar dados de alto volume e em alta velocidade, como dados de sequência de cliques, em escala. A intenção da Microsoft é também executar pipelines do Data Factory em outras distribuições do Spark. Além de executar trabalhos de ETL no Spark, o Data Factory pode invocar scripts do Pig e consultas do Hive para acessar e transformar dados armazenados no HDInsight.
Vincular a preparação de dados de autoatendimento e o processamento de ETL do Data Factory usando fluxos de dados de estruturação
A estruturação de dados permite que usuários empresariais, também conhecidos como integradores de dados cidadãos e engenheiros de dados, usem a plataforma para descobrir, explorar e preparar dados visualmente em escala sem escrever código. Essa funcionalidade do Data Factory é fácil de usar e é semelhante aos fluxos de dados do Microsoft Excel Power Query ou do Microsoft Power BI, em que usuários empresariais que trabalham com autoatendimento usam uma interface do usuário com estilo de planilha com transformações suspensas para preparar e integrar dados. A captura de tela a seguir mostra um exemplo de fluxo de dados de estruturação do Data Factory.

Diferente do Excel e do Power BI, os fluxos de dados de estruturação do Data Factory usam o Power Query para gerar um código M e convertê-lo em um trabalho do Spark na memória altamente paralelo para execução na escala da nuvem. A combinação de fluxos de dados de mapeamento e fluxos de dados de estruturação no Data Factory permite que desenvolvedores profissionais de ETL e usuários empresariais colaborem para preparar, integrar e analisar dados com uma finalidade comercial comum. O diagrama de fluxos de dados de mapeamento do Data Factory anterior mostra como os notebooks do Pool do Spark no Azure Synapse e o Data Factory podem ser combinados no mesmo pipeline do Data Factory. A combinação de fluxos de dados de mapeamento e de estruturação no Data Factory ajuda usuários de TI e empresariais a ficarem cientes de quais fluxos de dados cada um criou e dá suporte à reutilização de fluxos de dados para minimizar a reinvenção e maximizar a produtividade e a consistência.
Dica
O Data Factory dá suporte a fluxos de dados de estruturação e fluxos de dados de mapeamento para que usuários empresariais e de TI possam integrar dados de maneira colaborativa em uma plataforma comum.
Vincular dados e análise em pipelines analíticos
Além de limpar e transformar dados, o Data Factory pode combinar a integração de dados e a análise no mesmo pipeline. Use o Data Factory para criar pipelines de integração de dados e analíticos, sendo os pipelines analíticos uma extensão dos de integração. Você pode incluir um modelo analítico em um pipeline para criar um pipeline analítico que gera dados limpos e integrados para previsões ou recomendações. Em seguida, você pode agir com base nas previsões ou recomendações imediatamente ou pode armazená-las em seu data warehouse para fornecer novos insights e recomendações que podem ser exibidos em ferramentas de BI.
Para pontuar os dados em lote, você pode desenvolver um modelo analítico invocado como um serviço dentro de um pipeline do Data Factory. Você pode desenvolver modelos analíticos sem código com o Estúdio do Azure Machine Learning ou com o SDK do Azure Machine Learning usando os notebooks do Pool do Spark no Azure Synapse ou R no RStudio. Ao executar pipelines de machine learning do Spark nos notebooks do Pool do Spark no Azure Synapse, a análise ocorre em escala.
Você pode armazenar dados integrados e os resultados do pipeline analítico do Data Factory em um ou mais armazenamentos de dados, como o Data Lake Storage, o Azure Synapse ou as tabelas do Hive no HDInsight. Você também pode invocar outras atividades para agir com base nos insights produzidos por um pipeline analítico do Data Factory.
Usar um banco de dados do Lake para compartilhar dados confiáveis consistentes
Um dos principais objetivos de qualquer configuração de integração de dados é a capacidade de integrar dados uma vez e reutilizá-los em qualquer lugar, não apenas em um data warehouse. Por exemplo, talvez você queira usar dados integrados para ciência de dados. A reutilização evita a reinvenção e garante dados consistentes, compreendidos igualmente por todos e confiáveis em toda a empresa.
O Common Data Model descreve entidades de dados principais que podem ser compartilhadas e reutilizadas na empresa. Para possibilitar a reutilização, o Common Data Model estabelece um conjunto de nomes e definições de dados comuns que descrevem entidades de dados lógicas. Exemplos de nomes de dados comuns incluem Cliente, Conta, Produto, Fornecedor, Pedidos, Pagamentos e Devoluções. Profissionais de TI e de negócios podem usar software de integração de dados para criar e armazenar ativos de dados comuns e maximizar a reutilização e promover a consistência em qualquer lugar.
O Azure Synapse fornece modelos de banco de dados específicos do setor para ajudar a padronizar os dados no Lake. Os modelos de base de dados do Lake oferecem esquemas para áreas de negócios predefinidas, permitindo que os dados sejam carregados em um banco de dados do Lake de maneira estruturada. O poder vem do uso do software de integração de dados para criar ativos de dados comuns do banco de dados do Lake, resultando em dados confiáveis e autodescritivos que podem ser consumidos por aplicativos e sistemas analíticos. Você pode criar ativos de dados comuns no Data Lake Storage usando o Data Factory.
Dica
O Data Lake Storage é um armazenamento compartilhado subjacente ao Microsoft Azure Synapse, ao Azure Machine Learning, ao Azure Synapse Spark e ao HDInsight.
O Power BI, o Azure Synapse Spark, o Azure Synapse e o Azure Machine Learning podem consumir ativos de dados comuns. O diagrama a seguir mostra como um banco de dados do Lake pode ser usado no Azure Synapse.
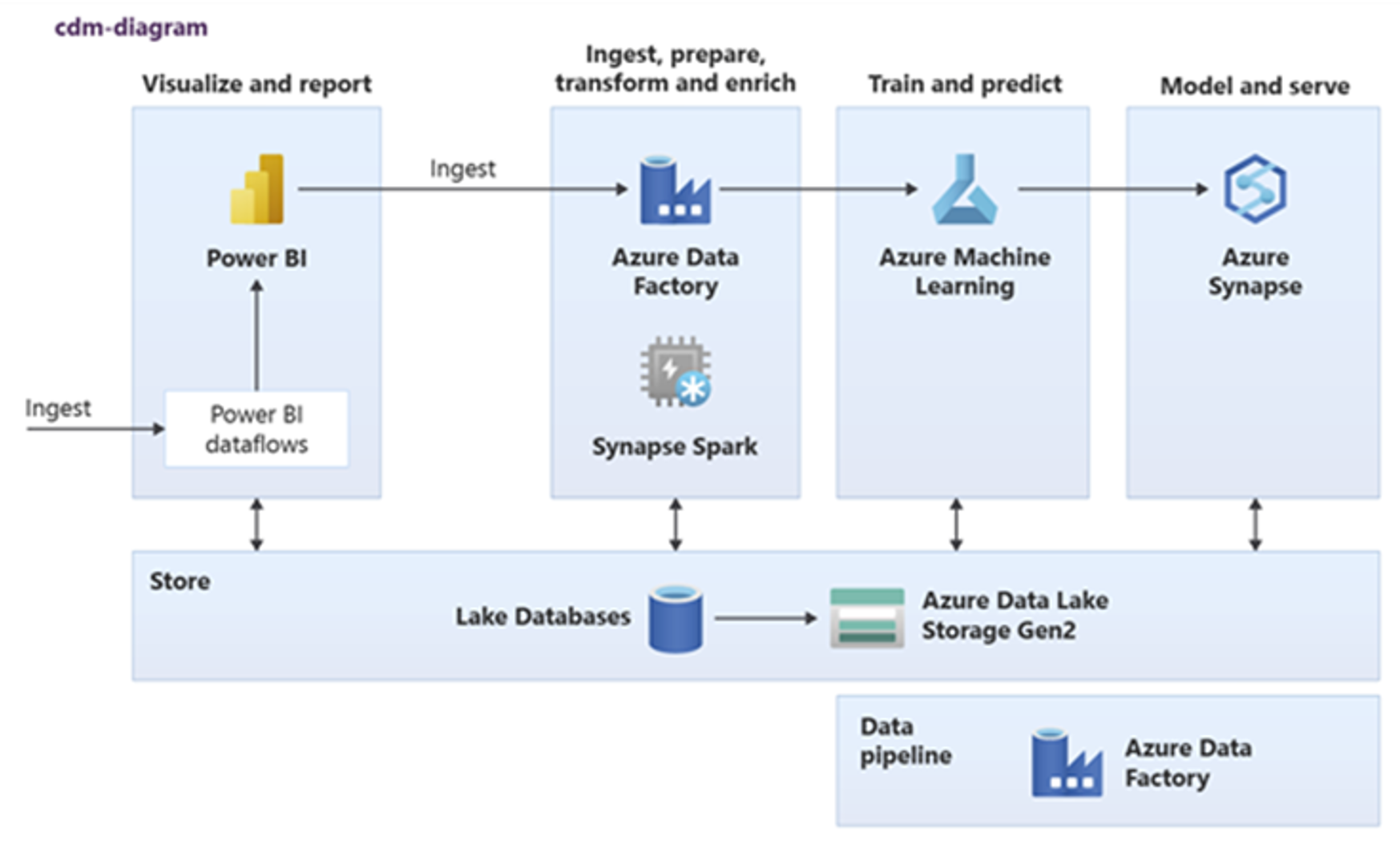
Dica
Integre dados para criar entidades lógicas do banco de dados do Lake no armazenamento compartilhado e maximizar a reutilização de ativos de dados comuns.
Integração com tecnologias de ciência de dados da Microsoft no Azure
Outro objetivo fundamental ao modernizar um data warehouse é produzir insights para obter vantagem competitiva. Você pode produzir insights integrando seu data warehouse migrado com tecnologias de ciência de dados da Microsoft e de terceiros no Azure. As seções a seguir descrevem as tecnologias de machine learning e ciência de dados oferecidas pela Microsoft para demostrar como elas podem ser usadas com o Azure Synapse em um ambiente de data warehouse moderno.
Tecnologias da Microsoft para ciência de dados no Azure
A Microsoft oferece uma variedade de tecnologias que dão suporte à análise avançada. Com essas tecnologias, você pode criar modelos analíticos preditivos usando machine learning ou analisar dados não estruturados usando aprendizado profundo. As tecnologias incluem:
Azure Machine Learning Studio
Azure Machine Learning
Notebooks do Pool do Spark no Azure Synapse
ML.NET (API, CLI ou ML.NET Model Builder para Visual Studio)
.NET para Apache Spark
Cientistas de dados podem usar o RStudio (R) e o Jupyter Notebooks (Python) para desenvolver modelos analíticos ou podem usar estruturas como Keras ou TensorFlow.
Dica
Desenvolva modelos de machine learning usando uma abordagem com pouco ou nenhum código ou usando linguagens de programação como Python, R e .NET.
Azure Machine Learning Studio
O Estúdio do Azure Machine Learning é um serviço de nuvem totalmente gerenciado que permite criar, implantar e compartilhar análises preditivas usando uma interface do usuário baseada na Web do tipo “arrastar e soltar”. A captura de tela a seguir mostra a interface do usuário do Estúdio do Azure Machine Learning.

Azure Machine Learning
O Azure Machine Learning fornece um SDK e serviços para Python com suporte que podem ajudar você a preparar dados rapidamente e também a treinar e implantar modelos de machine learning. Você pode usar o Azure Machine Learning em notebooks do Azure usando o Jupyter Notebook, com estruturas de código aberto, como PyTorch, TensorFlow, scikit-learn ou Spark MLlib – a biblioteca de machine learning do Spark. O Azure Machine Learning oferece uma funcionalidade de AutoML que testa automaticamente vários algoritmos para identificar os mais precisos para agilizar o desenvolvimento do modelo.
Dica
O Azure Machine Learning oferece um SDK para desenvolver modelos de machine learning usando várias estruturas de software livre.
Você também pode usar o Azure Machine Learning para criar pipelines de machine learning que gerenciam o fluxo de trabalho de ponta a ponta, são dimensionados programaticamente na nuvem e implantam modelos na nuvem e na borda. O Azure Machine Learning contém workspaces, que são espaços lógicos que você pode criar programática ou manualmente no portal do Azure. Esses workspaces contêm destinos de computação, testes, armazenamentos de dados, modelos de machine learning treinados, imagens do Docker e serviços implantados em um só lugar para permitir que as equipes trabalhem juntas. Você pode usar o Azure Machine Learning no Visual Studio com a extensão do Visual Studio para IA.
Dica
Organize e gerencie armazenamentos de dados, testes, modelos treinados, imagens do Docker e serviços implantados relacionados em workspaces.
Notebooks do Pool do Spark no Azure Synapse
Um notebook do Pool do Spark no Azure Synapse é um serviço do Apache Spark otimizado para o Azure. Com notebooks do Pool do Spark no Azure Synapse:
Engenheiros de dados podem criar e executar trabalhos de preparação de dados escalonáveis usando o Data Factory.
Cientistas de dados podem criar e executar modelos de machine learning em escala usando notebooks escritos em linguagens como Scala, R, Python, Java e SQL para visualizar os resultados.
Dica
O Azure Synapse Spark é uma oferta dinamicamente escalonável de Spark como serviço da Microsoft. O Spark oferece a execução escalonável da preparação de dados, o desenvolvimento de modelos e a execução do modelo implantado.
Trabalhos em execução em notebooks do Pool do Spark no Azure Synapse podem recuperar, processar e analisar dados em escala do Armazenamento de Blobs do Azure, do Data Lake Storage, do Azure Synapse, do HDInsight e de serviços de dados de streaming como o Apache Kafka.
Dica
O Azure Synapse Spark pode acessar dados em uma variedade de armazenamentos de dados do ecossistema analítico da Microsoft no Azure.
Os notebooks do Pool do Spark no Azure Synapse dão suporte ao dimensionamento automático e ao encerramento automático para reduzir o TCO (custo total de propriedade). Os cientistas de dados podem usar a estrutura de software livre do MLflow para gerenciar o ciclo de vida de machine learning.
ML.NET
O ML.NET é uma estrutura de machine learning multiplataforma de código aberto para Windows, Linux e macOS. A Microsoft criou o ML.NET para que desenvolvedores de .NET possam usar ferramentas existentes, como ML.NET Model Builder para Visual Studio, para desenvolver modelos de machine learning personalizados e integrá-los a aplicativos .NET.
Dica
A Microsoft estendeu a funcionalidade de machine learning para desenvolvedores do .NET.
.NET para Apache Spark
O .NET para Apache Spark estende o suporte para Spark além de R, Scala, Python e Java para .NET e tem como objetivo tornar o Spark acessível para desenvolvedores de .NET em todas as APIs do Spark. Embora o .NET para Apache Spark esteja disponível apenas no Apache Spark no HDInsight, a Microsoft pretende disponibilizá-lo em notebooks do Pool do Spark no Azure Synapse.
Usar o Azure Synapse Analytics com seu data warehouse
Para combinar modelos de machine learning com o Azure Synapse, você pode:
Usar modelos de machine learning em lote ou em tempo real em dados de streaming para gerar novos insights e adicionar esses insights ao que você já conhece no Azure Synapse.
Usar os dados no Azure Synapse para desenvolver e treinar novos modelos preditivos para implantação em outros lugares, como em outros aplicativos.
Implantar modelos de machine learning, incluindo modelos treinados em outros lugares, no Azure Synapse para analisar dados eu seu data warehouse e gerar valor comercial.
Dica
Treine, teste, avalie e execute modelos de machine learning em escala nos notebooks do Pool do Spark no Azure Synapse usando dados no Azure Synapse.
Cientistas de dados podem usar o RStudio, Jupyter Notebooks e notebooks do Pool do Spark no Azure Synapse juntamente com o Azure Machine Learning para desenvolver modelos de machine learning executados em escala nos notebooks do Pool do Spark no Azure Synapse usando dados do Azure Synapse. Por exemplo, os cientistas de dados podem criar um modelo não supervisionado para segmentar os clientes e gerar diferentes campanhas de marketing. Use machine learning supervisionado para treinar um modelo para prever um resultado específico, como prever a propensão de um cliente à rotatividade ou recomendar a próxima melhor oferta a um cliente para tentar aumentar o valor que ele representa. O diagrama a seguir mostra como o Azure Synapse pode ser usado pelo Azure Machine Learning.
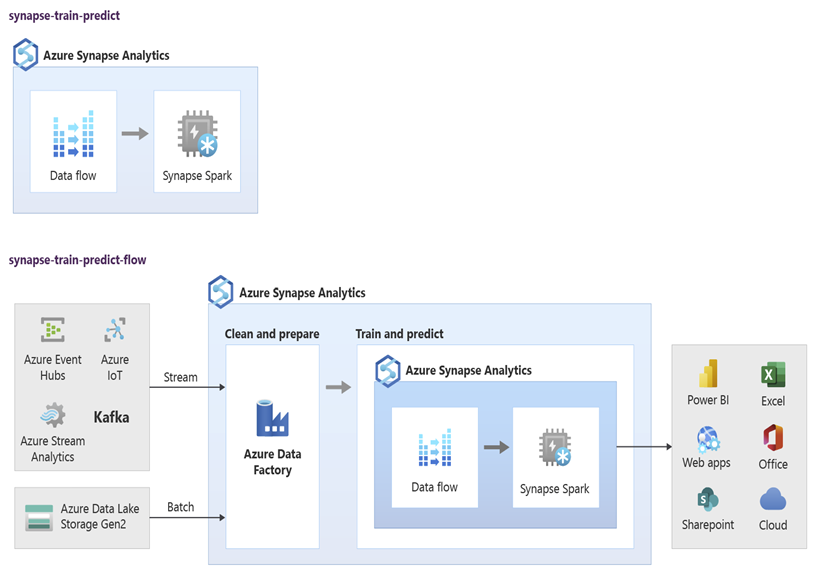
Em outro cenário, você pode ingerir dados de redes sociais ou sites de resenhas no Data Lake Storage e prepará-los e analisá-los em escala em um notebook do Pool do Spark no Azure Synapse usando processamento de linguagem natural para pontuar o sentimento do cliente sobre seus produtos ou marca. Em seguida, você pode adicionar essas pontuações ao data warehouse. Usando análise de Big Data para entender o efeito do sentimento negativo sobre vendas de produtos, você acrescenta ao que já sabe no data warehouse.
Dica
Produza novos insights usando machine learning no Azure em lote ou em tempo real e acrescente-os às informações que você já tem no seu data warehouse.
Integrar dados de transmissão ao vivo ao Azure Synapse Analytics
Ao analisar dados em um data warehouse moderno, você precisa da capacidade de analisar dados de streaming em tempo real e juntá-los aos dados históricos do seu data warehouse. Um exemplo é combinar dados de IoT e dados de produtos ou de ativos.
Dica
Integre seu data warehouse a dados de streaming de dispositivos IoT ou de sequências de cliques.
Depois de migrar com êxito seu data warehouse para o Azure Synapse, você pode introduzir a integração de dados de transmissão ao vivo como parte de um exercício de modernização do data warehouse aproveitando a funcionalidade extra no Azure Synapse. Para fazer isso, faça a ingestão de dados de streaming por meio dos Hubs de Eventos, de outras tecnologias como o Apache Kafka ou, potencialmente, de sua ferramenta de ETL existente se ela der suporte a fontes de dados de streaming. Armazene os dados no Data Lake Storage. Em seguida, crie uma tabela externa no Azure Synapse usando o PolyBase e aponte-a para os dados que estão sendo transmitidos para o Data Lake Storage para que seu warehouse contenha novas tabelas que fornecem acesso aos dados de streaming em tempo real. Consulte a tabela externa como se os dados estivessem no data warehouse usando T-SQL padrão de qualquer ferramenta de BI que tenha acesso ao Azure Synapse. Você também pode unir os dados de streaming a outras tabelas com dados históricos para criar exibições que unem dados de transmissão ao vivo a dados históricos para facilitar o acesso de usuários empresariais aos dados.
Dica
Faça a ingestão de dados de streaming no Data Lake Storage por meio dos Hubs de Eventos ou do Apache Kafka e acesse-os pelo Azure Synapse usando tabelas externas do PolyBase.
No diagrama a seguir, um data warehouse em tempo real no Azure Synapse é integrado aos dados de streaming no Data Lake Storage.
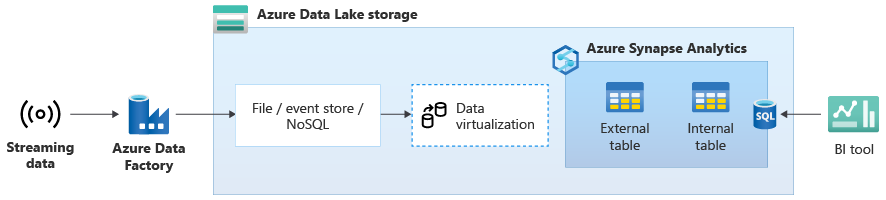
Criar um data warehouse lógico usando o PolyBase
Com o PolyBase, você pode criar um data warehouse lógico para simplificar o acesso do usuário a vários armazenamentos de dados analíticos. Nos últimos anos, muitas empresas adotaram armazenamentos de dados analíticos “otimizados para carga de trabalho” além do data warehouse. As plataformas analíticas no Azure incluem:
O Data Lake Storage com o notebook do Pool do Spark no Azure Synapse (Spark como serviço), para análise de Big Data.
O HDInsight (Hadoop como serviço), também para análise de Big Data.
Bancos de dados de grafo NoSQL para análise de grafo, que poderia ser feita no Azure Cosmos DB.
Os Hubs de Eventos e o Stream Analytics, para análise em tempo real de dados em trânsito.
Talvez você tenha equivalentes que não são da Microsoft dessas plataformas ou um sistema de MDM (Gerenciamento de Dados Mestre) que precise acessar para obter dados confiáveis e consistentes sobre clientes, fornecedores, produtos e ativos, entre outros.
Dica
O PolyBase simplifica o acesso a vários armazenamentos de dados analíticos subjacentes no Azure para facilitar o acesso de usuários empresariais.
Essas plataformas analíticas surgiram devido à explosão de novas fontes de dados dentro e fora da empresa e à demanda de usuários empresariais por capturar e analisar os novos dados. As novas fontes de dados incluem:
Dados gerados pelo computador, como dados do sensor IoT e dados de sequência de cliques.
Dados gerados por pessoas, como dados de redes sociais e dados de análise de site e email, imagem e vídeo recebidos pelo cliente.
Outros dados externos, como dados abertos do governo e dados meteorológicos.
Esses novos dados vão além dos dados de transações estruturados e das principais fontes de dados que normalmente alimentam data warehouses e geralmente incluem:
- Dados semiestruturados, como JSON, XML ou Avro.
- Dados não estruturados, como texto, voz, imagem ou vídeo, que são mais complexos de processar e analisar.
- Dados de alto volume, dados de alta velocidade ou ambos.
Como resultado, surgiram novos tipos de análise mais complexos, como processamento de linguagem natural, análise de grafo, aprendizado profundo, análise de streaming ou análise complexa de grandes volumes de dados estruturados. Esses tipos de análise geralmente não acontecem em um data warehouse, portanto não é surpreendente encontrar diferentes plataformas analíticas para diferentes tipos de cargas de trabalho analíticas, como é mostrado diagrama a seguir.
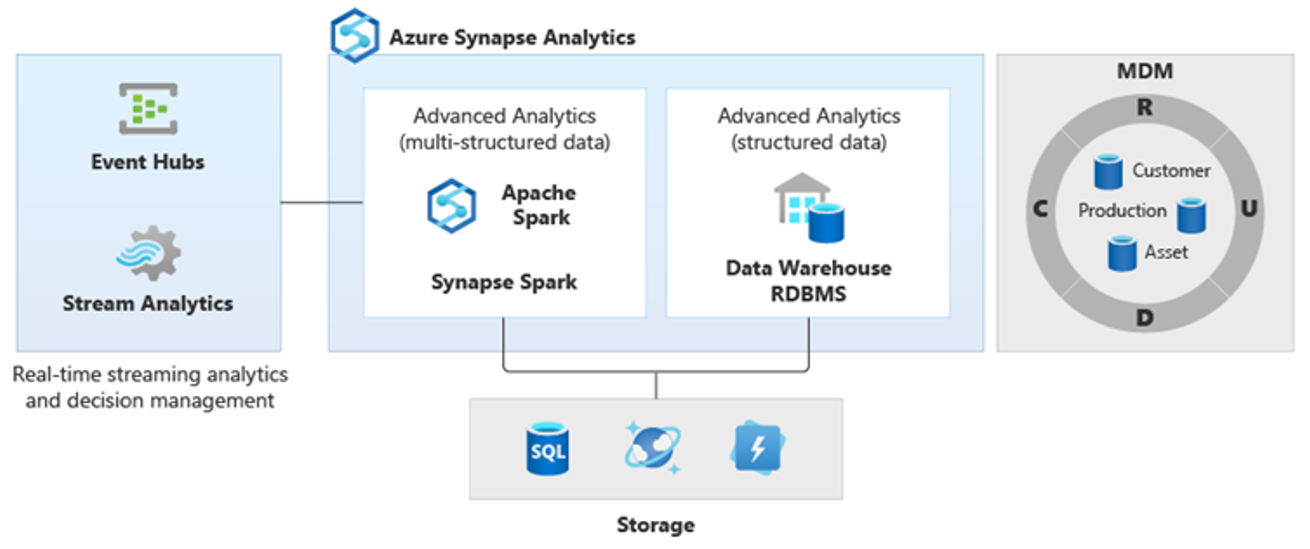
Dica
The ability to make data in multiple analytical data stores look like it's all in one system and join it to Azure Synapse is known as a logical data warehouse architecture.
Como essas plataformas produzem novos insights, é normal ver um requisito para combinar os novos insights com o que você já conhece no Azure Synapse, que é o que o PolyBase possibilita.
Usando a virtualização de dados do PolyBase dentro do Azure Synapse, você pode implementar um data warehouse lógico onde os dados no Azure Synapse são unidos a dados em outros armazenamentos de dados analíticos locais e do Azure, como o HDInsight, o Azure Cosmos DB ou dados de streaming que fluem para o Data Lake Storage do Stream Analytics ou dos Hubs de Eventos. Essa abordagem reduz a complexidade para os usuários, que acessam tabelas externas no Azure Synapse e não precisam saber que os dados que estão acessando estão armazenados em vários sistemas analíticos subjacentes. O diagrama a seguir mostra a estrutura complexa de data warehouse acessada por meio de métodos de interface do usuário relativamente mais simples, mas ainda assim eficientes.
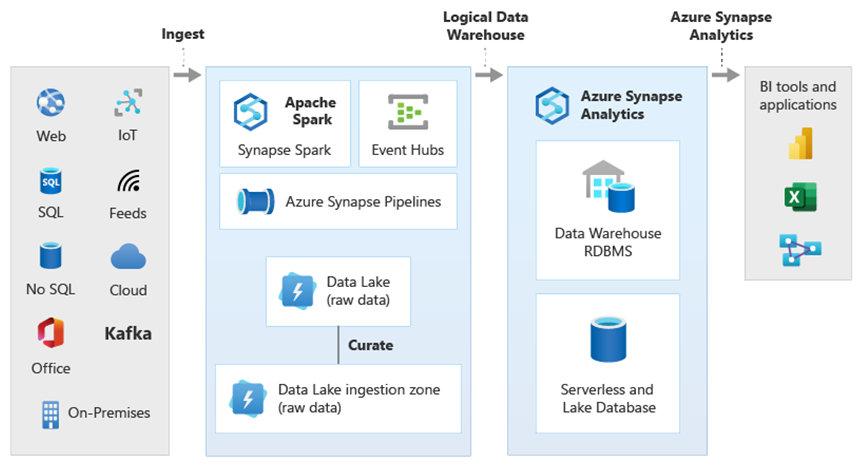
O diagrama mostra como outras tecnologias no ecossistema analítico da Microsoft podem ser combinadas com a funcionalidade da arquitetura lógica de data warehouse do Azure Synapse. Por exemplo, você pode ingerir dados no Data Lake Storage e coletar os dados usando o Data Factory para criar produtos de dados confiáveis que representem entidades de dados lógicas do banco de dados do Lake da Microsoft. Esses dados confiáveis, compreendidos igualmente por todos, podem ser consumidos e reutilizados em diferentes ambientes analíticos, como o Azure Synapse, os notebooks do Pool do Spark no Azure Synapse ou o Azure Cosmos DB. Todos os insights produzidos nesses ambientes são acessíveis por meio de uma camada lógica de virtualização de dados do data warehouse proporcionada pelo PolyBase.
Dica
Uma arquitetura lógica de data warehouse simplifica o acesso do usuário empresarial aos dados e agrega mais valor às informações que você já tem no seu data warehouse.
Conclusões
Depois de migrar seu data warehouse para o Azure Synapse, você poderá aproveitar outras tecnologias no ecossistema analítico da Microsoft. Ao fazer isso, você não apenas moderniza seu data warehouse, mas traz insights produzidos em outros armazenamentos de dados analíticos do Azure para uma arquitetura analítica integrada.
Você pode ampliar o processamento de ETL para ingerir dados de qualquer tipo no Data Lake Storage e, em seguida, preparar e integrar os dados em escala usando o Data Factory para produzir ativos de dados confiáveis e comumente compreendidos. Esses ativos podem ser consumidos pelo seu data warehouse e acessados por cientistas de dados e outros aplicativos. É possível criar pipelines analíticos em tempo real e orientados por lotes e criar modelos de machine learning a serem executados em lotes, em tempo real, nos dados de streaming e sob demanda como serviço.
Você pode usar o PolyBase ou COPY INTO para ir além do data warehouse para simplificar o acesso a insights de várias plataformas analíticas subjacentes no Azure. Para fazer isso, crie exibições holísticas e integradas em um data warehouse lógico que dê suporte ao acesso a streaming, Big Data e insights do data warehouse tradicionais de aplicativos e ferramentas de BI.
Ao migrar seu data warehouse para o Azure Synapse, você pode aproveitar o rico ecossistema analítico da Microsoft em execução no Azure para gerar novo valor em sua empresa.
Próximas etapas
Para saber mais sobre a migração para um pool de SQL dedicado, consulte Migrar um data warehouse para um pool de SQL dedicado no Azure Synapse Analytics.