Monitorar aplicativos Apache Spark com o Azure Log Analytics
Neste tutorial, você vai aprender a habilitar o conector do Synapse Studio que está dentro do Log Analytics. Em seguida, será possível coletar métricas e logs do aplicativo Apache Spark, depois enviá-los para o workspace do Log Analytics. Por fim, será possível usar uma pasta de trabalho do Azure Monitor para visualizar as métricas e os logs.
Observação
No momento, esse recurso não está disponível no Azure Synapse para Apache Spark 3.4, mas terá suporte após disponibilidade geral.
Configurar informações do workspace
Siga as etapas abaixo para configurar as informações necessárias no Synapse Studio.
Etapa 1: criar um workspace do Log Analytics
Confira um dos seguintes recursos para criar esse workspace:
- Criar um workspace no portal do Azure.
- Criar um workspace com a CLI do Azure.
- Criar e configurar um workspace no Azure Monitor usando o PowerShell.
Etapa 2: preparar um arquivo de configuração do Apache Spark
Use uma das opções abaixo para preparar o arquivo.
Opção 1: configurar usando a ID e a chave do workspace do Log Analytics
Copie as configurações abaixo do Apache Spark, salve-as como spark_loganalytics_conf.txt e preencha o seguintes parâmetros:
<LOG_ANALYTICS_WORKSPACE_ID>: ID do workspace do Log Analytics.<LOG_ANALYTICS_WORKSPACE_KEY>: chave do Log Analytics. Para localizá-los, abra o portal do Azure e acesse Workspace do Azure Log Analytics>Agentes>Chave primária.
spark.synapse.logAnalytics.enabled true
spark.synapse.logAnalytics.workspaceId <LOG_ANALYTICS_WORKSPACE_ID>
spark.synapse.logAnalytics.secret <LOG_ANALYTICS_WORKSPACE_KEY>
Opção 2: configurar usando o Azure Key Vault
Observação
Você precisa conceder permissão de leitura de segredo para os usuários que enviarão aplicativos Apache Spark. Para obter mais informações, confira como Fornecer acesso a chaves, certificados e segredos do Key Vault usando um controle de acesso baseado em função do Azure. Ao habilitar esse recurso em um pipeline do Synapse, você precisa usar a Opção 3. Isso é necessário para obter o segredo do Azure Key Vault com a identidade gerenciada do workspace.
Execute as seguintes etapas para configurar o Azure Key Vault a fim de armazenar a chave do workspace:
Crie e acesse o seu cofre de chaves no portal do Azure.
Na página de configurações do cofre de chaves, selecione Segredos.
Selecione Gerar/Importar.
Na tela Criar um segredo, selecione os seguintes valores:
- Nome: insira um nome para o segredo. Insira
SparkLogAnalyticsSecretcomo o nome padrão. - Valor: insira
<LOG_ANALYTICS_WORKSPACE_KEY>para o segredo. - Deixe os outros valores com seus padrões. Em seguida, selecione Criar.
- Nome: insira um nome para o segredo. Insira
Copie as configurações abaixo do Apache Spark, salve-as como spark_loganalytics_conf.txt e preencha o seguintes parâmetros:
<LOG_ANALYTICS_WORKSPACE_ID>: a ID do workspace do Log Analytics.<AZURE_KEY_VAULT_NAME>: o nome do cofre de chaves configurado.<AZURE_KEY_VAULT_SECRET_KEY_NAME>(opcional): o nome secreto da chave do workspace no cofre de chaves. O padrão éSparkLogAnalyticsSecret.
spark.synapse.logAnalytics.enabled true
spark.synapse.logAnalytics.workspaceId <LOG_ANALYTICS_WORKSPACE_ID>
spark.synapse.logAnalytics.keyVault.name <AZURE_KEY_VAULT_NAME>
spark.synapse.logAnalytics.keyVault.key.secret <AZURE_KEY_VAULT_SECRET_KEY_NAME>
Observação
Também é possível armazenar a ID do workspace no Key Vault. Confira as etapas anteriores e armazene a ID do workspace com o nome secreto SparkLogAnalyticsWorkspaceId. Como alternativa, é possível usar a configuração spark.synapse.logAnalytics.keyVault.key.workspaceId para especificar o nome secreto da ID do workspace no Key Vault.
Opção 3. Configurar usando um serviço vinculado
Observação
Nesta opção, você precisa conceder permissão de leitura de segredo à identidade gerenciada do workspace. Para obter mais informações, confira como Fornecer acesso a chaves, certificados e segredos do Key Vault usando um controle de acesso baseado em função do Azure.
Execute as seguintes etapas para configurar um serviço vinculado ao Key Vault no Synapse Studio a fim de armazenar a chave do workspace:
Siga todas as etapas da "Opção 2" mostrada na seção anterior.
Crie um serviço vinculado ao Key Vault no Synapse Studio:
a. Acesse Synapse Studio>Gerenciar>Serviços vinculados, depois clique em Novo.
b. Na caixa de pesquisa, digite Azure Key Vault.
c. Insira um nome para o serviço vinculado.
d. Selecione o cofre de chaves, depois clique em Criar.
Adicione o item
spark.synapse.logAnalytics.keyVault.linkedServiceNameà configuração do Apache Spark.
spark.synapse.logAnalytics.enabled true
spark.synapse.logAnalytics.workspaceId <LOG_ANALYTICS_WORKSPACE_ID>
spark.synapse.logAnalytics.keyVault.name <AZURE_KEY_VAULT_NAME>
spark.synapse.logAnalytics.keyVault.key.secret <AZURE_KEY_VAULT_SECRET_KEY_NAME>
spark.synapse.logAnalytics.keyVault.linkedServiceName <LINKED_SERVICE_NAME>
Configuração disponível do Apache Spark
| Nome da configuração | Valor padrão | Descrição |
|---|---|---|
| spark.synapse.logAnalytics.enabled | false | Use true para habilitar o coletor do Log Analytics em aplicativos Spark. Caso contrário, false. |
| spark.synapse.logAnalytics.workspaceId | - | A ID do workspace do Log Analytics de destino. |
| spark.synapse.logAnalytics.secret | - | O segredo do workspace do Log Analytics de destino. |
| spark.synapse.logAnalytics.keyVault.linkedServiceName | - | O nome do serviço vinculado ao Key Vault para a ID e a chave do workspace do Log Analytics. |
| spark.synapse.logAnalytics.keyVault.name | - | O nome do Key Vault para a ID e a chave do Log Analytics. |
| spark.synapse.logAnalytics.keyVault.key.workspaceId | SparkLogAnalyticsWorkspaceId | O nome secreto do Key Vault para a ID do workspace do Log Analytics. |
| spark.synapse.logAnalytics.keyVault.key.secret | SparkLogAnalyticsSecret | O nome secreto do Key Vault para o workspace do Log Analytics |
| spark.synapse.logAnalytics.uriSuffix | ods.opinsights.azure.com | O sufixo URI do workspace do Log Analytics de destino. Caso o workspace não esteja no Azure Global, será preciso atualizar o sufixo URI de acordo com a respectiva nuvem. |
| spark.synapse.logAnalytics.filter.eventName.match | - | Opcional. Os nomes de eventos do Spark separados por vírgula. Você pode especificar quais eventos serão coletados. Por exemplo: SparkListenerJobStart,SparkListenerJobEnd |
| spark.synapse.logAnalytics.filter.loggerName.match | - | Opcional. Os nomes dos agentes log4j separados por vírgula. Você pode especificar os logs que serão coletados. Por exemplo: org.apache.spark.SparkContext,org.example.Logger |
| spark.synapse.logAnalytics.filter.metricName.match | - | Opcional. Os sufixos de nome de métrica do Spark separados por vírgula. Você pode especificar as métricas que serão coletadas. Por exemplo: jvm.heap.used |
Observação
- Para o Microsoft Azure operado pela 21Vianet, o
spark.synapse.logAnalytics.uriSuffixparâmetro deve serods.opinsights.azure.cn. - O parâmetro
spark.synapse.logAnalytics.uriSuffixdeverá serods.opinsights.azure.usno Azure Government. - Para qualquer nuvem, exceto o Azure, o parâmetro
spark.synapse.logAnalytics.keyVault.namedeve ser o FQDN (nome de domínio totalmente qualificado) do Key Vault. Por exemplo,AZURE_KEY_VAULT_NAME.vault.usgovcloudapi.netpara AzureUSGovernment.
Etapa 3: carregar a configuração do Apache Spark em um pool do Apache Spark
Observação
Esta etapa será substituída pela etapa 4.
É possível carregar o arquivo de configuração no pool do Apache Spark do Azure Synapse Analytics. No Synapse Studio:
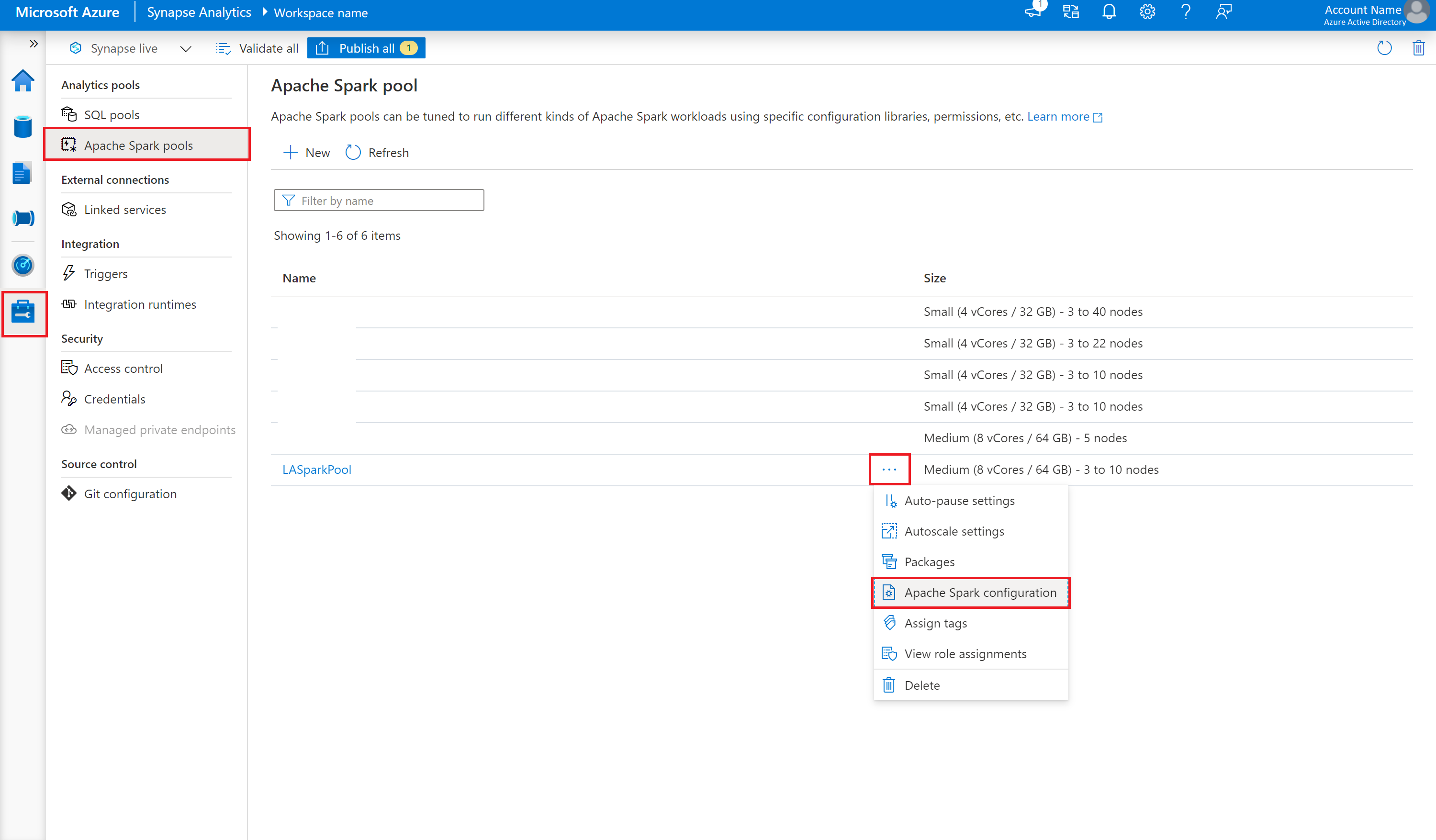
Clique em Gerenciar>Pools do Apache Spark.
Ao lado da opção Pool do Apache Spark, clique no botão ... .
Selecione Configuração do Apache Spark.
Clique em Carregar e selecione o arquivo spark_loganalytics_conf.txt.
Clique em Carregar, depois em Aplicar.
Observação
Todos os aplicativos Apache Spark enviados ao pool do Apache Spark usarão a definição de configuração para efetuar push das métricas e dos logs do aplicativo Apache Spark para o workspace indicado.
Etapa 4: Criar uma configuração do Apache Spark
É possível criar uma Configuração do Apache Spark para seu workspace e, ao criar a definição de trabalho do Notebook ou do Apache Spark, pode selecionar a configuração do Apache Spark que deseja usar com o pool do Apache Spark. Ao selecioná-lo, os detalhes da configuração são exibidos.
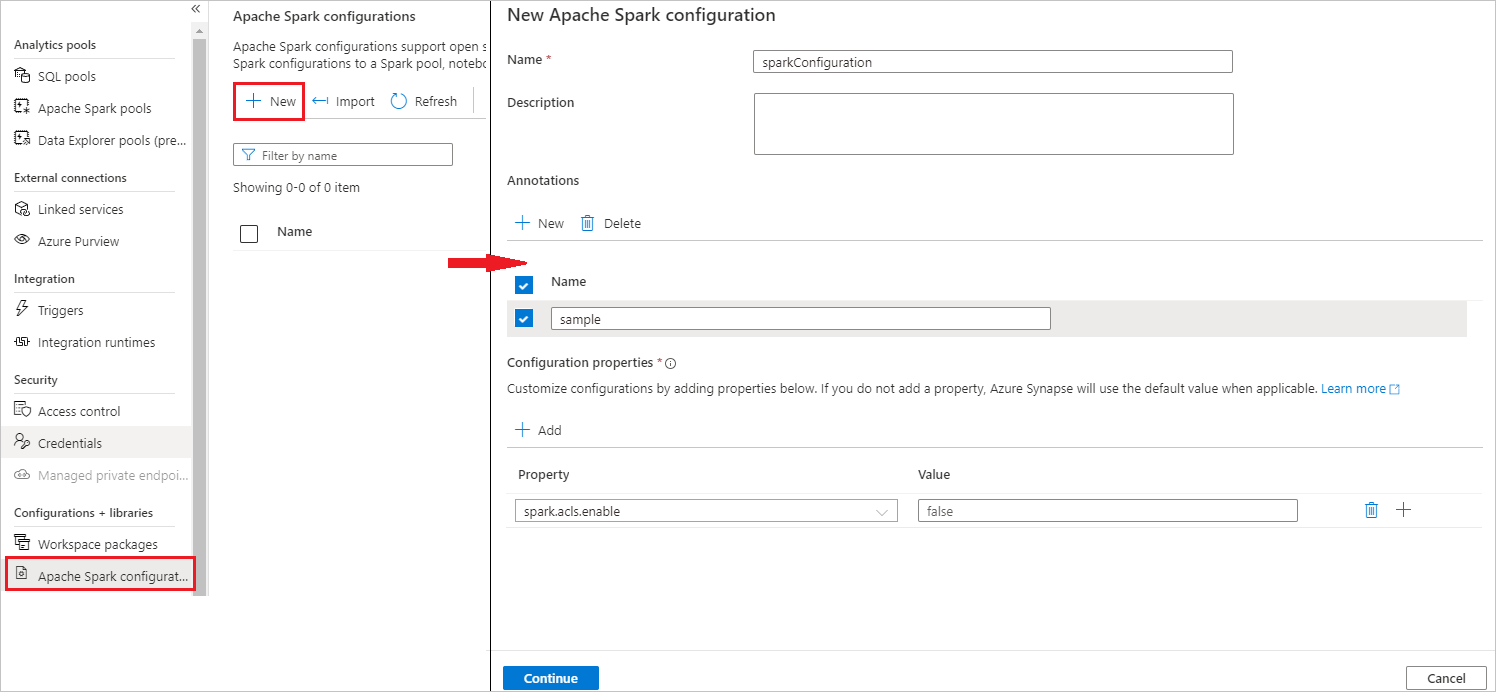
Selecione Gerenciar>configurações do Apache Spark.
Clique no botão Novo para criar uma nova configuração do Apache Spark ou clique em Importar um arquivo .json local para seu workspace.
A página Nova configuração do Apache Spark será aberta depois que você clicar no botão Novo.
Para Nome, digite seu nome preferencial e válido.
Para Descrição, digite alguma descrição nele.
Para Anotações, adicione anotações clicando no botão Novo e também é possível excluir anotações existentes selecionando e clicando no botão Excluir.
Para Propriedades de configuração, personalize a configuração clicando no botão Adicionar para adicionar propriedades. Se você não adicionar uma propriedade, o Azure Synapse usará o valor padrão quando aplicável.
Enviar um aplicativo Apache Spark e exibir os logs e as métricas
Este é o procedimento:
Envie um aplicativo Apache Spark para o pool do Apache Spark configurado na etapa anterior. É possível usar uma das opções abaixo para executar essa ação:
- Execute um notebook no Synapse Studio.
- No Synapse Studio, envie um trabalho em lotes do Apache Spark por meio de uma definição de trabalho do Apache Spark.
- Execute um pipeline que contém uma atividade do Apache Spark.
Acesse o workspace do Log Analytics indicado, depois veja as métricas e os logs do aplicativo ao iniciar a execução do aplicativo Apache Spark.
Gravar logs de aplicativo personalizados
Você pode usar a biblioteca do Apache Log4j para gravar logs personalizados.
Exemplo para Scala:
%%spark
val logger = org.apache.log4j.LogManager.getLogger("com.contoso.LoggerExample")
logger.info("info message")
logger.warn("warn message")
logger.error("error message")
//log exception
try {
1/0
} catch {
case e:Exception =>logger.warn("Exception", e)
}
// run job for task level metrics
val data = sc.parallelize(Seq(1,2,3,4)).toDF().count()
Exemplo para PySpark:
%%pyspark
logger = sc._jvm.org.apache.log4j.LogManager.getLogger("com.contoso.PythonLoggerExample")
logger.info("info message")
logger.warn("warn message")
logger.error("error message")
Usar a pasta de trabalho de exemplo para visualizar as métricas e os logs
Abra e copie o conteúdo do arquivo da pasta de trabalho.
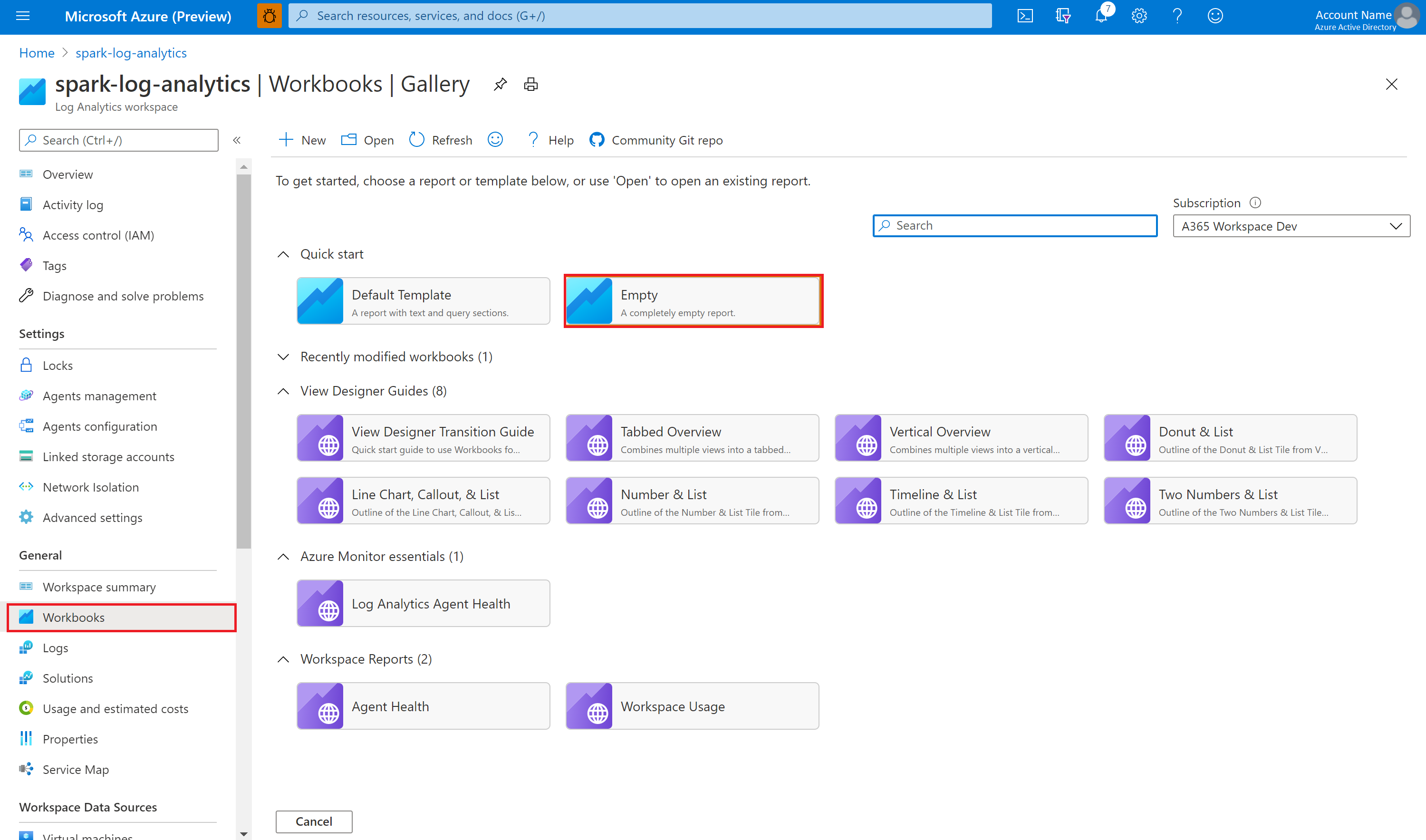
No portal do Azure, selecione Workspace do Log Analytics>Pastas de Trabalho.
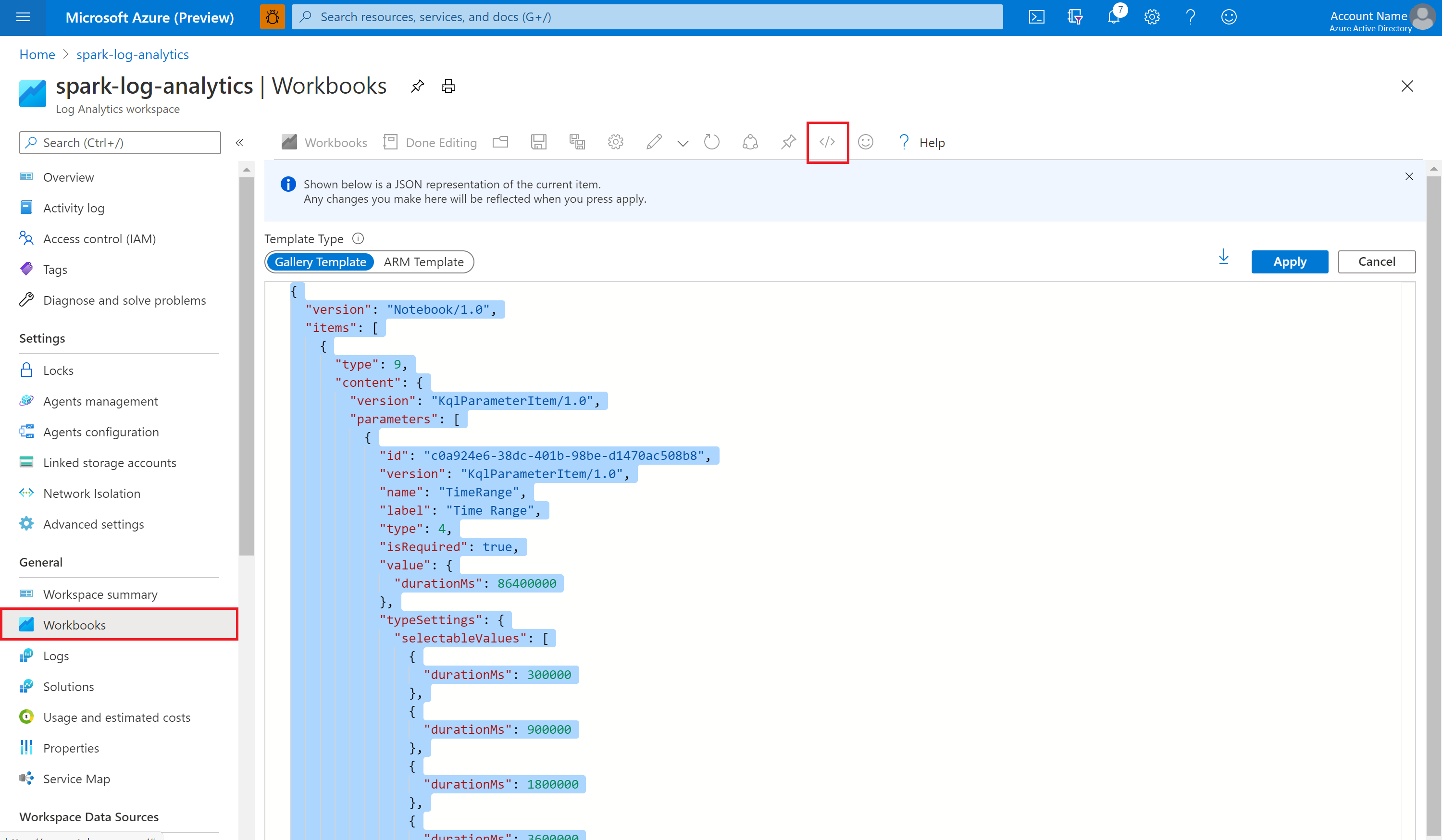
Abra a pasta de trabalho Vazia. Use o modo Editor Avançado clicando no ícone </>.
Cole em algum código JSON existente.
Clique em Aplicar, depois selecione Edição Concluída.
Em seguida, envie seu aplicativo Apache Spark para o pool do Apache Spark configurado. Depois que o aplicativo entrar no estado de execução, selecione o aplicativo em execução na lista suspensa da pasta de trabalho.

É possível personalizar a pasta de trabalho. Por exemplo, é possível usar consultas do Kusto e configurar alertas.
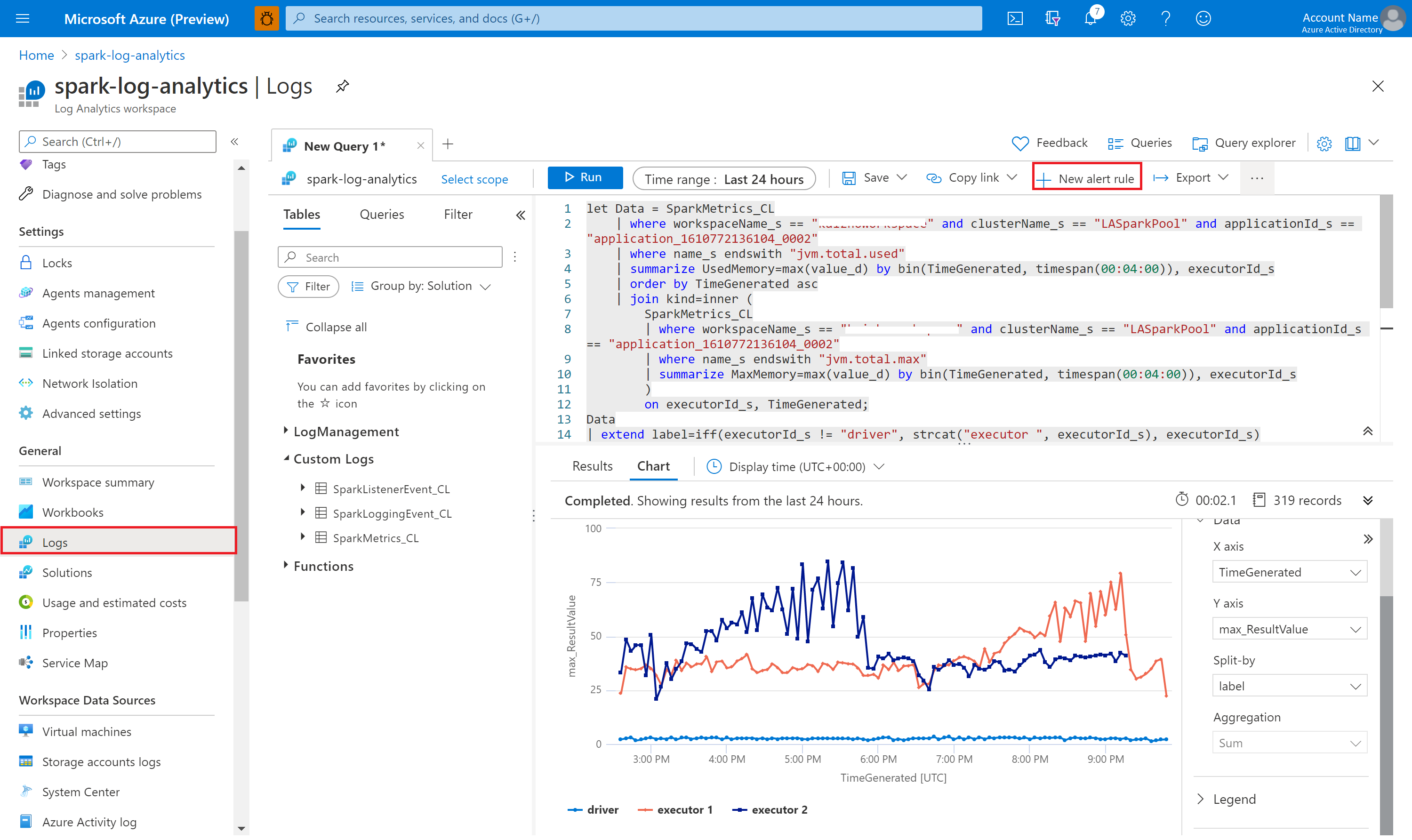
Consultar dados com o Kusto
O seguinte exemplo mostra como consultar eventos do Apache Spark:
SparkListenerEvent_CL
| where workspaceName_s == "{SynapseWorkspace}" and clusterName_s == "{SparkPool}" and livyId_s == "{LivyId}"
| order by TimeGenerated desc
| limit 100
Veja um exemplo de como consultar o driver do aplicativo Apache Spark e os logs executores:
SparkLoggingEvent_CL
| where workspaceName_s == "{SynapseWorkspace}" and clusterName_s == "{SparkPool}" and livyId_s == "{LivyId}"
| order by TimeGenerated desc
| limit 100
Veja também um exemplo de como consultar métricas do Apache Spark:
SparkMetrics_CL
| where workspaceName_s == "{SynapseWorkspace}" and clusterName_s == "{SparkPool}" and livyId_s == "{LivyId}"
| where name_s endswith "jvm.total.used"
| summarize max(value_d) by bin(TimeGenerated, 30s), executorId_s
| order by TimeGenerated asc
Criar e gerenciar alertas
Os usuários podem executar uma consulta para avaliar as métricas e os logs em uma frequência definida, bem como disparar um alerta com base nos resultados. Para obter mais informações, confira como Criar, ver e gerenciar alertas de logs usando o Azure Monitor.
Workspace do Azure Synapse com a proteção contra exfiltração dos dados habilitada
Após o workspace do Azure Synapse ser criado com a proteção contra exfiltração dos dados habilitada,
Quando quiser habilitar esse recurso, você precisará criar solicitações de conexão do ponto de extremidade privado gerenciado nos Escopos de link privado do Azure Monitor (A M P L S) nos locatários aprovados do Microsoft Entra no workspace.
Você pode seguir as etapas abaixo para criar uma conexão de ponto de extremidade privado gerenciada para escopos de link privado do Azure Monitor (AMPLS):
- Se não houver um AMPLS, siga a configuração de conexão do Link Privado do Azure Monitor para criar um.
- Navegue até seu AMPLS no portal do Azure e, na página Recursos do Azure Monitor, clique em Adicionar para adicionar a conexão a seu workspace do Azure Log Analytics.
- Navegue até Synapse Studio > Gerenciar > Pontos de extremidade privados gerenciados, clique no botão Novo, selecione Escopos de Link Privado do Azure Monitor e continuar.
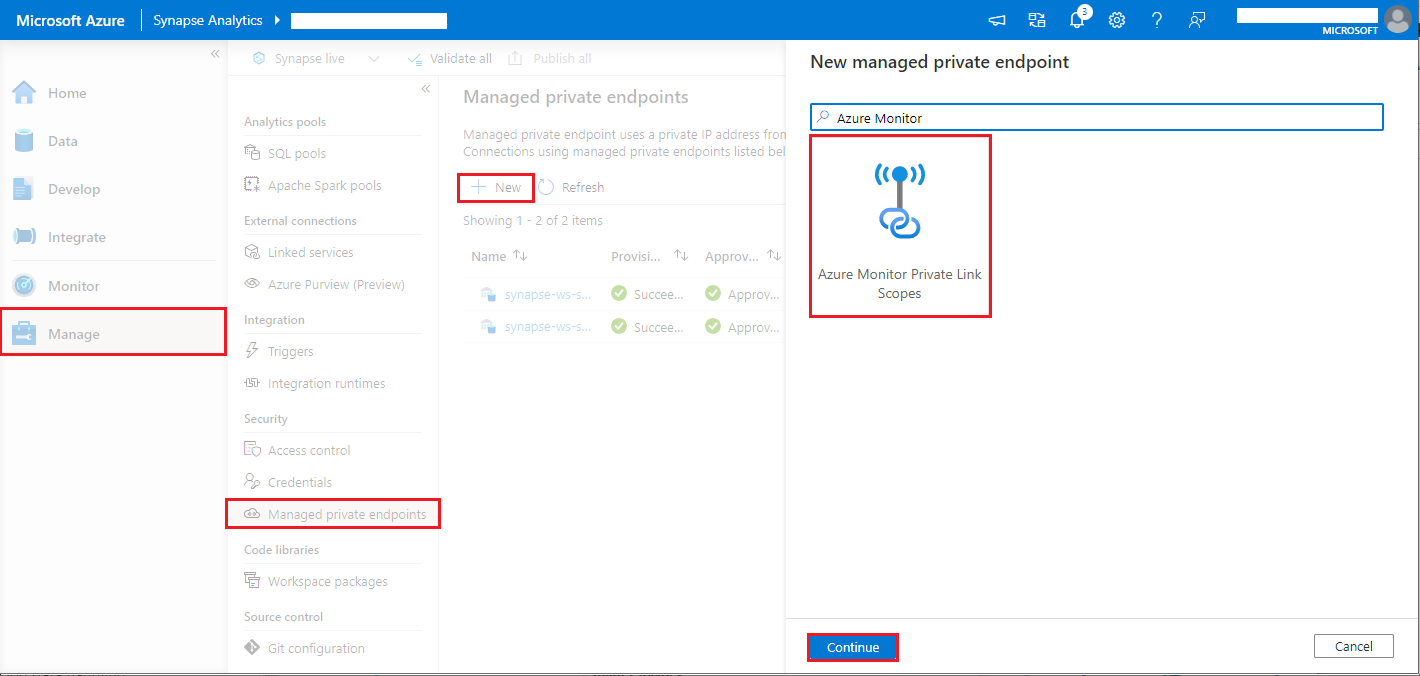
- Escolha o escopo de link privado do Azure Monitor que você criou e selecione o botão Criar.
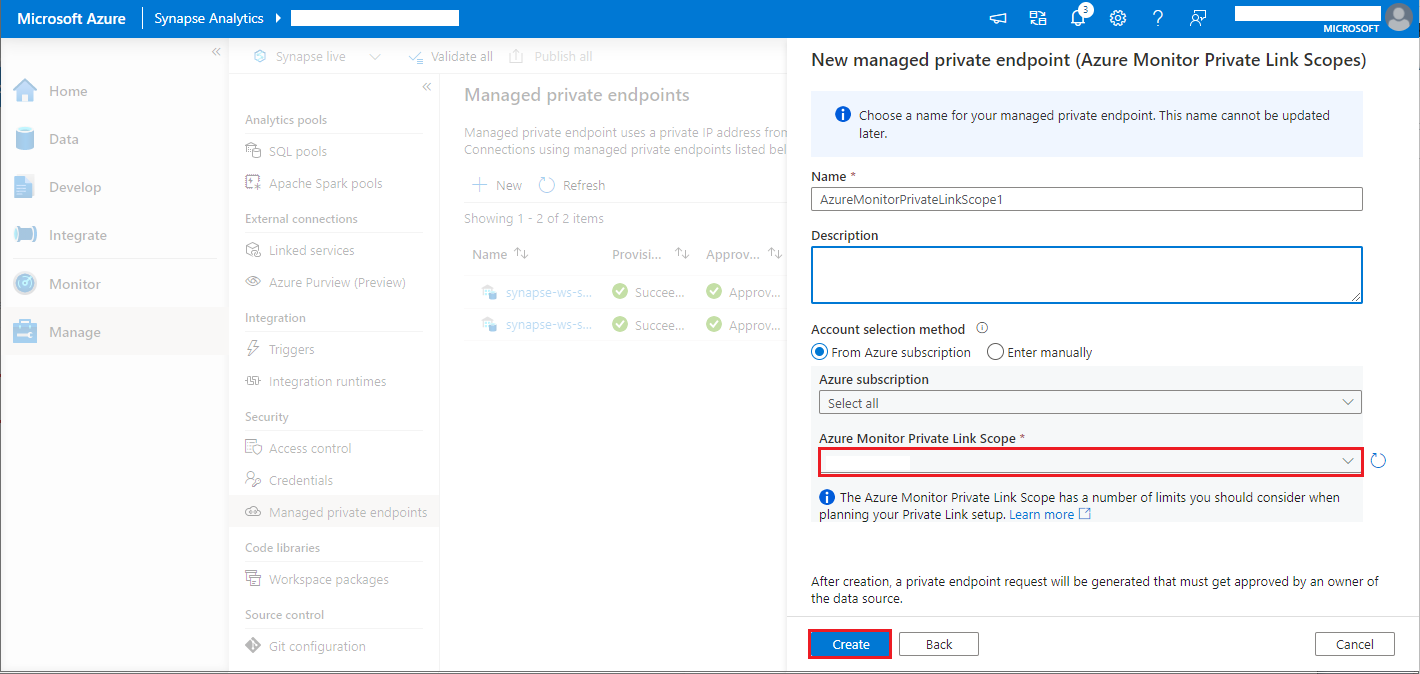
- Aguarde alguns minutos para o provisionamento do ponto de extremidade privado.
- Navegue até seu AMPLS no portal do Azure e, na página Conexões de ponto de extremidade privado, selecione a conexão provisionada e Aprovar.
Observação
- O objeto AMPLS tem vários limites que você deve considerar ao planejar a configuração do Link Privado. Consulte Limites do AMPLS para obter uma análise mais profunda desses limites.
- Verifique se você tem a permissão correta para criar um ponto de extremidade privado.
Próximas etapas
- Usar o Pool do Apache Spark sem servidor no Synapse Studio.
- Executar um aplicativo Spark em um notebook.
- Criar uma definição de trabalho do Apache Spark no Azure Studio.
- Coletar logs e métricas de aplicativos do Apache Spark com a conta de Armazenamento do Azure.
- Coletar logs e métricas de aplicativos do Apache Spark com os Hubs de Eventos do Azure.
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de