Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Um notebook do Microsoft Fabric é um item de código principal para o desenvolvimento de trabalhos do Apache Spark e experimentos de aprendizado de máquina. É uma superfície interativa baseada na Web utilizada por cientistas de dados e engenheiros de dados para escrever códigos que se beneficiam de visualizações avançadas e texto Markdown. Este artigo explica como desenvolver notebooks com operações em células de código e executá-los.
Desenvolver notebooks
Os notebooks consistem em células, que são blocos individuais de código ou texto que podem ser executados de forma independente ou em grupo.
Fornecemos operações avançadas para desenvolver notebooks:
- Adicionar uma célula
- Definir uma linguagem principal
- Usar vários idiomas
- IntelliSense no estilo IDE
- Trechos de código
- Arrastar e soltar para inserir trechos
- Arrastar e soltar para inserir imagens
- Formatar célula de texto com botões da barra de ferramentas
- Desfazer ou refazer a operação da célula
- Mover uma célula
- Excluir uma célula
- Recolher uma entrada de célula
- Recolher uma saída de célula
- Segurança de saída da célula
- Bloquear ou congelar uma célula
- Conteúdos do Notebook
- Dobramento de Markdown
- Encontrar e substituir
- Modo de tamanho total em uma célula
Adicionar uma célula
Há várias maneiras de adicionar uma nova célula ao notebook.
Passe o mouse sobre o espaço entre duas células e selecione Código ou Markdown.
Use teclas de atalho no modo de comando. Pressione A para inserir uma célula acima da célula atual. Pressione B para inserir uma célula abaixo da célula atual.
Definir uma linguagem principal
Os notebooks do Fabric suportam atualmente quatro linguagens do Apache Spark:
- PySpark (Python)
- Spark (Scala)
- Spark SQL
- SparkR
Defina a linguagem principal para novas células adicionadas na lista suspensa na barra de comandos superior.
Usar vários idiomas
Use várias linguagens em um notebook especificando o comando magic da linguagem no início de uma célula. Você também pode alterar o idioma da célula no menu de seleção de idioma. A tabela a seguir lista os comandos mágicos para alternar as linguagens das células.

| Comando mágico | Idioma | Descrição |
|---|---|---|
| %%pyspark | Python | Execute uma consulta Python no contexto do Apache Spark. |
| %%spark | Scala (linguagem de programação) | Execute uma consulta Scala no contexto do Apache Spark. |
| %%sql | SparkSQL | Execute uma consulta SparkSQL no contexto do Apache Spark. |
| %%html | Html | Execute uma consulta HTML no Contexto do Apache Spark. |
| %%sparkr | R | Execute uma consulta R no contexto do Apache Spark. |
IntelliSense de estilo IDE
Os notebooks do Fabric são integrados ao editor Monaco para colocar o IntelliSense de estilo IDE ao editor de célula. O realce de sintaxe, o marcador de erros e os preenchimentos de código automáticos ajudam você a codificar rapidamente e identificar problemas.
Os recursos do IntelliSense estão em níveis diferentes de maturidade para linguagens diferentes. A tabela a seguir mostra o suporte do Fabric:
| Idiomas | Realce da sintaxe | Marcador de erro de sintaxe | Conclusão de código de sintaxe | Conclusão de código de variável | Conclusão de código de função do sistema | Conclusão do código de função do usuário | Recuo Inteligente | Dobramento de código |
|---|---|---|---|---|---|---|---|---|
| PySpark (Python) | Sim | Sim | Sim | Sim | Sim | Sim | Sim | Sim |
| Python | Sim | Sim | Sim | Sim | Sim | Sim | Sim | Sim |
| Spark (Scala) | Sim | Sim | Sim | Sim | Sim | Sim | Sim | Sim |
| SparkSQL | Sim | Sim | Sim | Sim | Sim | Não | Sim | Sim |
| SparkR | Sim | Sim | Sim | Sim | Sim | Sim | Sim | Sim |
| T-SQL | Sim | Sim | Sim | Não | Sim | Sim | Sim | Sim |
Observação
É necessário ter uma sessão ativa do Apache Spark para usar a conclusão do código do IntelliSense.
Melhore o desenvolvimento Python com Pylance
Pylance, um servidor de linguagem poderoso e rico em recursos, agora está disponível no Fabric Notebook. O Pylance facilita o desenvolvimento em Python com conclusões inteligentes, melhor detecção de erros e insights de código aprimorados. As principais melhorias incluem preenchimento automático mais inteligente, suporte aprimorado a expressões lambda, sugestões de parâmetros, informações de sobreposição aprimoradas, melhor renderização de docstrings e realce de erros. Com o Pylance, escrever código Python e PySpark se torna mais rápido, preciso e eficiente.
Trechos de código
Os notebooks do Fabric fornecem trechos de código que ajudam você a gravar facilmente os padrões de código utilizados com frequência, como:
- Ler dados como um DataFrame do Apache Spark
- Desenhar gráficos com o Matplotlib
Os trechos aparecem em Teclas de atalho do IntelliSense de estilo IDE misturados com outras sugestões. O conteúdo do trecho de código corresponde à linguagem da célula de código. Visualize os snippets disponíveis digitando Snippet. Também poderá digitar qualquer palavra-chave para visualizar uma lista de snippets relevantes. Por exemplo, se você digitar leitura, verá a lista de snippets para fazer a leitura dos dados de várias fontes de dados.

Arrastar e soltar para inserir trechos de código
Use o recurso de arrastar e soltar para fazer a leitura de dados do Lakehouse Explorer de forma conveniente. Vários tipos de arquivos são suportados aqui, podendo operar em arquivos de texto, tabelas, imagens, etc. É possível soltar em uma célula existente ou em uma nova célula. O notebook gera o snippet de código de acordo com a prévia dos dados.

Arrastar e soltar para inserir imagens
Use o recurso de arrastar e soltar para inserir facilmente imagens do navegador ou do computador local em uma célula de markdown.

Formatar célula de texto com botões da barra de ferramentas
Para concluir ações Markdown comuns, use os botões de formatação na barra de ferramentas da célula de texto.

Desfazer ou refazer as operações das células
Selecione Desfazer ou Refazer ou pressione Z ou Shift+Z para revogar as operações de célula mais recentes. É possível desfazer ou refazer até 10 das últimas operações de células históricas.

Operações de desfazer célula com suporte:
- Inserir ou excluir célula. Você pode revogar as operações excluídas selecionando Desfazer (o conteúdo do texto é mantido junto com a célula).
- Reordenar célula.
- Alternar parâmetro.
- Converter entre célula de código e célula de Markdown.
Observação
As operações de texto na célula e as operações de comentários na célula do código não podem ser desfeitas. É possível desfazer ou refazer até 10 das últimas operações de células históricas.
Mover uma célula
Você pode arrastar da parte vazia de uma célula e soltá-la na posição desejada.
Também é possível utilizar Mover para cima e Mover para baixo na faixa de opções para mover a célula selecionada.

Excluir uma célula
Para excluir uma célula, selecione o botão excluir à direita da célula.
Também poderá usar teclas de atalho no modo de comando. Pressione D,D (D duas vezes) para excluir a célula atual.
Recolher uma entrada de célula
Selecione as reticências (...) Mais comandos na barra de ferramentas da célula e Ocultar entrada para recolher a entrada da célula atual. Para expandi-la novamente, selecione Mostrar entrada enquanto a célula estiver recolhida.
Recolher uma saída de célula
Selecione as reticências (...) Mais comandos na barra de ferramentas da célula e Ocultar entrada para recolher a saída da célula atual. Para expandi-la novamente, selecione Mostrar saída enquanto a saída da célula estiver recolhida.
Segurança de saída da célula
Você pode usar funções de acesso a dados do OneLake (versão prévia) para configurar o acesso apenas a pastas específicas em um lakehouse durante consultas em notebooks. Usuários sem acesso a uma pasta ou tabela veem um erro não autorizado durante a execução da consulta.
Importante
A segurança só se aplica durante a execução da consulta. Células de notebook que contêm resultados de consulta podem ser exibidas por usuários que não estão autorizados a executar consultas diretamente nos dados.
Bloquear ou congelar uma célula
As operações de bloqueio e congelamento de células permitem fazer com que as células sejam somente leitura ou impedir que as células de código sejam executadas em uma pessoa.

Mesclar e dividir células
Use a Mesclagem com células anteriores ou Mesclagem com a próxima célula para mesclar células relacionadas convenientemente.
Selecionar Dividir célula ajuda a dividir instruções irrelevantes em várias células. A operação divide o código de acordo com a posição de linha do cursor.

Conteúdos do Notebook
Selecionar Estruturas do Código ou Sumário apresenta o primeiro cabeçalho de markdown de qualquer célula de markdown em uma janela de barra lateral para navegação rápida. A barra lateral de Estruturas do Códigos é redimensionável e recolhível para se ajustar à tela da melhor maneira possível. Selecione o botão Conteúdos na barra de comandos do notebook para abrir ou ocultar a barra lateral.

Dobramento de markdown
A opção de dobramento de markdown permite ocultar células sob uma célula de markdown que contenha um título. A célula de markdown e suas células ocultas são tratadas da mesma forma que um conjunto de células contíguas multisselecionadas ao realizar operações de célula.

Localizar e substituir
A opção localizar e substituir pode ajudá-lo a corresponder e localizar as palavras-chave ou expressão no conteúdo do notebook. Também poderá substituir facilmente a cadeia de caracteres de destino por uma nova cadeia de caracteres.

Modo de tamanho total em uma célula
O modo de tamanho completo permite que você se concentre totalmente na gravação e edição de código em uma única célula , perfeito para lógica longa ou complexa. Você pode alternar esse modo clicando no botão expandir célula na barra de ferramentas da célula para expandir a célula e sair clicando em retornar ao tamanho padrão.

Complementação de código inline do Copilot (versão prévia)
A completação de código em linha do Copilot é um recurso de IA que ajuda você a escrever código Python de forma mais rápida e eficiente no ambiente do Fabric Notebooks. Esse recurso fornece sugestões de código inteligentes e com reconhecimento de contexto à medida que você digita código. Ele reduz tarefas repetitivas, minimiza erros de sintaxe e acelera o desenvolvimento integrando-se perfeitamente ao fluxo de trabalho do notebook.
Principais benefícios
- Conclusões controladas por IA: Gera sugestões com base no contexto do bloco de anotações usando um modelo treinado em milhões de linhas de código.
- Aumenta a produtividade: Ajuda a escrever funções complexas, reduz a codificação repetitiva e acelera a exploração de bibliotecas desconhecidas.
- Reduz erros: Minimiza erros de digitação e sintaxe com conclusões inteligentes e com reconhecimento de contexto.
- Configuração mínima: Embutido nos notebooks do Fabric e não requer qualquer instalação. Você pode simplesmente habilitá-lo e começar a codificar.
Como funciona
Habilite sugestões de código em linha usando o alternador na parte inferior do notebook.

Conforme você digita, as sugestões aparecem em texto cinza claro, pressione tab para aceitar ou modificar. As sugestões são baseadas em células de bloco de anotações anteriores.

Observação
Habilitar a conclusão de código embutido do Copilot consome mais unidades de capacidade.
Limitações atuais
- Atualmente, o Copilot Inline Code Completion dá suporte à linguagem Python e usa o contexto de células anteriores e esquemas lakehouse.
- As sugestões consideram os dados dos esquemas do Lakehouse.
- Somente um subconjunto de elementos de esquema é usado quando há muitas tabelas ou colunas.
- Tabelas criadas dinamicamente (via Spark) não são reconhecidas em tempo real.
- As conclusões embutidas são principalmente limitadas ao contexto de células anteriores e aos esquemas de Lakehouse. As ações e diagnósticos do Copilot no nível de bloco de anotações descritos nas seções a seguir podem usar um contexto de notebook mais amplo (estrutura e estado de execução) sem a necessidade de iniciar uma sessão Spark.
Ações em todo o bloco de anotações do Copilot
O Copilot dá suporte a funcionalidades de várias etapas em todo o notebook que vão além das células individuais. Você pode usar o Copilot para gerar código entre células, refatorar a lógica em funções reutilizáveis, resumir fluxos de trabalho inteiros e validar a saída do notebook. O Copilot entende o contexto do workspace, os esquemas, tabelas e arquivos do Lakehouse anexados, a estrutura do notebook e o estado de execução, e está ciente do contexto imediatamente, sem a necessidade de iniciar uma sessão do Spark.
Para obter detalhes sobre o painel de chat e os comandos de barra, consulte Usar o painel de chat do Copilot.
Análises de desempenho com o Copilot
O Copilot apresenta recomendações de otimização com base no tamanho dos dados, nos padrões de junção e no comportamento de runtime. Por exemplo, ele pode propor estratégias de junção eficientes, ajudá-lo a evitar embaralhamentos de dados, detectar problemas de qualidade de dados e sugerir refatorações para melhor reutilização e manutenção. Esses insights aparecem em conversas do Copilot e se alinham com o comando /optimize.
Correção com Copilot
Quando uma célula ou trabalho Spark falha, uma opção Correção com Copilot é exibida abaixo da célula que falhou. O Copilot fornece um resumo de erros, causa raiz provável, correções recomendadas e a capacidade de aplicar alterações automaticamente com uma diferença de aprovação. Você também pode usar o /fix comando no chat do Copilot para executar o diagnóstico direcionado em uma célula específica ou em todo o notebook.
Para obter mais informações, consulte Diagnosticar falhas de notebook com Copilot.
Executar notebooks
Você pode executar as células de código em seu notebook individualmente ou todas de uma vez. O status e o progresso de cada célula são exibidos no notebook.
Executar uma célula
Há várias maneiras de executar o código em uma célula.
Passe o mouse sobre a célula a ser executada e selecione o botão Executar célula ou pressione Ctrl+Enter.
Use teclas de atalho no modo de comando. Pressione Shift+Enter para executar a célula atual e selecionar a próxima célula. Pressione Alt+Enter para executar a célula atual e inserir uma nova célula.
Executar todas as células
Selecione o botão Executar tudo para executar todas as células do notebook atual em sequência.
Executar todas as células acima ou abaixo
Expanda a lista suspensa de Executar tudo e selecione Executar células acima para executar todas as células acima da atual em sequência. Selecione Executar células abaixo para executar em sequência a célula atual e todas as células abaixo da atual.

Cancelar todas as células em execução
Selecione Cancelar tudo para cancelar as células em execução ou as células aguardando na fila.
Interromper a sessão
Interromper sessão cancela as células em execução e em espera e interrompe a sessão atual. É possível reiniciar uma nova sessão selecionando a opção de Executar novamente.

Execução de referência
Execução de referência de um Notebook
Além da API de execução de referência notebookutils, também é possível utilizar o comando mágico %run <notebook name> para referenciar outro notebook no contexto do notebook atual. Todas as variáveis definidas no bloco de anotações de referência estão disponíveis no notebook atual. O comando magic %run dá suporte a chamadas aninhadas, mas não dá suporte a chamadas recursivas. Você receberá uma exceção se a profundidade da declaração for maior que cinco.
Exemplo: %run Notebook1 { "parameterInt": 1, "parameterFloat": 2.5, "parameterBool": true, "parameterString": "abc" }.
A referência do Notebook funciona tanto no modo interativo quanto no pipeline.
Observação
- Atualmente, o comando
%runsuporta apenas notebooks de referência no mesmo espaço de trabalho com o notebook atual. - O comando
%runatualmente só dá suporte a até quatro tipos de valor de parâmetro:int,float,boolestring. Não há suporte para a operação de substituição de variável. - O comando
%runnão dá suporte às referências aninhadas com um profundidade seja maior que cinco.
Execução de referência de um script
O comando %run também permite executar arquivos Python ou SQL que são armazenados nos recursos internos do notebook, para que você possa executar seus arquivos de código-fonte nesse notebook convenientemente.
%run [-b/--builtin -c/--current] [script_file.py/.sql] [variables ...]
Para opções:
- -b/--builtin: Essa opção indica que o comando encontra e executa o arquivo de script especificado a partir dos recursos internos do notebook.
- -c/--current: Essa opção garante que o comando sempre use os recursos internos do notebook atual, mesmo que este seja referenciado por outros notebooks.
Exemplos:
Para executar script_file.py a partir dos recursos internos:
%run -b script_file.pyPara executar script_file.sql a partir dos recursos internos:
%run -b script_file.sqlPara executar script_file.py a partir dos recursos internos com variáveis específicas:
%run -b script_file.py { "parameterInt": 1, "parameterFloat": 2.5, "parameterBool": true, "parameterString": "abc" }
Observação
Se o comando não contiver -b/--builtin, ele tentará localizar e executar o item de notebook dentro do mesmo workspace em vez dos recursos internos.
Exemplo de uso para caso de execução aninhado:
- Suponha que tenhamos dois blocos de anotações.
- Notebook1: contém script_file1.py em seus recursos internos
- Notebook2: contém script_file2.py em seus recursos internos
- Vamos usar Notebook1 como um notebook raiz com o conteúdo:
%run Notebook2. - Em Notebook2, a instrução de uso é:
- Para executar script_file1.py no Notebook1(o Notebook raiz), o código seria:
%run -b script_file1.py - Para executar script_file2.py no Notebook2(o Notebook atual), o código seria:
%run -b -c script_file2.py
- Para executar script_file1.py no Notebook1(o Notebook raiz), o código seria:
Gerenciador de variáveis
Os notebooks do Fabric fornecem um gerenciador de variáveis incorporado que exibe a lista de nomes de variáveis, tipo, comprimento e valor na atual sessão Spark para células (Python) PySpark. Mais variáveis são mostradas automaticamente à medida que são definidas nas células de código. Clicar em cada cabeçalho de coluna classifica as variáveis na tabela.
Para abrir ou ocultar o gerenciador de variáveis, selecione Variáveis na faixa de opções do notebook Exibir.

Observação
O gerenciador de variáveis dá suporte apenas ao Python.
Indicador de estado de célula
Um status de execução de célula passo a passo é exibido abaixo da célula para ajudá-lo a ver seu progresso atual. Após a conclusão da execução da célula, um resumo da execução com a duração total e a hora de término é exibido e armazenado para referência futura.

Indicador de status da sessão
Configuração de tempo limite da sessão
No canto inferior esquerdo, você pode selecionar o status da sessão para obter mais informações sobre a sessão atual:

No pop-up, há uma opção para redefinir o tempo limite para x minutos ou horas.

Escolha por quanto tempo deseja uma sessão ininterrupta e clique em aplicar. O tempo limite da sessão se redefine com o novo valor e você está pronto para ir!
Você também pode definir o tempo limite conforme descrito em:
- Configurações de administração do workspace de Engenharia de Dados no Microsoft Fabric
- Comando mágico de configuração de sessão do Spark
Mantenha-se conectado: Durante o login, se você vir o diálogo Mantenha-se conectado, selecione Sim para desativar o tempo limite de inatividade para sua sessão atual.
Importante
Não selecione a caixa de seleção Não mostrar isso novamente, pois bloqueará permanentemente suas configurações de login. Essa opção poderá não aparecer se o administrador do locatário tiver desabilitado a configuração KMSI (Keep Me Signed In).
Solicitar uma alteração de política: Se você precisar de uma duração de sessão mais longa, peça ao administrador do inquilino para estender a política de duração do tempo limite para sessões inativas. Eles podem fazer isso navegando até Configurações da Organização > Segurança e Privacidade > Tempo limite de sessão ociosa no Centro de Administração do Microsoft 365.
Observação
Selecionar KMSI e/ou estender o tempo limite da sessão ociosa aumenta o risco de uma máquina desbloqueada ser acessada.
Como ABT e o tempo limite de sessão ociosa afetam execuções prolongadas do Fabric Notebook?
Se o locatário usar o ABT (tempo limite baseado em atividade), trabalhos interativos de execução prolongada em notebooks do Fabric poderão ser afetados pela política de tempo limite de sessão ociosa do Microsoft 365. Esse recurso de segurança foi projetado para desconectar usuários em dispositivos inativos e não gerenciados, mesmo que um trabalho de notebook ainda esteja em execução. Embora a atividade em outros aplicativos do Microsoft 365 possa manter a sessão ativa, os dispositivos ociosos são desconectados por design.
Por que os usuários são desconectados mesmo quando um trabalho de notebook ainda está em execução?
O tempo limite de sessão ocioso prioriza a segurança encerrando sessões em dispositivos inativos para impedir o acesso não autorizado. Mesmo quando uma execução de notebook está em andamento, a sessão termina se o dispositivo não mostra nenhuma atividade. Manter as sessões abertas em dispositivos ociosos comprometeria a segurança, razão pela qual o comportamento atual é imposto.
Indicador de trabalho do Apache Spark embutido
Os notebooks do Fabric são baseados no Apache Spark. As células do código são executadas remotamente no cluster do Apache Spark. Um indicador de progresso do trabalho do Spark é fornecido com uma barra de progresso em tempo real que aparece para ajudá-lo a entender o status de execução do trabalho. O número de tarefas por cada trabalho ou estágio ajuda a identificar o nível paralelo do seu trabalho do Spark. Você também pode fazer uma busca detalhada na interface do usuário do Spark de um trabalho específico (ou estágio) por meio da seleção do link no nome do trabalho (ou estágio).
Também é possível encontrar o Registo em tempo real do nível da célula junto ao indicador de progresso, e o Diagnóstico pode fornecer sugestões úteis para ajudar a refinar e depurar o código. Quando solicitado, o Copilot pode usar informações de trabalho de runtime para ajudar a solucionar recomendações de desempenho e confiabilidade. Se uma tarefa ou célula falhar, o ponto de entrada Corrigir com Copilot estará disponível para ajudar a diagnosticar e resolver o problema.

Em Mais ações, você pode navegar facilmente para a página Detalhes do aplicativo do Spark e para a página Interface do usuário do Spark na Web.

Redação de segredo
Para evitar que as credenciais vazem acidentalmente durante a execução de notebooks, os notebooks do Fabric dão suporte à Redação secreta para substituir os valores secretos exibidos na saída da célula por [REDACTED]. A redação secreta é aplicável para Python, Scala, e R.

Comandos mágicos em um caderno
Comandos magic internos
É possível utilizar os comandos mágicos conhecidos do Ipython nos notebooks do Fabric. Confira a lista a seguir de comandos magic disponíveis no momento.
Observação
Estes são os únicos comandos magic com suporte no pipeline do Fabric: %%pyspark, %%spark, %%csharp, %%sql, %%configure.
Comandos magic de linha disponíveis: %lsmagic, %time, %timeit, %history, %run, %load, %alias, %alias_magic, %autoawait, %autocall, %automagic, %bookmark, %cd, %colors, %dhist, %dirs, %doctest_mode, %killbgscripts, %load_ext, %logoff, %logon, %logstart, %logstate, %logstop, %magic, %matplotlib, %page, %pastebin, %pdef, %pfile, %pinfo, %pinfo2, %popd, %pprint, %precision, %prun, %psearch, %psource, %pushd, %pwd, %pycat, %quickref, %rehashx, %reload_ext, %reset, %reset_selective, %sx, %system, %tb, %unalias, %unload_ext, %who, %who_ls, %whos, %xdel, %xmode.
O notebook do Fabric também dá suporte aos comandos de gerenciamento de biblioteca aprimorados %pip e %conda. Para obter mais informações sobre o uso, consulte Gerenciar bibliotecas do Apache Spark no Microsoft Fabric.
Comandos magic de célula disponíveis: %%time, %%timeit, %%capture, %%writefile, %%sql, %%pyspark, %%spark, %%csharp, %%configure, %%html, %%bash, %%markdown, %%perl, %%script, %%sh.
Comandos mágicos personalizados
Também é possível criar mais comandos magic personalizados para atender às suas necessidades específicas. Veja um exemplo:
Criar um notebook com o nome "MyLakehouseModule".
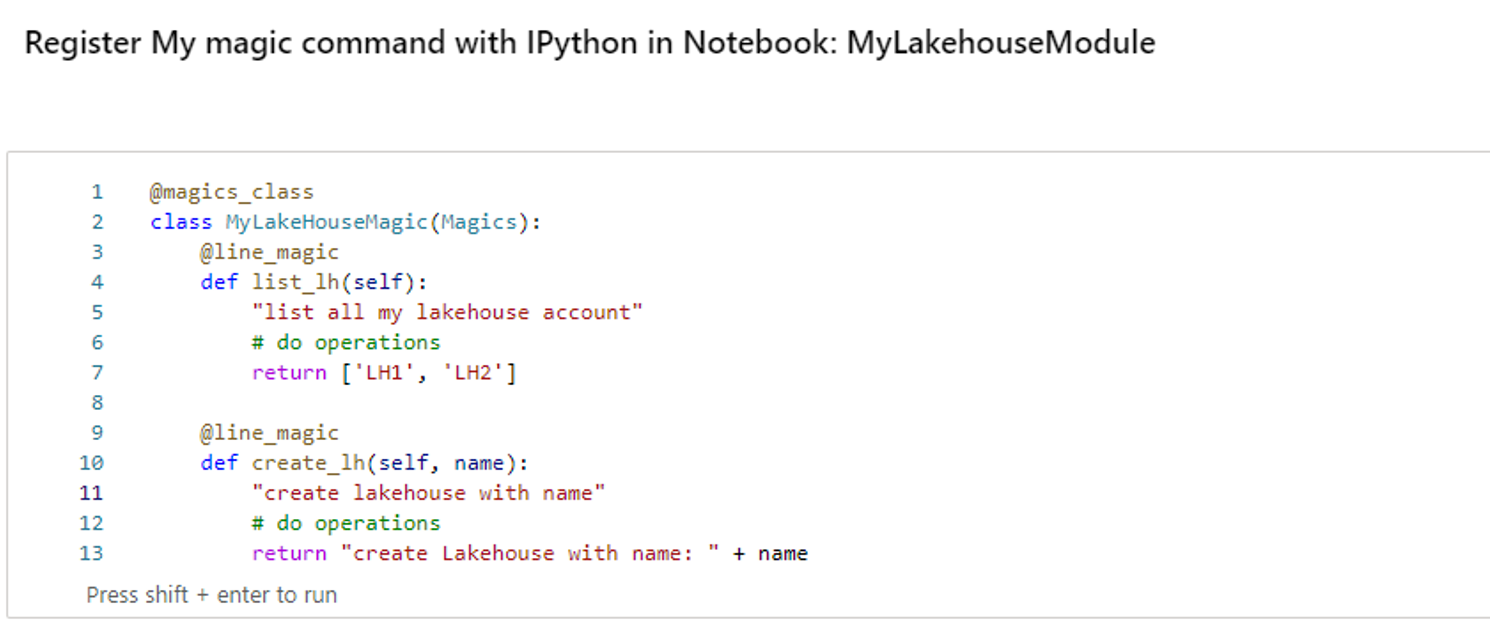
Em outro notebook, faça referência ao “MyLakehouseModule” e seus comandos mágicos. Esse processo é como você poderá organizar convenientemente seu projeto com notebooks que usam idiomas diferentes.
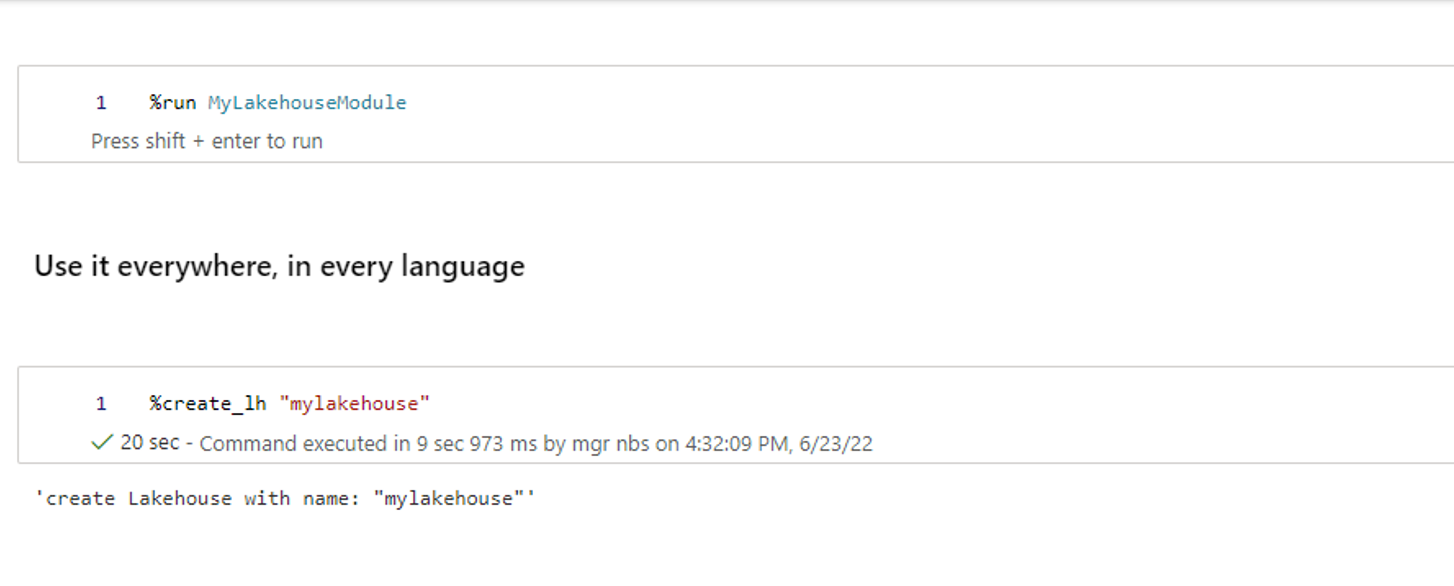


Widgets de IPython
Os widgets do IPython são objetos do Python com eventos que têm uma representação no navegador. É possível utilizar os Widgets IPython como controles de baixo código (por exemplo, controle deslizante ou caixa de texto) no seu notebook tal como o notebook Jupyter. Atualmente, ele só funciona em um contexto do Python.
Para usar o Widgets de IPython
Importe o módulo ipywidgets primeiro para utilizar a estrutura do Jupyter Widget.
import ipywidgets as widgetsUse a função exibir de nível superior para renderizar um widget ou deixar uma expressão do tipo widget na última linha da célula de código.
slider = widgets.IntSlider() display(slider)Execute a célula. O widget será exibido na área de saída.
slider = widgets.IntSlider() display(slider)
Use várias chamadas display() para renderizar a mesma instância de widget várias vezes. Eles permanecem em sincronia uns com os outros.
slider = widgets.IntSlider() display(slider) display(slider)
Para renderizar dois widgets independentes, crie duas instâncias de widget:
slider1 = widgets.IntSlider() slider2 = widgets.IntSlider() display(slider1) display(slider2)



Widgets com suporte
| Tipo de widgets | Widgets |
|---|---|
| Widgets numéricos | IntSlider, FloatSlider, FloatLogSlider, IntRangeSlider, FloatRangeSlider, IntProgress, FloatProgress, BoundedIntText, BoundedFloatText, IntText, FloatText |
| Widgets boolianas | ToggleButton, Checkbox, Válido |
| Widgets de seleção | Menu suspenso, Botões de opção, Selecionar, Controle deslizante de seleção, Controle deslizante de intervalo de seleção, Botões de alternância, Seleção múltipla |
| Widgets de texto | Texto, Área de texto, Combobox, Senha, Rótulo, HTML, HTML Math, Imagem, Botão |
| Widgets de reprodução (animação) | Seletor de data, Seletor de cor, Controlador |
| Widgets de contêiner ou de layout | Box, HBox, VBox, GridBox, Acordeão, Abas, Empilhado |
Limitações conhecidas
Ainda não há suporte para os seguintes widgets. As seguintes soluções alternativas estão disponíveis:
Funcionalidade Solução alternativa Widget Saída Em vez disso, é possível utilizar a função print() para escrever texto no stdout. widgets.jslink() É possível utilizar a função widgets.link() para vincular dois widgets semelhantes. Widget FileUpload Ainda não há suporte. A função de exibição de global do Fabric não dá suporte à exibição de vários widgets em uma chamada (por exemplo, display(a, b)). Esse comportamento é diferente da função de exibição do IPython.
Caso feche um notebook que contenha um widget IPython, não poderá conferir ou interagir com ele até executar a célula correspondente novamente.
Não há suporte para a função de interação (ipywidgets.interact).
Integrar um notebook
Designar uma célula de parâmetros
Para parametrizar o notebook, selecione as elipses (...) para acessar os comandos Mais na barra de ferramentas da célula. Em seguida, selecione Alternar célula de parâmetro para designar a célula como a célula de parâmetros.

A célula de parâmetros é utilizada para integrar um notebook em um pipeline. A atividade do pipeline procura a célula de parâmetros e trata essa célula como padrão para os parâmetros passados no tempo de execução. O mecanismo de execução adiciona uma nova célula abaixo da célula de parâmetros com parâmetros de entrada para substituir os valores padrão.
Atribuir valores de parâmetros de um pipeline
Após criar um notebook com parâmetros, você poderá executá-lo a partir de um pipeline com a atividade do notebook do Fabric. Após adicionar a atividade à tela do pipeline, você poderá definir os valores dos parâmetros na seção Parâmetros de base da guia Configurações.

Ao atribuir valores de parâmetro, use a linguagem de expressão de pipeline ou funções e variáveis.
Os parâmetros do notebook dão suporte a tipos simples, como int, floate boolstring. Tipos complexos, como list e dict ainda não têm suporte. Para passar um tipo complexo, considere serializá-lo para um formato de cadeia de caracteres (por exemplo, JSON) e, em seguida, desserializá-lo dentro do notebook. O exemplo a seguir mostra como passar uma cadeia de caracteres JSON do pipeline para o notebook e desserializá-la:

O código python a seguir demonstra como desserializar a cadeia de caracteres JSON em um dicionário Python:
import json
# Deserialize the JSON string into a Python dictionary
params = json.loads(json_string)
# Access the individual parameters
param1 = params.get("param1")
param2 = params.get("param2")
Verifique se o nome do parâmetro na célula de código do parâmetro corresponde ao nome do parâmetro no pipeline.
Comando magic de configuração de sessão do Spark
Personalize sua sessão do Spark com o comando magic %%configure. O notebook do Fabric dá suporte a vCores personalizados, Memória do Driver e Executor, propriedades do Apache Spark, pontos de montagem, pool e o lakehouse padrão da sessão de notebook. Eles podem ser usados em atividades interativas de notebook e notebook de pipeline. É recomendável que você execute o comando %%configure no início do notebook ou reinicie a sessão do Spark para que as configurações entrem em vigor.
%%configure
{
// You can get a list of valid parameters to config the session from https://github.com/cloudera/livy#request-body.
"driverMemory": "28g", // Recommended values: ["28g", "56g", "112g", "224g", "400g"]
"driverCores": 4, // Recommended values: [4, 8, 16, 32, 64]
"executorMemory": "28g",
"executorCores": 4,
"jars": ["abfs[s]: //<file_system>@<account_name>.dfs.core.windows.net/<path>/myjar.jar", "wasb[s]: //<containername>@<accountname>.blob.core.windows.net/<path>/myjar1.jar"],
"conf":
{
// Example of customized property, you can specify count of lines that Spark SQL returns by configuring "livy.rsc.sql.num-rows".
"livy.rsc.sql.num-rows": "3000",
"spark.log.level": "ALL"
},
"defaultLakehouse": { // This overwrites the default lakehouse for current session
"name": "<lakehouse-name>",
"id": "<(optional) lakehouse-id>",
"workspaceId": "<(optional) workspace-id-that-contains-the-lakehouse>" // Add workspace ID if it's from another workspace
},
"mountPoints": [
{
"mountPoint": "/myMountPoint",
"source": "abfs[s]://<file_system>@<account_name>.dfs.core.windows.net/<path>"
},
{
"mountPoint": "/myMountPoint1",
"source": "abfs[s]://<file_system>@<account_name>.dfs.core.windows.net/<path1>"
},
],
"environment": {
"id": "<environment-id>",
"name": "<environment-name>"
},
"sessionTimeoutInSeconds": 1200,
"useStarterPool": false, // Set to true to force using starter pool
"useWorkspacePool": "<workspace-pool-name>"
}
Observação
- É recomendável que você defina o mesmo valor para “DriverMemory” e “ExecutorMemory” em %%configure. Os valores de “driverCores” e “executorCores” também devem ser os mesmos.
- O "defaultLakehouse" substituirá sua lakehouse fixada no gerenciador de Lakehouse, mas isso só funciona em sua sessão de notebook atual.
- Você pode usar %%configure em pipelines do Fabric, mas se ele não estiver definido na primeira célula de código, a execução do pipeline falhará devido a não conseguir reiniciar a sessão.
- O %%configure usado em notebookutils.notebook.run é ignorado, mas quando usado em %run, o notebook continua executando.
- As propriedades de configuração padrão do Spark precisam ser usadas no corpo de "conf". O Fabric não dá suporte à referência de primeiro nível para as propriedades de configuração do Spark.
- Algumas propriedades especiais do Spark, incluindo “spark.driver.cores”, “spark.executor.cores”, “spark.driver.memory”, “spark.executor.memory” e “spark.executor.instances” não entrarão em vigor no corpo de “conf”.
Você também pode usar o %%configure comando magic para injetar dinamicamente valores de configuração da Biblioteca de Variáveis em seu notebook.
%%configure
{
"defaultLakehouse": {
"name": {
"variableName": "$(/**/myVL/LHname)"
},
"id": {
"variableName": "$(/**/myVL/LHid)"
},
"workspaceId": {
"variableName": "$(/**/myVL/WorkspaceId)"
}
}
}
Neste exemplo:
-
myVLé o nome da Biblioteca de Variáveis. -
LHname,LHideWorkspaceIdsão chaves variáveis definidas na biblioteca. - Todas as variáveis devem ser definidas como tipo de cadeia de caracteres na biblioteca de variáveis, mesmo para valores GUID.
- Isso
workspaceIdé necessário quando o lakehouse está em um espaço de trabalho diferente do notebook atual. - Esses valores são resolvidos em runtime dependendo do ambiente ativo (por exemplo, Desenvolvimento, Teste, Prod).
Isso permite que você alterne configurações como o lakehouse padrão sem modificar o código do notebook.
Configuração de sessão parametrizada de um pipeline
A configuração de sessão parametrizada permite substituir o valor do magic %%configure pelos parâmetros de atividade de notebook de execução de pipeline Ao preparar a célula de código %%configure, você pode substituir os valores padrão (também configuráveis, 4 e "2000" no exemplo abaixo) por um objeto como este:
{
"parameterName": "paramterNameInPipelineNotebookActivity",
"defaultValue": "defaultValueIfNoParamterFromPipelineNotebookActivity"
}
%%configure
{
"driverCores":
{
"parameterName": "driverCoresFromNotebookActivity",
"defaultValue": 4
},
"conf":
{
"livy.rsc.sql.num-rows":
{
"parameterName": "rows",
"defaultValue": "2000"
}
}
}
Um notebook usa o valor padrão se você executar um notebook diretamente no modo interativo ou se a atividade do notebook do pipeline não fornecer nenhum parâmetro que corresponder a “activityParameterName”.
Durante uma execução de pipeline, defina as configurações de atividade do notebook de pipeline da seguinte maneira:

Caso deseje alterar a configuração da sessão, o nome dos parâmetros da atividade de notebook do pipeline deve ser o mesmo que parameterName no notebook. Neste exemplo de execução de um pipeline, driverCores em %%configure são substituídos por 8 e livy.rsc.sql.num-rows são substituídos por 4000.
Observação
- Se uma execução de pipeline falhar porque você usou o comando mágico %%configure, encontre mais informações sobre o erro executando a célula com o comando mágico %%configure no modo interativo do notebook.
- As execuções agendadas do notebook não dão suporte à configuração de sessão parametrizada.
Registro em log do Python em um notebook
É possível encontrar os logs do Python e definir diferentes níveis e formatos de log, como o código de exemplo mostrado aqui:
import logging
# Customize the logging format for all loggers
FORMAT = "%(asctime)s - %(name)s - %(levelname)s - %(message)s"
formatter = logging.Formatter(fmt=FORMAT)
for handler in logging.getLogger().handlers:
handler.setFormatter(formatter)
# Customize log level for all loggers
logging.getLogger().setLevel(logging.INFO)
# Customize the log level for a specific logger
customizedLogger = logging.getLogger('customized')
customizedLogger.setLevel(logging.WARNING)
# logger that use the default global log level
defaultLogger = logging.getLogger('default')
defaultLogger.debug("default debug message")
defaultLogger.info("default info message")
defaultLogger.warning("default warning message")
defaultLogger.error("default error message")
defaultLogger.critical("default critical message")
# logger that use the customized log level
customizedLogger.debug("customized debug message")
customizedLogger.info("customized info message")
customizedLogger.warning("customized warning message")
customizedLogger.error("customized error message")
customizedLogger.critical("customized critical message")
Exibir o histórico de comandos de entrada
O notebook do Fabric suporta o comando mágico %history para imprimir o histórico de comandos de entrada executados na sessão atual. Em comparação com o comando padrão do Jupyter Ipython, %history suporta um contexto de várias linguagens no notebook.
%history [-n] [range [range ...]]
Para opções:
- -n: imprime o número de execução.
No qual o intervalo pode ser:
- N: imprime o código da N-ésima célula executada.
- M-N: imprimir código de Mth para Nth célula executada.
Exemplo:
- Imprimir o histórico de entrada da 1ª para a 2ª célula executada:
%history -n 1-2
Teclas de atalho
Semelhante aos notebooks Jupyter, os notebooks Fabric têm uma interface de usuário modal. O teclado faz coisas diferentes, dependendo de em qual modo a célula do notebook está. Os notebooks do Fabric suportam os dois modos a seguir para uma determinada célula de código: modo de comando e modo de edição.
Uma célula está no modo Comando quando não existe um cursor de texto solicitando que você digite. Quando uma célula está no modo de comando, você pode editar o notebook como um todo, mas não pode digitar em células individuais. Insira o modo Comando pressionando ESC ou utilizando o mouse para selecionar fora da área do editor de uma célula.

O modo de edição pode ser indicado por um cursor de texto solicitando que você digite na área do editor. Quando uma célula está no modo Editar, você pode digitar na célula. Insira o modo Edição pressionando Enter ou utilizando o mouse para selecionar a área do editor de uma célula.



Teclas de atalho no modo de comando
| Ação | Atalhos do Notebook |
|---|---|
| Executar a célula atual e selecionar abaixo | Shift+Enter |
| Executar a célula atual e inserir abaixo | Alt+Enter |
| Executar a célula atual | Ctrl+Enter |
| Selecionar célula acima | Para cima |
| Selecionar célula abaixo | Para baixo |
| Selecionar célula anterior | K |
| Selecionar próxima célula | J |
| Inserir célula acima | Um |
| Inserir célula abaixo | B |
| Excluir células selecionadas | D,D |
| Mudar para o modo de edição | Entrar |
Teclas de atalho no modo de edição
Utilizando os seguintes atalhos de teclas, é possível navegar e executar facilmente o código nos notebooks do Fabric quando estiver no modo de edição.
| Ação | Atalhos do Notebook |
|---|---|
| Mover o cursor para cima | Para cima |
| Mover o cursor para baixo | Para baixo |
| Desfazer | CTRL+Z |
| Refazer | Ctrl+Y |
| Comentar ou Descomentar | Ctrl+/ Comentar: Ctrl + K + C Descomentar: Ctrl + K + U |
| Excluir palavra anterior | Ctrl+Backspace |
| Excluir palavra seguinte | Ctrl+Delete |
| Ir para o início da célula | Ctrl+Home |
| Ir para o final da célula | Ctrl+End |
| Ir uma palavra para a esquerda | CTRL+Seta para a esquerda |
| Ir uma palavra para a direita | CTRL+Seta para a direita |
| Selecionar tudo | CTRL+A |
| Recuar | Ctrl+] |
| Desfazer recuo | Ctrl+[ |
| Alternar para o modo de comando | Esc |
Para localizar todas as teclas de atalho, selecione Exibir na faixa de opções do bloco de anotações e selecione Configurações de teclas.