Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Este artigo descreve como configurar o formato XML no pipeline de dados do Data Factory no Microsoft Fabric.
Funcionalidades com suporte
O formato XML tem suporte para as seguintes atividades e conectores como origem.
| Categoria | Conector/Atividade |
|---|---|
| Conector compatível | Amazon S3 |
| Amazon S3 Compatible | |
| Armazenamento de Blobs do Azure | |
| Azure Data Lake Storage Gen1 | |
| Azure Data Lake Storage Gen2 | |
| Arquivos do Azure | |
| Sistema de arquivos | |
| FTP | |
| Google Cloud Storage | |
| HTTP | |
| Arquivos do Lakehouse | |
| Oracle Cloud Storage | |
| SFTP | |
| Atividade com suporte | atividade Copy (fonte/-) |
| Atividade de pesquisa | |
| Atividade GetMetadata | |
| Excluir atividade |
Formato XML na atividade de cópia
Para configurar o formato XML, escolha sua conexão na origem da atividade de cópia do pipeline de dados e selecione XML na lista suspensa de formato de arquivo. Selecione Configurações para configuração adicional desse formato.
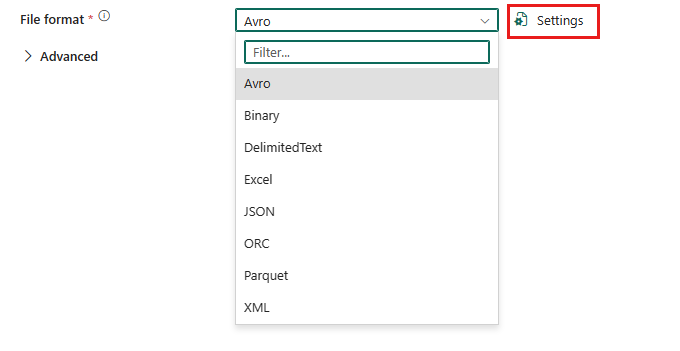
XML como origem
Depois de selecionar Configurações na seção Formato de arquivo, as seguintes propriedades são mostradas na caixa de diálogo pop-up Configurações de formato de arquivo.
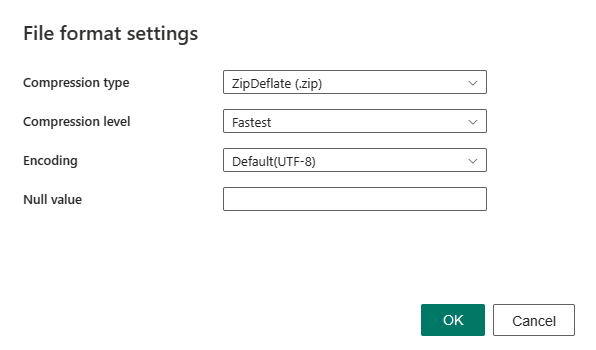
Tipo de compactação: o codec de compactação usado para ler arquivos XML. Você pode escolher entre os tipos nenhum, bzip2, gzip, deflate, ZipDeflate, TarGZip ou tar na lista suspensa.
Se você selecionar ZipDeflate como tipo de compactação, Preservar o nome do arquivo zip como pasta aparecerá em Configurações avançadas na guia Origem.
- Preservar o nome do arquivo zip como pasta: indica se o nome do arquivo zip de origem deve ser preservado como estrutura de pasta durante a cópia.
- Se essa caixa estiver marcada (padrão), o serviço gravará arquivos descompactados em
<specified file path>/<folder named as source zip file>/. - Se essa caixa estiver desmarcada, o serviço gravará arquivos descompactados diretamente em
<specified file path>. Verifique se não há nomes de arquivo duplicados nos arquivos zip de origem diferentes para evitar a corrida ou comportamento inesperado.
- Se essa caixa estiver marcada (padrão), o serviço gravará arquivos descompactados em
Se você selecionar TarGZip/tar como o tipo de compactação, Preservar o nome do arquivo de compactação como pasta será exibido nas configurações Avançadas na guia Origem.
- Preservar o nome do arquivo compactado como pasta: indica se o nome do arquivo compactado de origem deve ser preservado como estrutura de pasta durante a cópia.
- Se essa caixa estiver marcada (padrão), o serviço gravará arquivos descompactados em
<specified file path>/<folder named as source compressed file>/. - Se essa caixa estiver desmarcada, o serviço gravará arquivos descompactados diretamente em
<specified file path>. Verifique se não há nomes de arquivo duplicados nos arquivos de origem diferentes para evitar a corrida ou comportamento inesperado.
- Se essa caixa estiver marcada (padrão), o serviço gravará arquivos descompactados em
- Preservar o nome do arquivo zip como pasta: indica se o nome do arquivo zip de origem deve ser preservado como estrutura de pasta durante a cópia.
Nível de compactação: especifique a taxa de compactação ao selecionar um tipo de compactação. Você pode escolher entre Mais Rápido ou Ideal.
- Mais rápida: a operação de compactação deve ser concluída o mais rápido possível, mesmo se o arquivo resultante não for compactado da maneira ideal.
- Ideal: a operação de compactação deve ser concluída da maneira ideal, mesmo se a operação demorar mais tempo para ser concluída. Para saber mais, veja o tópico Nível de compactação .
Codificação: o tipo de codificação usado para gravar arquivos de teste. Selecione um tipo na lista suspensa. O valor padrão é UTF-8.
Valor nulo: Especifica a representação em cadeia do valor nulo. O valor padrão pode ser uma cadeia de caracteres vazia.
Nas configurações Avançadas na guia Origem, as seguintes propriedades relacionadas ao formato XML são exibidas.
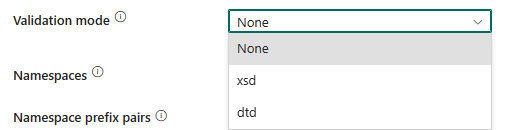
Modo de validação: especifica se o esquema XML deve ser validado. Selecione um modo na lista suspensa.
- Nenhum: selecione isso para não usar o modo de validação.
- xsd: selecione isso para validar o esquema XML usando XSD.
- dtd: selecione isso para validar o esquema XML usando DTD.
Namespaces: especifique se o namespace deve ser habilitado ao analisar os arquivos XML. Ele é selecionado por padrão.
Pares de prefixo de namespace: se os Namespaces estiverem habilitados, selecione + Novo e especifique a URL e o Prefixo. Você pode adicionar mais pares selecionando + Novo.
O URI do namespace para mapeamento de prefixo é usado para nomear campos ao analisar o arquivo XML. Se um arquivo XML tiver namespace e o namespace estiver habilitado, por padrão, o nome do campo será o mesmo que no documento XML. Se houver um item definido para o URI do namespace neste mapa, o nome do campo seráprefix:fieldName.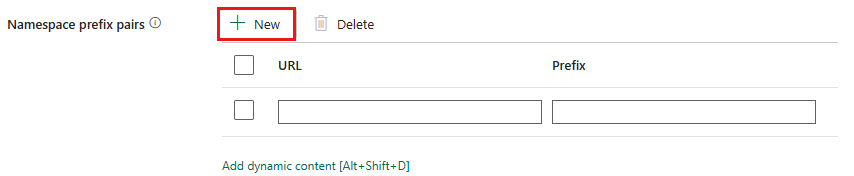
Detectar tipo de dados: especifique se os tipos de dados inteiro, duplo e booliano devem ser detectados. Ele é selecionado por padrão.
Resumo da tabela
XML como origem
As propriedades a seguir têm suporte na seção Origem da atividade de cópia ao usar o formato XML.
| Nome | Descrição | Valor | Obrigatório | Propriedade de script JSON |
|---|---|---|---|---|
| Formato de arquivo | O formato de arquivo que você deseja usar. | XML | Sim | tipo (em datasetSettings):Xml |
| Tipo de compactação | O codec de compactação usado para ler arquivos XML. | Nenhum bzip2 gzip deflate ZipDeflate TarGZip tar |
Não | tipo (em compression):bzip2 gzip deflate ZipDeflate TarGZip tar |
| Nível de compactação | A taxa de compactação. | Fastest Ideal |
Nenhum | nível (em compression):Fastest Ideal |
| Codificação | O tipo de codificação usado para ler arquivos de teste. | "UTF-8" (por padrão),"UTF-8 sem BOM", "UTF-16LE", "UTF-16BE", "UTF-32LE", "UTF-32BE", "US-ASCII", "UTF-7", "BIG5", "EUC-JP", "EUC-KR", "GB2312", "GB18030", "JOHAB", "SHIFT-JIS", "CP875", "CP866", "IBM00858", "IBM037", "IBM273", "IBM437", "IBM500", "IBM737", "IBM775", "IBM850", "IBM852", "IBM855", "IBM857", "IBM860", "IBM861", "IBM863", "IBM864", "IBM865", "IBM869", "IBM870", "IBM01140", "IBM01141", "IBM01142", "IBM01143", "IBM01144", "IBM01145", "IBM01146", "IBM01147", "IBM01148", "IBM01149", "ISO-2022-JP", "ISO-2022-KR", "ISO-8859-1", "ISO-8859-2", "ISO-8859-3", "ISO-8859-4", "ISO-8859-5", "ISO-8859-6", "ISO-8859-7", "ISO-8859-8", "ISO-8859-9", "ISO-8859-13", "ISO-8859-15", "WINDOWS-874", "WINDOWS-1250", "WINDOWS-1251", "WINDOWS-1252", "WINDOWS-1253", "WINDOWS-1254", "WINDOWS-1255", "WINDOWS-1256", "WINDOWS-1257", "WINDOWS-1258" | Nenhum | encodingName |
| Preservar o nome do arquivo zip como pasta | Indica se o nome do arquivo zip de origem deve ser preservado como estrutura de pastas durante a cópia. | Selecionado (padrão) ou não selecionado. | Não | preserveZipFileNameAsFolder (em compressionProperties->type como ZipDeflateReadSettings):true (padrão) ou false |
| Preservar o nome do arquivo de compactação como pasta | Indica se o nome do arquivo zip de origem deve ser preservado como estrutura de pastas durante a cópia. | Selecionado (padrão) ou não selecionado. | Não | preserveCompressionFileNameAsFolder (em compressionProperties->type como TarGZipReadSettings ou TarReadSettings):true (padrão) ou false |
| Valor nulo | A representação em cadeia de caracteres do valor nulo. | <seu valor nulo> cadeia de caracteres vazia (por padrão) |
Nenhum | nullValue |
| Modo de validação | Se o esquema XML deve ser validado. | Nenhum xsd dtd |
Não | validationMode: xsd dtd |
| Namespaces | Se é para habilitar o namespace ao analisar os arquivos XML. | Selecionado (padrão) ou não selecionado | Não | namespaces: true (padrão) ou false |
| Pares de prefixo de namespace | URI do namespace para mapeamento de prefixo, que é usada para nomear campos ao analisar o arquivo XML. Se um arquivo XML tiver namespace e o namespace estiver habilitado, por padrão, o nome do campo será o mesmo que no documento XML. Se houver um item definido para o URI do namespace neste mapa, o nome do campo será prefix:fieldName. |
< url >:< prefixo > | Não | namespacePrefixes: < url >:< prefixo > |
| Detectar tipo de dados | Se os tipos de dados inteiro, duplo e booliano devem ser detectados. | Selecionado (padrão) ou não selecionado | Não | detectDataType: true (padrão) ou false |