Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Aplica-se a:✅Warehouse no Microsoft Fabric
Neste artigo, você aprenderá a usar a atividade de cópia em pipelines do Data Factory.
- Os pipelines oferecem uma alternativa ao uso do comando COPY através de uma interface gráfica de usuário.
- Um pipeline é um agrupamento lógico de atividades que, juntos, executam uma tarefa de ingestão de dados.
- Os pipelines permitem que você gerencie todas as atividades de ETL (extração, transformação e carregamento) em um só lugar, em vez de gerenciar cada uma individualmente.
Observação
Alguns recursos do Azure Data Factory não estão disponíveis no Microsoft Fabric. No entanto, os conceitos são intercambiáveis. Você pode saber mais sobre o Azure Data Factory e pipelines em Pipelines e atividades no Azure Data Factory e no Azure Synapse Analytics. Para obter um início rápido, consulte Início Rápido: Criar seu primeiro pipeline para copiar dados.
Criar um trabalho de cópia
Para criar um novo trabalho de cópia, siga estas etapas.
Na tela inicial do workspace, selecione o botão + Novo item . Na seção Obter dados , selecione Copiar trabalho.
Na caixa de diálogo Novo trabalho de cópia , insira um nome para o novo pipeline e selecione Criar. A nova janela Copiar tarefa abre.
Escolha sua fonte de dados no catálogo do OneLake.
Na página Escolher dados , visualize o conjunto de dados selecionado. Depois de examinar os dados, selecione Avançar.
Na página Escolher destino de dados , selecione o warehouse desejado no catálogo do OneLake.
A página Escolher o modo de trabalho de cópia permite que você configure como deseja que os dados sejam copiados: uma cópia completa ou cópias incrementais que executam apenas cópias subsequentes quando os dados de origem são alterados.
Por enquanto, selecione Cópia completa. Para outras fontes de dados e cenários, você pode carregar dados incrementalmente conforme a fonte de dados é atualizada.
Você pode ajustar as tabelas de destino com o nome do esquema de destino desejado e o nome da tabela. Forneça nomes de esquema e tabela que correspondam à convenção de nomenclatura desejada. Quando terminar de fazer alterações, selecione Avançar.
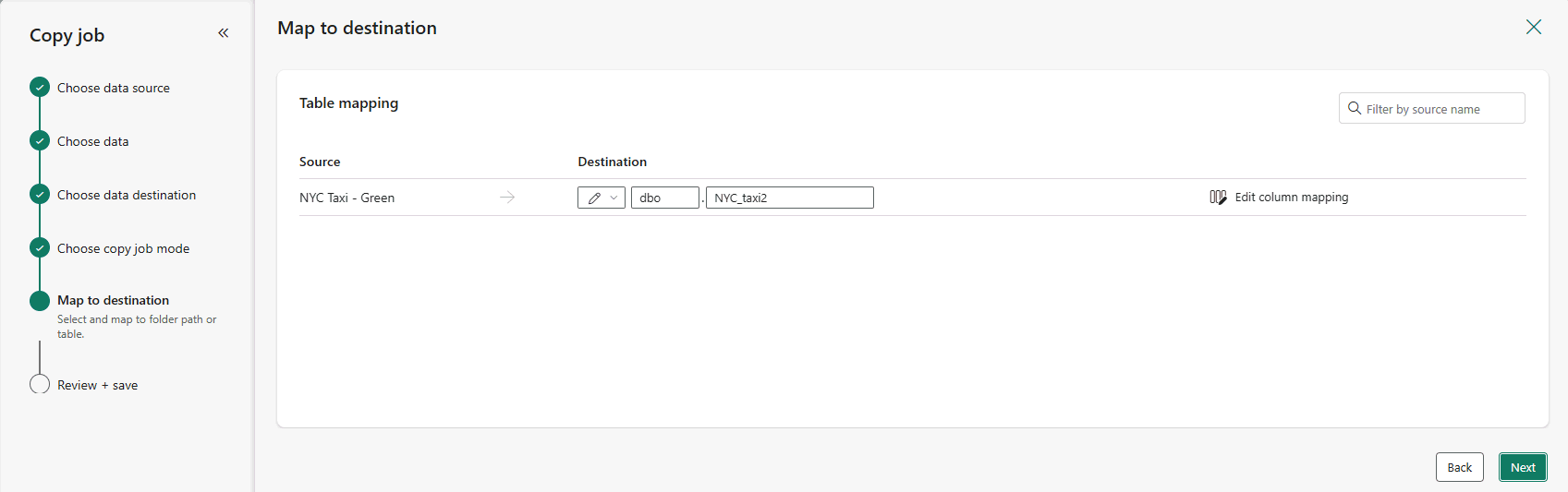
Opcionalmente, para modificar os mapeamentos de coluna, selecione Editar mapeamento de coluna. Você pode mapear nomes de coluna de origem para novos nomes, tipos de dados ou ignorar colunas de coluna de origem.
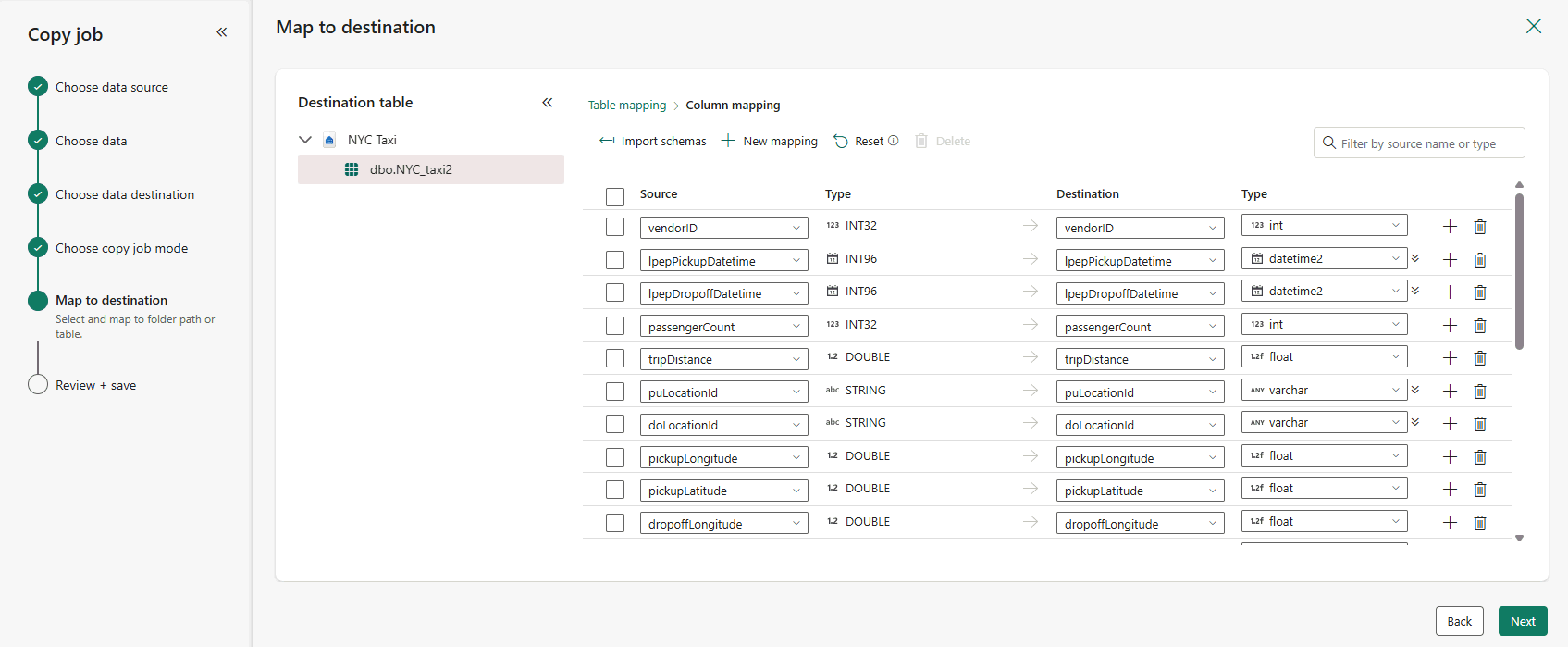
Quando terminar de revisar os mapeamentos de coluna, selecione Avançar.
A página Revisar + salvar é um resumo do novo trabalho de Cópia.
Examine o resumo e as opções e selecione Salvar + Executar.
Você é direcionado para a área de tela do pipeline, em que uma nova atividade de trabalho de Cópia com sua Origem e Destino já está configurada para você. Se você selecionou Iniciar transferência de dados imediatamente na página anterior, o trabalho de cópia será iniciado assim que estiver pronto para ser executado.
Você pode monitorar o status do pipeline no painel Resultados .
Após alguns segundos, o pipeline será concluído com sucesso. Ao navegar de volta para o seu armazém, você pode selecionar sua tabela para visualizar os dados e confirmar se a operação de cópia foi concluída.


Próxima etapa
Opções de ingestão de dados
Outras maneiras de ingerir dados em seu warehouse incluem:
- Ingerir dados usando a instrução COPY
- Ingerir dados usando Transact-SQL
- Ingerir dados usando um fluxo de dados