Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Este artigo apresenta a arquitetura medallion lake e descreve como você pode implementar o padrão de projeto no Microsoft Fabric. Ele é direcionado a vários públicos-alvo:
- Engenheiros de dados: Equipe técnica que projeta, cria e mantém infraestruturas e sistemas que permitem que sua organização colete, armazene, processe e analise grandes volumes de dados.
- Equipes do Centro de Excelência, TI e BI: As equipes responsáveis por supervisionar a análise em toda a organização.
- Administradores de Fabric: Os administradores responsáveis por supervisionar o Fabric na organização.
A arquitetura de lakehouse medallion, comumente conhecida como arquitetura medallion, é um padrão de design usado por organizações para organizar logicamente os dados em um lakehouse. É a abordagem de design recomendada para o Fabric. Como o OneLake é o data lake do Fabric, a arquitetura medallion é implementada por meio da criação de lakehouses no OneLake.
A arquitetura medallion é composta por três camadas distintas, também chamadas de zonas. As três camadas de medalhão são: bronze (dados brutos), prata (dados validados) e ouro (dados enriquecidos). Cada camada indica a qualidade dos dados armazenados no lakehouse, com níveis mais altos representando maior qualidade. Essa abordagem de várias camadas ajuda você a criar uma única fonte de verdade para produtos de dados corporativos.
É importante ressaltar que a arquitetura de medalhão garante atomicidade, consistência, isolamento e durabilidade (ACID) à medida que os dados progridem pelas camadas. Seus dados começam em sua forma bruta e, em seguida, uma série de validações e transformações prepara os dados para otimizá-los para análise eficiente, mantendo também as cópias originais como uma fonte confiável.
Para obter mais informações, confira O que é a arquitetura lakehouse medallion?.
Arquitetura medallion no Fabric
O objetivo da arquitetura medallion é melhorar de forma incremental e progressiva a estrutura e a qualidade dos dados à medida que avança em cada estágio.
A arquitetura medallion é composta por três camadas (ou zonas) distintas.
- Bronze: Também chamada de zona bruta, essa primeira camada armazena dados de origem em seu formato original, incluindo tipos de dados não estruturados, semiestruturados ou estruturados. Os dados nessa camada normalmente são somente de acréscimo e imutáveis. Preservando os dados brutos na camada bronze, você mantém uma fonte de verdade e habilita o reprocessamento e a auditoria no futuro.
- Prata: Também chamada de zona enriquecida, essa camada armazena dados provenientes da camada bronze. Os dados são limpos e padronizados e agora são estruturados como tabelas (linhas e colunas). Ele também pode ser integrado a outros dados para fornecer uma exibição empresarial de todas as entidades de negócios, como clientes, produtos e muito mais.
- Ouro: Também chamada de zona curada, essa camada final armazena dados provenientes da camada prata. Os dados são refinados para atender a requisitos específicos de análise e negócios downstream. As tabelas normalmente estão em conformidade com o star schema design, que dá suporte ao desenvolvimento de modelos de dados otimizados para desempenho e usabilidade.
Cada zona deve ser separada em seu próprio lakehouse ou data warehouse no OneLake, com dados se movendo entre as zonas à medida que são transformados e refinados.
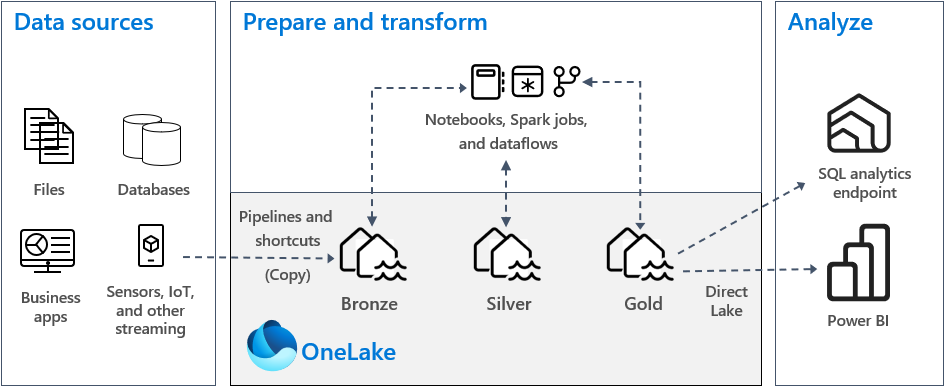
Em uma implementação típica de arquitetura medallion no Fabric, a zona bronze armazena os dados no mesmo formato que a fonte de dados. Quando a fonte de dados é um banco de dados relacional, as tabelas Delta são uma boa opção. As zonas prata e ouro devem conter tabelas Delta.
Dica
Para saber como criar um lakehouse, siga o tutorial Cenário de ponta a ponta do Lakehouse.
OneLake e lakehouse no Fabric
A base de um data warehouse moderno é um data lake. O Microsoft OneLake é um data lake único, unificado e lógico para toda a sua organização. Ele é provisionado automaticamente com cada locatário do Fabric e é o único local para todos os seus dados de análise.
Você pode usar o OneLake para:
- Remover silos e reduzir o esforço de gerenciamento. Todos os dados organizacionais são armazenados, gerenciados e protegidos em um recurso do data lake.
- Reduzir a movimentação e a duplicação de dados. O objetivo do OneLake é armazenar apenas uma cópia de dados. Menos cópias de dados resultam em menos processos de movimentação de dados e isso gera ganhos de eficiência e redução na complexidade. Use atalhos para fazer referência aos dados armazenados em outros locais, em vez de copiá-los para o OneLake.
- Usar com vários mecanismos analíticos. Os dados no OneLake são armazenados em um formato aberto. Dessa forma, os dados podem ser consultados por vários mecanismos analíticos, incluindo o Analysis Services (usado pelo Power BI), o T-SQL e o Apache Spark. Outros aplicativos não Fabric também podem usar APIs e SDKs para acessar o OneLake .
Para armazenar dados no OneLake, crie um lakehouse no Fabric. Um lakehouse é uma plataforma de arquitetura de dados para armazenar, gerenciar e analisar dados estruturados e não estruturados em um único local. Ele pode ser dimensionado para grandes volumes de dados de todos os tipos e tamanhos de arquivos e, como os dados são armazenados em um único local, eles podem ser compartilhados e reutilizados em toda a organização.
Cada lakehouse tem um ponto de extremidade de análise de SQL interno que desbloqueia recursos de data warehouse sem a necessidade de mover dados. Isso significa que você pode consultar seus dados no lakehouse usando consultas SQL e sem nenhuma configuração especial.
Para obter mais informações, confira O que é um lakehouse no Microsoft Fabric?.
Tabelas e arquivos
Quando você cria um lakehouse no OneLake, dois locais de armazenamento físico são provisionados automaticamente:
- As tabelas são uma área gerenciada para armazenar tabelas de todos os formatos no Apache Spark (CSV, Parquet ou Delta). Todas as tabelas, criadas automaticamente ou explicitamente, são reconhecidas como tabelas no lakehouse. Todas as tabelas Delta, que são arquivos de dados Parquet com um log de transações baseado em arquivo, também são reconhecidas como tabelas.
- Os arquivos são uma área não gerenciada para armazenar dados em qualquer formato de arquivo. Todos os arquivos Delta armazenados nessa área não são reconhecidos automaticamente como tabelas. Se você quiser criar uma tabela em uma pasta Delta Lake na área não gerenciada, crie um atalho ou uma tabela externa com um local que aponte para a pasta não gerenciada que contém os arquivos Delta Lake no Apache Spark.
A principal distinção entre a área gerenciada (tabelas) e a área não gerenciada (arquivos) é o processo automático de descoberta e registro de tabela. Esse processo é executado em qualquer pasta criada apenas na área gerenciada, mas não na área não gerenciada.
Na zona bronze, você armazena dados em seu formato original, que podem ser tabelas ou arquivos. Se os dados de origem forem do OneLake, do Azure Data Lake Store Gen2 (ADLS Gen2), do Amazon S3 ou do Google, crie um atalho na zona bronze em vez de copiar os dados.
Nas zonas prata e ouro, normalmente você armazena dados em tabelas Delta. No entanto, você também pode armazenar dados em arquivos Parquet ou CSV. Se você fizer isso, deverá criar explicitamente um atalho ou uma tabela externa com um local que aponte para a pasta não gerenciada que contém os arquivos Delta Lake no Apache Spark.
No Microsoft Fabric, o Lakehouse Explorer fornece uma representação gráfica unificada de toda a Lakehouse para que os usuários naveguem, acessem e atualizem seus dados.
Para obter mais informações sobre a descoberta automática de tabelas, consulte Descoberta automática de tabela e registro.
Armazenamento do Delta Lake
O Delta Lake é uma camada de armazenamento otimizada que fornece a base para armazenar dados e tabelas. Ele dá suporte a transações ACID para cargas de trabalho de Big Data e, por esse motivo, é o formato de armazenamento padrão em um lakehouse do Fabric.
O Delta Lake oferece confiabilidade, segurança e desempenho no lakehouse para operações de streaming e em lote. Internamente, armazena dados no formato de arquivo Parquet, no entanto, também mantém logs de transações e estatísticas que fornecem recursos e melhoria de desempenho em relação ao formato Parquet padrão.
O formato Delta Lake oferece os seguintes benefícios em comparação com formatos de arquivo genéricos:
- Suporte às propriedades ACID, especialmente a durabilidade para evitar dados corrompidos.
- Consultas de leitura mais rápidas.
- Aumento da atualização de dados.
- Suporte para cargas de trabalho em lote e streaming.
- Suporte à reversão de dados usando a viagem no tempo do Delta Lake.
- Conformidade regulatória avançada e auditoria usando o histórico de tabelas do Delta Lake.
O Fabric padroniza o formato de arquivo de armazenamento com o Delta Lake. Por padrão, cada mecanismo de carga de trabalho no Fabric cria tabelas Delta quando você grava dados em uma nova tabela. Para obter mais informações, consulte as tabelas Lakehouse e Delta Lake.
Modelo de implantação
Para implementar a arquitetura medallion no Fabric, você pode usar lakehouses (um para cada zona), um data warehouse ou uma combinação de ambos. Sua decisão deve ser baseada em sua preferência e na experiência de sua equipe. Com o Fabric, você pode usar diferentes mecanismos analíticos que funcionam em uma cópia de seus dados no OneLake.
Aqui estão dois padrões a serem considerados:
- Padrão 1: criar cada zona como um lakehouse. Nesse caso, os usuários empresariais acessam dados usando o ponto de extremidade de análise do SQL.
- Padrão 2: criar zonas bronze e prata como lakehouses e a zona ouro como data warehouse. Nesse caso, os usuários empresariais acessam dados usando o ponto de extremidade do data warehouse.
Embora você possa criar todas as lakehouses em um único workspace do Fabric, recomendamos que você crie cada lakehouse em seu próprio workspace separado. Essa abordagem fornece mais controle e melhor governança no nível da zona.
Para a zona bronze, recomendamos que você armazene os dados em seu formato original ou use Parquet ou Delta Lake. Sempre que possível, mantenha os dados em seu formato original. Se os dados de origem forem do OneLake, do Azure Data Lake Store Gen2 (ADLS Gen2), do Amazon S3 ou do Google, crie um atalho na zona bronze em vez de copiar os dados.
Para as zonas prata e ouro, recomendamos que você use tabelas Delta devido às funcionalidades extras e aos aprimoramentos de desempenho que elas fornecem. O Fabric padroniza no formato Delta Lake e, por padrão, cada mecanismo no Fabric grava dados nesse formato. Além disso, esses mecanismos usam a otimização de tempo de gravação do V-Order para o formato de arquivo Parquet. Essa otimização permite leituras rápidas por mecanismos de computação do Fabric, como Power BI, SQL, Apache Spark e outros. Para obter mais informações, consulte a otimização da tabela Delta Lake e o V-Order.
Por fim, hoje muitas organizações enfrentam um enorme crescimento nos volumes de dados, juntamente com uma necessidade crescente de organizar e gerenciar esses dados de forma lógica, facilitando o uso e a governança mais direcionados e eficientes. Isso pode fazer com que você estabeleça e gerencie uma organização de dados descentralizada ou federada com governança. Para atender a esse objetivo, considere implementar uma arquitetura de malha de dados. A malha de dados é um padrão de arquitetura que se concentra na criação de domínios de dados que oferecem dados como um produto.
Você pode criar uma arquitetura de malha de dados para seu patrimônio de dados no Fabric criando domínios de dados. Você pode criar domínios mapeados para seus domínios de negócios, por exemplo, marketing, vendas, inventário, recursos humanos e outros. Em seguida, você pode implementar a arquitetura medallion configurando zonas de dados em cada um de seus domínios. Para obter mais informações sobre domínios, consulte Domínios.
Compreender o armazenamento de dados da tabela Delta
Essa seção descreve outras diretrizes relacionadas à implementação de uma arquitetura de lakehouse medallion no Fabric.
Tamanho do arquivo
Geralmente, uma plataforma de Big Data tem um desempenho melhor quando tem alguns arquivos grandes em vez de muitos arquivos pequenos. A degradação de desempenho ocorre quando o mecanismo de computação tem muitos metadados e operações de arquivo para gerenciar. Para melhorar o desempenho da consulta, recomendamos que você vise arquivos de dados com aproximadamente 1 GB de tamanho.
O Delta Lake tem um recurso chamado otimização preditiva. A otimização preditiva automatiza as operações de manutenção para tabelas Delta. Quando esse recurso está habilitado, o Delta Lake identifica tabelas que se beneficiariam de operações de manutenção e otimizam seu armazenamento. Embora esse recurso também faça parte da excelência operacional e do trabalho de preparação de dados, o Fabric também pode otimizar arquivos de dados durante a gravação de dados. Para obter mais informações, consulte Otimização preditiva para Delta Lake.
Retenção histórica
Por padrão, o Delta Lake mantém um histórico de todas as alterações feitas, de modo que o tamanho dos metadados históricos cresce ao longo do tempo. Com base nos requisitos de negócios, mantenha os dados históricos apenas por um determinado período de tempo para reduzir os custos de armazenamento. Considere a retenção de dados históricos apenas para o último mês ou outro período apropriado.
Você pode remover dados históricos mais antigos de uma tabela Delta usando o comando VACUUM. No entanto, por padrão, você não pode excluir dados históricos nos últimos sete dias. Essa restrição mantém a consistência nos dados. Configure o número padrão de dias com a propriedade delta.deletedFileRetentionDuration = "interval <interval>"da tabela. Essa propriedade determina o período de tempo em que um arquivo deve ser excluído antes de ser considerado um candidato para uma operação de vácuo.
Partições de tabela
Ao armazenar dados em cada zona, recomendamos que você use uma estrutura de pasta particionada sempre que aplicável. Essa técnica melhora a capacidade de gerenciamento de dados e o desempenho da consulta. Em geral, dados particionados em uma estrutura de pastas resultam em uma pesquisa mais rápida por entradas de dados específicas devido à remoção/eliminação de partições irrelevantes.
Normalmente, você acrescenta dados à tabela de destino à medida que novos dados chegam. No entanto, em alguns casos, você pode mesclar dados porque precisa atualizar os dados existentes ao mesmo tempo. Nesse caso, você pode executar uma operação upsert usando o comando MERGE. Quando a tabela de destino for particionada, use um filtro de partição para acelerar a operação. Dessa forma, o mecanismo pode eliminar partições que não exigem atualização.
Acesso de dados
Planeje e controle quem precisa de acesso a dados específicos no lakehouse. Você também deve entender os vários padrões de transação que eles usarão ao acessar esses dados. Em seguida, você pode definir o esquema de particionamento de tabela correto e a ordenação de dados com índices de ordem Z do Delta Lake.
Conteúdo relacionado
Para obter mais informações sobre como implementar uma lakehouse do Fabric, consulte os recursos a seguir.
- Tutorial: Cenário de ponta a ponta do Lakehouse
- Tabelas Lakehouse e Delta Lake
- Guia de decisão do Microsoft Fabric: escolha um armazenamento de dados
- A necessidade de otimizar a gravação no Apache Spark
- Alguma dúvida? Tente perguntar à comunidade do Fabric.
- Sugestões? Contribua com ideias para melhorar o Fabric.