Diretrizes de recuperação de desastres específicas da experiência
Este documento fornece diretrizes específicas da experiência para recuperar seus dados do Fabric no caso de um desastre regional.
Cenário de exemplo
Várias das seções de diretrizes neste documento usam o seguinte cenário de amostra para fins de explicação e ilustração. Consulte esse cenário de volta conforme necessário.
Digamos que você tenha uma capacidade C1 na região A que tenha um espaço de trabalho W1. Se você tiver ativado a recuperação de desastres para a capacidade C1, os dados do OneLake serão replicados para um backup na região B. Se a região A sofrer interrupções, o serviço Fabric em C1 fará failover para a região B.
A imagem a seguir ilustra esse cenário. A caixa à esquerda mostra a região com interrupção. A caixa no meio representa a disponibilidade contínua dos dados após o failover, e a caixa à direita mostra a situação totalmente abordada após o cliente agir para restaurar a função total de seus serviços.
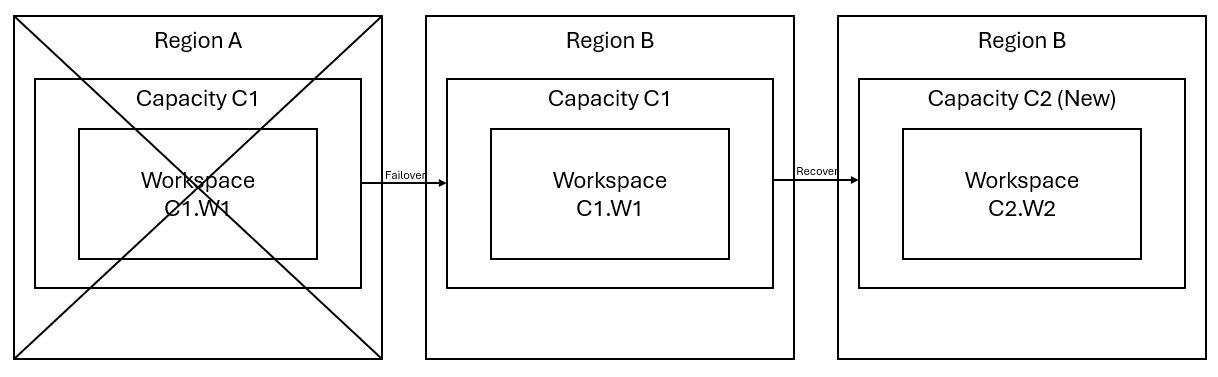
Este é o plano geral de recuperação:
Crie uma capacidade do Fabric C2 em uma nova região.
Criar um novo espaço de trabalho W2 em C2, incluindo seus itens correspondentes com os mesmos nomes que em C1.W1.
Copie os dados do C1.W1 interrompido para o C2.W2.
Siga as instruções dedicadas a cada componente para restaurar os itens em suas funções completas.
Planos de recuperação específicos da experiência
As seções a seguir fornecem guias passo a passo para cada experiência do Fabric para ajudar os clientes durante o processo de recuperação.
Engenharia de Dados
Este guia guiará você através dos procedimentos de recuperação para a experiência de engenharia de dados. Ele aborda lakehouses, Notebooks e definições de trabalho do Spark.
Lakehouse
Os Lakehouses da região original permanecem indisponíveis para os clientes. Para recuperar um Lakehouse, os clientes podem recriá-lo no espaço de trabalho C2.W2. Recomendamos duas abordagens para a recuperação de Lakehouses:
Abordagem 1: usar um script personalizado para copiar as tabelas e os arquivos Delta do Lakehouse
Os clientes podem recriar os lakehouses usando um script Scala personalizado.
Crie o Lakehouse (por exemplo, LH1) no espaço de trabalho recém-criado C2.W2.
Crie um novo Notebook no espaço de trabalho C2.W2.
Para recuperar as tabelas e os arquivos do Lakehouse original, você precisará usar o caminho ABFS para acessar os dados (consulte Conectando-se ao Microsoft OneLake). Você pode usar o exemplo de código abaixo (consulte Introdução aos utilitários do Microsoft Spark) no Notebook para obter os caminhos ABFS de arquivos e tabelas do lakehouse original. (Substitua C1.W1 pelo nome real do espaço de trabalho)
mssparkutils.fs.ls('abfs[s]://<C1.W1>@onelake.dfs.fabric.microsoft.com/<item>.<itemtype>/<Tables>/<fileName>')Use o exemplo de código a seguir para copiar tabelas e arquivos para a lakehouse recém-criada.
No caso das tabelas Delta, você precisa copiar uma tabela de cada vez para recuperar na nova lakehouse. No caso dos arquivos do Lakehouse, você pode copiar a estrutura de arquivos completa com todas as pastas subjacentes com uma única execução.
Entre em contato com a equipe de suporte para obter o carimbo de data/hora do failover requerido no script.
%%spark val source="abfs path to original Lakehouse file or table directory" val destination="abfs path to new Lakehouse file or table directory" val timestamp= //timestamp provided by Support mssparkutils.fs.cp(source, destination, true) val filesToDelete = mssparkutils.fs.ls(s"$source/_delta_log") .filter{sf => sf.isFile && sf.modifyTime > timestamp} for(fileToDelte <- filesToDelete) { val destFileToDelete = s"$destination/_delta_log/${fileToDelte.name}" println(s"Deleting file $destFileToDelete") mssparkutils.fs.rm(destFileToDelete, false) } mssparkutils.fs.write(s"$destination/_delta_log/_last_checkpoint", "", true)Uma vez executado o script, as tabelas aparecerão no novo Lakehouse.
Abordagem 2: usar o Gerenciador de Armazenamento do Microsoft Azure para copiar arquivos e tabelas
Para recuperar apenas tabelas ou arquivos do Lakehouse específicos do lakehouse original, use o Gerenciador de Armazenamento do Microsoft Azure. Consulte Integrar o OneLake com o Gerenciador de Armazenamento do Microsoft Azure para obter as etapas detalhadas. Para dados de grande dimensão, use Abordagem 1.
Observação
As duas abordagens descritas acima recuperam tanto os metadados quanto os dados tabelas formatadas em Delta, porque os metadados estão co-localizados e armazenados com os dados no OneLake. Para tabelas não Delta formatadas (por exemplo, CSV, Parquet, etc.) que forem criadas usando scripts/comandos da Linguagem de Definição de Dados do Spark (DDL) do Spark, o usuário é responsável pela manutenção e execução dos scripts/comandos DDL do Spark para recuperá-los.
Notebook
Os Notebooks da região primária permanecem indisponíveis para os clientes e o código nos Notebooks não será replicado para a região secundária. Para recuperar o código do Notebook na nova região, existem duas abordagens para recuperar o conteúdo do código do Notebook.
Abordagem 1: redundância gerenciada pelo usuário com integração do Git (em versão prévia pública)
A melhor maneira de tornar isso fácil e rápido é usar a integração com o Git do Fabric e sincronizar o Notebook com o repositório ADO. Após o failover do serviço para outra região, você poderá usar o repositório para recompilar o Notebook no novo espaço de trabalho criado.
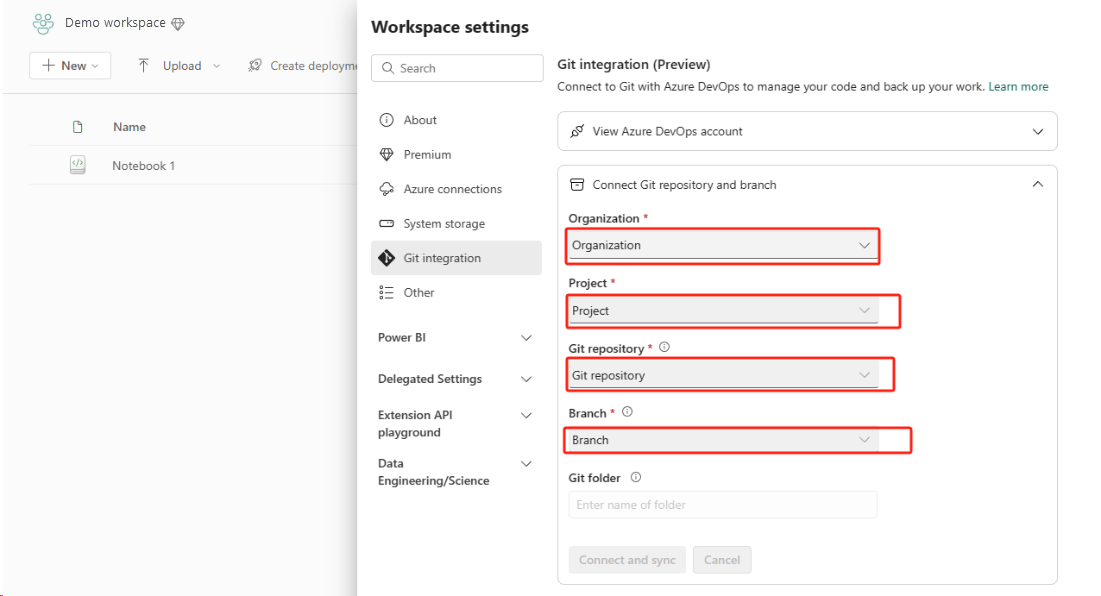
Configure a integração do Git e selecione Conectar e sincronizar com o repositório ADO.
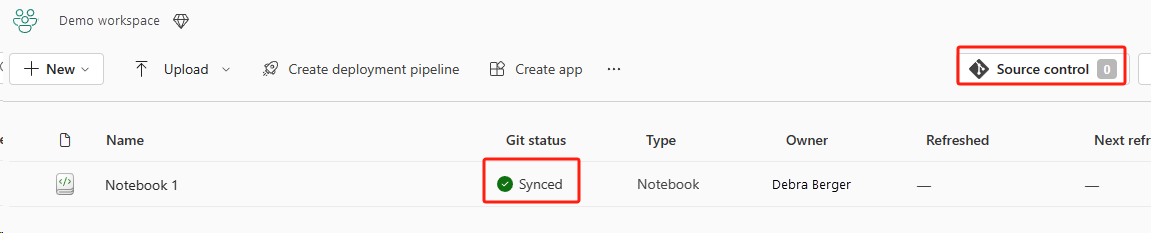
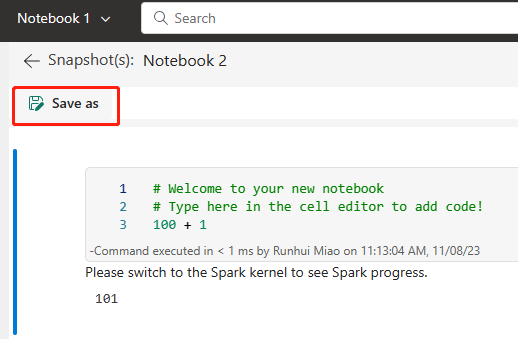
A imagem a seguir mostra o Notebook sincronizado.
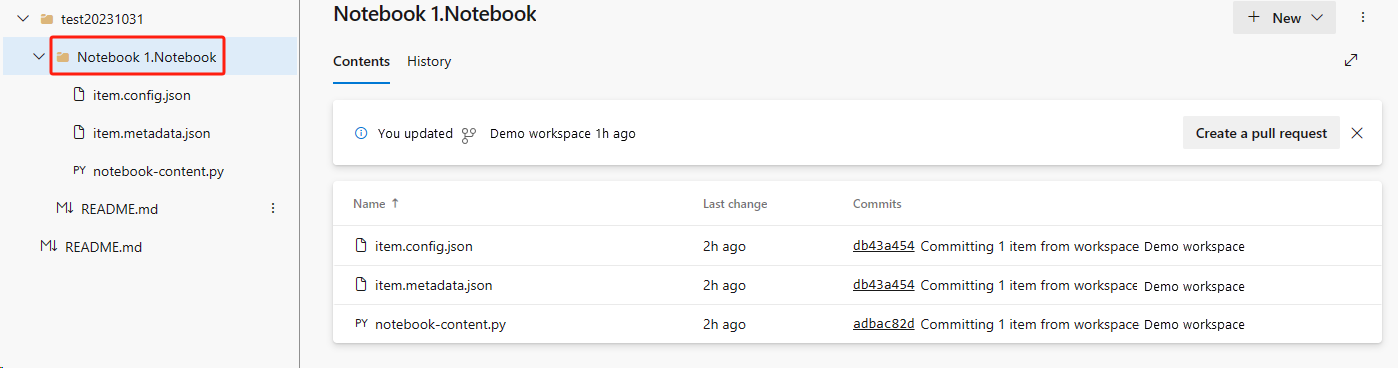
Recuperar o Notebook do repositório ADO.
No espaço de trabalho recém-criado, conecte-se novamente ao seu repositório do Azure ADO.
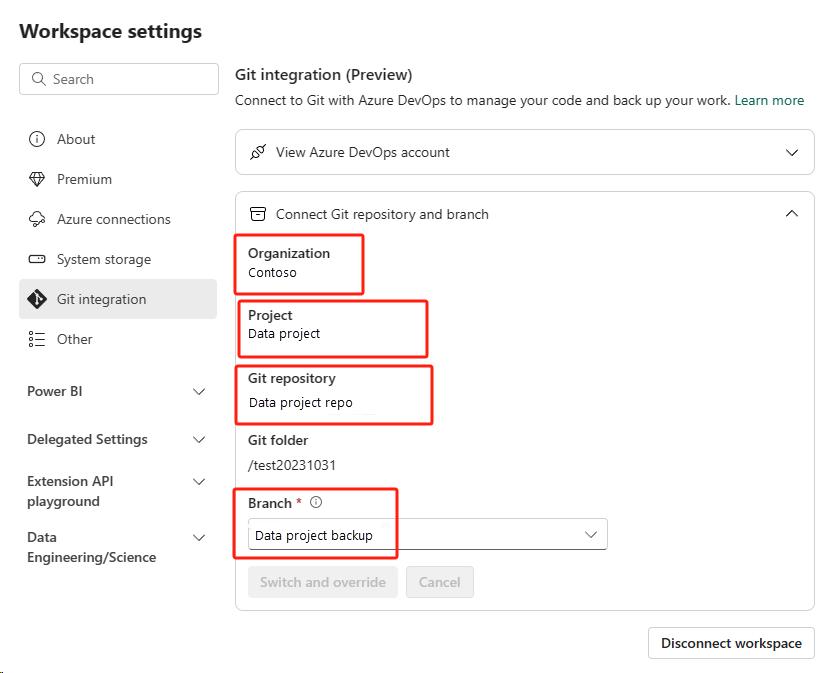
Selecione o botão Controle do código-fonte. Em seguida, selecione a ramificação relevante do repositório. Em seguida, selecione Atualizar tudo. Aparecerá o Notebook original.
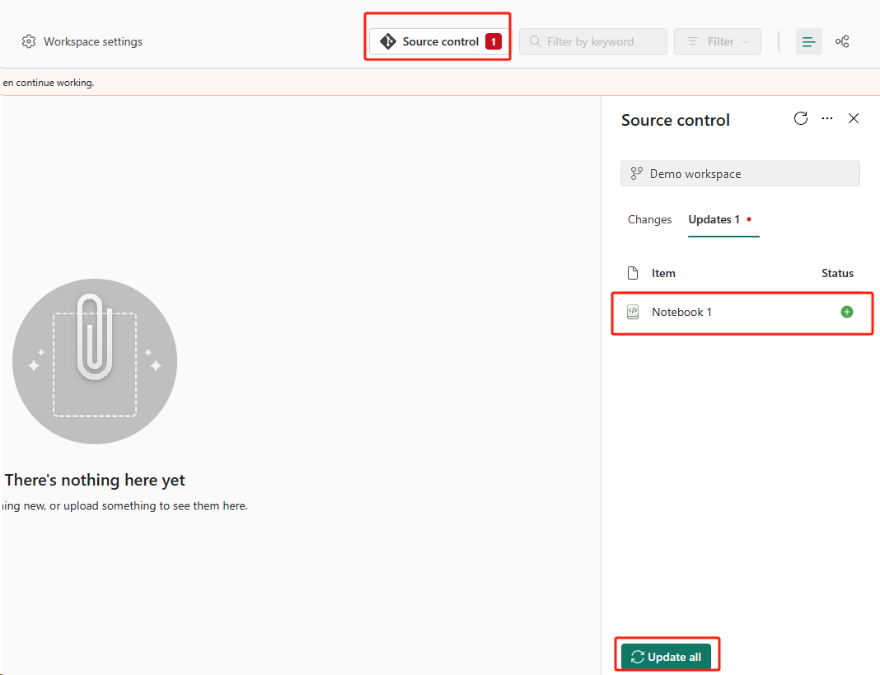
Se o Notebook original tiver um lakehouse padrão, os usuários poderão referenciar a seção Lakehouse para recuperar o lakehouse e, em seguida, conectar o lakehouse recém-recuperado ao Notebook recém-recuperado.
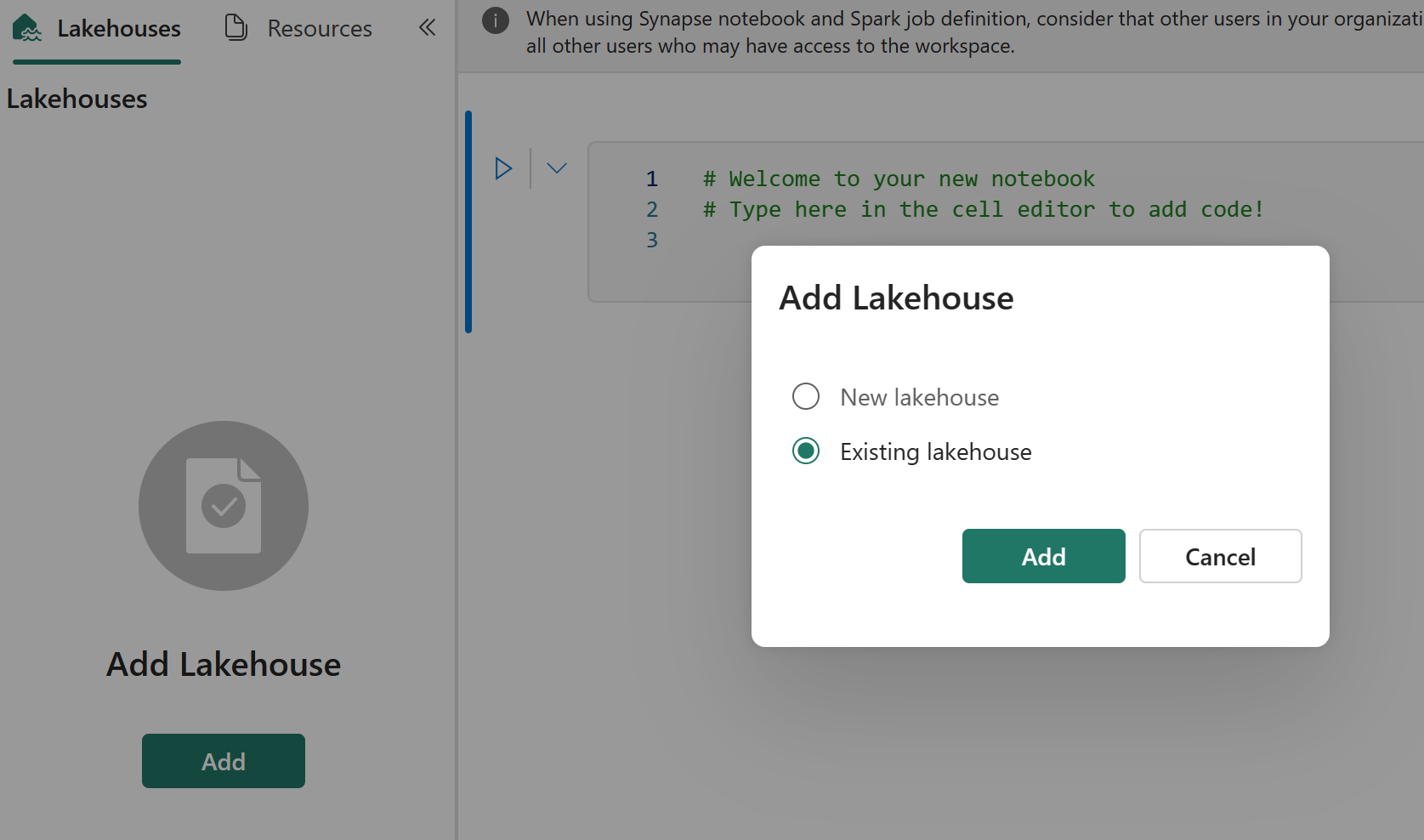
A integração do Git não dá suporte à sincronização de arquivos, pastas ou instantâneos de arquivo do Notebook no gerenciador de recursos do Notebook.
Se o Notebook original tiver arquivos no gerenciador de recursos do Notebook:
Certifique-se de salvar os arquivos ou pastas em um disco local ou em outro lugar.
Carregue novamente o arquivo do seu disco local ou das unidades de nuvem para o Notebook recuperado.
Se o Notebook original tiver um instantâneo do Notebook, salve também o instantâneo do Notebook no seu próprio sistema de controle de versão ou no disco local.
Para obter mais informações sobre a integração do Git, consulte Introdução à integração do Git.
Abordagem 2: abordagem manual para fazer o backup do conteúdo do código
Se não adotar a abordagem de integração com o Git, é possível salvar a versão mais recente do código, os arquivos do gerenciador de recursos e o instantâneo do Notebook em um sistema de controle de versão, como o Git, e recuperar manualmente o conteúdo do Notebook após um desastre:
Use o recurso "Importar Notebook" para importar o código do Notebook que deseja recuperar.
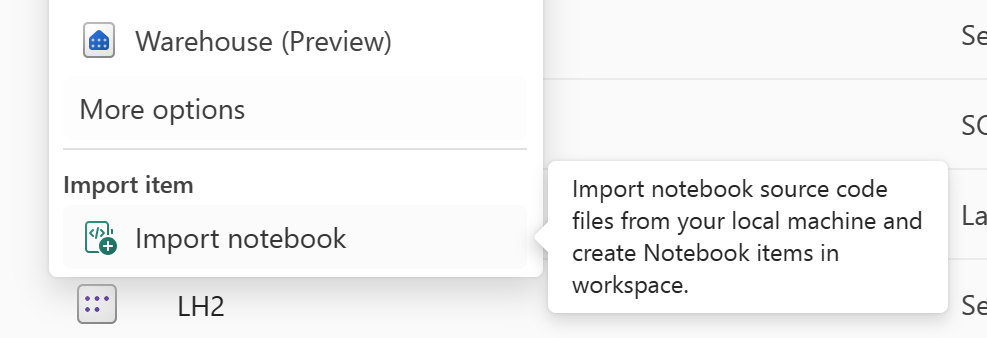
Após a importação, vá para o espaço de trabalho desejado (por exemplo, "C2.W2") para acessá-lo.
Se o Notebook original tiver um lakehouse padrão, consulte a seção Lakehouse. Em seguida, conecte o lakehouse recém-recuperado (que tem o mesmo conteúdo do lakehouse padrão original) ao Notebook recém-recuperado.
Se o Notebook original tiver arquivos ou pastas no gerenciador de recursos, carregue novamente os arquivos ou pastas salvos no sistema de controle de versão do usuário.
Definição de Trabalho do Spark
As definições de trabalho do Spark (SJD) da região primária permanecem indisponíveis para os clientes, e o arquivo de definição principal e o arquivo de referenciar no Notebook serão replicados para a região secundária via OneLake. Se desejar recuperar o SJD na nova região, você poderá seguir as etapas manuais descritas abaixo para recuperar o SJD. Observe que as execuções históricas do SJD não serão recuperadas.
É possível recuperar os itens do SJD copiando o código da região original usando o Gerenciador de Armazenamento do Microsoft Azure e reconectando manualmente as referências do Lakehouse após o desastre.
Crie um novo item SJD (por exemplo, SJD1) no novo espaço de trabalho C2.W2, com as mesmas definições e configurações do item SJD original (por exemplo, idioma, ambiente, etc.).
Use o Gerenciador de Armazenamento do Microsoft Azure para copiar Bibliotecas, Principais e Instantâneos do item SJD original para o novo item SJD.
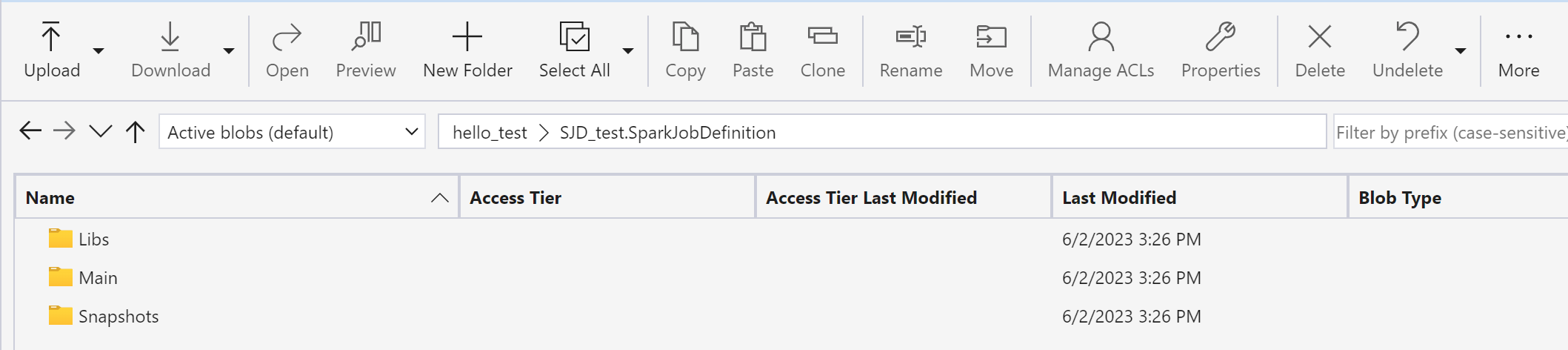
O conteúdo do código aparecerá no SJD recém-criado. Você precisará adicionar manualmente a referência do Lakehouse recém-recuperada para o trabalho (consulte as etapas de recuperação do Lakehouse). Os usuários precisarão reinserir manualmente os argumentos originais da linha de comando.
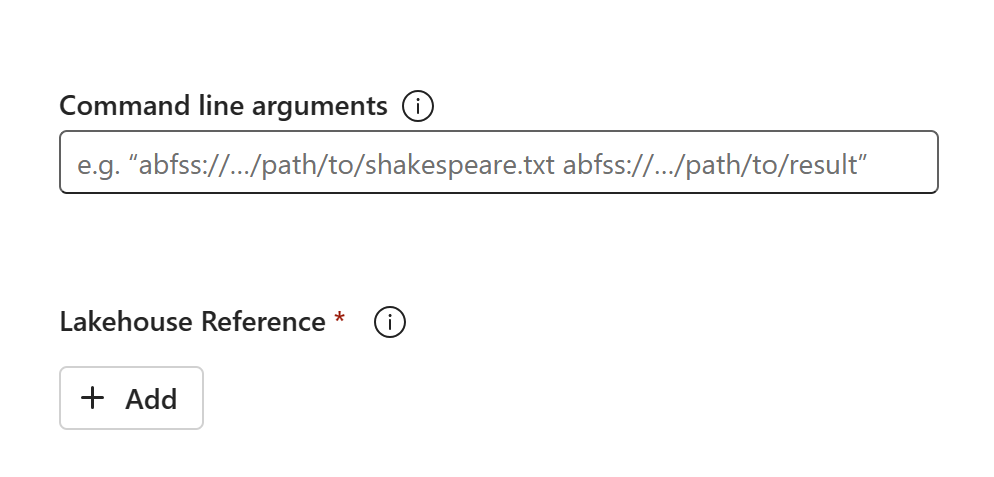
Agora você pode executar ou agendar seu SJD recém-recuperado.
Para obter detalhes, confira Integrar o OneLake com o Gerenciador de Armazenamento do Microsoft Azure.
Ciência de Dados
Este guia guiará você através dos procedimentos de recuperação para a experiência da Ciência de Dados. Ele aborda modelos e experimentos de ML.
Modelo e Experimento de ML
Os itens da Ciência de Dados da região primária permanecem indisponíveis para os clientes, e o conteúdo e os metadados nos modelos e experimentos de ML não serão replicados para a região secundária. Para recuperá-los totalmente na nova região, salve o conteúdo do código em um sistema de controle de versão (como o Git) e reexecute manualmente o conteúdo do código após o desastre.
Recuperar o Notebook. Consulte as Etapas de recuperação do Notebook.
A configuração, as métricas executadas historicamente e os metadados não serão replicados para a região emparelhada. Você terá que executar novamente cada versão do seu código de ciência de dados para recuperar totalmente os experimentos e modelos de ML após o desastre.
Data Warehouse
Este guia guiará você através dos procedimentos de recuperação para a experiência do Data Warehouse. Ele aborda os Warehouses.
Depósito
Os warehouses da região original permanecem indisponíveis para os clientes. Para recuperar os warehouses, execute as duas etapas a seguir.
Crie um novo Lakehouse provisório no espaço de trabalho C2.W2 para os dados que você copiará do warehouse original.
Preencha as tabelas Delta do warehouse aproveitando o Gerenciador do Warehouse e as funcionalidades do T-SQL (consulte Tabelas no armazenamento de dados no Microsoft Fabric).
Observação
Recomenda-se manter o código do Warehouse (esquema, tabela, exibição, procedimento armazenado, definições de função e códigos de segurança) com controle de versão e salvo em um local seguro (como o Git) de acordo com suas práticas de desenvolvimento.
Ingestão de dados via Lakehouse e código T-SQL
No espaço de trabalho recém-criado C2.W2:
Criar um Lakehouse provisório "LH2" em C2.W2.
Recupere as tabelas Delta no lakehouse provisório do warehouse original executando as etapas de recuperação do Lakehouse.
Cria um novo Warehouse "WH2" no C2.W2.
Conectar o lakehouse provisório no seu gerenciador de warehouse.
Dependendo de como você implantará as definições de tabela antes da importação de dados, o T-SQL real usado para as importações pode variar. Você pode usar a abordagem INSERT INTO, SELECT INTO ou CREATE TABLE AS SELECT para recuperar as tabelas do Warehouse de Lakehouses. Mais adiante no exemplo, estaríamos usando a variante INSERT INTO. (Se você usar o código abaixo, substitua os exemplos pelos nomes reais de tabelas e colunas)
USE WH1 INSERT INTO [dbo].[aggregate_sale_by_date_city]([Date],[City],[StateProvince],[SalesTerritory],[SumOfTotalExcludingTax],[SumOfTaxAmount],[SumOfTotalIncludingTax], [SumOfProfit]) SELECT [Date],[City],[StateProvince],[SalesTerritory],[SumOfTotalExcludingTax],[SumOfTaxAmount],[SumOfTotalIncludingTax], [SumOfProfit] FROM [LH11].[dbo].[aggregate_sale_by_date_city] GOPor fim, altere a cadeia de caracteres de conexão nos aplicativos que usam seu Fabric Warehouse.
Observação
Para os clientes que precisam de recuperação de desastres entre regiões e continuidade de negócios totalmente automatizada, recomendamos manter duas configurações de Fabric Warehouse em regiões do Fabric separadas e manter a paridade de código e dados, implantando regularmente e ingerindo dados em ambos os locais.
Data Factory
Os itens do Data Factory da região primária permanecem indisponíveis para os clientes, e as definições e configurações nos pipelines de dados ou nos itens do Dataflow Gen2 não serão replicadas para a região secundária. Para recuperar esses itens no caso de uma falha regional, será necessário recriar seus itens de Integração de Dados em outro espaço de trabalho de uma região diferente. As seções a seguir descrevem os detalhes.
Fluxos de Dados Gen2
Se desejar recuperar um item do Dataflow Gen2 na nova região, será necessário exportar um arquivo PQT para um sistema de controle de versão como o Git e, em seguida, recuperar manualmente o conteúdo do Dataflow Gen2 após o desastre.
No item do Dataflow Gen2, na guia Início do editor do Power Query, selecione Exportar modelo.
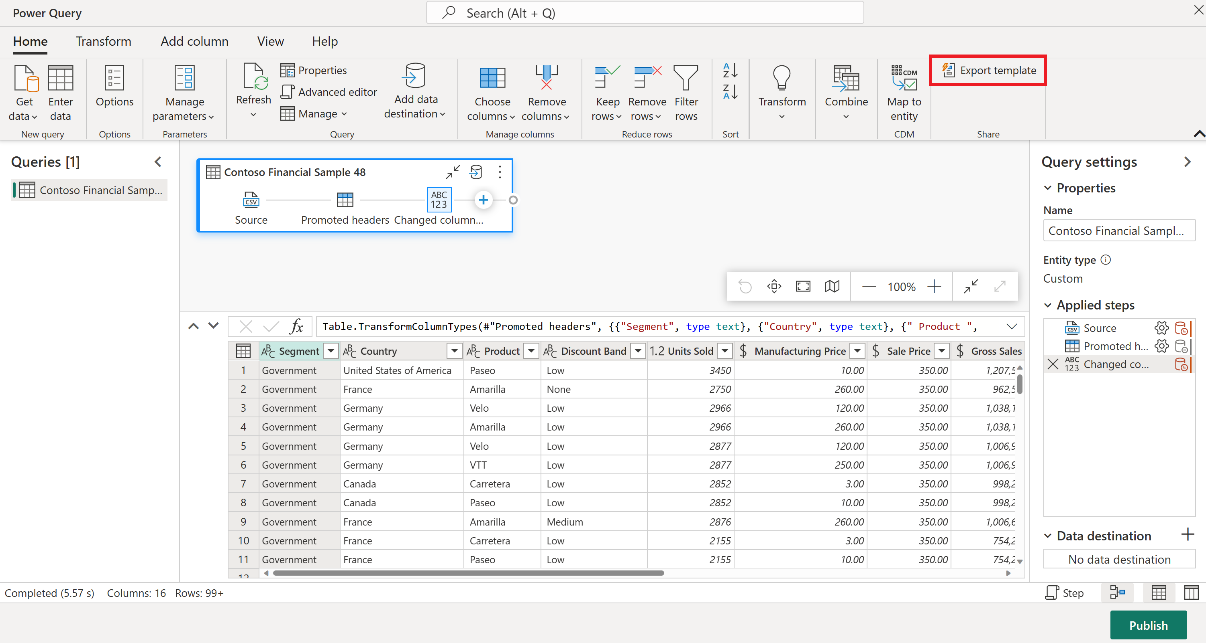
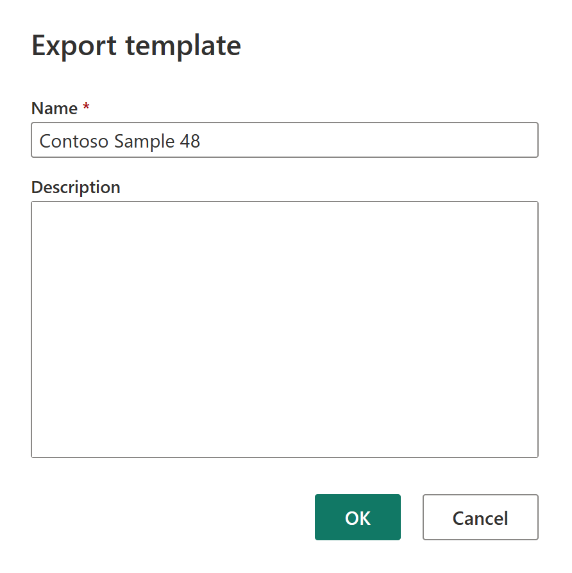
Na caixa de diálogo Exportar modelo, insira um nome (obrigatório) e uma descrição (opcional) para esse modelo. Ao concluir, selecione OK.
Após o desastre, crie um novo item de Dataflow Gen2 no novo espaço de trabalho "C2.W2".
No painel de exibição atual do editor do Power Query, selecione Importar de um modelo do Power Query.
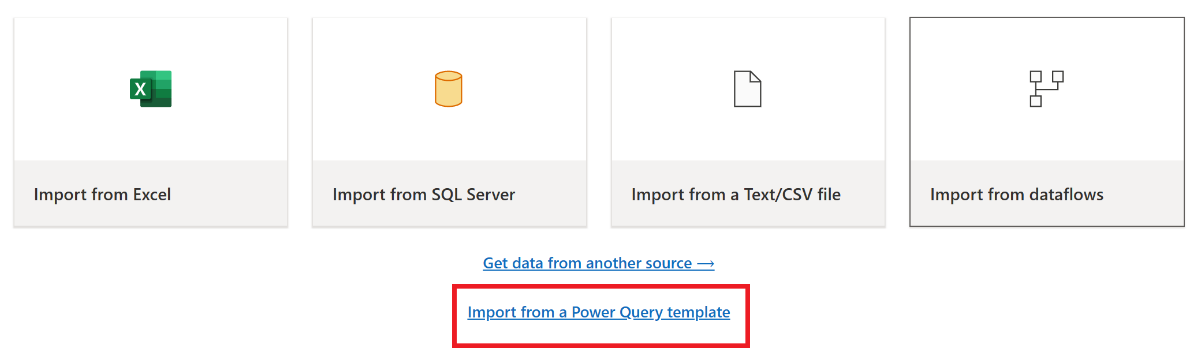
Na caixa de diálogo Abrir, navegue até a pasta de downloads padrão e selecione o arquivo .pqt que você salvou nas etapas anteriores. Em seguida, selecione Abrir.
O modelo é então importado para seu novo item Dataflow Gen2.
Pipelines de dados
Os clientes não podem acessar pipelines de dados em caso de desastre regional, e as configurações não são replicadas para a região emparelhada. Recomendamos a criação de seus pipelines de dados críticos em vários espaços de trabalho em diferentes regiões.
Inteligência em Tempo Real
Este guia guiará você através dos procedimentos de recuperação para a experiência da Inteligência em Tempo Real. Ele aborda bancos de dados/conjuntos de consultas KQL e fluxos de eventos.
Banco de dados/Conjunto de consultas KQL
Os usuários do banco de dados/conjunto de consultas KQL devem tomar medidas proativas para se protegerem em relação a um desastre regional. A abordagem a seguir garante que, no caso de um desastre regional, os dados em seus conjuntos de consultas de bancos de dados KQL permaneçam seguros e acessíveis.
Execute as etapas a seguir para garantir uma solução eficaz de recuperação de desastres para bancos de dados KQL e conjuntos de consultas.
Estabeleça bancos de dados KQL independentes: configure dois ou mais bancos de dados/conjuntos de consultas KQL independentes em capacidades dedicadas do Fabric. Eles devem ser configurados em duas regiões diferentes do Azure (de preferência, regiões emparelhadas do Azure) para maximizar a resiliência.
Replicar atividades de gerenciamento: qualquer ação de gerenciamento executada em um cluster de banco de dados/Conjunto de consultas KQL deve ser espelhada no outro. Isso garante que ambos os bancos de dados permaneçam em sincronia. As principais atividades a serem replicadas incluem:
Tabelas: verifique se as estruturas de tabela e as definições de esquema estão consistentes em ambos os bancos de dados.
Mapeamentos: duplicar todos os mapeamentos requeridos. Verifique se as fontes de dados e os destinos estão corretamente alinhados.
Políticas: verifique se os dois bancos de dados têm retenção de dados, acesso e outras políticas relevantes de modo semelhante.
Gerenciar a autenticação e a autorização: para cada réplica, configure as permissões necessárias. Verifique se você estabeleceu níveis de autorização adequados, concedendo acesso ao pessoal necessário e mantendo os padrões de segurança.
Ingestão de dados paralela: para manter os dados consistentes e prontos em várias regiões, carregue o mesmo conjunto de dados em cada banco de dados KQL ao mesmo tempo que você os ingere.
Eventstream
Um fluxo de eventos é um posicionamento centralizado na plataforma Fabric para capturar, transformar e rotear eventos em tempo real para vários destinos (por exemplo, lakehouses, bancos de dados/conjuntos de consultas KQL) sem a necessidade de código. Desde que os destinos tenham suporte para recuperação de desastres, os fluxos de eventos não perderão dados. Portanto, os clientes devem usar as funcionalidades de recuperação de desastres desses sistemas de destino para garantir a disponibilidade dos dados.
Os clientes também podem obter redundância geográfica implantando cargas de trabalho do Eventstream idênticas em várias regiões do Azure como parte de uma estratégia ativa/ativa em vários sites. Com uma abordagem ativa/ativa em vários sites, os clientes podem acessar sua carga de trabalho em qualquer uma das regiões implantadas. Essa abordagem é a mais complexa e dispendiosa para a recuperação de desastres, mas pode reduzir o tempo de recuperação a quase zero na maioria das situações. Para ter redundância geográfica total, os clientes podem
Crie réplicas de suas fontes de dados em diferentes regiões.
Criar itens do Eventstream nas regiões correspondentes.
Conectar-se a esses novos itens nas fontes de dados idênticas.
Adicionar destinos idênticos para cada fluxo de eventos em diferentes regiões.
Informações relacionadas
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de