Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Usando o Copilot Studio, você pode aprimorar seus agentes com conhecimento específico do domínio alimentado pelas mesmas fontes de dados confiáveis e familiares que você cria por meio de conectores do Power Platform.
Ao carregar conteúdo externo de seu dispositivo, OneDrive ou SharePoint, você pode enriquecer seus agentes com conhecimento contextual adaptado à sua empresa. Microsoft Dataverse armazena esses arquivos com segurança e os processa automaticamente em índices semânticos e inserções de vetor. Essa configuração permite que seus agentes gerem respostas mais precisas e fundamentadas com base nas informações fornecidas.
Os arquivos carregados no Copilot Studio usam Microsoft Dataverse para ingerir arquivos brutos e criar índices e inserções de vetor. Esses índices e embeddings ajudam a fornecer respostas de qualidade para seus agentes. Você pode carregar esses arquivos do seu computador ou conectando-se a OneDrive ou SharePoint.
Quando você faz upload de arquivos como fontes de conhecimento, ajuda a enriquecer seus agentes com dados extras, aumenta o conhecimento do modelo de linguagem e fundamenta o agente em informações específicas que você fornece. Você pode carregar vários arquivos, que o sistema indexa semanticamente como inserções de vetor e, em seguida, usa como conhecimento para agentes. Você pode compartilhar esse conhecimento em agentes com usuários autenticados e não autenticados do agente.
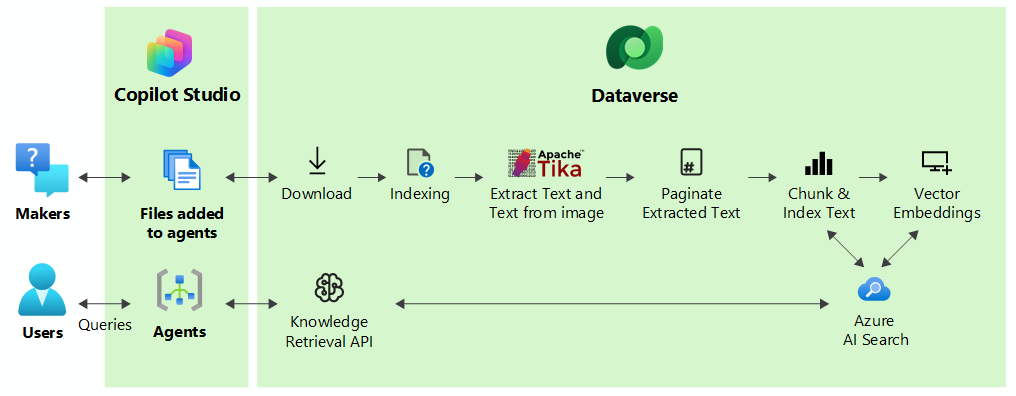
Para melhorar as respostas do agente, o sistema carregava os arquivos em partes para um processamento mais rápido e os indexava vetorialmente para fornecer correspondências semânticas com a consulta do usuário. O sistema armazena os arquivos de forma segura no Dataverse. Quando um usuário consulta por meio de um agente, o Copilot Studio localiza as partes mais relevantes que correspondem à intenção da consulta de usuário e retorna os resultados para o usuário.
Da mesma forma, o Dataverse ingere arquivos do OneDrive e do SharePoint usando as opções em upload de arquivo. Ele também ingere conteúdo não estruturado, como artigos da base de dados de conhecimento do Salesforce, ServiceNow, Confluence e Zendesk, para fornecer melhores resultados semânticos para o agente.
Note
Saiba mais em Usar interpretador de código para analisar dados estruturados.
Conectores do Power Platform para dados não estruturados
Os seguintes conectores do Power Platform funcionam com fontes de dados não estruturadas:
OneDrive
Use a opção Carregar arquivos > do OneDrive com uma interface de seletor de arquivo para escolher os arquivos e pastas que você deseja incluir. Uma vez selecionados, o sistema recupera os itens no Dataverse e os indexa para uso. As pastas que você adiciona incluem todos os arquivos suportados e subpastas dentro daquela pasta até o limite total de arquivos.
SharePoint
Use a opção Carregar arquivos > do SharePoint para selecionar arquivos e pastas por meio de uma interface de seletor de arquivo. Depois de selecionar esses itens, o conector os recupera no Dataverse e os indexa para uso. Ao adicionar pastas, você inclui todos os arquivos e subpastas com suporte dentro dessa pasta até o limite total de arquivos. Atualmente, o conector não dá suporte ao Pages.
Note
Quando você usa o SharePoint como uma fonte de conhecimento, o Copilot Studio recupera o conteúdo por meio da indexação de pesquisa do SharePoint, não lendo diretamente exibições de lista, como AllItems.aspx. Os itens do SharePoint recém-adicionados ou atualizados podem não estar disponíveis para o agente até que a indexação de pesquisa seja concluída. Verifique se o agente tem as permissões necessárias, como Sites.Read.All e Files.Read.All, e o conteúdo é armazenado em formatos de arquivo com suporte.
Salesforce
O conector do Salesforce para dados não estruturados dá suporte à recuperação de bases de dados de conhecimento que contêm artigos de conhecimento. Selecione uma Base de Dados de Conhecimento e o conector indexa todos os artigos nessa Base de Dados de Conhecimento. Você não pode selecionar artigos ou tópicos individuais. Ao consultar dados, você não pode especificar um artigo ou base de conhecimento específico. A lista de conhecimentos mostra um único objeto para todos os objetos de conhecimento selecionados ao criar a origem.
ServiceNow
O conector do ServiceNow para dados não estruturados dá suporte à recuperação de bases de dados de conhecimento que contêm artigos de conhecimento. As bases de dados de conhecimento contêm artigos. Selecione uma Base de Dados de Conhecimento e o conector indexa todos os artigos nessa Base de Dados de Conhecimento. Você não pode selecionar artigos individuais. Ao consultar dados, você não pode especificar uma base de conhecimento, pasta ou artigo individual. A lista de conhecimentos mostra um único objeto para todos os objetos de conhecimento selecionados ao criar a origem.
Confluência
O conector Confluence para dados não estruturados dá suporte à recuperação dos espaços que contêm páginas. O conector também suporta subpastas. Você não pode selecionar páginas individuais. Ao consultar dados, você não pode especificar uma página. A lista de conhecimentos mostra um único objeto para todas as páginas dentro do espaço.
Zendesk
O conector Zendesk para dados não estruturados oferece suporte à recuperação da base de conhecimento que contém artigos de conhecimento. Você não pode selecionar artigos, categorias ou seções individuais. Ao consultar dados, você não pode especificar um artigo, categoria ou seção. A lista de conhecimento mostra um único objeto para todos os artigos dentro da base de dados de conhecimento.
Segurança
Quando um usuário consulta um agente que usa uma origem do Power Platform Connector, o sistema executa verificações de autorização.
Acesso ao conector
Quando você usa pela primeira vez uma fonte baseada em conector, o sistema solicita que você selecione um conector existente do Power Platform ou adicione um. Esse processo garante que você compartilhe apenas dados com os criadores que têm as permissões apropriadas para acessar a fonte de dados.
Acesso ao conteúdo
Quando um usuário faz uma consulta, o sistema usa suas informações de conexão para verificar a fonte dos dados e verificar se ele tem permissão para ver o conteúdo. Embora o sistema armazene fragmentos e índices localmente no Dataverse, ele realiza uma verificação ao vivo nas consultas para garantir que o usuário atual tenha acesso aos dados antes de fornecer um resumo ou resposta.
Note
- O sistema não retornará resultados aos usuários se eles não tiverem permissão para conjuntos específicos de arquivos ou artigos da base de dados de conhecimento. Em vez disso, recebem uma mensagem padrão dizendo "nenhum resultado foi encontrado." Se os usuários acham que deveriam haver resultados para essa fonte, precisam trabalhar com seus administradores para garantir que eles tenham permissões para os dados que estão tentando acessar. O usuário precisa de um papel de segurança Dataverse apropriado atribuído a ele, como o papel de Usuário Básico.
- O sistema não armazena localmente as informações de permissão de conteúdo. Ele realiza todas as verificações de permissão em tempo real com a fonte para garantir que estejam sempre atualizadas.
Frequência de sincronização e atualização de arquivo
Um trabalho de sincronização agendado mantém arquivos conectados de OneDrive e SharePoint e artigos de conhecimento não estruturados atualizados. Esse trabalho é executado automaticamente em segundo plano, atualizando o conteúdo dos arquivos e reindexando as alterações para fornecer resultados precisos para consultas. As atualizações gerenciam não apenas as alterações no conteúdo, mas também garantem que qualquer conteúdo excluído da origem não apareça mais como parte de quaisquer respostas de consulta. Atualmente, você não pode disparar manualmente uma atualização.
Para obter mais informações sobre a frequência de atualização, consulte Limites das fontes de dados não estruturados do Copilot Studio.
Licenciamento
Todas as solicitações que requerem conhecimento são cobradas nas taxas de mensagens de respostas generativas do Microsoft Copilot. Para mais informações, veja Taxas de cobrança e gestão.
Se as fontes de conhecimento exigem a ingestão de dados, o armazenamento dos dados e os índices correspondentes para recuperá-los estão sujeitos aos direitos de armazenamento que o cliente possui. Para mais informações sobre a busca em linguagem natural do Dataverse, veja Aprimorar experiências baseadas em IA com a busca do Dataverse.
Limites e limitações
Quando você ativa o suporte a dados não estruturados pela primeira vez, o Dataverse pode levar entre 5 e 30 minutos para configurar e indexar antes de processar os arquivos adicionados. O período de tempo depende do tamanho do ambiente dataverse atual.
Cada agente pode ter no máximo 500 objetos de conhecimento. Esses objetos podem ser arquivos, pastas, artigos de conhecimento, sites ou outras fontes.
Atualmente, um agente pode usar apenas cinco fontes diferentes por vez. Por exemplo, SharePoint, Dataverse, OneDrive ou outras fontes.
Para obter mais informações sobre limites e limitações específicos para as fontes de dados não estruturadas suportadas, consulte limites de conhecimento de fontes de dados não estruturadas do Copilot Studio.
Note
Os agentes do Copilot Studio requerem a pesquisa do Dataverse para usar essa fonte de conhecimento. Se você não puder adicionar um arquivo habilitado para Dataverse a um agente, peça ao administrador para ativar a pesquisa do Dataverse em seu ambiente. Para obter mais informações sobre a pesquisa do Dataverse e como gerenciá-la, consulte o que é a pesquisa do Dataverse e configure a pesquisa do Dataverse para seu ambiente.
Para acessar OneDrive e SharePoint conteúdo armazenado no Dataverse, os usuários devem ter pelo menos uma licença de usuário básico para Power Apps ou Dynamics 365. Além disso, as permissões Básicas de Usuário também devem incluir permissões de leitura para as seguintes tabelas e entidades:
- Montagem de Plug-in
- Tipo de plug-in
- Mensagem do Sdk
- Etapa de processamento de mensagens do SDK
- Imagem da Etapa de Processamento de Mensagens do Sdk
Você pode configurar essas permissões no Centro de administração do Power Platform ou no Centro de administração do Dynamics 365.
perguntas frequentes
Qual é a diferença entre as duas opções do SharePoint em Adicionar conhecimento?
Na caixa de diálogo Add knowledge, você verá duas opções de SharePoint.

A opção SharePoint na seção de upload de arquivo (1) é para carregar arquivos ou pastas SharePoint individuais para seu agente. Essa opção carrega uma cópia do arquivo de SharePoint para o Dataverse e mantém uma relação síncrona para manter o arquivo atualizado. Durante as consultas, SharePoint é acessado para validar as permissões do usuário para o conteúdo. Os arquivos armazenados do Dataverse consomem armazenamento de dados, mas fornecem uma funcionalidade de pesquisa semântica de documento completo e suporte para texto em imagens para determinados tipos de documento, como arquivos PDF.
Use a opção 1 quando desejar sincronização rápida e não arquivos estáticos carregados no Dataverse. Ele é atualizado automaticamente quando os arquivos de origem são alterados.
A outra opção SharePoint (2) fornece a integração completa SharePoint no Copilot Studio usando o conector SharePoint. Use esta opção quando precisar das capacidades completas do conector do SharePoint, configurações de autenticação personalizadas ou opções avançadas de consulta.
Diferenças de tempo de execução
| Cenário | Opção 1: upload de arquivo | Opção 2: conector do SharePoint |
|---|---|---|
| Repositório de conteúdo | Copiado para o Dataverse do SharePoint | ** Está no SharePoint |
| Funcionalidade de pesquisa | Pesquisa um índice semântico do Dataverse compilado a partir de vetores inseridos do conteúdo ingerido copiado do SharePoint | Consulta diretamente a infraestrutura de pesquisa do SharePoint |
| Atualização de conteúdo | O conteúdo é sincronizado a cada quatro a seis horas, com base na conclusão da ingestão | Em tempo real e reflete o conteúdo mais recente disponível |
| Listas do SharePoint | Supported | Sem suporte |
| Consumo de armazenamento do Dataverse | Sim, para arquivos copiados e índices de pesquisa | No |
| Filtros de consulta avançados | Não disponível | Filtrar por título, autor, modificado por, data de modificação |
Uso de opção
Use a opção 1 nas seguintes situações:
- Você precisa de suporte para listas do SharePoint
- O agente usa apenas um conjunto específico de arquivos ou pastas
- Você deseja pesquisa semântica de alta qualidade alimentada por inserções de vetor
- Um intervalo de atualização de conteúdo de quatro a seis horas é suficiente
Use a opção 2 nas seguintes situações:
- Nenhum atraso na sincronização de conteúdo, como um wiki atualizado com frequência ou um site de anúncio
- Precisa evitar o consumo do Dataverse, especialmente para bibliotecas de documentos grandes
- Uso de filtros de consulta avançados, como filtragem com base no autor, data modificada ou título
Note
Ambas as opções exigem autenticação do usuário. Os usuários podem entrar antes que o agente recupere os resultados do conteúdo do SharePoint. Saiba mais sobre o tempo de sincronização e os limites de arquivo nos limites de fonte de dados não estruturados do Copilot Studio.
Por que o ícone do SharePoint não é exibido na seção Carregar arquivos da caixa de diálogo Adicionar conhecimento?
Há um pequeno atraso após a instalação de uma solução até que ela apareça em todas as organizações existentes. Para iniciar uma atualização manual, siga estas etapas:
Faça login no centro de administração do Power Platform usando credenciais de administrador.
Na barra lateral, selecione Gerenciar.
Na lista de produtos, selecione Dynamics 365 Apps.
Pesquise poweraiextensions.
Selecione os três pontos (... ) para Microsoft Dynamics 365 – PowerAIExtensions e selecione Install.
No menu suspenso, selecione seu ambiente e selecione Instalar.
Após a conclusão da instalação, abra Power Apps em uma nova janela.
No painel de navegação esquerdo, selecione Soluções.
Selecione Detalhes.
Verifique se a versão da solução PowerAIExtensions Anchor está configurada para 1.01.688 ou superior.
O que acontece quando adiciono mais de 500 objetos de conhecimento ao meu agente?
Você não pode adicionar mais objetos a menos que primeiro exclua os anteriores.
Cada agente tem seu próprio índice da fonte de conhecimento?
O Dataverse armazena fontes de conhecimento para uso no ambiente onde você as cria. Se vários agentes usarem a mesma pasta SharePoint, todos os agentes usarão uma única instância dessa pasta.
O que acontece se eu adicionar uma pasta do SharePoint ou do OneDrive que exceda o número máximo de arquivos, pastas e subpastas?
O Copilot Studio recupera e indexa até o número máximo de arquivos, pastas e subpastas. Ele não processa os itens restantes e não indica quais itens são ou não processados.
Um dos arquivos que eu adiciono aparece como parte da fonte de conhecimento, mas não consigo obter respostas dele. Por quê?
Esse problema pode estar relacionado a um dos seguintes motivos:
- A página Conhecimento não relata o arquivo ou a pasta como Pronto.
- O nome do arquivo inclui um caractere sem suporte (especificamente para arquivos do SharePoint).
- O arquivo tem configuração de confidencialidade Confidencial ou Altamente Confidencial, ou proteção por senha.
- Não há suporte para o tipo de arquivo.
- O arquivo ou pasta vem de um site diferente do OneDrive ou do SharePoint de um usuário diferente e o usuário não o compartilhou com você.
- O arquivo é um arquivo de base de dados de conhecimento e sua conta não tem as permissões necessárias para exibir o conteúdo no sistema de origem.