Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Dependendo da fonte de dados, as informações sobre tipos de dados e nomes de coluna podem ou não ser fornecidas explicitamente. Normalmente, as APIs REST do OData lidam com isso usando a definição de $metadata e o método Power Query OData.Feed lida automaticamente com a análise dessas informações e aplicando-as aos dados retornados de uma fonte OData.
Muitas APIs REST não têm uma maneira de determinar programaticamente seu esquema. Nesses casos, você precisará incluir uma definição de esquema em seu conector.
Abordagem simples codificada
A abordagem mais simples é codificar uma definição de esquema em seu conector. Isso é suficiente para a maioria dos casos de uso.
No geral, a imposição de um esquema nos dados retornados pelo conector tem vários benefícios, como:
- Definindo os tipos de dados corretos.
- Removendo colunas que não precisam ser mostradas aos usuários finais (como IDs internas ou informações de estado).
- Garantindo que cada página de dados tenha a mesma forma adicionando todas as colunas que possam estar ausentes de uma resposta (as APIs REST geralmente indicam que os campos devem ser nulos omitindo-os inteiramente).
Exibindo o esquema existente com Table.Schema
Considere o seguinte código que retorna uma tabela simples do serviço de exemplo TripPin OData:
let
url = "https://services.odata.org/TripPinWebApiService/Airlines",
source = Json.Document(Web.Contents(url))[value],
asTable = Table.FromRecords(source)
in
asTable
Observação
TripPin é uma origem OData, portanto, realisticamente, faria mais sentido simplesmente usar o OData.Feed tratamento automático de esquema da função. Neste exemplo, você tratará a origem como uma API REST típica e usará Web.Contents para demonstrar a técnica de codificação manual de um esquema.
Esta tabela é o resultado:
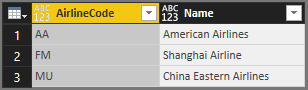
Você pode usar a função útil Table.Schema para verificar o tipo de dados das colunas:
let
url = "https://services.odata.org/TripPinWebApiService/Airlines",
source = Json.Document(Web.Contents(url))[value],
asTable = Table.FromRecords(source)
in
Table.Schema(asTable)

AirlineCode e Name são do any tipo.
Table.Schema retorna muitos metadados sobre as colunas em uma tabela, incluindo nomes, posições, informações de tipo e muitas propriedades avançadas, como Precisão, Escala e MaxLength. Por enquanto, você só deve se preocupar com o tipo inscrito (TypeName), o tipo primitivo (Kind) e se o valor da coluna pode ser nulo (IsNullable).
Definindo uma tabela de esquema simples
Sua tabela de esquema será composta por duas colunas:
| Coluna | Detalhes |
|---|---|
| Nome | O nome da coluna. Isso deverá corresponder ao nome presente nos resultados retornados pelo serviço. |
| Tipo | O tipo de dados M que você vai definir. Pode ser um tipo primitivo (texto, número, datetime e assim por diante) ou um tipo inscrito (Int64.Type, Currency.Type e assim por diante). |
A tabela de esquema codificada para a tabela Airlines definirá suas colunas AirlineCode e Name para text, e ficará assim:
Airlines = #table({"Name", "Type"}, {
{"AirlineCode", type text},
{"Name", type text}
})
Ao observar alguns dos outros pontos de extremidade, considere as seguintes tabelas de esquema:
A Airports tabela tem quatro campos que você deseja manter (incluindo um do tipo record):
Airports = #table({"Name", "Type"}, {
{"IcaoCode", type text},
{"Name", type text},
{"IataCode", type text},
{"Location", type record}
})
A People tabela tem sete campos, incluindo lists (Emails, AddressInfo), uma coluna anulável (Gender) e uma coluna com um tipo atribuído (Concurrency):
People = #table({"Name", "Type"}, {
{"UserName", type text},
{"FirstName", type text},
{"LastName", type text},
{"Emails", type list},
{"AddressInfo", type list},
{"Gender", type nullable text},
{"Concurrency", Int64.Type}
})
Você pode colocar todas essas tabelas em uma única tabela SchemaTablede esquema mestre:
SchemaTable = #table({"Entity", "SchemaTable"}, {
{"Airlines", Airlines},
{"Airports", Airports},
{"People", People}
})
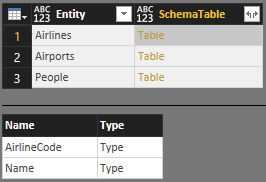
A função auxiliar SchemaTransformTable
A SchemaTransformTablefunção auxiliar descrita abaixo será usada para impor esquemas em seus dados. Ele usa os seguintes parâmetros:
| Parâmetro | Tipo | Description |
|---|---|---|
| tabela | tabela | A tabela de dados na qual você desejará impor seu esquema. |
| esquema | tabela | A tabela de esquema da qual ler as informações da coluna, com o seguinte tipo: type table [Name = text, Type = type]. |
| enforceSchema | número | (opcional) Uma enumeração que controla o comportamento da função. O valor padrão ( EnforceSchema.Strict = 1) garante que a tabela de saída corresponda à tabela de esquema fornecida adicionando colunas ausentes e removendo colunas extras. A EnforceSchema.IgnoreExtraColumns = 2 opção pode ser usada para preservar colunas extras no resultado. Quando EnforceSchema.IgnoreMissingColumns = 3 for usado, as colunas ausentes e as colunas extras serão ignoradas. |
A lógica dessa função é semelhante a esta:
- Determine se há colunas ausentes da tabela de origem.
- Determine se há colunas extras.
- Ignorar colunas estruturadas (do tipo
list,recordetable) e colunas configuradas como do tipoany. - Use
Table.TransformColumnTypespara definir cada tipo de coluna. - Reordene colunas com base na ordem em que aparecem na tabela de esquema.
- Defina o tipo na própria tabela usando
Value.ReplaceType.
Observação
A última etapa para definir o tipo de tabela removerá a necessidade de a interface do usuário do Power Query inferir informações de tipo ao exibir os resultados no editor de consultas, o que às vezes pode resultar em uma chamada dupla para a API.
Juntando as peças
No contexto maior de uma extensão completa, o tratamento de esquema ocorrerá quando uma tabela for retornada da API. Normalmente, essa funcionalidade ocorre no nível mais baixo da função de paginação (se houver), com informações de entidade passadas de uma tabela de navegação.
Como grande parte da implementação de tabelas de paginação e navegação é específica do contexto, o exemplo completo de implementação de um mecanismo de tratamento de esquema codificado não será mostrado aqui. Este exemplo de TripPin demonstra a aparência de uma solução de ponta a ponta.
Abordagem sofisticada
A implementação embutida discutida acima faz um bom trabalho para garantir que os esquemas permaneçam consistentes para respostas JSON simples, mas é limitada à análise do primeiro nível da resposta. Conjuntos de dados profundamente aninhados se beneficiariam da seguinte abordagem, que tira proveito dos M Types.
Aqui está uma atualização rápida sobre os tipos na linguagem M da Especificação de Idioma:
Um valor de tipo é um valor que classifica outros valores. Um valor classificado por um tipo obedece a esse tipo. O sistema de tipos de M é composto pelas seguintes categorias de tipos:
- Tipos primitivos, que classificam valores primitivos (
binary, ,date,datetime,datetimezone,duration,list,logical,null, ,number,record, ,text,timetype) e também incluem uma série de tipos abstratos (function,table,anyenone).- Tipos de registro, que classificam valores de registro com base em nomes de campo e tipos de valor.
- Tipos de lista, que classificam listas usando um único tipo de base de item.
- Tipos de função, que classificam valores de função com base nos tipos de seus parâmetros e valores retornados.
- Tipos de tabela, que classificam valores de tabela com base em nomes de coluna, tipos de coluna e chaves.
- Tipos anuláveis, que classificam o valor nulo, além de todos os valores classificados por um tipo base.
- Tipos de dados, que classificam valores que são tipos.
Usando a saída JSON bruta que você obtém (e/ou pesquisando as definições no $metadata do serviço), você pode definir os seguintes tipos de registro para representar tipos complexos OData:
LocationType = type [
Address = text,
City = CityType,
Loc = LocType
];
CityType = type [
CountryRegion = text,
Name = text,
Region = text
];
LocType = type [
#"type" = text,
coordinates = {number},
crs = CrsType
];
CrsType = type [
#"type" = text,
properties = record
];
Observe como LocationType faz referência aos CityType e LocType para representar suas colunas estruturadas.
Para as entidades de nível superior que você desejará representar como Tabelas, você pode definir tipos de tabela:
AirlinesType = type table [
AirlineCode = text,
Name = text
];
AirportsType = type table [
Name = text,
IataCode = text,
Location = LocationType
];
PeopleType = type table [
UserName = text,
FirstName = text,
LastName = text,
Emails = {text},
AddressInfo = {nullable LocationType},
Gender = nullable text,
Concurrency Int64.Type
];
Em seguida, você pode atualizar sua SchemaTable variável (que você pode usar como uma tabela de pesquisa para mapeamentos de entidade para tipo) para usar essas novas definições de tipo:
SchemaTable = #table({"Entity", "Type"}, {
{"Airlines", AirlinesType},
{"Airports", AirportsType},
{"People", PeopleType}
});
Você pode contar com uma função comum (Table.ChangeType) para impor um esquema em seus dados, assim como você usou SchemaTransformTable no exercício anterior. Ao contrário de SchemaTransformTable, Table.ChangeType utiliza um tipo de tabela M real como argumento e aplicará seu esquema recursivamente para todos os tipos aninhados. Sua assinatura é:
Table.ChangeType = (table, tableType as type) as nullable table => ...
Observação
Para flexibilidade, a função pode ser usada em tabelas, bem como listas de registros (que é como as tabelas são representadas em um documento JSON).
Em seguida, você precisará atualizar o código do conector para alterar o schema parâmetro de um table para um typee adicionar uma chamada a Table.ChangeType. Novamente, os detalhes para fazer isso são muito específicos da implementação e, portanto, não vale a pena entrar em detalhes aqui.
Este exemplo de conector TripPin estendido demonstra uma solução de ponta a ponta implementando essa abordagem mais sofisticada para lidar com o esquema.