Tamanho da tabela e da linha em tabelas com otimização de memória
Aplica-se a:![]() SQL Server
SQL Server![]() Banco de Dados SQL do Azure
Banco de Dados SQL do Azure![]() Instância Gerenciada de SQL do Azure
Instância Gerenciada de SQL do Azure
Antes do SQL Server 2016 (13.x), o tamanho dos dados na linha de uma tabela com otimização de memória não podia ter mais de 8.060 bytes. No entanto, a partir do SQL Server 2016 (13.x) e no Banco de Dados SQL do Azure, é possível criar uma tabela com otimização de memória com várias colunas grandes (por exemplo, várias colunas de varbinary(8000)) e colunas LOB (ou seja, varbinary(máx), varchar(máx) e nvarchar(máx)) e executar operações nela usando módulos Transact-SQL (T-SQL) e tipos de tabela em compilação nativa.
Colunas que não se ajustam ao limite de tamanho de linha de 8.060 bytes são colocadas fora de linha, em uma tabela interna separada. Cada coluna fora de linha tem uma tabela interna correspondente, que por sua vez, tem um único índice não clusterizado. Para obter detalhes sobre essas tabelas internas usadas para colunas fora da linha, veja sys.memory_optimized_tables_internal_attributes.
Existem alguns cenários em que é útil calcular o tamanho da linha e da tabela:
Qual a quantidade de memória que uma tabela usa.
A quantidade de memória usada pela tabela não pode ser calculada exatamente. Muitos fatores afetam a quantidade de memória usada. como alocação de memória baseada na página, localidade, cache e preenchimento. Além disso, várias versões de linhas têm transações ativas associadas ou estão aguardando a coleta de lixo.
O tamanho mínimo necessário para os dados e índices na tabela é determinado pelo cálculo de
<table size>, discutido posteriormente no artigo.Calcular o uso da memória é, na melhor das hipóteses, uma aproximação; portanto, é recomendável incluir o planejamento de capacidade nos planos de implantação.
O tamanho dos dados de uma linha; ele se ajusta à limitação de tamanho de linha de 8.060 bytes? Para responder a essas perguntas, use a computação para
<row body size>, discutida mais adiante neste artigo.
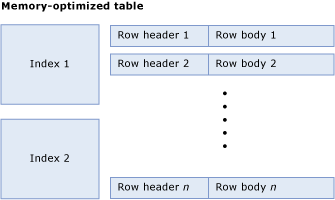
Uma tabela com otimização de memória consiste em uma coleção de linhas e índices que contêm ponteiros para linhas. A figura a seguir ilustra uma tabela com índices e linhas que, por sua vez, têm cabeçalhos e corpos de linha:
Calcular o tamanho da tabela
O tamanho de uma tabela na memória, em bytes, é calculado da seguinte forma:
<table size> = <size of index 1> + ... + <size of index n> + (<row size> * <row count>)
O tamanho de um índice de hash é fixado no momento da criação da tabela e depende do número real de buckets. O bucket_count especificado com a definição de índice é arredondado até a potência mais próxima de 2 para obter o número real de buckets. Por exemplo, se o bucket_count especificado for 100000, o número real de buckets do índice será 131072.
<hash index size> = 8 * <actual bucket count>
O tamanho de um índice não clusterizado está na ordem de <row count> * <index key size>.
O tamanho da linha é calculado adicionando-se o cabeçalho e o corpo:
<row size> = <row header size> + <actual row body size>
<row header size> = 24 + 8 * <number of indexes>
Calcular o tamanho do corpo da linha
As linhas em uma tabela com otimização de memória têm os seguintes componentes:
O cabeçalho de linha contém o carimbo de data/hora necessário para implementar o controle de versão de linha. O cabeçalho da linha também contém o ponteiro de índice para implementar o encadeamento de linhas nos buckets de hash (descrito anteriormente).
O corpo da linha contém os dados reais da coluna, que incluem algumas informações auxiliares como a matriz nula das colunas que permitem valor nulo e a matriz de deslocamento dos tipos de dados de comprimento variável.
A figura a seguir ilustra a estrutura de linha de uma tabela que tem dois índices:

Os carimbos de data/hora de início e de término indicam o período em que uma determinada versão de linha é válida. As transações que começam nesse intervalo podem ver essa versão de linha. Para obter mais informações, veja Transações com tabelas com otimização de memória.
Os ponteiros de índice apontam para a próxima linha da cadeia de caracteres que pertence ao bucket de hash. A figura a seguir ilustra a estrutura de uma tabela com duas colunas (nome, cidade), e com dois índices, um na coluna nome e outro na coluna cidade.
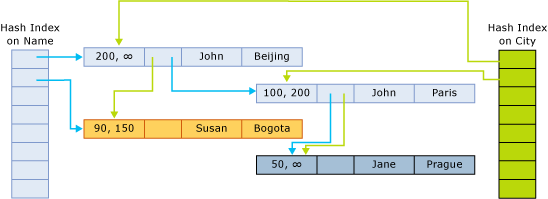
Nesta figura, os nomes John e Jane são transformados em hash no primeiro bucket. Susan é transformado em hash no segundo bucket. As cidades Beijing e Bogota são transformadas em hash no primeiro bucket. Paris e Prague são transformadas em hash no segundo bucket.
Desse modo, as cadeias do índice de hash na coluna nome são as seguintes:
- Primeiro bucket:
(John, Beijing);(John, Paris);(Jane, Prague) - Segundo bucket:
(Susan, Bogota)
As cadeias do índice de cidade são as seguintes:
- Primeiro bucket:
(John, Beijing),(Susan, Bogota) - Segundo bucket:
(John, Paris),(Jane, Prague)
Um carimbo de data/hora de término ∞ (infinito) indica que essa é a versão atualmente válida da linha. A linha não foi atualizada nem excluída desde que essa versão de linha foi gravada.
Para um tempo maior que 200, a tabela contém as seguintes linhas:
| Nome | City |
|---|---|
| John | Pequim |
| Jane | Praga |
Entretanto, qualquer transação ativa com tempo inicial igual a 100 resultará na seguinte versão da tabela:
| Nome | City |
|---|---|
| John | Paris |
| Jane | Praga |
| Susan | Bogota |
O cálculo do <row body size> é abordado na tabela a seguir.
Há dois cálculos diferentes para o tamanho do corpo da linha: tamanho calculado e o tamanho real:
O tamanho calculado, marcado com tamanho calculado do corpo da linha, é usado para determinar se a limitação do tamanho da linha de 8.060 bytes foi excedida.
O tamanho real, marcado com tamanho do corpo da linha real, é o tamanho real do armazenamento do corpo da linha na memória e nos arquivos do ponto de verificação.
O tamanho calculado do corpo da linha e o tamanho real do corpo da linha real são calculados de modo semelhante. A única diferença é o cálculo do tamanho das colunas (n)varchar(i) e varbinary(i), como refletido na parte inferior da tabela a seguir. O tamanho do corpo da linha calculado usa o tamanho declarado i como o tamanho da coluna, enquanto o tamanho do corpo da linha real usa o tamanho real dos dados.
A tabela a seguir descreve o cálculo do tamanho do corpo da linha, dado como <actual row body size> = SUM(<size of shallow types>) + 2 + 2 * <number of deep type columns>.
| Seção | Tamanho | Comentários |
|---|---|---|
| Colunas do tipo superficial | SUM(<size of shallow types>). O tamanho dos tipos individuais em bytes é o seguinte:bit: 1tinyint: 1smallint: 2int: 4real: 4smalldatetime: 4smallmoney: 4bigint: 8datetime: 8datetime2: 8float: 8money: 8numeric (precisão <= 18): 8time: 8numeric(precisão > 18): 16uniqueidentifier: 16 |
|
| Preenchimento da coluna superficial | Os valores possíveis são:1 se houver colunas do tipo profundas e o tamanho total dos dados das colunas superficiais for como um número ímpar.0; caso contrário |
Os tipos profundos são os tipos (var)binary e (n)(var)char. |
| Matriz de deslocamento para colunas do tipo profundas | Os valores possíveis são:0 se não houver colunas de tipo profunda2 + 2 * <number of deep type columns>; caso contrário |
Os tipos profundos são os tipos (var)binary e (n)(var)char. |
| Matriz nula | <number of nullable columns> / 8 é arredondado para bytes completos. |
A matriz tem 1 bit por coluna anulável. Ele é arredondado para bytes completos. |
| Preenchimento da matriz nula | Os valores possíveis são:1 se houver colunas do tipo profundas e o tamanho da matriz NULL é um número ímpar de bytes.0; caso contrário |
Os tipos profundos são os tipos (var)binary e (n)(var)char. |
| Preenchimento | Se não houver colunas de tipo profunda: 0Se houver colunas do tipo profundas, de 0 a 7 bytes de preenchimento serão adicionados, com base no maior alinhamento exigido por uma coluna superficial. Cada coluna superficial exige alinhamento igual a seu tamanho, como documentado anteriormente, exceto pelo fato de que as colunas GUID precisam de alinhamento de 1 byte (e não 16) e as colunas numéricas sempre precisam de alinhamento de 8 bytes (nunca 16). O maior requisito de alinhamento entre todas as colunas rasas é usado. De 0 a 7 bytes de preenchimento são adicionados, de modo que o tamanho total até agora (sem as colunas do tipo profundas) é um múltiplo do alinhamento requerido. |
Os tipos profundos são os tipos (var)binary e (n)(var)char. |
| Colunas do tipo profundas de comprimento fixo | SUM(<size of fixed length deep type columns>)O tamanho de cada coluna é o seguinte: i para char(i) e binary(i).2 * i para nchar(i) |
As colunas do tipo profundas de comprimento fixo são colunas do tipo char(i), nchar(i) ou binary(i). |
| Tamanho calculado das colunas do tipo profundo de tamanho variável | SUM(<computed size of variable length deep type columns>)O tamanho calculado de cada coluna é o seguinte: i para varchar(i) e varbinary(i)2 * i para nvarchar(i) |
Essa linha é aplicada somente ao tamanho calculado do corpo da linha. As colunas do tipo profundas de comprimento variável são colunas do tipo varchar(i), nvarchar(i) ou varbinary(i). O tamanho calculado é determinado pelo comprimento máximo ( i) da coluna. |
| Tamanho real das colunas do tipo profundo de tamanho variável | SUM(<actual size of variable length deep type columns>)O tamanho real de cada coluna é o seguinte: n, onde n é o número de caracteres armazenados na coluna, para varchar(i).2 * n, onde n é o número de caracteres armazenados na coluna, para nvarchar(i).n, onde n é o número de bytes armazenados na coluna, para varbinary(i). |
Essa linha é aplicada somente ao tamanho real do corpo da linha. O tamanho real é determinado pelos dados armazenados nas colunas da linha. |
Exemplo: cálculo do tamanho da tabela e da linha
Para índices de hash, o número de buckets real é arredondado até a potência mais próxima de 2. Por exemplo, se o bucket_count especificado for 100000, o número real de buckets do índice será 131072.
Considere uma tabela Orders com a seguinte definição:
CREATE TABLE dbo.Orders (
OrderID INT NOT NULL PRIMARY KEY NONCLUSTERED,
CustomerID INT NOT NULL INDEX IX_CustomerID HASH WITH (BUCKET_COUNT = 10000),
OrderDate DATETIME NOT NULL,
OrderDescription NVARCHAR(1000)
)
WITH (MEMORY_OPTIMIZED = ON);
GO
Esta tabela tem um índice de hash e um índice não clusterizado (a chave primária). Ela também tem três colunas de tamanho fixo e uma coluna de tamanho variável, além disso, uma das colunas é capaz de NULL (OrderDescription). Vamos supor que a tabela Orders tenha 8.379 linhas e o tamanho médio dos valores na coluna OrderDescription seja de 78 caracteres.
Para determinar o tamanho da tabela, primeiro determine o tamanho dos índices. O bucket_count para ambos os índices é especificado como 10000. Isso é arredondado para a potência mais próxima de 2: 16384. Consequentemente, o tamanho total dos índices da tabela Orders é:
8 * 16384 = 131072 bytes
O que sobra é o tamanho dos dados da tabela, que é:
<row size> * <row count> = <row size> * 8379
(A tabela de exemplo tem 8.379 linhas.) Agora, temos:
<row size> = <row header size> + <actual row body size>
<row header size> = 24 + 8 * <number of indices> = 24 + 8 * 1 = 32 bytes
A seguir, vamos calcular <actual row body size>:
Colunas do tipo superficial:
SUM(<size of shallow types>) = 4 <int> + 4 <int> + 8 <datetime> = 16O preenchimento da coluna superficial é 0, pois o tamanho total da coluna superficial é par.
Matriz de deslocamento para colunas do tipo profundas:
2 + 2 * <number of deep type columns> = 2 + 2 * 1 = 4matriz
NULL= 1Preenchimento da matriz
NULL= 1, pois o tamanho da matriz é ímpar e há uma coluna do tipo profunda.Preenchimento
- 8 é o maior requisito de alinhamento
- O tamanho até agora é 16 + 0 + 4 + 1 + 1 = 22
- O múltiplo mais próximo de 8 é 24
- O preenchimento total é 24 - 22 = 2 bytes
Não há colunas do tipo profundas de comprimento fixo (Colunas do tipo profundas de comprimento fixo: 0.).
O tamanho real da coluna do tipo profunda é 2 * 78 = 156. A única coluna do tipo profundo
OrderDescriptiontem o tiponvarchar.
<actual row body size> = 24 + 156 = 180 bytes
Para concluir o cálculo:
<row size> = 32 + 180 = 212 bytes
<table size> = 8 * 16384 + 212 * 8379 = 131072 + 1776348 = 1907420
O tamanho total da tabela na memória é de aproximadamente 2 megabytes. Isso não leva em conta a possível sobrecarga incorrida pela alocação de memória, e qualquer controle de versão de linha exigido para as transações que acessam essa tabela.
A memória real alocada para essa tabela, e usada por ela, bem como seus índices, podem ser obtidos por meio da seguinte consulta:
SELECT * FROM sys.dm_db_xtp_table_memory_stats
WHERE object_id = object_id('dbo.Orders');
Limitações de coluna fora da linha
Certas limitações e restrições ao uso de colunas fora da linha em uma tabela com otimização de memória estão listadas a seguir:
- Se houver um índice columnstore em uma tabela com otimização de memória, todas as colunas deverão caber na linha.
- Todas as colunas de chave de índice devem ser armazenadas na linha. Se uma coluna de chave de índice não couber na linha, a adição do índice falhará.
- Advertências sobre alterar uma tabela com otimização de memória com colunas fora da linha.
- Para LOBs, a limitação de tamanho espelha-se na de tabelas baseadas em disco (limite de 2 GB em valores de LOB).
- Para otimizar o desempenho, é recomendável que a maioria das colunas caibam dentro de 8.060 bytes.
- Dados fora da linha podem causar uso excessivo de memória e/ou disco.
Conteúdo relacionado
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de