Usar o Spark em notebooks
Você pode executar muitos tipos diferentes de aplicativos no Spark, incluindo código em scripts Python ou Scala, código Java compilado como JAR (Arquivo Java) e outros. O Spark é normalmente usado em dois tipos de carga de trabalho:
- Trabalhos de processamento em lote ou fluxo para ingerir, limpar e transformar dados (geralmente em execução como parte de um pipeline automatizado).
- Sessões de análise interativas para explorar, analisar e visualizar dados.
Executando código Spark em notebooks
O Azure Databricks inclui uma interface de notebook integrada para trabalhar com o Spark. Os notebooks fornecem uma forma intuitiva de combinar código com anotações Markdown, normalmente usados por cientistas e analistas de dados. A aparência da experiência de notebook integrada no Azure Databricks é semelhante à do Jupyter Notebooks, uma plataforma de notebooks de código aberto popular.
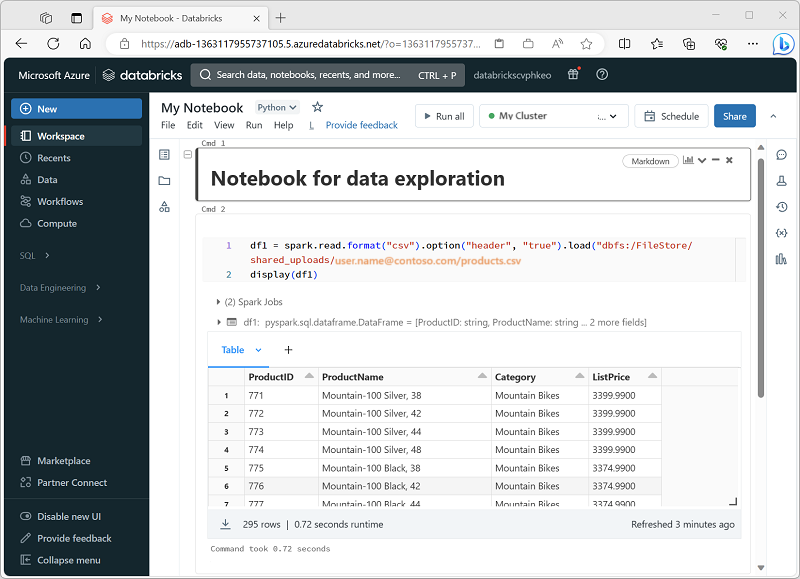
Os notebooks consistem em uma ou mais células, cada uma contendo código ou Markdown. As células de código nos notebooks têm alguns recursos que podem ajudar você a ser mais produtivo, incluindo:
- Realce de sintaxe e suporte a erros.
- Preenchimento automático de código.
- Visualização de dados interativas.
- Exportação de resultados.
Dica
Para saber mais sobre como trabalhar com notebooks no Azure Databricks, confira o artigo Notebooks na documentação do Azure Databricks.