Modelos de processamento de documentos
Importante
- As versões de visualização pública do Document Intelligence fornecem acesso antecipado a recursos que estão em desenvolvimento ativo. Recursos, abordagens e processos podem mudar, antes da Disponibilidade Geral (GA), com base nos comentários dos usuários.
- A versão de visualização pública das bibliotecas de cliente do Document Intelligence usa como padrão a API REST versão 2024-07-31-preview.
- A versão de pré-visualização pública 2024-07-31-preview está atualmente disponível apenas nas seguintes regiões do Azure. Observe que o modelo generativo personalizado (extração de campo de documento) no AI Studio só está disponível na região Centro-Norte dos EUA:
- E.U.A. Leste
- Oeste dos EUA2
- Europa Ocidental
- Centro-Norte dos EUA
Este conteúdo aplica-se a: ![]() v4.0 (pré-visualização) | Versões anteriores:
v4.0 (pré-visualização) | Versões anteriores: ![]() v3.1 (GA)
v3.1 (GA) ![]() v3.0 (GA)
v3.0 (GA) ![]() v2.1 (GA)
v2.1 (GA)
Este conteúdo aplica-se a: ![]() v3.1 (GA) | Última versão:
v3.1 (GA) | Última versão:![]() v4.0 (pré-visualização) | Versões anteriores:
v4.0 (pré-visualização) | Versões anteriores: ![]() v3.0
v3.0![]() v2.1
v2.1
Este conteúdo aplica-se a: ![]() v3.0 (GA) | Últimas versões:
v3.0 (GA) | Últimas versões: ![]() v4.0 (preview)
v4.0 (preview) ![]() v3.1 | Versão anterior:
v3.1 | Versão anterior: ![]() v2.1
v2.1
Este conteúdo aplica-se a: ![]() v2.1 | Última versão:
v2.1 | Última versão: ![]() v4.0 (pré-visualização)
v4.0 (pré-visualização)
O Azure AI Document Intelligence dá suporte a uma ampla variedade de modelos que permitem adicionar processamento inteligente de documentos aos seus aplicativos e fluxos. Você pode usar um modelo específico de domínio pré-criado ou treinar um modelo personalizado adaptado às suas necessidades de negócios e casos de uso específicos. O Document Intelligence pode ser usado com a API REST ou bibliotecas de clientes Python, C#, Java e JavaScript.
Nota
- Projetos de processamento de documentos que envolvam dados financeiros, dados de saúde protegidos, dados pessoais ou dados altamente sensíveis exigem atenção cuidadosa.
- Certifique-se de cumprir todos os requisitos nacionais/regionais e específicos do setor.
Descrição geral do modelo
A tabela a seguir mostra os modelos disponíveis para cada visualização atual e API estável:
| Tipo de modelo | Modelo | • 2024-02-29-pré-visualização • Pré-visualização 2023-10-31 |
2023-07-31 (GA) | 2022-08-31 (GA) | v2.1 (GA) |
|---|---|---|---|---|---|
| Modelos de análise de documentos | Ler | ✔️ | ✔️ | ✔️ | n/d |
| Modelos de análise de documentos | Esquema | ✔️ | ✔️ | ✔️ | ✔️ |
| Modelos de análise de documentos | Documento geral | movido para layout** | ✔️ | ✔️ | n/d |
| Modelos pré-criados | Cheque Bancário | ✔️ | n/d | n/d | n/d |
| Modelos pré-criados | Extrato Bancário | ✔️ | n/d | n/d | n/d |
| Modelos pré-criados | Paystub | ✔️ | n/d | n/d | n/d |
| Modelos pré-criados | Contrato | ✔️ | ✔️ | n/d | n/d |
| Modelos pré-criados | Cartão de seguro de doença | ✔️ | ✔️ | ✔️ | n/d |
| Modelos pré-criados | Documento de identificação | ✔️ | ✔️ | ✔️ | ✔️ |
| Modelos pré-criados | Fatura | ✔️ | ✔️ | ✔️ | ✔️ |
| Modelos pré-criados | Receção | ✔️ | ✔️ | ✔️ | ✔️ |
| Modelos pré-criados | Imposto Unificado dos EUA* | ✔️ | n/d | n/d | n/d |
| Modelos pré-criados | Imposto US 1040* | ✔️ | ✔️ | n/d | n/d |
| Modelos pré-criados | Imposto dos EUA 1098* | ✔️ | n/d | n/d | n/d |
| Modelos pré-criados | Imposto dos EUA 1099* | ✔️ | n/d | n/d | n/d |
| Modelos pré-criados | Imposto W2 dos EUA | ✔️ | ✔️ | ✔️ | n/d |
| Modelos pré-criados | Hipoteca dos EUA 1003 URLA | ✔️ | n/d | n/d | n/d |
| Modelos pré-criados | Hipoteca dos EUA 1004 URAR | ✔️ | n/d | n/d | n/d |
| Modelos pré-criados | Hipoteca dos EUA 1005 | ✔️ | n/d | n/d | n/d |
| Modelos pré-criados | US Mortgage 1008 Resumo | ✔️ | n/d | n/d | n/d |
| Modelos pré-criados | Divulgação de fechamento de hipoteca dos EUA | ✔️ | n/d | n/d | n/d |
| Modelos pré-criados | Certidão de casamento | ✔️ | n/d | n/d | n/d |
| Modelos pré-criados | Cartão de crédito | ✔️ | n/d | n/d | n/d |
| Modelos pré-criados | Cartão de visita | preterido | ✔️ | ✔️ | ✔️ |
| Modelo de classificação personalizado | Classificador personalizado | ✔️ | ✔️ | n/d | n/d |
| Modelo Generativo Personalizado | Modelo Generativo Personalizado | ✔️ | n/d | n/d | n/d |
| Modelo de extração personalizado | Neural personalizado | ✔️ | ✔️ | ✔️ | n/d |
| Modelo de extração personalizada | Modelo personalizado | ✔️ | ✔️ | ✔️ | ✔️ |
| Modelo de extração personalizado | Composição personalizada | ✔️ | ✔️ | ✔️ | ✔️ |
| Todos os modelos | Capacidades adicionais | ✔️ | ✔️ | n/d | n/d |
* - Contém submodelos. Consulte as informações específicas do modelo para variações e subtipos suportados.
Latência
Latência é a quantidade de tempo que um servidor de API leva para lidar e processar uma solicitação de entrada e entregar a resposta de saída para o cliente. O tempo para analisar um documento depende do tamanho (por exemplo, número de páginas) e dos conteúdos associados em cada página. O Document Intelligence é um serviço multilocatário onde a latência de documentos semelhantes é comparável, mas nem sempre idêntica. A variabilidade ocasional na latência e no desempenho é inerente a qualquer serviço assíncrono, sem monitoração de estado e baseado em microsserviços que processa imagens e documentos grandes em escala. Embora estejamos continuamente ampliando o hardware e a capacidade e os recursos de dimensionamento, você ainda pode ter problemas de latência em tempo de execução.
| Capacidade de complemento | Add-On/Grátis | • 2024-02-29-pré-visualização &bullet [2023-10-31-preview](/rest/api/aiservices/operation-groups?view=rest-aiservices-v4.0%20(2024-07-31-preview)&preserve-view=true |
2023-07-31 (GA) |
2022-08-31 (GA) |
v2.1 (GA) |
|---|---|---|---|---|---|
| Extração de propriedade de fonte | Complemento | ✔️ | ✔️ | n/d | n/d |
| Extração de fórmulas | Complemento | ✔️ | ✔️ | n/d | n/d |
| Extração de alta resolução | Complemento | ✔️ | ✔️ | n/d | n/d |
| Extração de código de barras | Gratuito | ✔️ | ✔️ | n/d | n/d |
| Deteção de idioma | Gratuito | ✔️ | ✔️ | n/d | n/d |
| Pares de valores-chave | Gratuito | ✔️ | n/d | n/d | n/d |
| Campos de consulta | Complemento* | ✔️ | n/d | n/d | n/d |
| PDF pesquisável | Complemento* | ✔️ | n/d | n/d | n/d |
Recursos de análise de modelo
| Model ID | Extração de conteúdo | Campos de consulta | Parágrafos | Funções de parágrafo | Marcas de seleção | Tabelas | Pares chave-valor | Idiomas | Códigos de barras | Análise Documental | Fórmulas* | Fonte de estilo* | Alta resolução* | PDF pesquisável |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| leitura pré-embutida | ✓ | O | O | O | O | O | ✓ | |||||||
| layout pré-construído | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | O | O | O | O | O | |||
| documento pré-construído | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | O | O | O | O | O | ||
| cartão de visita pré-construído | ✓ | ✓ | ✓ | |||||||||||
| contrato pré-construído | ✓ | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | ||||
| prebuilt-healthInsuranceCard.us | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-idDocument | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| fatura pré-embutida | ✓ | ✓ | ✓ | ✓ | O | O | O | ✓ | O | O | O | |||
| recibo pré-embutido | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-marriageCertificate.us | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| cartão de crédito pré-construído | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-check.us | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-payStub.us | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| extrato bancário pré-construído | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| pré-construído-hipoteca.us.1003 | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| pré-construído-hipoteca.us.1004 | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| pré-construído-hipoteca.us.1005 | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| pré-construído-hipoteca.pt.1008 | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-mortgage.us.closingDivulgação | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-tax.us | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| pré-construído-tax.us.w2 | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| pré-construído-tax.us.1098 | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| pré-construído-tax.us.1098E | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| pré-construído-tax.us.1098T | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-tax.us.1099(variações) | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-tax.us.1040(variações) | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| { customModelName } | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O |
✓ - Ativado
O - Opcional
* - Os recursos Premium incorrem em custos extras
Add-On* - Os campos de consulta têm um preço diferente dos outros recursos do complemento. Consulte os preços para obter detalhes.
Caixa delimitadora e coordenadas de polígono
Uma caixa delimitadora (polygon na v3.0 e versões posteriores) é um retângulo abstrato que envolve elementos de texto em um documento usado como ponto de referência para deteção de objetos.
A caixa delimitadora especifica a posição usando um plano de coordenadas x e y apresentado em uma matriz de quatro pares numéricos. Cada par representa um canto da caixa na seguinte ordem: superior esquerdo, superior direito, inferior direito, inferior direito, inferior esquerdo.
As coordenadas da imagem são apresentadas em pixels. Para um PDF, as coordenadas são apresentadas em polegadas.
Para todos os modelos, exceto o modelo de cartão de visita, o Document Intelligence agora suporta recursos adicionais para permitir análises mais sofisticadas. Esses recursos opcionais podem ser habilitados e desabilitados dependendo do cenário de extração de documentos. Há sete recursos adicionais disponíveis para a versão (GA) e posterior da 2023-07-31 API:
ocrHighResolutionformulasstyleFontbarcodeslanguageskeyValuePairs(2024-02-29-pré-visualização, 2023-10-31-pré-visualização)queryFields(2024-02-29-pré-visualização, 2023-10-31-pré-visualização)Not available with the US.Tax modelssearchablePDF(2024-07-31-pré-visualização)Only available for Read Model
Suporte de idiomas
Os modelos universais baseados em aprendizagem profunda em Document Intelligence suportam muitas linguagens que podem extrair texto multilíngue de suas imagens e documentos, incluindo linhas de texto com idiomas mistos. O suporte a idiomas varia de acordo com a funcionalidade do serviço Document Intelligence. Para obter uma lista completa, consulte os seguintes artigos:
- Suporte linguístico: modelos de análise de documentos
- Suporte linguístico: modelos pré-construídos
- Suporte a idiomas: modelos personalizados
Disponibilidade regional
O Document Intelligence está geralmente disponível em muitas das 60+ regiões de infraestrutura global do Azure.
Para obter mais informações, consulte a nossa página de geografias do Azure para ajudar a escolher a região mais adequada para si e para os seus clientes.
Detalhes do modelo
Esta seção descreve a saída que você pode esperar de cada modelo. Você pode estender a saída da maioria dos modelos com recursos adicionais.
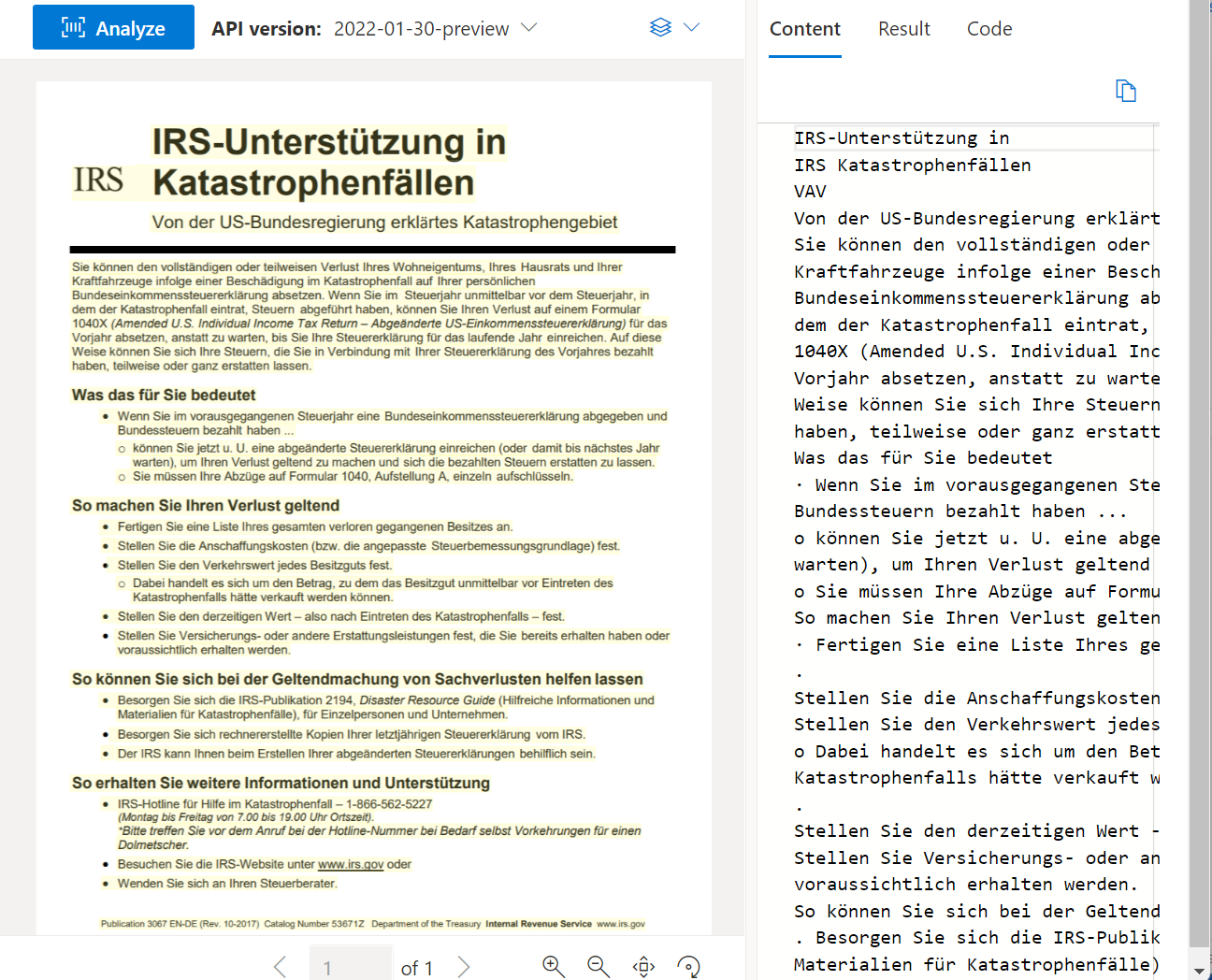
Ler OCR

A API de leitura analisa e extrai linhas, palavras, seus locais, idiomas detetados e estilo manuscrito, se detetado.
Exemplo de documento processado usando o Document Intelligence Studio:
Análise de layout
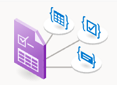
O modelo de análise de layout analisa e extrai texto, tabelas, marcas de seleção e outros elementos de estrutura, como títulos, títulos de seção, cabeçalhos de página, rodapés de página e muito mais.
Exemplo de documento processado usando o Document Intelligence Studio:
Cartão de seguro de doença
![]()
O modelo de cartão de seguro de saúde combina poderosos recursos de Reconhecimento Ótico de Caracteres (OCR) com modelos de aprendizagem profunda para analisar e extrair informações importantes de cartões de seguro de saúde dos EUA.
Exemplo de cartão de seguro de saúde dos EUA processado usando o Document Intelligence Studio:

Documentos fiscais dos EUA
Os modelos de documentos fiscais dos EUA analisam e extraem campos-chave e itens de linha de um grupo selecionado de documentos fiscais. A API suporta a análise de documentos fiscais dos EUA em inglês de vários formatos e qualidade, incluindo imagens capturadas por telefone, documentos digitalizados e PDFs digitais. Os seguintes modelos são atualmente suportados:
| Modelo | Description | ID do modelo |
|---|---|---|
| Imposto dos EUA W-2 | Extraia detalhes da compensação tributável. | pré-construído-tax.us.W-2 |
| Imposto dos EUA 1040 | Extraia detalhes de juros de hipoteca. | prebuilt-tax.us.1040(variações) |
| Imposto dos EUA 1098 | Extraia detalhes de juros de hipoteca. | prebuilt-tax.us.1098(variações) |
| Imposto dos EUA 1099 | Extrair rendimentos recebidos de outras fontes que não o empregador. | prebuilt-tax.us.1099(variações) |
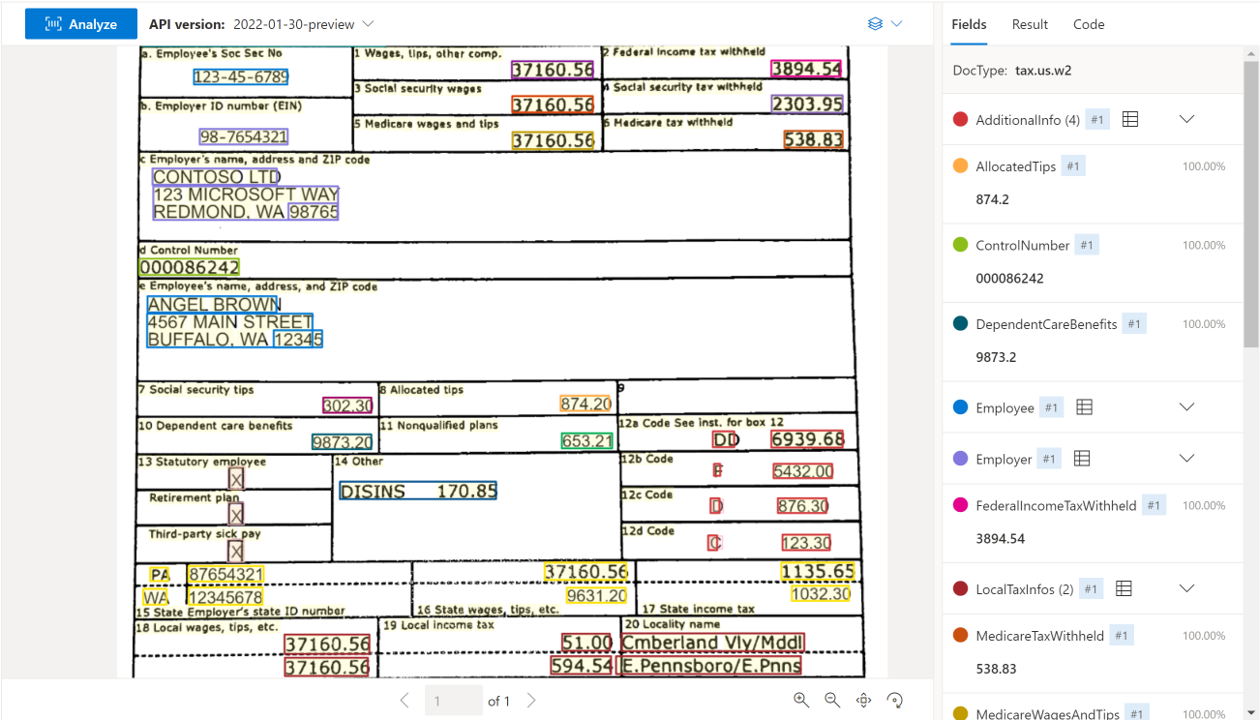
Exemplo de documento W-2 processado usando o Document Intelligence Studio:
Documentos de hipoteca dos EUA

Os modelos de documentos hipotecários dos EUA analisam e extraem campos-chave, incluindo informações sobre mutuários, empréstimos e propriedades de um grupo selecionado de documentos hipotecários. A API suporta a análise de documentos hipotecários americanos em inglês de vários formatos e qualidade, incluindo imagens capturadas por telefone, documentos digitalizados e PDFs digitais. Os seguintes modelos são atualmente suportados:
| Modelo | Description | ID do modelo |
|---|---|---|
| 1003 Contrato de Licença de Usuário Final (EULA) | Extrato de empréstimo, mutuário, detalhes do imóvel. | pré-construído-hipoteca.us.1003 |
| 1008 Documento de síntese | Extraia detalhes do mutuário, vendedor, propriedade, hipoteca e subscrição. | pré-construído-hipoteca.pt.1008 |
| Divulgação de encerramento | Extraia fechamento, custos de transação e detalhes do empréstimo. | prebuilt-mortgage.us.closingDivulgação |
| Certidão de casamento | Extraia detalhes de informações de casamento para requerentes de empréstimo conjunto. | Certidão de casamento pré-construída |
| Imposto dos EUA W-2 | Extraia detalhes da compensação tributável para verificação de renda. | pré-construído-tax.us.W-2 |
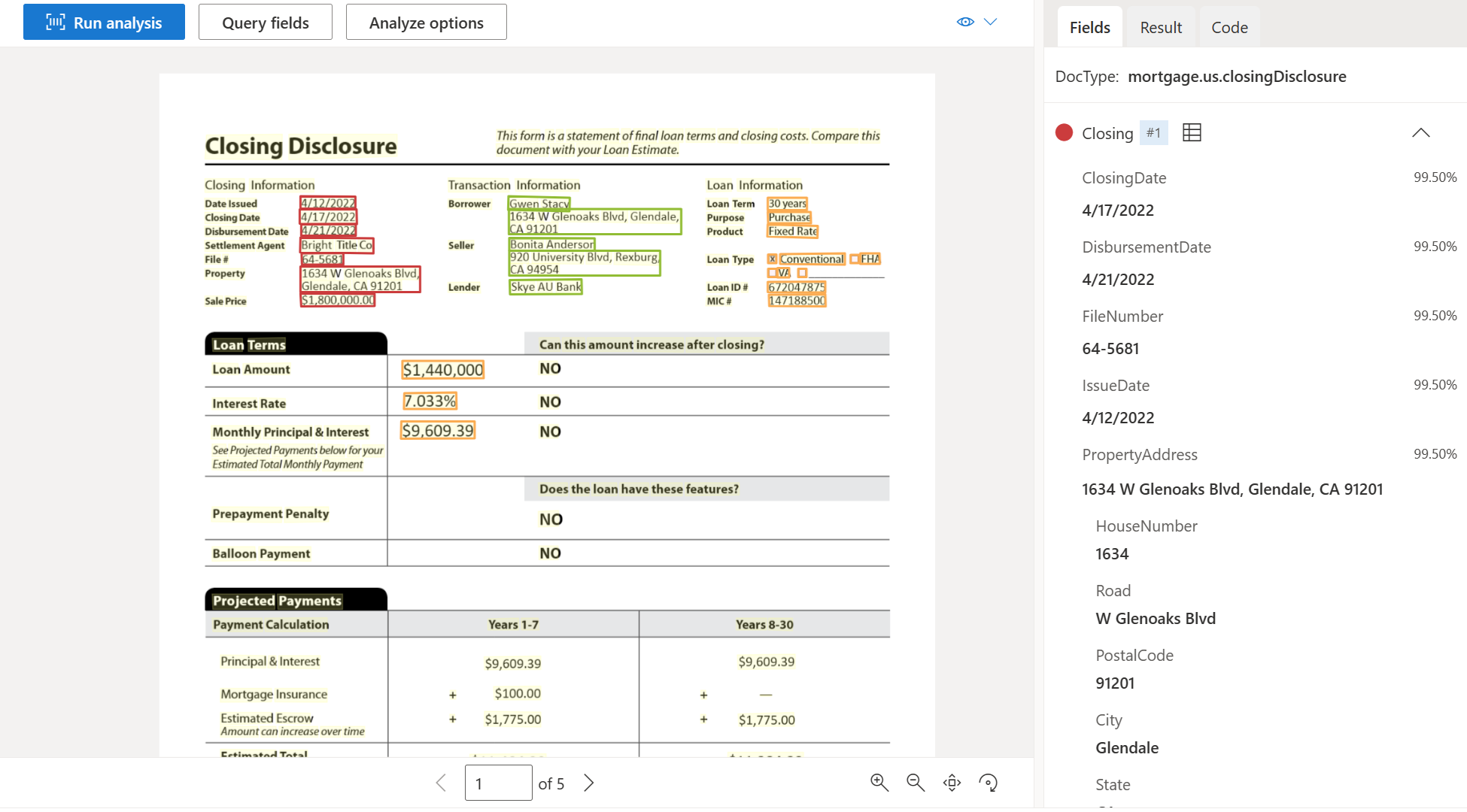
Exemplo de documento de divulgação de fechamento processado usando o Document Intelligence Studio:
Contract
![]()
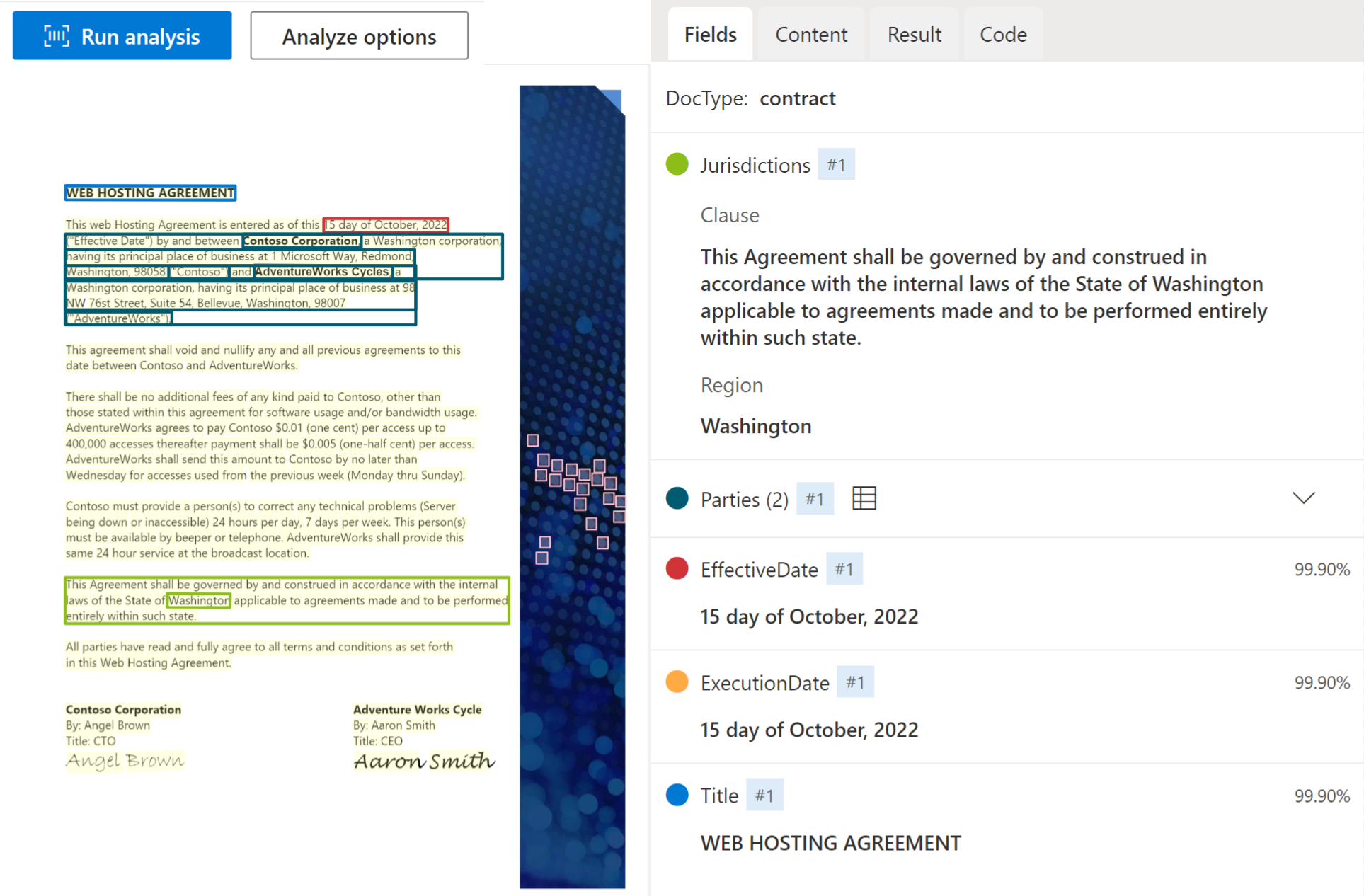
O modelo de contrato analisa e extrai campos-chave e itens de linha de acordos contratuais, incluindo partes, jurisdições, ID do contrato e título. O modelo suporta atualmente os cadernos de encargos em língua inglesa.
Exemplo de contrato processado usando o Document Intelligence Studio:
Invoice
O modelo de fatura automatiza o processamento de faturas para extrair o nome do cliente, o endereço de cobrança, a data de vencimento e o valor devido, itens de linha e outros dados importantes. Atualmente, o modelo suporta faturas em inglês, espanhol, alemão, francês, italiano, português e holandês.
Exemplo de fatura processada usando o Document Intelligence Studio:

Recibo
Use o modelo de recibo para verificar os recibos de vendas para o nome do comerciante, datas, itens de linha, quantidades e totais de recibos impressos e manuscritos. A versão v3.0 também suporta processamento de recibos de hotel de página única.
Exemplo de recibo processado usando o Document Intelligence Studio:

Documento de identidade (ID)

Use o modelo de documento de identidade (ID) para processar carteiras de motorista dos EUA (todos os 50 estados e o Distrito de Colúmbia) e páginas biográficas de passaportes internacionais (excluindo vistos e outros documentos de viagem) para extrair campos-chave.
Exemplo de Carteira de Motorista dos EUA processada usando o Document Intelligence Studio:

Certidão de casamento
![]()
Use o modelo de certidão de casamento para processar certidões de casamento dos EUA para extrair campos-chave, incluindo os indivíduos, data e local.
Exemplo de certidão de casamento dos EUA processada usando o Document Intelligence Studio:

Cartão de crédito
![]()
Use o modelo de cartão de crédito para processar cartões de crédito e débito para extrair campos-chave.
Exemplo de cartão de crédito processado usando o Document Intelligence Studio:

Modelos personalizados

Os modelos personalizados podem ser amplamente classificados em dois tipos. Modelos de classificação personalizados que suportam a classificação de um "tipo de documento" e modelos de extração personalizados que podem extrair um esquema definido de um tipo de documento específico.
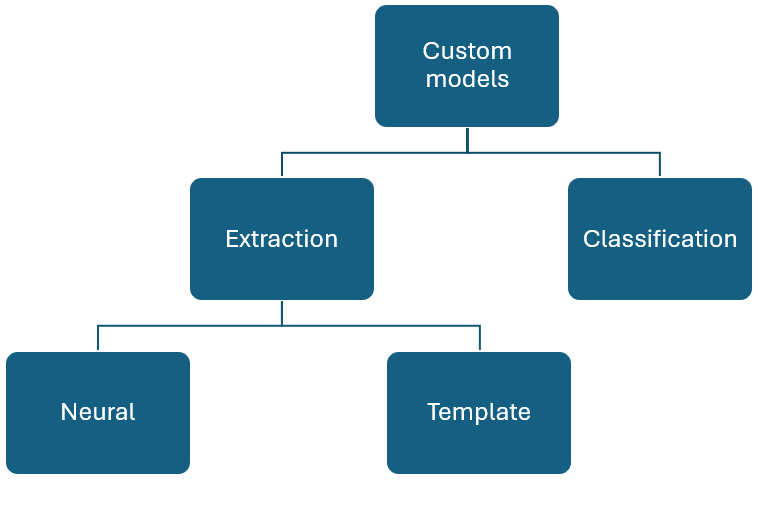
Modelos de documentos personalizados analisam e extraem dados de formulários e documentos específicos para o seu negócio. Eles reconhecem campos de formulário dentro de seu conteúdo distinto e extraem pares chave-valor e dados de tabela. Você só precisa de um exemplo do tipo de formulário para começar.
Os modelos personalizados da versão v3.0 e posteriores oferecem suporte à deteção de assinatura em modelos personalizados (formulário) e páginas cruzadas em modelos neurais e de modelo. A deteção de assinatura procura a presença de uma assinatura, não a identidade da pessoa que assina o documento. Se o modelo retornar não assinado para deteção de assinatura, o modelo não encontrou uma assinatura no campo definido.
Exemplo de modelo personalizado processado usando o Document Intelligence Studio:
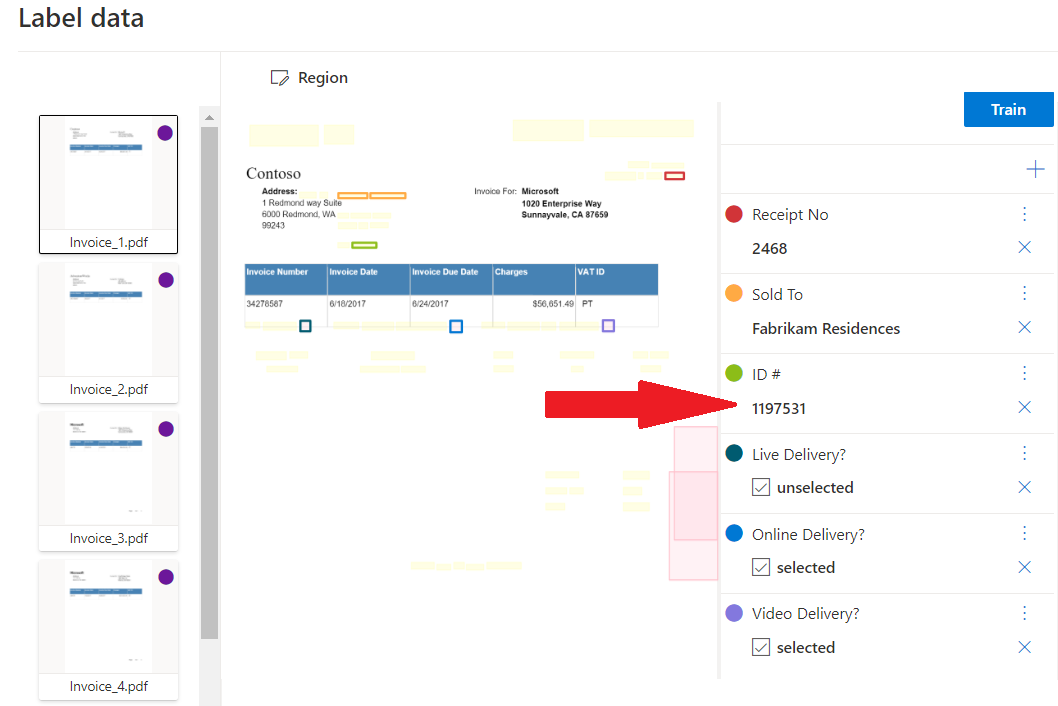
Extração personalizada

Modelo de extração personalizado pode ser um dos dois tipos, modelo personalizado ou neural personalizado. Para criar um modelo de extração personalizado, rotule um conjunto de dados de documentos com os valores que você deseja extrair e treine o modelo no conjunto de dados rotulado. Você só precisa de cinco exemplos do mesmo formulário ou tipo de documento para começar.
Exemplo de extração personalizada processada usando o Document Intelligence Studio:

Classificador personalizado

O modelo de classificação personalizado permite identificar o tipo de documento antes de invocar o modelo de extração. O modelo de classificação está disponível a partir da 2023-07-31 (GA) API. O treinamento de um modelo de classificação personalizado requer pelo menos duas classes distintas e um mínimo de cinco amostras por classe.
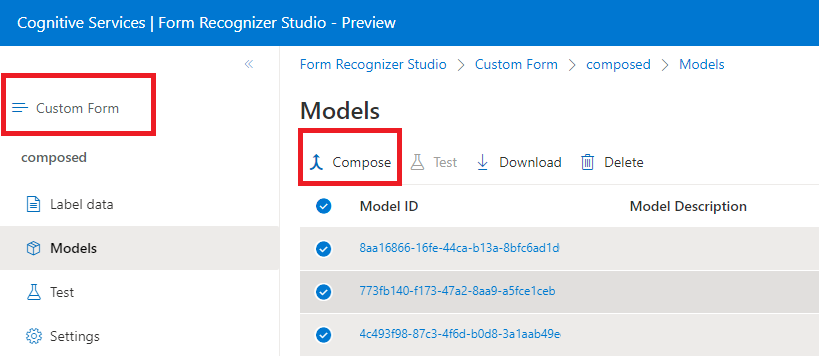
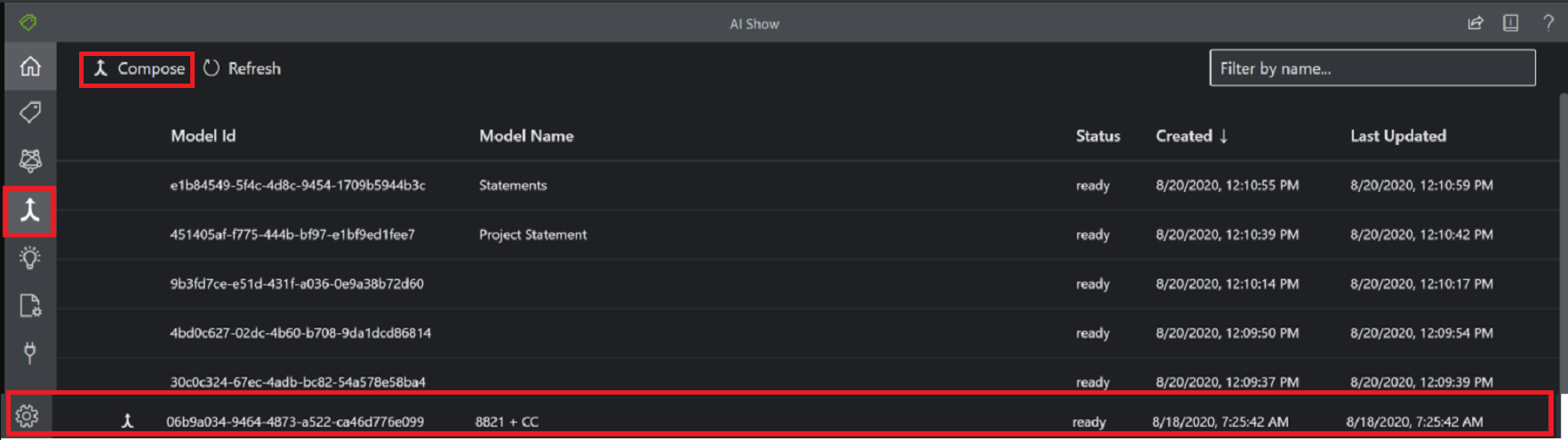
Modelos compostos
Um modelo composto é criado pegando uma coleção de modelos personalizados e atribuindo-os a um único modelo criado a partir de seus tipos de formulário. Você pode atribuir vários modelos personalizados a um modelo composto chamado com um único ID de modelo. Você pode atribuir até 200 modelos personalizados treinados a um único modelo composto.
Janela de diálogo Modelo composto no Document Intelligence Studio:
Requisitos de entrada
Formatos de ficheiro suportados:
Modelo PDF Imagem: JPEG/JPG,PNG,BMP,TIFF, ,HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLLida ✔ ✔ ✔ Esquema ✔ ✔ ✔ (2024-07-31-pré-visualização, 2024-02-29-pré-visualização, 2023-10-31-pré-visualização) Documento Geral ✔ ✔ Pré-criado ✔ ✔ Extração personalizada ✔ ✔ Classificação personalizada ✔ ✔ ✔ (2024-07-31-pré-visualização, 2024-02-29-pré-visualização) Para obter melhores resultados, forneça uma foto nítida ou uma digitalização de alta qualidade por documento.
Para PDF e TIFF, até 2.000 páginas podem ser processadas (com uma assinatura de nível gratuito, apenas as duas primeiras páginas são processadas).
O tamanho do arquivo para analisar documentos é de 500 MB para a camada paga (S0) e
4MB para a camada gratuita (F0).As dimensões da imagem devem estar entre 50 pixels x 50 pixels e 10.000 pixels x 10.000 pixels.
Se os seus PDFs forem bloqueados por uma palavra-passe, terá de remover o bloqueio antes da submetê-los.
A altura mínima do texto a ser extraído é de 12 pixels para uma imagem de 1024 x 768 pixels. Esta dimensão corresponde a cerca
8de texto pontual a 150 pontos por polegada (DPI).Para treinamento de modelo personalizado, o número máximo de páginas para dados de treinamento é 500 para o modelo de modelo personalizado e 50.000 para o modelo neural personalizado.
Para o treinamento do modelo de extração personalizado, o tamanho total dos dados de treinamento é de 50 MB para o modelo de modelo e
1GB para o modelo neural.Para treinamento de modelo de classificação personalizado, o tamanho total dos dados de treinamento é
1GB com um máximo de 10.000 páginas. Para 2024-07-31-preview e posterior, o tamanho total dos dados de treinamento é2GB com um máximo de 10.000 páginas.
Nota
A ferramenta Exemplo de etiquetagem não suporta o formato de ficheiro BMP. Esta é uma limitação da ferramenta e não do Serviço de Inteligência Documental.
Migração de versão
Saiba como usar o Document Intelligence v3.0 em seus aplicativos seguindo nosso guia de migração do Document Intelligence v3.1
| Modelo | Descrição |
|---|---|
| Análise documental | |
| Esquema | Extraia texto e informações de layout de documentos. |
| Pré-construído | |
| Fatura | Extraia informações importantes de faturas em inglês e espanhol. |
| Receção | Extraia informações importantes de recibos em inglês. |
| Documento de identificação | Extraia informações importantes de carteiras de motorista dos EUA e passaportes internacionais. |
| Cartão de visita | Extraia informações importantes de cartões de visita em inglês. |
| Personalizadas | |
| Personalizadas | Extraia dados de formulários e documentos específicos para o seu negócio. Os modelos personalizados são treinados para seus dados e casos de uso distintos. |
| Composto | Componha uma coleção de modelos personalizados e atribua-os a um único modelo criado a partir de seus tipos de formulário. |
Esquema
A API de layout analisa e extrai texto, tabelas e cabeçalhos, marcas de seleção e informações de estrutura de documentos.
Documento de exemplo processado usando a ferramenta Etiquetagem de amostra:
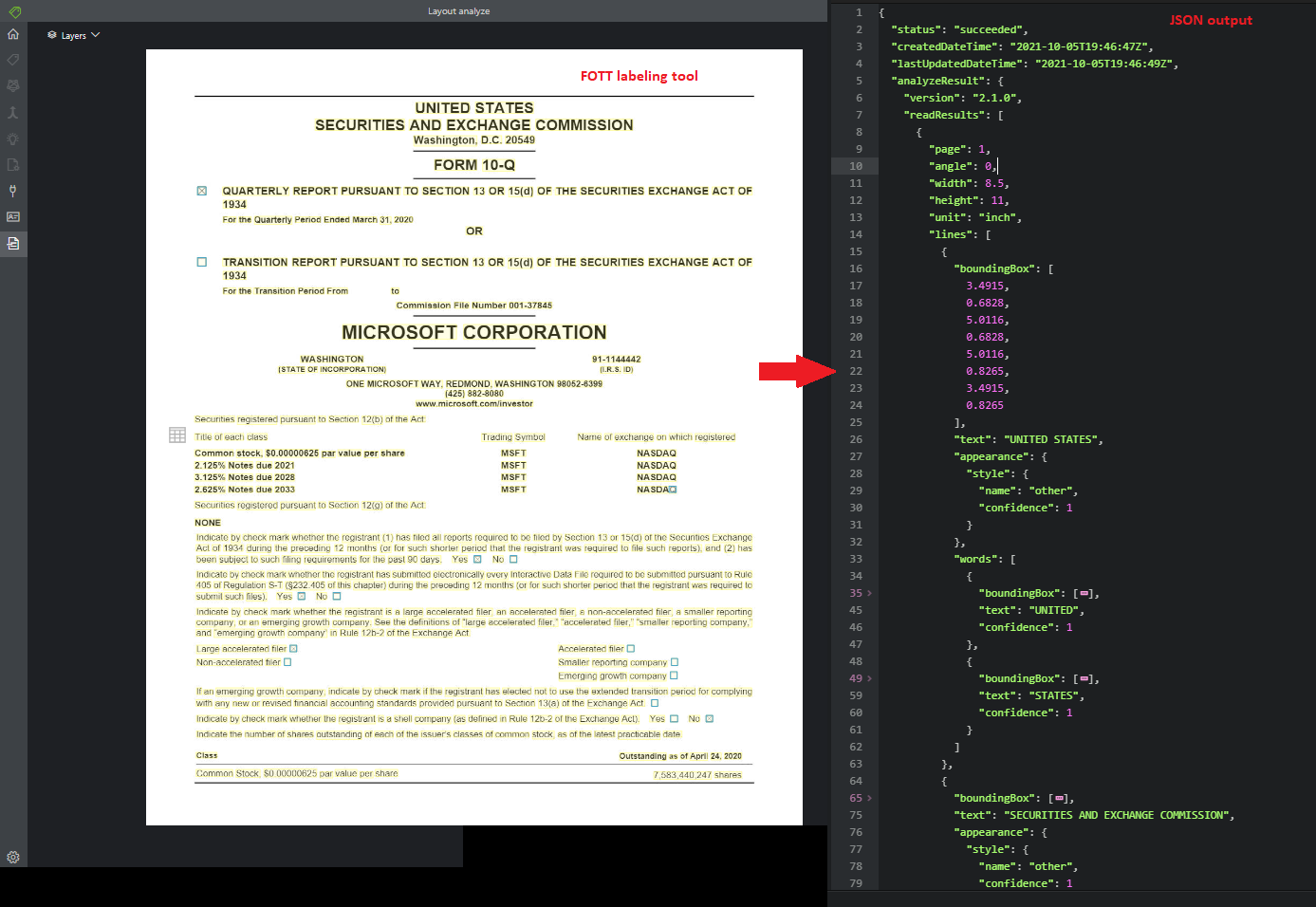
Invoice
O modelo de fatura analisa e extrai informações importantes das faturas de vendas. A API analisa faturas em vários formatos e extrai informações importantes, como nome do cliente, endereço de cobrança, data de vencimento e valor devido.
Fatura de amostra processada usando a ferramenta Etiquetagem de amostra:
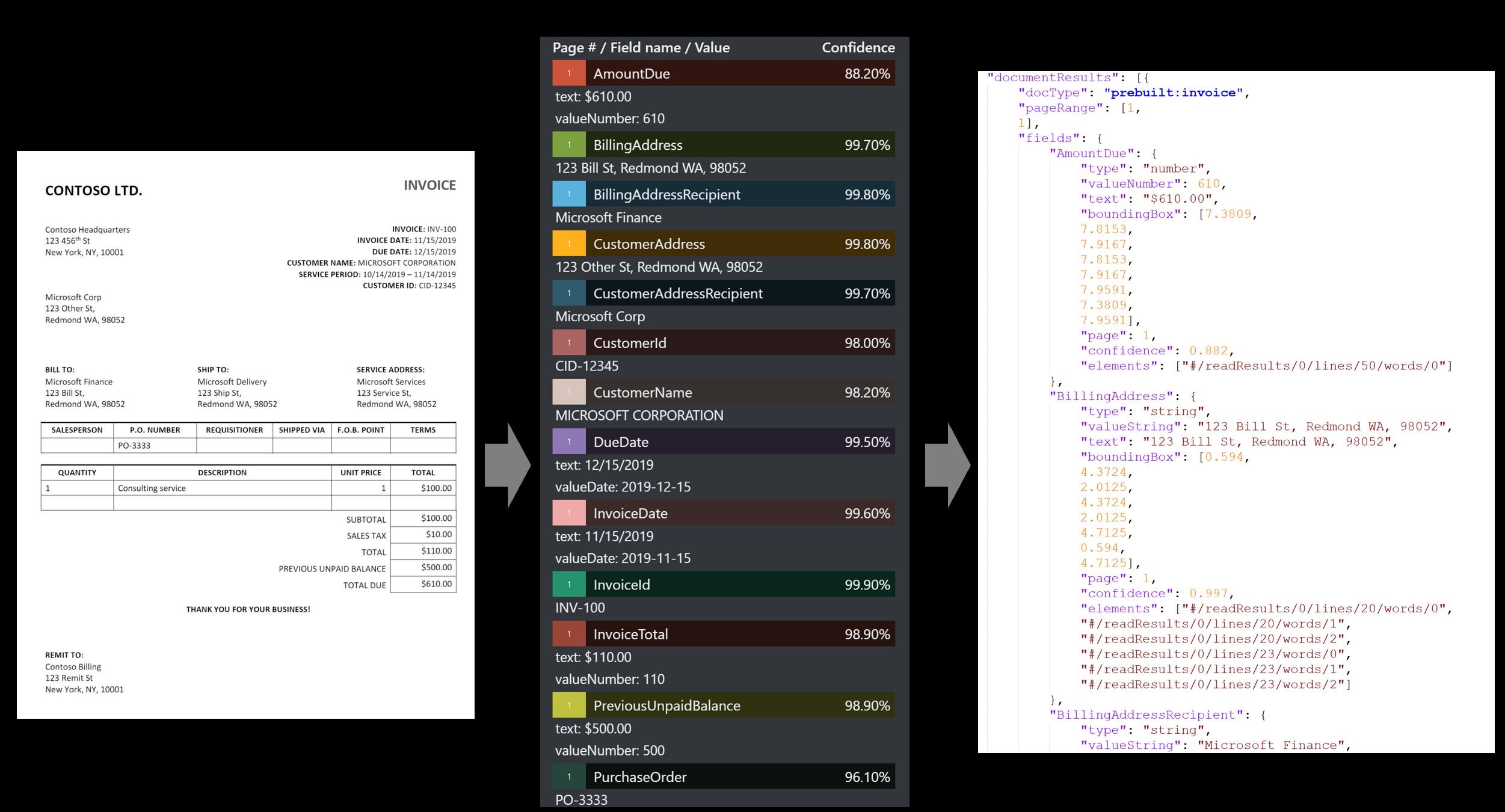
Recibo
- O modelo de recibo analisa e extrai informações importantes de recibos de venda impressos e manuscritos.
Recibo de amostra processado usando a ferramenta de etiquetagem de amostras:
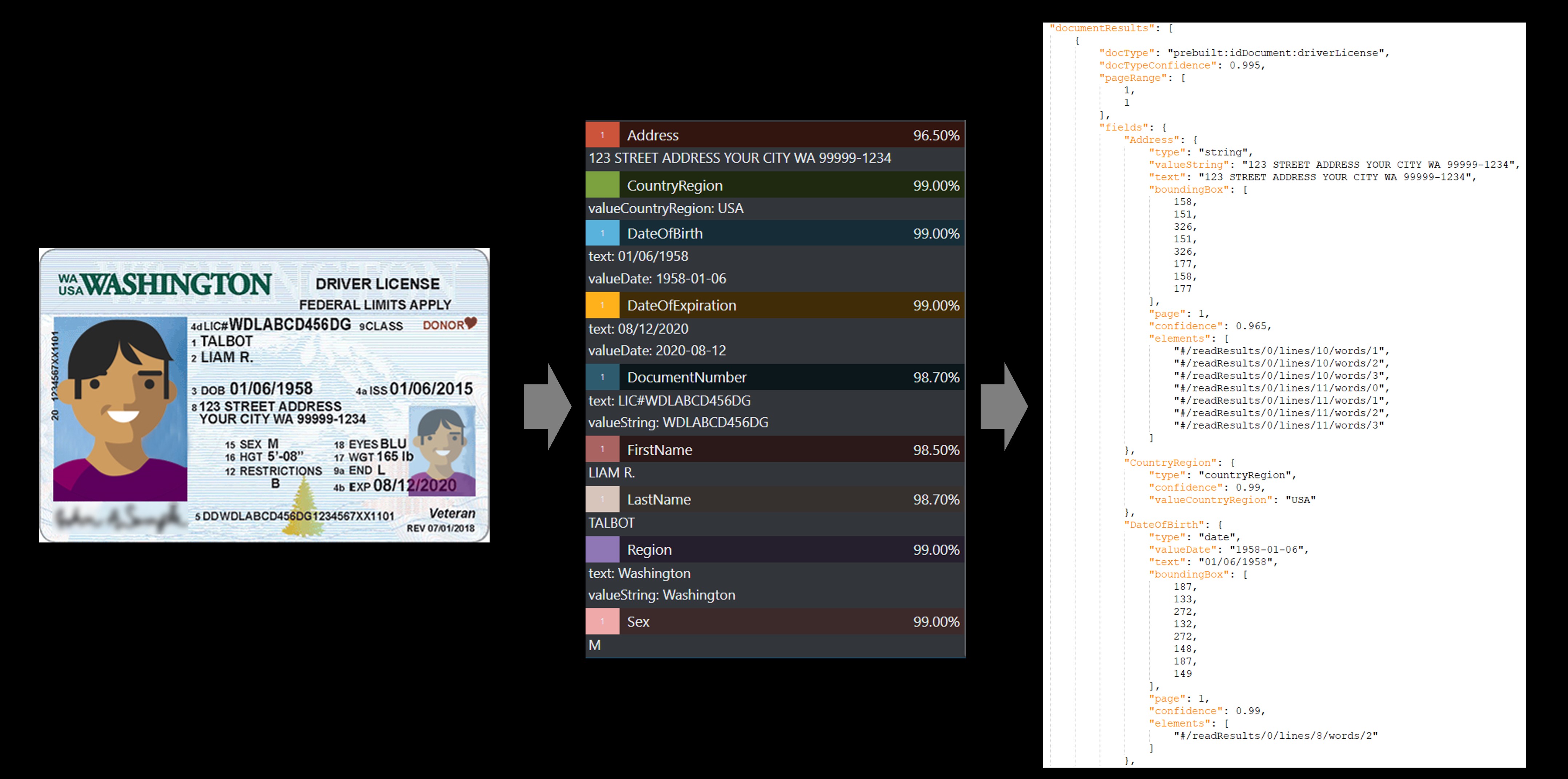
Documento de identificação
O modelo de documento ID analisa e extrai informações importantes dos seguintes documentos:
Carteiras de Motorista dos EUA (todos os 50 estados e Distrito de Colúmbia)
Páginas biográficas de passaportes internacionais (excluindo vistos e outros documentos de viagem). A API analisa documentos de identidade e extratos
Exemplo de Carteira de Motorista dos EUA processada usando a ferramenta Etiquetagem de Amostra:
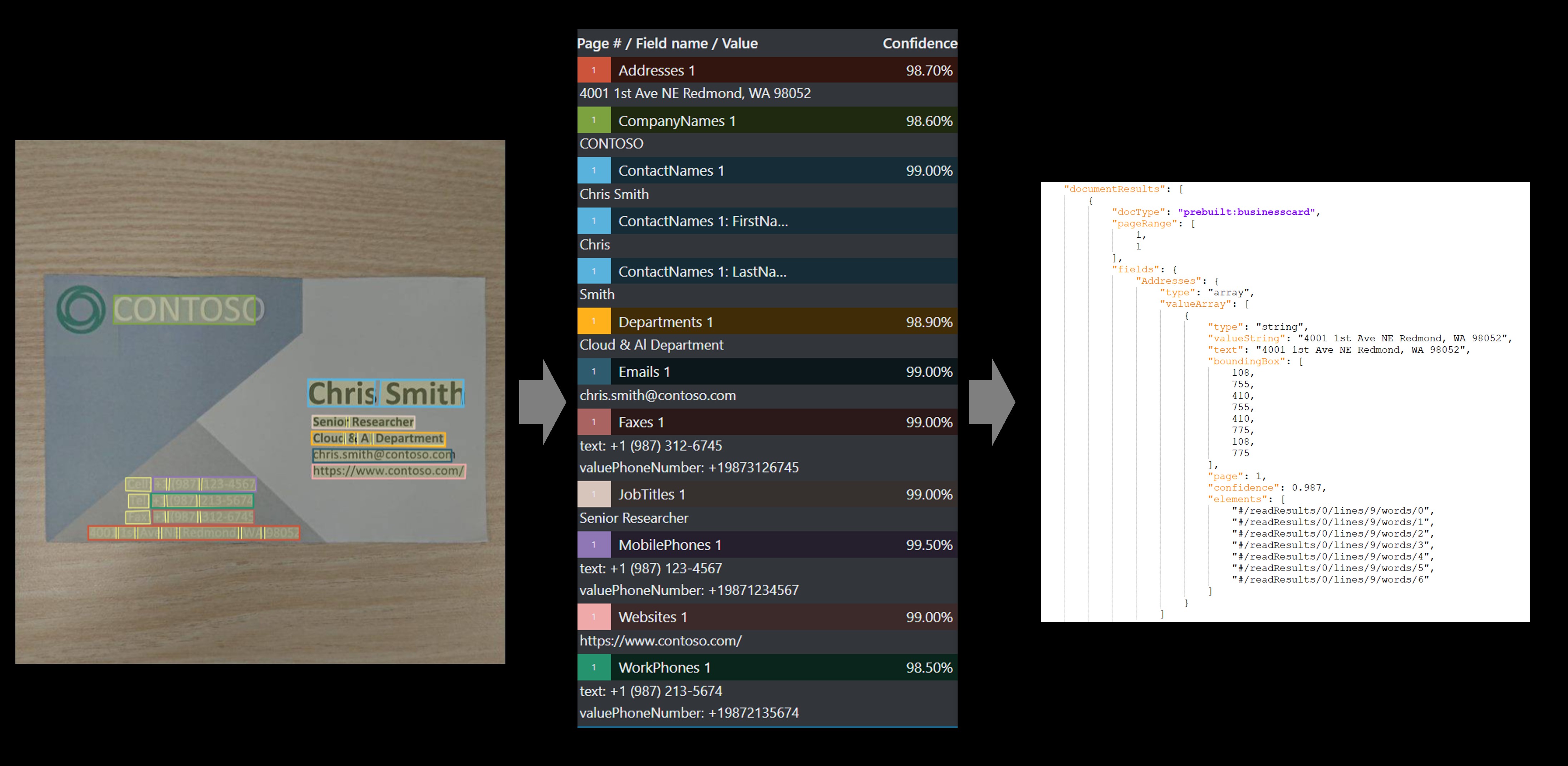
Cartão de visita
O modelo de cartão de visita analisa e extrai informações importantes de imagens de cartão de visita.
Cartão de visita de amostra processado usando a ferramenta Etiquetagem de amostra:
Personalizado
- Modelos personalizados analisam e extraem dados de formulários e documentos específicos para o seu negócio. A API é um programa de aprendizado de máquina treinado para reconhecer campos de formulário em seu conteúdo distinto e extrair pares chave-valor e dados de tabela. Você só precisa de cinco exemplos do mesmo tipo de formulário para começar e seu modelo personalizado pode ser treinado com ou sem conjuntos de dados rotulados.
Exemplo de processamento de modelo personalizado usando a ferramenta Etiquetagem de amostra:
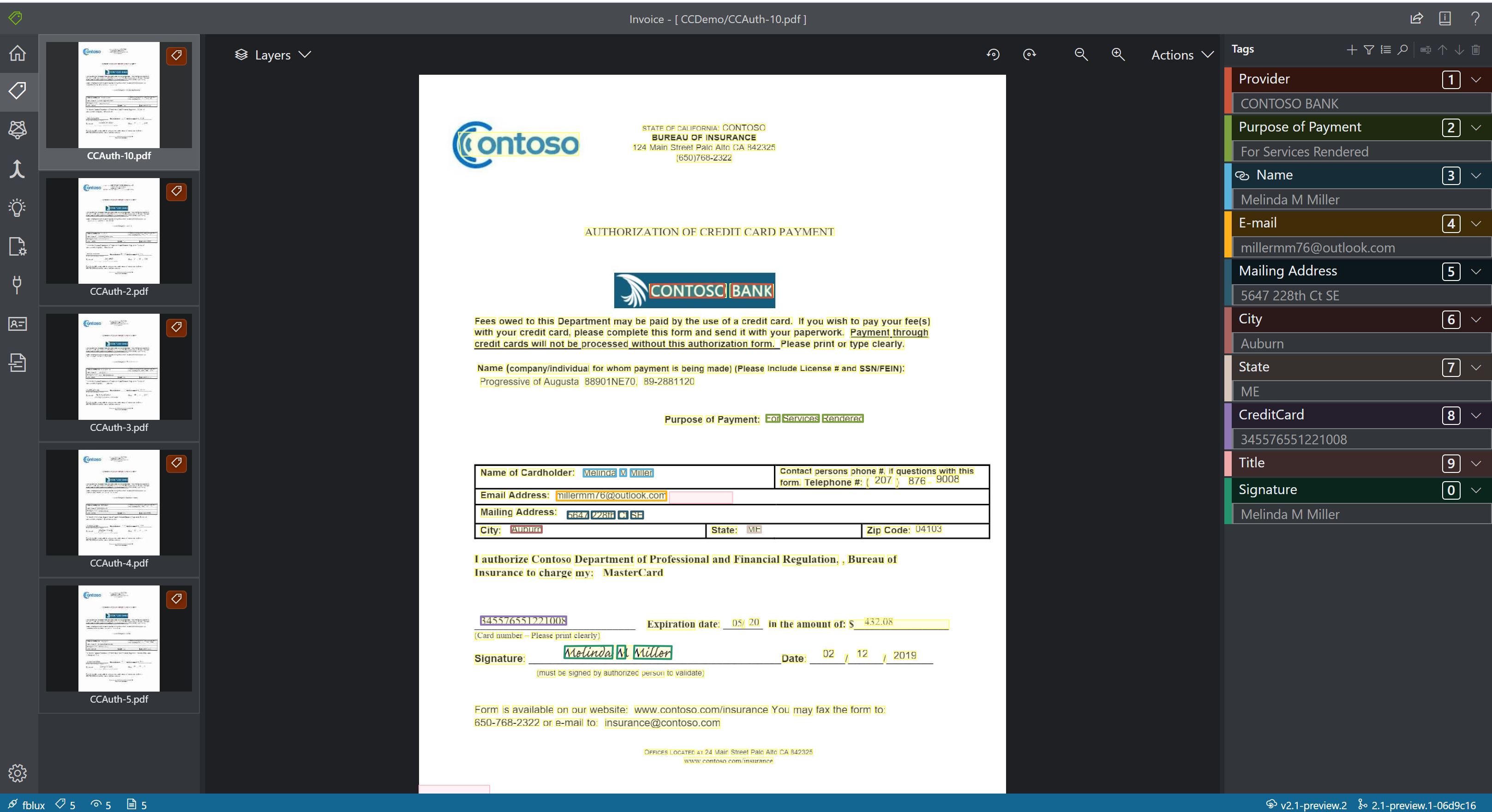
Modelo personalizado composto
Um modelo composto é criado pegando uma coleção de modelos personalizados e atribuindo-os a um único modelo criado a partir de seus tipos de formulário. Você pode atribuir vários modelos personalizados a um modelo composto chamado com um único ID de modelo. Pode atribuir até 100 modelos personalizados preparados a um único modelo composto.
Janela de diálogo Modelo composto usando a ferramenta Etiquetagem de amostra:
Extração de dados do modelo
| Modelo | Extração de texto | Deteção de idioma | Marcas de seleção | Tabelas | Parágrafos | Funções de parágrafo | Pares chave-valor | Campos |
|---|---|---|---|---|---|---|---|---|
| Esquema | ✓ | ✓ | ✓ | ✓ | ✓ | |||
| Fatura | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| Receção | ✓ | ✓ | ✓ | |||||
| Documento de identificação | ✓ | ✓ | ✓ | |||||
| Cartão de visita | ✓ | ✓ | ✓ | |||||
| Formulário personalizado | ✓ | ✓ | ✓ | ✓ | ✓ |
Requisitos de entrada
Formatos de ficheiro suportados:
Modelo PDF Imagem: JPEG/JPG,PNG,BMP,TIFF, ,HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLLida ✔ ✔ ✔ Esquema ✔ ✔ ✔ (2024-07-31-pré-visualização, 2024-02-29-pré-visualização, 2023-10-31-pré-visualização) Documento Geral ✔ ✔ Pré-criado ✔ ✔ Extração personalizada ✔ ✔ Classificação personalizada ✔ ✔ ✔ (2024-07-31-pré-visualização, 2024-02-29-pré-visualização) Para obter melhores resultados, forneça uma foto nítida ou uma digitalização de alta qualidade por documento.
Para PDF e TIFF, até 2.000 páginas podem ser processadas (com uma assinatura de nível gratuito, apenas as duas primeiras páginas são processadas).
O tamanho do arquivo para analisar documentos é de 500 MB para a camada paga (S0) e
4MB para a camada gratuita (F0).As dimensões da imagem devem estar entre 50 pixels x 50 pixels e 10.000 pixels x 10.000 pixels.
Se os seus PDFs forem bloqueados por uma palavra-passe, terá de remover o bloqueio antes da submetê-los.
A altura mínima do texto a ser extraído é de 12 pixels para uma imagem de 1024 x 768 pixels. Esta dimensão corresponde a cerca
8de texto pontual a 150 pontos por polegada (DPI).Para treinamento de modelo personalizado, o número máximo de páginas para dados de treinamento é 500 para o modelo de modelo personalizado e 50.000 para o modelo neural personalizado.
Para o treinamento do modelo de extração personalizado, o tamanho total dos dados de treinamento é de 50 MB para o modelo de modelo e
1GB para o modelo neural.Para treinamento de modelo de classificação personalizado, o tamanho total dos dados de treinamento é
1GB com um máximo de 10.000 páginas. Para 2024-07-31-preview e posterior, o tamanho total dos dados de treinamento é2GB com um máximo de 10.000 páginas.
Nota
A ferramenta Exemplo de etiquetagem não suporta o formato de ficheiro BMP. Esta é uma limitação da ferramenta e não do Serviço de Inteligência Documental.
Migração de versão
Você pode aprender a usar o Document Intelligence v3.0 em seus aplicativos seguindo nosso guia de migração do Document Intelligence v3.1
Próximos passos
Tente processar seus próprios formulários e documentos com o Document Intelligence Studio.
Conclua um início rápido do Document Intelligence e comece a criar um aplicativo de processamento de documentos na linguagem de desenvolvimento de sua escolha.
Tente processar seus próprios formulários e documentos com a ferramenta Document Intelligence Sample Labeling.
Conclua um início rápido do Document Intelligence e comece a criar um aplicativo de processamento de documentos na linguagem de desenvolvimento de sua escolha.