Como usar a Análise de Texto para a saúde
Importante
A Análise de Texto para integridade é um recurso fornecido "COMO ESTÁ" e "COM TODAS AS FALHAS". A Análise de Texto para Saúde não se destina nem é disponibilizada para uso como dispositivo médico, suporte clínico, ferramenta de diagnóstico ou outra tecnologia destinada a ser usada no diagnóstico, cura, mitigação, tratamento ou prevenção de doenças ou outras condições, e nenhuma licença ou direito é concedido pela Microsoft para usar esse recurso para tais fins. Esta capacidade não foi concebida nem se destina a ser implementada ou implementada como um substituto do aconselhamento médico profissional ou da opinião sobre cuidados de saúde, diagnóstico, tratamento ou julgamento clínico de um profissional de saúde, e não deve ser utilizada como tal. O cliente é o único responsável por qualquer uso de Análise de Texto para saúde. O cliente deve licenciar separadamente todo e qualquer vocabulário de origem que pretenda usar sob os termos definidos para esse UMLS, Metathesaurus, Contrato de Licença, Apêndice ou qualquer link equivalente futuro. O cliente é responsável por garantir a conformidade com esses termos de licença, incluindo quaisquer restrições geográficas ou outras restrições aplicáveis.
A Análise de Texto para a Saúde agora permite a extração de Determinantes Sociais da Saúde (SDOH) e menções étnicas no texto. Esta capacidade pode não abranger todos os potenciais SDOH e não deriva inferências com base no SDOH ou etnia (por exemplo, informações sobre o uso de substâncias são reveladas, mas o abuso de substâncias não é inferido). Todas as decisões que aproveitam os resultados da Análise de Texto para a saúde que afetam os indivíduos ou a alocação de recursos (incluindo, mas não limitado a, aquelas relacionadas à cobrança, recursos humanos ou tratamento gerenciando cuidados) devem ser tomadas com supervisão humana e não ser baseadas apenas nas descobertas do modelo. O objetivo da capacidade de extração de SDOH e etnia é ajudar os provedores a melhorar os resultados de saúde e não deve ser usado para estigmatizar ou tirar inferências negativas sobre os usuários ou consumidores de dados SDOH, ou populações de pacientes além do propósito declarado de ajudar os provedores a melhorar os resultados de saúde.
A Análise de Texto para Saúde pode ser usada para extrair e rotular informações médicas relevantes de textos não estruturados, como anotações médicas, resumos de alta, documentos clínicos e registros de saúde eletrônicos. O serviço executa reconhecimento de entidade nomeada, extração de relação, vinculação de entidade e deteção de asserção para descobrir insights do texto de entrada. Para obter informações sobre as pontuações de confiança devolvidas, consulte a nota de transparência.
Gorjeta
Se você quiser testar o recurso sem escrever nenhum código, use o Language Studio.
Há duas maneiras de chamar o serviço:
- Um contêiner do Docker (síncrono)
- Usando a API baseada na Web e bibliotecas de cliente (assíncronas)
Opções de desenvolvimento
Para usar a Análise de Texto para integridade, envie texto não estruturado bruto para análise e manipule a saída da API em seu aplicativo. A análise é realizada no estado em que se encontra, sem personalização adicional ao modelo usado em seus dados. Há duas maneiras de usar a Análise de Texto para integridade:
| Opção de desenvolvimento | Description |
|---|---|
| Estúdio de linguagem | O Language Studio é uma plataforma baseada na Web que permite que você tente vincular entidades com exemplos de texto sem uma conta do Azure e seus próprios dados quando você se inscreve. Para obter mais informações, consulte o site do Language Studio ou o início rápido do language studio. |
| API REST ou biblioteca de cliente (SDK do Azure) | Integre a Análise de Texto para integridade em seus aplicativos usando a API REST ou a biblioteca de cliente disponível em vários idiomas. Para obter mais informações, consulte o Guia de início rápido da Análise de Texto para integridade. |
| Contêiner do Docker | Use o contêiner do Docker disponível para implantar esse recurso localmente. Esses contêineres docker permitem que você aproxime o serviço de seus dados por motivos de conformidade, segurança ou outros motivos operacionais. |
Línguas de entrada
A Análise de Texto para integridade suporta inglês, além de vários idiomas que estão atualmente em visualização. Você pode usar a API hospedada ou implantar a API em um contêiner, conforme detalhado em Análise de texto para suporte a idiomas de integridade.
Envio de dados
Para enviar uma solicitação de API, você precisará do ponto de extremidade e da chave do recurso de idioma.
Nota
Você pode encontrar a chave e o ponto de extremidade para seu recurso de idioma no portal do Azure. Eles estarão localizados na página Chave e ponto final do recurso, em Gerenciamento de recursos.
A análise é realizada aquando da receção do pedido. Se você enviar uma solicitação usando a API REST ou a biblioteca do cliente, os resultados serão retornados de forma assíncrona. Se você estiver usando o contêiner do Docker, eles serão retornados de forma síncrona.
Ao usar esse recurso de forma assíncrona, os resultados da API ficam disponíveis por 24 horas a partir do momento em que a solicitação foi ingerida e são indicados na resposta. Após esse período de tempo, os resultados são limpos e não estão mais disponíveis para recuperação.
Enviando uma solicitação FHIR (Fast Healthcare Interoperability Resources)
Fast Healthcare Interoperability Resources (FHIR) é o padrão de comunicação da indústria de saúde desenvolvido pela organização Health Level Seven International (HL7). A norma define os formatos de dados (recursos) e a estrutura da API para o intercâmbio de dados eletrónicos de cuidados de saúde. Para receber seu resultado usando a estrutura FHIR , você deve enviar a versão FHIR no corpo da solicitação da API.
| Nome do Parâmetro | Type | valor |
|---|---|---|
| fhirVersão | string | 4.0.1 |
Obtendo resultados do recurso
Dependendo da sua solicitação de API e dos dados enviados para a Análise de Texto para integridade, você terá:
- Reconhecimento de Entidades Nomeadas
- Extração de Relação
- Associação de Entidades
- Deteção de asserção
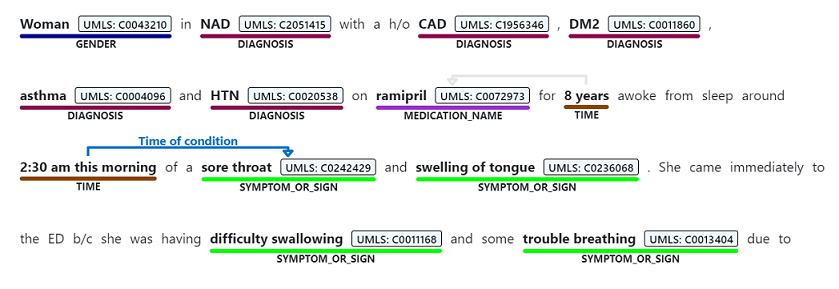
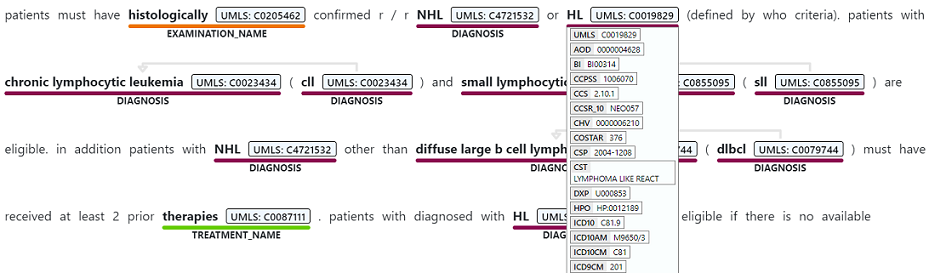
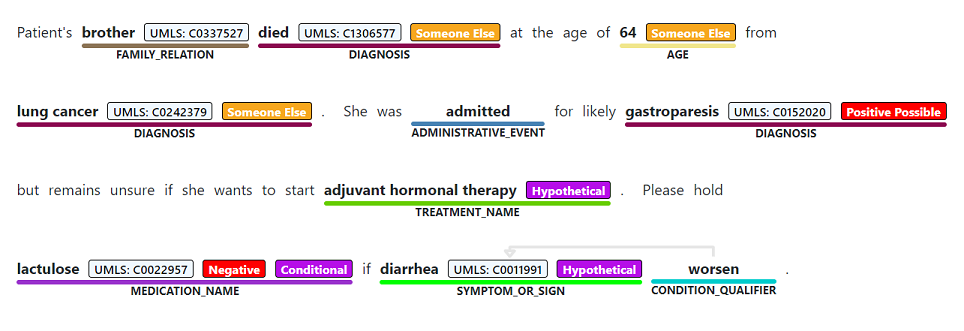
O reconhecimento de entidade nomeada é usado para executar uma extração semântica de palavras e frases mencionadas de texto não estruturado que estão associadas a qualquer um dos tipos de entidade suportados, como diagnóstico, nome do medicamento, sintoma/sinal ou idade.

Limites de serviço e dados
Para obter informações sobre o tamanho e o número de solicitações que você pode enviar por minuto e segundo, consulte o artigo Limites de serviço.