Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Com a fala personalizada, você pode avaliar e melhorar a precisão do reconhecimento de fala para seus aplicativos e produtos. Um modelo de fala personalizado pode ser usado para conversão de fala em texto em tempo real, tradução de fala e transcrição em lote.
Pronto para usar, o reconhecimento de fala utiliza um Modelo de Linguagem Universal como um modelo base que é treinado com dados de propriedade da Microsoft e reflete a linguagem falada comumente usada. O modelo base é pré-treinado com dialetos e fonética representando vários domínios comuns. Quando você faz uma solicitação de reconhecimento de fala, o modelo base mais recente para cada idioma suportado é usado por padrão. O modelo base funciona bem na maioria dos cenários de reconhecimento de fala.
Um modelo personalizado pode ser usado para aumentar o modelo base para melhorar o reconhecimento do vocabulário específico do domínio específico para o aplicativo, fornecendo dados de texto para treinar o modelo. Ele também pode ser usado para melhorar o reconhecimento com base nas condições específicas de áudio do aplicativo, fornecendo dados de áudio com transcrições de referência.
Você também pode treinar um modelo com texto estruturado quando os dados seguem um padrão, para especificar pronúncias personalizadas e para personalizar a formatação de texto de exibição com normalização de texto inverso personalizada, reescrita personalizada e filtragem de palavrões personalizada.
Como é que isto funciona?
Com a fala personalizada, você pode carregar seus próprios dados, testar e treinar um modelo personalizado, comparar a precisão entre modelos e implantar um modelo em um ponto de extremidade personalizado.
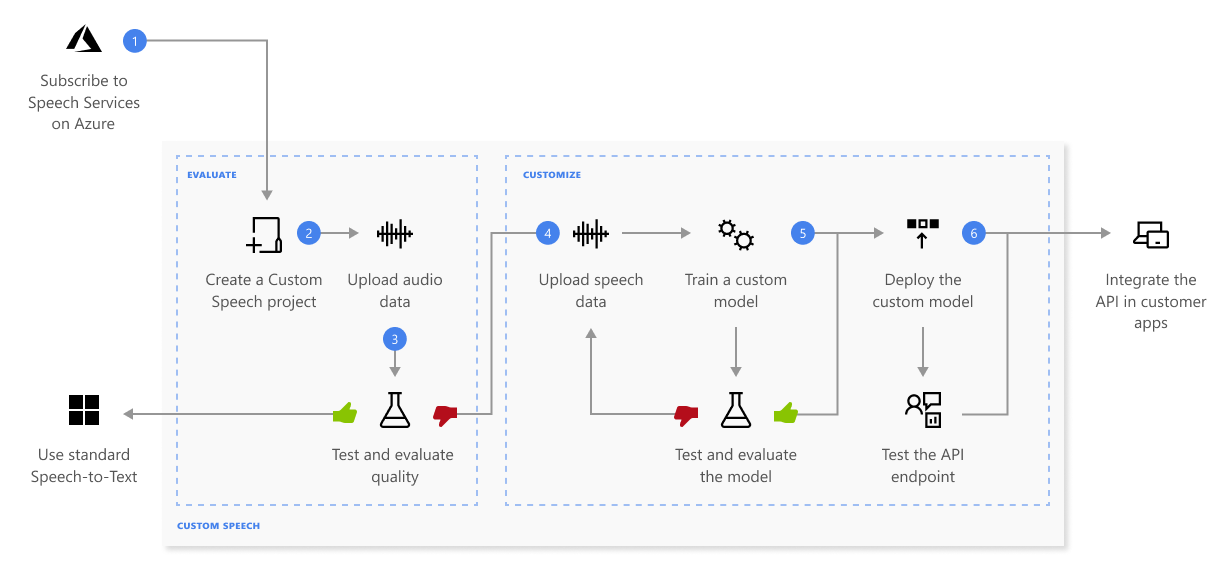
Aqui estão mais informações sobre a sequência de etapas mostrada no diagrama anterior:
Crie um projeto e escolha um modelo. Utilize um que é criado no portal do Azure. Se você treinar um modelo personalizado com dados de áudio, selecione um recurso de serviço em uma região com hardware dedicado para treinar dados de áudio. Para obter mais informações, consulte notas de rodapé na tabela de regiões .
Carregue dados de teste. Carregue dados de teste para avaliar a oferta de conversão de fala em texto para seus aplicativos, ferramentas e produtos.
Treine um modelo. Forneça transcrições escritas e texto relacionado, juntamente com os dados de áudio correspondentes. Testar um modelo antes e depois do treinamento é opcional, mas recomendado.
Nota
Você paga pelo uso do modelo de fala personalizado e pela hospedagem de pontos finais. Você também será cobrado pelo treinamento de modelo de fala personalizado se o modelo base tiver sido criado em 1º de outubro de 2023 e posterior. Você não será cobrado pelo treinamento se o modelo base tiver sido criado antes de outubro de 2023. Para obter mais informações, consulte Preços do Azure AI Speech e a seção Cobrar pela adaptação no guia de migração de fala para texto 3.2.
Qualidade de reconhecimento de testes. Use o Speech Studio para reproduzir o áudio carregado e inspecionar a qualidade do reconhecimento de fala dos dados do teste.
Modelo de teste quantitativamente. Avaliar e melhorar a precisão do modelo de fala para texto. O serviço de Fala fornece uma taxa de erro quantitativa de palavras (WER), que você pode usar para determinar se é necessário mais treinamento.
Implante um modelo. Quando estiver satisfeito com os resultados do teste, implante o modelo em um ponto de extremidade personalizado. Exceto para transcrição em lote, você deve implantar um ponto de extremidade personalizado para usar um modelo de fala personalizado.
Gorjeta
Um ponto de extremidade de implantação hospedado não é necessário para usar fala personalizada com a API de transcrição em lote. Você pode conservar recursos se o modelo de fala personalizado for usado apenas para transcrição em lote. Para obter mais informações, consulte Preços do serviço de fala.
Escolha o seu modelo
Existem algumas abordagens para usar modelos de fala personalizados:
- O modelo base fornece reconhecimento de fala preciso pronto para uso em uma variedade de cenários. Os modelos básicos são atualizados periodicamente para melhorar a precisão e a qualidade. Recomendamos que, se você usar modelos básicos, use os modelos básicos padrão mais recentes. Se um recurso de personalização necessário estiver disponível apenas com um modelo mais antigo, você poderá escolher um modelo básico mais antigo.
- Um modelo personalizado aumenta o modelo base para incluir vocabulário específico do domínio compartilhado em todas as áreas do domínio personalizado.
- Vários modelos personalizados podem ser usados quando o domínio personalizado tem várias áreas, cada uma com um vocabulário específico.
Uma maneira recomendada de ver se o modelo base é suficiente é analisar a transcrição produzida a partir do modelo base e compará-la com uma transcrição gerada por humanos para o mesmo áudio. Você pode comparar as transcrições e obter uma pontuação de taxa de erro de palavras (WER). Se a pontuação WER for alta, recomenda-se treinar um modelo personalizado para reconhecer as palavras identificadas incorretamente.
Vários modelos são recomendados se o vocabulário variar entre as áreas de domínio. Por exemplo, os comentadores olímpicos relatam vários eventos, cada um associado ao seu próprio vernáculo. Como o vocabulário de cada evento olímpico difere significativamente dos outros, a construção de um modelo personalizado específico para um evento aumenta a precisão, limitando os dados de enunciação relativos a esse evento específico. Como resultado, o modelo não precisa filtrar dados não relacionados para fazer uma correspondência. Independentemente disso, o treinamento ainda requer uma variedade decente de dados de treinamento. Inclua áudio de vários comentaristas que têm diferentes sotaques, sexo, idade, etc.
Estabilidade e ciclo de vida do modelo
Um modelo base ou modelo personalizado implantado em um ponto de extremidade usando fala personalizada é corrigido até que você decida atualizá-lo. A precisão e a qualidade do reconhecimento de fala permanecem consistentes, mesmo quando um novo modelo básico é lançado. Isso permite que você bloqueie o comportamento de um modelo específico até decidir usar um modelo mais recente.
Se você treinar seu próprio modelo ou usar um instantâneo de um modelo base, você pode usar o modelo por um tempo limitado. Para obter mais informações, consulte Ciclo de vida do modelo e do ponto final.
IA responsável
Um sistema de IA inclui não apenas a tecnologia, mas também as pessoas que a usam, as pessoas que são afetadas por ela e o ambiente em que é implantado. Leia as notas de transparência para saber mais sobre o uso e a implantação responsáveis da IA em seus sistemas.
- Nota de transparência e casos de uso
- Características e limitações
- Integração e utilização responsável
- Dados, privacidade e segurança