Repetir anti-padrão do Storm
Quando um serviço está indisponível ou ocupado, fazer com que os clientes repitam as suas ligações com demasiada frequência pode fazer com que o serviço tenha dificuldades em recuperar e pode piorar o problema. Também não faz sentido repetir para sempre, uma vez que os pedidos são normalmente válidos apenas por um período de tempo definido.
Descrição do problema
Na cloud, por vezes, os serviços têm problemas e ficam indisponíveis para os clientes ou têm de limitar ou limitar a taxa dos clientes. Embora seja uma boa prática para os clientes repetirem ligações falhadas aos serviços, é importante que não repitam com demasiada frequência ou durante demasiado tempo. É pouco provável que as repetições sejam bem-sucedidas num curto período de tempo, uma vez que os serviços provavelmente não terão recuperado. Além disso, os serviços podem ser colocados sob ainda mais stress quando muitas tentativas de ligação são feitas enquanto tentam recuperar, e as tentativas de ligação repetidas podem até sobrecarregar o serviço e piorar o problema subjacente.
O exemplo seguinte ilustra um cenário em que um cliente se liga a uma API baseada no servidor. Se o pedido não for bem-sucedido, o cliente tentará novamente imediatamente e continuará a tentar para sempre. Muitas vezes, este tipo de comportamento é mais subtil do que neste exemplo, mas aplica-se o mesmo princípio.
public async Task<string> GetDataFromServer()
{
while(true)
{
var result = await httpClient.GetAsync(string.Format("http://{0}:8080/api/...", hostName));
if (result.IsSuccessStatusCode) break;
}
// ... Process result.
}
Como resolver o problema
As aplicações cliente devem seguir algumas das melhores práticas para evitar causar um storm de repetição.
- Limite o número de tentativas de repetição e não continue a tentar durante um longo período de tempo. Embora possa parecer fácil escrever um
while(true)ciclo, quase de certeza que não quer repetir durante um longo período de tempo, uma vez que a situação que levou ao início do pedido provavelmente mudou. Na maioria das aplicações, tentar novamente durante alguns segundos ou minutos é suficiente. - Coloque o cursor entre tentativas de repetição. Se um serviço não estiver disponível, é pouco provável que volte a tentar de imediato. Aumente gradualmente a quantidade de tempo que espera entre tentativas, por exemplo, através de uma estratégia de recuo exponencial.
- Processe erros corretamente. Se o serviço não estiver a responder, considere se faz sentido abortar a tentativa e devolver um erro ao utilizador ou autor da chamada do componente. Considere estes cenários de falha ao conceber a sua aplicação.
- Considere utilizar o padrão disjuntor automático, concebido especificamente para ajudar a evitar tempestades de repetição.
- Se o servidor fornecer um
retry-aftercabeçalho de resposta, certifique-se de que não tenta tentar novamente até que o período de tempo especificado tenha decorrido. - Utilize SDKs oficiais ao comunicar com os serviços do Azure. Geralmente, estes SDKs têm políticas de repetição incorporadas e proteções contra causar ou contribuir para a repetição de tempestades. Se estiver a comunicar com um serviço que não tem um SDK ou em que o SDK não processa a lógica de repetição corretamente, considere utilizar uma biblioteca como Polly (para .NET) ou tentar novamente (para JavaScript) para processar a lógica de repetição corretamente e evitar escrever o código.
- Se estiver a executar num ambiente que o suporte, utilize uma malha de serviço (ou outra camada de abstração) para enviar chamadas de saída. Normalmente, estas ferramentas, como o Dapr, suportam políticas de repetição e seguem automaticamente as melhores práticas, como recuar após tentativas repetidas. Esta abordagem significa que não tem de escrever o código de repetição manualmente.
- Considere a criação de batches de pedidos e a utilização do conjunto de pedidos, sempre que disponível. Muitos SDKs processam a criação de lotes de pedidos e o conjunto de ligações em seu nome, o que reduzirá o número total de tentativas de ligação de saída que a sua aplicação faz, embora ainda tenha de ter cuidado para não repetir estas ligações com demasiada frequência.
Os serviços também devem proteger-se contra tempestades de repetição.
- Adicione uma camada de gateway para que possa desligar as ligações durante um incidente. Este é um exemplo do padrão Bulkhead. O Azure fornece vários serviços de gateway diferentes para diferentes tipos de soluções, incluindo o Front Door, Gateway de Aplicação e Gestão de API.
- Limitar os pedidos no gateway, o que garante que não aceita tantos pedidos que os componentes de back-end não podem continuar a operar.
- Se estiver a limitar, envie um
retry-aftercabeçalho de volta para ajudar os clientes a compreender quando voltar a utilizar as respetivas ligações.
Considerações
- Os clientes devem considerar o tipo de erro devolvido. Alguns tipos de erro não indicam uma falha do serviço, mas indicam que o cliente enviou um pedido inválido. Por exemplo, se uma aplicação cliente receber uma
400 Bad Requestresposta de erro, repetir o mesmo pedido provavelmente não irá ajudar, uma vez que o servidor está a informar que o pedido não é válido. - Os clientes devem considerar o período de tempo que faz sentido voltar a tentar ligações. O período de tempo durante o qual deve tentar novamente será impulsionado pelos seus requisitos empresariais e se pode propagar razoavelmente um erro para um utilizador ou autor da chamada. Na maioria das aplicações, tentar novamente durante alguns segundos ou minutos é suficiente.
Como detetar o problema
Do ponto de vista de um cliente, os sintomas deste problema podem incluir tempos de resposta ou processamento muito longos, juntamente com telemetria que indica tentativas repetidas de repetir a ligação.
Do ponto de vista de um serviço, os sintomas deste problema podem incluir um grande número de pedidos de um cliente num curto espaço de tempo ou um grande número de pedidos de um único cliente durante a recuperação de falhas. Os sintomas também podem incluir dificuldades na recuperação do serviço ou falhas em cascata contínuas do serviço logo após uma falha ter sido reparada.
Diagnóstico de exemplo
As secções seguintes ilustram uma abordagem para detetar um potencial storm de repetição, tanto do lado do cliente como do lado do serviço.
Identificar a partir da telemetria do cliente
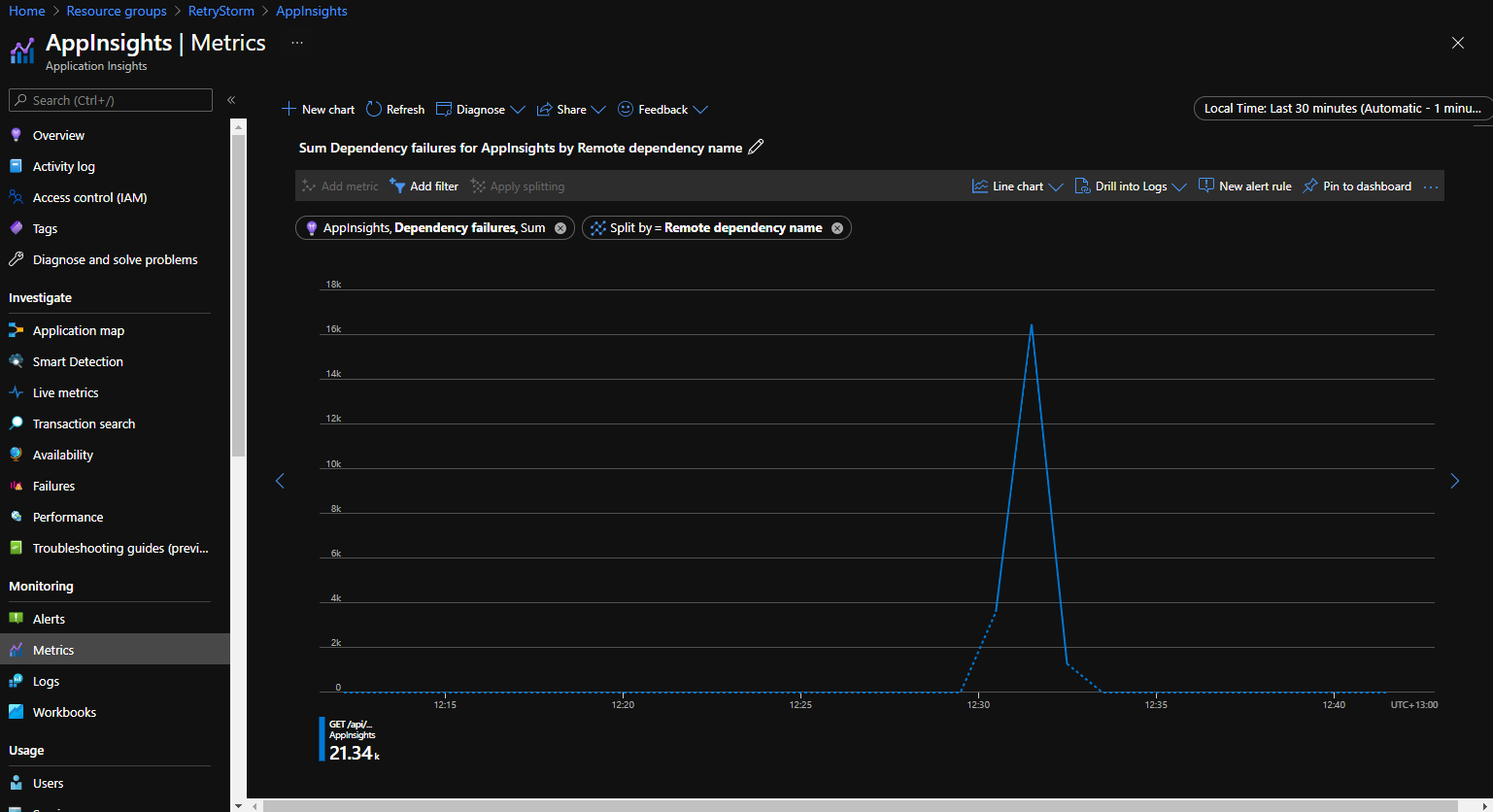
Aplicação Azure Insights regista a telemetria das aplicações e disponibiliza os dados para consulta e visualização. As ligações de saída são controladas como dependências e as informações sobre as mesmas podem ser acedidas e listadas para identificar quando um cliente está a fazer um grande número de pedidos de saída para o mesmo serviço.
O gráfico seguinte foi retirado do separador Métricas no portal do Application Insights e a apresentar a métrica Falhas de dependência dividida pelo nome de dependência remota. Isto ilustra um cenário em que havia um grande número (mais de 21 000) de tentativas de ligação falhadas a uma dependência num curto espaço de tempo.
Identificar a partir da telemetria do servidor
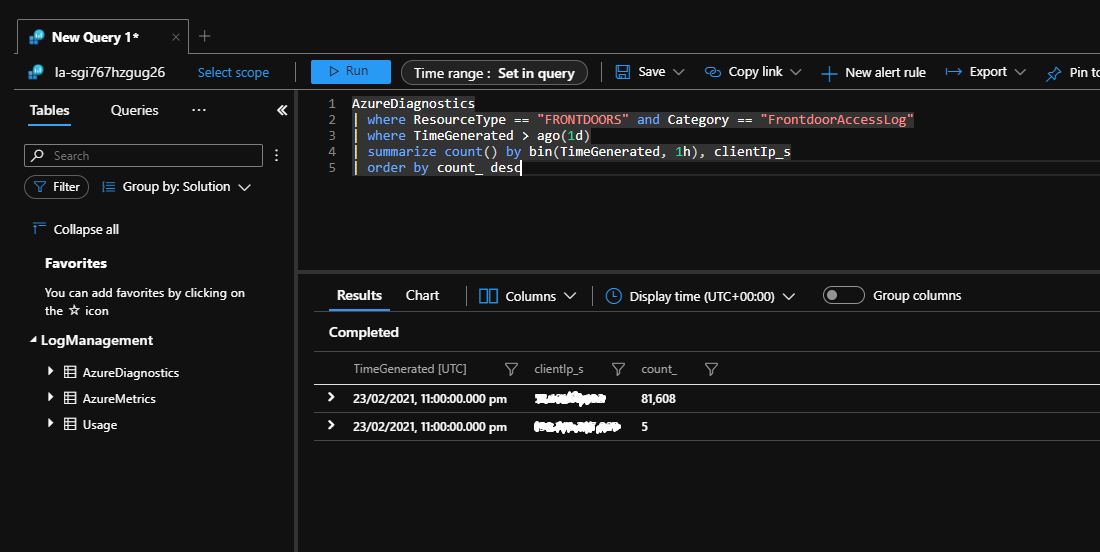
As aplicações de servidor podem ser capazes de detetar um grande número de ligações de um único cliente. No exemplo seguinte, o Azure Front Door funciona como um gateway para uma aplicação e foi configurado para registar todos os pedidos numa área de trabalho do Log Analytics.
A seguinte consulta Kusto pode ser executada no Log Analytics. Identificará os endereços IP do cliente que enviaram um grande número de pedidos para a aplicação no último dia.
AzureDiagnostics
| where ResourceType == "FRONTDOORS" and Category == "FrontdoorAccessLog"
| where TimeGenerated > ago(1d)
| summarize count() by bin(TimeGenerated, 1h), clientIp_s
| order by count_ desc
A execução desta consulta durante um storm de repetição mostra um grande número de tentativas de ligação a partir de um único endereço IP.
Recursos relacionados
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários