Em muitas soluções de grande escala, os dados são divididos em partições que podem ser gerenciadas e acessadas separadamente. A criação de partições pode melhorar a escalabilidade, reduzir a contenção e otimizar o desempenho. Também pode proporcionar um mecanismo para dividir os dados por padrão de utilização. Por exemplo, pode arquivar dados mais antigos num armazenamento de dados mais barato.
No entanto, a estratégia de particionamento deve ser escolhida cuidadosamente para maximizar os benefícios, minimizando os efeitos adversos.
Nota
Neste artigo, o termo criação de partições significa o processo de dividir fisicamente os dados em arquivos de dados separados. Não é igual à criação de partições de tabela do SQL Server.
Porquê criar partições de dados?
Melhorar a escalabilidade. Quando dimensiona um sistema de base de dados individual, este acabará por atingir um limite de hardware físico. Se você dividir os dados em várias partições, cada uma hospedada em um servidor separado, poderá expandir o sistema quase indefinidamente.
Melhorar o desempenho. As operações de acesso aos dados em cada partição ocorrem através de um volume de dados mais pequeno. Feito corretamente, o particionamento pode tornar seu sistema mais eficiente. As operações que afetam mais do que uma partição podem ser executadas em paralelo.
Melhorar a segurança. Em alguns casos, você pode separar dados confidenciais e não confidenciais em partições diferentes e aplicar controles de segurança diferentes aos dados confidenciais.
Fornecer flexibilidade operacional. O particionamento oferece muitas oportunidades para ajustar as operações, maximizar a eficiência administrativa e minimizar os custos. Por exemplo, pode definir diferentes estratégias de gestão, monitorização, cópia de segurança e restauro, e outras tarefas administrativas, com base na importância dos dados de cada partição.
Corresponder o arquivo de dados ao padrão de utilização. A criação de partições permite que cada partição seja implementada num tipo diferente de arquivo de dados, com base no custo e nas funcionalidades incorporadas que o arquivo de dados oferece. Por exemplo, grandes dados binários podem ser armazenados em armazenamento de blob, enquanto dados mais estruturados podem ser mantidos em um banco de dados de documentos. Para obter mais informações, consulte Escolher o armazenamento de dados correto.
Melhorar a disponibilidade. Separar os dados por vários servidores evita um ponto único de falha. Se uma instância falhar, apenas os dados nessa partição não estarão disponíveis. As operações das outras partições podem continuar. Para armazenamentos de dados de plataforma gerenciada como serviço (PaaS), essa consideração é menos relevante, porque esses serviços são projetados com redundância integrada.
Estruturar partições
Existem três estratégias típicas para particionar dados:
Criação de partições horizontais (frequentemente denominado fragmentação). Nessa estratégia, cada partição é um armazenamento de dados separado, mas todas as partições têm o mesmo esquema. Cada partição é conhecida como fragmento e contém um subconjunto específico dos dados, como todos os pedidos de um conjunto específico de clientes.
Criação de partições verticais. Nesta estratégia, cada partição contém um subconjunto dos campos para os itens no arquivo de dados. Os campos são divididos de acordo com o respetivo padrão de utilização. Por exemplo, os campos acedidos frequentemente podem ser colocados numa partição vertical e os campos acedidos com menos frequência podem ser colocados noutra.
Criação de partições funcionais. Nesta estratégia, os dados são agregados de acordo com a forma como são utilizados por cada contexto vinculado no sistema. Por exemplo, um sistema de comércio eletrônico pode armazenar dados de fatura em uma partição e dados de inventário de produtos em outra.
Essas estratégias podem ser combinadas, e recomendamos que você as considere todas ao projetar um esquema de particionamento. Por exemplo, pode dividir os dados em partições horizontais e, em seguida, utilizar a criação de partições verticais para subdividir os dados de cada partição horizontal.
Criação de partições horizontais (fragmentação)
A Figura 1 mostra o particionamento horizontal ou fragmentação. Neste exemplo, os dados de inventário dos produtos estão divididos em partições horizontais com base na chave de produto. Cada partição horizontal contém os dados para um intervalo contínuo de chaves de partição horizontal (A-G e H-Z), organizadas por ordem alfabética. O compartilhamento distribui a carga por mais computadores, o que reduz a contenção e melhora o desempenho.
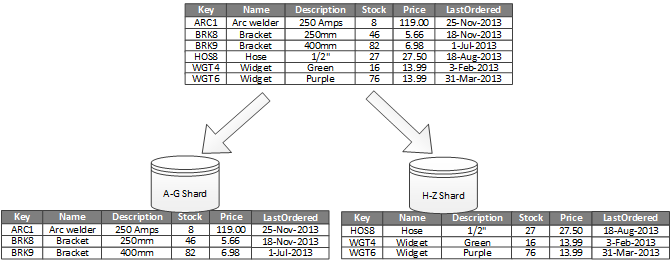
Figura 1 - Particionamento horizontal (fragmentação) de dados com base em uma chave de partição.
O fator mais importante é a escolha de uma chave de fragmentação. Pode ser difícil alterar a chave depois de o sistema estar em funcionamento. A chave deve garantir que os dados sejam particionados para distribuir a carga de trabalho da forma mais uniforme possível pelos fragmentos.
Os estilhaços não precisam ter o mesmo tamanho. É mais importante equilibrar o número de solicitações. Alguns fragmentos podem ser muito grandes, mas cada item tem um número baixo de operações de acesso. Outras partições horizontais poderão ser mais pequenas, mas cada item ser acedido muito mais frequentemente. Também é importante garantir que um único fragmento não exceda os limites de escala (em termos de capacidade e recursos de processamento) do armazenamento de dados.
Evite criar partições "quentes" que podem afetar o desempenho e a disponibilidade. Por exemplo, usar a primeira letra do nome de um cliente causa uma distribuição desequilibrada, porque algumas letras são mais comuns. Em vez disso, utilize um hash de um identificador do cliente para distribuir os dados de forma mais uniforme pelas partições.
Escolha uma chave de fragmentação que minimize quaisquer requisitos futuros para dividir fragmentos grandes, aglutinar fragmentos pequenos em partições maiores ou alterar o esquema. Estas operações podem ser muito morosas e podem requerer que coloque uma ou mais partições horizontais offline enquanto estão a ser executadas.
Se as partições horizontais forem replicadas, poderá ser possível manter algumas das réplicas online, enquanto outras são divididas, unidas ou reconfiguradas. No entanto, o sistema pode precisar limitar as operações que podem ser executadas durante a reconfiguração. Por exemplo, os dados nas réplicas podem ser marcados como somente leitura para evitar inconsistências de dados.
Para obter mais informações sobre particionamento horizontal, consulte Padrão de compartilhamento.
Criação de partições verticais
O uso mais comum para particionamento vertical é reduzir os custos de E/S e desempenho associados à busca de itens que são acessados com frequência. A Figura 2 mostra um exemplo de criação de partições verticais. Neste exemplo, diferentes propriedades de um item são armazenadas em partições diferentes. Uma partição contém dados que são acessados com mais frequência, incluindo nome do produto, descrição e preço. Outra partição contém dados de inventário: a contagem de estoque e a data do último pedido.
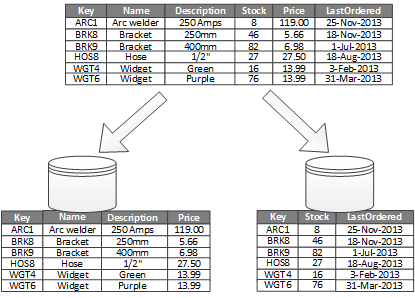
Figura 2 - Particionamento vertical de dados pelo seu padrão de uso.
Neste exemplo, a aplicação consulta regularmente o nome, a descrição e o preço do produto ao apresentar os detalhes do produto aos clientes. A contagem de estoque e a data da última ordem são mantidas em uma partição separada porque esses dois itens são comumente usados juntos.
Outras vantagens do particionamento vertical:
Os dados relativamente lentos (nome do produto, descrição e preço) podem ser separados dos dados mais dinâmicos (nível de estoque e data do último pedido). Dados em movimento lento são um bom candidato para um aplicativo armazenar em cache na memória.
Dados confidenciais podem ser armazenados em uma partição separada com controles de segurança adicionais.
O particionamento vertical pode reduzir a quantidade de acesso simultâneo necessária.
A criação de partições verticais funciona ao nível da entidade dentro de um arquivo de dados, normalizando parcialmente uma entidade para a dividir, de um item amplo para um conjunto de itens estreitos. Idealmente, é adequada aos arquivos de dados orientados para colunas, como o HBase e Cassandra. Se for pouco provável que os dados numa coleção de colunas sejam alterados, pode também considerar a utilização de arquivos de colunas no SQL Server.
Criação de partições funcionais
Quando é possível identificar um contexto delimitado para cada área de negócios distinta em um aplicativo, o particionamento funcional é uma maneira de melhorar o isolamento e o desempenho de acesso a dados. Outro uso comum para particionamento funcional é separar dados de leitura-gravação de dados somente leitura. A Figura 3 mostra uma descrição geral da criação de partições funcionais em que os dados de inventário estão separados dos dados de cliente.
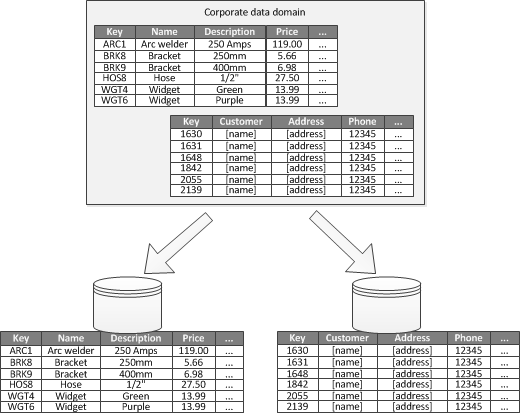
Figura 3 - Particionamento funcional de dados por contexto delimitado ou subdomínio.
Esta estratégia de criação de partições pode ajudar a reduzir a contenção do acesso aos dados nas diferentes partes de um sistema.
Estruturar partições para escalabilidade
É essencial considerar o tamanho e a carga de trabalho de cada partição e equilibrá-los de modo a que os dados sejam distribuídos de modo a alcançar a escalabilidade máxima. No entanto, também tem de particionar os dados para que não excedam os limites de dimensionamento de um único arquivo de partições.
Ao estruturar as partições para escalabilidade, siga estes passos:
- Analise a aplicação para compreender os padrões de acesso aos dados, como o tamanho do conjunto de resultados devolvido por cada consulta, a frequência de acesso, a latência inerente e os requisitos de processamento de computação do lado do servidor. Em muitos casos, algumas entidades principais irão requerer a maioria dos recursos de processamento.
- Utilize esta análise para determinar as metas de escalabilidade atuais e futuras, como o tamanho dos dados e a carga de trabalho. Em seguida, distribua os dados pelas partições para ir de encontro à meta de escalabilidade. Para particionamento horizontal, escolher a chave de estilhaço certa é importante para garantir que a distribuição seja uniforme. Para obter mais informações, consulte o padrão de fragmentação.
- Certifique-se de que cada partição tem recursos suficientes para lidar com os requisitos de escalabilidade, em termos de tamanho e taxa de transferência de dados. Dependendo do armazenamento de dados, pode haver um limite na quantidade de espaço de armazenamento, poder de processamento ou largura de banda de rede por partição. Se for provável que os requisitos excedam esses limites, talvez seja necessário refinar sua estratégia de particionamento ou dividir os dados ainda mais, possivelmente combinando duas ou mais estratégias.
- Monitore o sistema para verificar se os dados são distribuídos conforme o esperado e se as partições podem lidar com a carga. O uso real nem sempre corresponde ao que uma análise prevê. Se assim for, pode ser possível reequilibrar as partições, ou então redesenhar algumas partes do sistema para obter o equilíbrio necessário.
Alguns ambientes de nuvem alocam recursos em termos de limites de infraestrutura. Certifique-se de que os limites do seu limiar selecionado fornecem espaço suficiente para qualquer crescimento previsto do volume de dados, em termos de armazenamento de dados, capacidade de processamento e largura de banda.
Por exemplo, se você usar o armazenamento de tabelas do Azure, haverá um limite para o volume de solicitações que podem ser tratadas por uma única partição em um determinado período de tempo. (Para obter mais informações, consulte Metas de desempenho e escalabilidade de armazenamento do Azure.) Um fragmento ocupado pode exigir mais recursos do que uma única partição pode suportar. Em caso afirmativo, o fragmento pode precisar ser reparticionado para distribuir a carga. Se o tamanho total ou a taxa de transferência dessas tabelas exceder a capacidade de uma conta de armazenamento, talvez seja necessário criar contas de armazenamento adicionais e distribuir as tabelas por essas contas.
Estruturar partições para desempenho de consultas
Muitas vezes, o desempenho das consultas pode ser aumentado através da utilização de conjuntos de dados mais pequenos e ao executar consultas paralelas. Cada partição deve conter uma pequena proporção do conjunto completo de dados. Esta redução de volume pode melhorar o desempenho das consultas. No entanto, a criação de partições não é uma alternativa para estruturar e configurar uma base de dados adequadamente. Por exemplo, certifique-se de que tem os índices necessários.
Ao estruturar as partições para desempenho de consultas, siga estes passos:
Verifique os requisitos e o desempenho da aplicação:
- Use os requisitos de negócios para determinar as consultas críticas que sempre devem ser executadas rapidamente.
- Monitorize o sistema para identificar quaisquer consultas com execução lenta.
- Descubra quais consultas são realizadas com mais frequência. Mesmo que uma única consulta tenha um custo mínimo, o consumo cumulativo de recursos pode ser significativo.
Particione os dados que estão a causar o desempenho lento:
- Limite o tamanho de cada partição de forma a que o tempo de resposta de consulta esteja dentro da meta.
- Se você usar particionamento horizontal, projete a chave de estilhaço para que o aplicativo possa selecionar facilmente a partição correta. Isto impede que a consulta tenha de analisar cada partição.
- Considere a localização de uma partição. Se for possível, tente manter os dados nas partições que estão geograficamente próximas das aplicações e dos utilizadores que lhes acedem.
Se uma entidade tiver requisitos de débito e de desempenho de consultas, utilize a criação de partições funcionais com base nessa entidade. Se isto não satisfazer os requisitos, aplique também a criação de partições horizontais. Na maioria dos casos, uma única estratégia de particionamento será suficiente, mas em alguns casos é mais eficiente combinar ambas as estratégias.
Considere executar consultas em paralelo entre partições para melhorar o desempenho.
Estruturar partições para disponibilidade
A criação de partições de dados pode melhorar a disponibilidade das aplicações, garantindo que todo o conjunto de dados não constitui um ponto único de falha e que os subconjuntos individuais do conjunto de dados podem ser geridos de forma independente.
Considere os seguintes fatores que afetam a disponibilidade:
O quão críticos os dados são para as operações empresariais. Identifique quais dados são informações comerciais críticas, como transações, e quais dados são dados operacionais menos críticos, como arquivos de log.
Considere armazenar dados críticos em partições altamente disponíveis com um plano de backup apropriado.
Estabelecer procedimentos separados de gestão e monitorização para os diferentes conjuntos de dados.
Coloque os dados com o mesmo nível de criticidade na mesma partição, para que possa ser feita uma cópia de segurança dos mesmos em conjunto, com uma frequência adequada. Por exemplo, as partições que contêm dados de transação podem precisar de backup com mais frequência do que as partições que contêm informações de log ou rastreamento.
Como as partições individuais podem ser geridas. Estruturar partições para suportar a gestão e manutenção independentes proporciona várias vantagens. Por exemplo:
Se uma partição falhar, ela pode ser recuperada independentemente sem aplicativos que acessam dados em outras partições.
A criação de partições de dados por área geográfica permite que as tarefas de manutenção agendada ocorram fora das horas de ponta para cada localização. Certifique-se de que as partições não são muito grandes para evitar que qualquer manutenção planejada seja concluída durante esse período.
Se pretende replicar dados críticos em partições. Esta estratégia pode melhorar a disponibilidade e o desempenho, mas também pode introduzir problemas de coerência. Leva tempo para sincronizar as alterações com cada réplica. Durante este período, partições diferentes irão conter valores de dados diferentes.
Considerações de design de aplicações
O particionamento adiciona complexidade ao design e desenvolvimento do seu sistema. Considere a criação de partições como uma parte fundamental da conceção do sistema, mesmo se o sistema apenas contiver inicialmente uma só partição. Se você abordar o particionamento como uma reflexão posterior, será mais desafiador porque você já tem um sistema ativo para manter:
- A lógica de acesso aos dados terá de ser modificada.
- Grandes quantidades de dados existentes podem precisar ser migradas, para distribuí-los entre partições.
- Os usuários esperam poder continuar usando o sistema durante a migração.
Em alguns casos, a criação de partições não é considerada importante porque o conjunto de dados inicial é pequeno e pode facilmente ser processado por um único servidor. Isso pode ser verdade para algumas cargas de trabalho, mas muitos sistemas comerciais precisam se expandir à medida que o número de usuários aumenta.
Além disso, não são apenas grandes armazenamentos de dados que se beneficiam do particionamento. Por exemplo, um arquivo de dados pequeno poderá ser intensamente acedido por centenas de clientes em simultâneo. A criação de partições de dados nesta situação pode ajudar a reduzir a contenção e melhorar o débito.
Ao estruturar um esquema de partições de dados, considere os seguintes pontos:
Minimize as operações de acesso a dados entre partições. Sempre que possível, mantenha juntos os dados das operações de base de dados mais comuns em cada partição para minimizar as operações de acesso aos dados entre partições. Consultar entre partições pode ser mais demorado do que consultar dentro de uma única partição, mas otimizar partições para um conjunto de consultas pode afetar negativamente outros conjuntos de consultas. Se você precisar consultar entre partições, minimize o tempo de consulta executando consultas paralelas e agregando os resultados dentro do aplicativo. (Essa abordagem pode não ser possível em alguns casos, como quando o resultado de uma consulta é usado na próxima consulta.)
Considere replicar dados de referência estáticos. Se as consultas usarem dados de referência relativamente estáticos, como tabelas de código postal ou listas de produtos, considere replicar esses dados em todas as partições para reduzir operações de pesquisa separadas em partições diferentes. Essa abordagem também pode reduzir a probabilidade de os dados de referência se tornarem um conjunto de dados "quente", com tráfego intenso de todo o sistema. No entanto, há um custo adicional associado à sincronização de quaisquer alterações nos dados de referência.
Minimize as junções entre partições. Sempre que possível, minimize os requisitos de integridade referencial através de partições verticais e funcionais. Nesses esquemas, o aplicativo é responsável por manter a integridade referencial entre partições. As consultas que unem dados em várias partições são ineficientes porque o aplicativo normalmente precisa executar consultas consecutivas com base em uma chave e, em seguida, em uma chave estrangeira. Em vez disso, considere replicar ou anular a normalização dos dados relevantes. Se forem necessárias junções entre partições, execute consultas paralelas nas partições e junte os dados dentro do aplicativo.
Adote a consistência eventual. Avalie se a consistência forte é, de facto, um requisito. Uma abordagem comum em sistemas distribuídos é implementar consistência eventual. Os dados em cada partição são atualizados separadamente e a lógica da aplicação assegura que as atualizações são todas concluídas com êxito. Lida igualmente com as inconsistência que possam surgir de consultar dados enquanto uma operação eventualmente consistente está em execução.
Considere a forma como as consultas localizam a partição correta. Se uma consulta tiver de analisar todas as partições para localizar os dados necessários, há um impacto significativo no desempenho, mesmo quando estão em execução várias consultas paralelas. Com o particionamento vertical e funcional, as consultas podem especificar naturalmente a partição. O particionamento horizontal, por outro lado, pode dificultar a localização de um item, porque cada fragmento tem o mesmo esquema. Uma solução típica para manter um mapa que é usado para procurar o local do estilhaço para itens específicos. Este mapa pode ser implementado na lógica de fragmentação da aplicação ou mantido pelo arquivo de dados, se este suportar a fragmentação transparente.
Considere reequilibrar periodicamente os fragmentos. Com o particionamento horizontal, o rebalanceamento de fragmentos pode ajudar a distribuir os dados uniformemente por tamanho e por carga de trabalho para minimizar pontos de acesso, maximizar o desempenho da consulta e contornar limitações de armazenamento físico. No entanto, esta é uma tarefa complexa que requer, muitas vezes, a utilização de uma ferramenta ou processo personalizado.
Replicar partições. Se replicar cada partição, proporciona proteção adicional contra falhas. Se uma única réplica falhar, as consultas podem ser direcionadas para uma cópia em funcionamento.
Se atingir os limites físicos de uma estratégia de criação de partições, poderá ter de expandir a escalabilidade para um nível diferente. Por exemplo, se estiver a criar partições ao nível de base de dados, poderá ter de localizar ou replicar partições em várias bases de dados. Se a criação de partições já se encontra ao nível de base de dados e as limitações físicas forem um problema, poderá significar que tem de localizar ou replicar partições em várias contas de alojamento.
Evite as transações que acedem a dados em várias partições. Alguns arquivos de dados implementam a consistência transacional e a integridade para operações que modificam dados, mas apenas quando os dados estão localizados numa única partição. Se precisar de suporte transacional entre várias partições, provavelmente terá de implementar isto como parte da sua lógica de aplicação porque a maioria dos sistemas de partição não fornecem suporte nativo.
Todos os arquivos de dados requerem alguma gestão operacional e monitorização da atividade. As tarefas podem variar entre carregar dados, fazer cópias de segurança e restaurar dados, reorganizar dados e garantir que o sistema está a funcionar correta e eficientemente.
Considere os seguintes fatores que afetam a gestão operacional:
Como implementar tarefas de gestão e operacionais adequadas quando os dados estão particionados. Estas tarefas podem incluir fazer cópia de segurança e restaurar, arquivar dados, monitorizar o sistema e outras tarefas administrativas. Por exemplo, a manutenção da consistência lógica durante as operações de cópia de segurança e restauro pode ser um desafio.
Como carregar os dados para várias partições e adicionar novos dados provenientes de outras origens. Algumas ferramentas e utilitários podem não suportar as operações de dados em partição horizontal, como carregar dados para a partição correta.
Como arquivar e eliminar os dados regularmente. Para evitar o crescimento excessivo de partições, você precisa arquivar e excluir dados regularmente (como mensalmente). Poderá ser necessário transformar os dados para que correspondam a um esquema de arquivo diferente.
Como localizar problemas de integridade de dados. Considere a execução de um processo periódico para localizar quaisquer problemas de integridade de dados, como dados em uma partição que fazem referência a informações ausentes em outra. O processo pode tentar corrigir esses problemas automaticamente ou gerar um relatório para revisão manual.
Reequilibrar partições
À medida que um sistema amadurece, você pode ter que ajustar o esquema de particionamento. Por exemplo, partições individuais podem começar a receber um volume desproporcional de tráfego e tornar-se quentes, levando a uma contenção excessiva. Ou você pode ter subestimado o volume de dados em algumas partições, fazendo com que algumas partições se aproximem dos limites de capacidade.
Alguns armazenamentos de dados, como o Azure Cosmos DB, podem reequilibrar partições automaticamente. Em outros casos, o reequilíbrio é uma tarefa administrativa que consiste em duas etapas:
Determine uma nova estratégia de particionamento.
- Quais partições precisam ser divididas (ou possivelmente combinadas)?
- O que é a nova chave de partição?
Migre dados do esquema de particionamento antigo para o novo conjunto de partições.
Dependendo do armazenamento de dados, você poderá migrar dados entre partições enquanto elas estiverem em uso. Isso é chamado de migração online. Se isso não for possível, talvez seja necessário tornar as partições indisponíveis enquanto os dados são realocados (migração offline).
Migração offline
A migração offline normalmente é mais simples porque reduz as chances de ocorrência de contenção. Conceitualmente, a migração offline funciona da seguinte maneira:
- Marque a partição offline.
- Divida-mescle e mova os dados para as novas partições.
- Verify the data.
- Coloque as novas partições online.
- Remova a partição antiga.
Opcionalmente, você pode marcar uma partição como somente leitura na etapa 1, para que os aplicativos ainda possam ler os dados enquanto eles estão sendo movidos.
Migração online
A migração on-line é mais complexa de executar, mas menos perturbadora. O processo é semelhante à migração offline, exceto que a partição original não está marcada offline. Dependendo da granularidade do processo de migração (por exemplo, item por item versus fragmento por estilhaço), o código de acesso a dados nos aplicativos cliente pode ter que lidar com dados de leitura e gravação mantidos em dois locais, a partição original e a nova partição.
Próximos passos
- Saiba mais sobre estratégias de particionamento para serviços específicos do Azure. Para obter mais informações, consulte Estratégias de particionamento de dados.
- Metas de desempenho e escalabilidade do armazenamento do Azure
Recursos relacionados
Os seguintes padrões de design podem ser relevantes para o seu cenário:
O padrão de fragmentação descreve algumas estratégias comuns para fragmentação de dados.
O padrão de tabela de índice mostra como criar índices secundários sobre dados. Uma aplicação pode rapidamente obter dados com esta abordagem, através de consultas que não façam referência à chave primária de uma coleção.
O padrão de exibição materializado descreve como gerar exibições pré-preenchidas que resumem dados para dar suporte a operações de consulta rápidas. Esta abordagem poderá ser útil num arquivo de dados particionado, se as partições que contêm os dados que estão a ser resumidos estiverem distribuídas por vários sites.