Dados não relacionais e NoSQL
Um banco de dados não relacional é um banco de dados que não usa o esquema tabular de linhas e colunas encontrado na maioria dos sistemas de banco de dados tradicionais. Em vez disso, os bancos de dados não relacionais usam um modelo de armazenamento otimizado para os requisitos específicos do tipo de dados que estão sendo armazenados. Por exemplo, os dados podem ser armazenados como pares chave/valor simples, como documentos JSON ou como um gráfico que consiste em arestas e vértices.
O que todos esses armazenamentos de dados têm em comum é que eles não usam um modelo relacional. Além disso, tendem a ser mais específicos no tipo de dados que suportam e na forma como os dados podem ser consultados. Por exemplo, os armazenamentos de dados de séries temporais são otimizados para consultas em sequências de dados baseadas no tempo. No entanto, os armazenamentos de dados gráficos são otimizados para explorar relações ponderadas entre entidades. Nenhum dos dois formatos generalizaria bem a tarefa de gerenciar dados transacionais.
O termo NoSQL refere-se a armazenamentos de dados que não usam SQL para consultas. Em vez disso, os armazenamentos de dados usam outras linguagens de programação e construções para consultar os dados. Na prática, "NoSQL" significa "banco de dados não relacional", embora muitos desses bancos de dados ofereçam suporte a consultas compatíveis com SQL. No entanto, a estratégia de execução de consulta subjacente geralmente é muito diferente da maneira como um sistema de gerenciamento de banco de dados relacional tradicional (RDBMS) executaria a mesma consulta SQL.
Há variações nas implementações e especializações de bancos de dados NoSQL, como há variações nas capacidades de bancos de dados relacionais. Essas variações dão a cada implementação seus próprios pontos fortes primários e vêm com sua própria curva de aprendizado e recomendações de uso. As seções a seguir descrevem as principais categorias de banco de dados não relacional ou NoSQL.
Armazenamentos de dados de documentos
Um armazenamento de dados de documento gerencia um conjunto de campos de cadeia de caracteres nomeados e valores de dados de objeto em uma entidade que é referida como um documento. Esses armazenamentos de dados normalmente armazenam dados na forma de documentos JSON. Cada valor de campo pode ser um item escalar, como um número, ou um elemento composto, como uma lista ou uma coleção pai-filho. Os dados nos campos de um documento podem ser codificados de várias maneiras, incluindo XML, YAML, JSON, binário JSON (BSON), ou até mesmo armazenados como texto simples. Os campos dentro dos documentos são expostos ao sistema de gerenciamento de armazenamento, permitindo que um aplicativo consulte e filtre dados usando os valores nesses campos.
Normalmente, um documento contém todos os dados de uma entidade. Os itens que constituem uma entidade são específicos à aplicação. Por exemplo, uma entidade pode conter os detalhes de um cliente, uma encomenda ou uma combinação de ambos. Um único documento pode conter informações que seriam espalhadas por várias tabelas relacionais em um sistema de gerenciamento de banco de dados relacional (RDBMS). Um arquivo de documentos não requer que todos os documentos tenham a mesma estrutura. Esta abordagem de forma livre oferece muita flexibilidade. Por exemplo, os aplicativos podem armazenar dados diferentes em documentos em resposta a uma alteração nos requisitos de negócios.
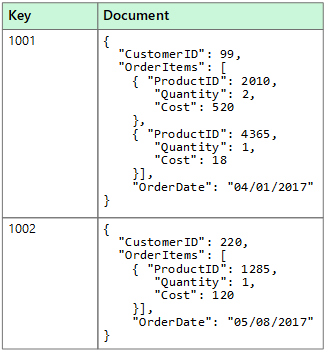
A aplicação pode utilizar a chave de documento para obter os documentos. A chave é um identificador exclusivo para o documento, que geralmente é colocado em hash, para ajudar a distribuir os dados uniformemente. Algumas bases de dados de documentos criam as chaves dos documentos automaticamente. Outras bases de dados permitem que especifique um atributo do documento para utilizar como chave. A aplicação também pode consultar documentos com base no valor de um ou mais campos. Algumas bases de dados de documentos suportam a indexação para facilitar a procura rápida de documentos com base em um ou mais campos indexados.
Muitas bases de dados de documentos suportam atualizações no local, permitindo às aplicações modificar os valores de campos específicos num documento sem que seja necessário reescrever todo o documento. As operações de leitura e gravação em vários campos em um único documento geralmente são atômicas.
Serviço do Azure relevante:
Armazenamentos de dados colunares
Um armazenamento de dados colunar ou de família de colunas organiza os dados em colunas e linhas. Em sua forma mais simples, um armazenamento de dados de família de colunas pode parecer muito semelhante a um banco de dados relacional, pelo menos conceitualmente. O verdadeiro poder de um banco de dados de família de colunas reside em sua abordagem desnormalizada para estruturar dados esparsos, que deriva da abordagem orientada a colunas para armazenar dados.
Você pode pensar em um armazenamento de dados de família de colunas como contendo dados tabulares com linhas e colunas, mas as colunas são divididas em grupos conhecidos como famílias de colunas. Cada família de colunas contém um conjunto de colunas que estão logicamente relacionadas e normalmente são recuperadas ou manipuladas como uma unidade. Outros dados que são acedidos separadamente podem ser armazenados em famílias de colunas separadas. Dentro de uma família de colunas, podem ser adicionadas colunas novas dinamicamente e as linhas podem ser dispersas (ou seja, uma linha não tem de ter um valor para cada coluna).
O diagrama seguinte mostra um exemplo com duas famílias de colunas, Identity e Contact Info. Os dados de uma única entidade têm a mesma chave de linha em cada família de colunas. Essa estrutura, onde as linhas de qualquer objeto em uma família de colunas podem variar dinamicamente, é um benefício importante da abordagem de família de colunas, tornando essa forma de armazenamento de dados altamente adequada para armazenar dados com esquemas variados.

Ao contrário dos arquivos de chaves/valores ou das bases de dados de documentos, a maioria das bases de dados de família de colunas armazenam fisicamente os dados por ordem de chave e não através do cálculo de um hash. A chave de linha é considerada o índice primário e permite o acesso baseado em chave através de uma chave específica ou de um intervalo de chaves. Algumas implementações permitem criar índices secundários sobre colunas específicas em uma família de colunas. Os índices secundários permitem recuperar dados por valor de colunas, em vez de chave de linha.
No disco, todas as colunas de uma família de colunas são armazenadas juntas no mesmo arquivo, com um número específico de linhas em cada arquivo. Com grandes conjuntos de dados, essa abordagem cria um benefício de desempenho reduzindo a quantidade de dados que precisam ser lidos do disco quando apenas algumas colunas são consultadas juntas de cada vez.
As operações de leitura e gravação de uma linha são tipicamente atômicas dentro de uma única família de colunas, embora algumas implementações forneçam atomicidade em toda a linha, abrangendo várias famílias de colunas.
Serviço do Azure relevante:
Armazenamentos de dados de chave/valor
Os arquivos de chaves/valores são essencialmente uma grande tabela hash. Cada valor de dados é associado a uma chave única e o arquivo de chaves/valores utiliza essa chave para armazenar os dados, mediante a utilização de um algoritmo hash adequado. O algoritmo hash é selecionado para fornecer uma distribuição uniforme das chaves com hash no armazenamento de dados.
A maioria dos arquivos de chaves/valores suportam apenas operações de consulta simples, inserção e eliminação. Para modificar um valor (parcial ou totalmente), as aplicações têm de substituir os dados atuais pelo valor inteiro. Na maioria das implementações, ler ou escrever um valor único é uma operação atómica. Se o valor for grande, a escrita pode demorar algum tempo.
As aplicações podem armazenar dados arbitrários como conjuntos de valores, embora alguns arquivos de chaves/valores imponham limites ao tamanho máximo dos valores. Os valores armazenados são opacos para o software de sistema de armazenamento. As aplicações têm de fornecer e interpretar todas as informações do esquema. Essencialmente, os valores são blobs e o arquivo de chaves/valores simplesmente obtém ou armazena o valor de acordo com a chave.
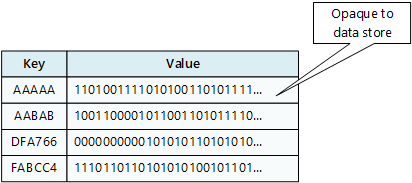
Os armazenamentos de chave/valor são altamente otimizados para aplicativos que executam pesquisas simples usando o valor da chave ou por uma variedade de chaves, mas são menos adequados para sistemas que precisam consultar dados em diferentes tabelas de chaves/valores, como unir dados em várias tabelas.
Os armazenamentos de chave/valor também não são otimizados para cenários em que a consulta ou filtragem por valores que não sejam de chave é importante, em vez de executar pesquisas baseadas apenas em chaves. Por exemplo, com um banco de dados relacional, você pode encontrar um registro usando uma cláusula WHERE para filtrar as colunas não-chave, mas os armazenamentos de chave/valores geralmente não têm esse tipo de capacidade de pesquisa de valores ou, se tiverem, isso requer uma verificação lenta de todos os valores.
Um arquivo de chaves/valores individual pode ser extremamente dimensionável, pois o arquivo de dados pode distribuir os dados facilmente para vários nós em máquinas separadas.
Serviços do Azure relevantes:
Armazenamentos de dados gráficos
Um armazenamento de dados de gráfico gerencia dois tipos de informações, nós e bordas. Os nós representam entidades e as bordas especificam as relações entre essas entidades. Os nós e os limites podem ter propriedades que disponibilizam informações sobre os mesmos, de forma semelhante às colunas em tabelas. Os limites também podem ter uma direção, a qual indica a natureza da relação.
O objetivo de um armazenamento de dados gráfico é permitir que um aplicativo execute consultas de forma eficiente que atravessam a rede de nós e bordas e analise as relações entre entidades. O diagrama a seguir mostra os dados pessoais de uma organização estruturados como um gráfico. As entidades são os funcionários e os departamentos e os limites indicam as relações hierárquicas e o departamento em que os funcionários trabalham. Neste grafo, as setas nas arestas mostram a direção das relações.
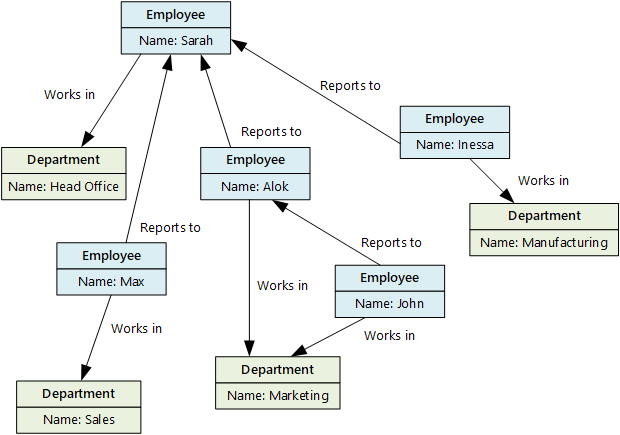
Essa estrutura facilita a realização de consultas como "Encontrar todos os funcionários que se reportam direta ou indiretamente a Sarah" ou "Quem trabalha no mesmo departamento que John?" Para gráficos grandes com muitas entidades e relacionamentos, você pode executar análises complexas rapidamente. Muitas bases de dados de gráficos disponibilizam uma linguagem de consultas que pode utilizar para atravessar uma rede de relações de forma eficiente.
Serviço do Azure relevante:
Armazenamentos de dados de séries cronológicas
Os dados de séries temporais são um conjunto de valores organizados por tempo, e um armazenamento de dados de séries temporais é otimizado para esse tipo de dados. Os armazenamentos de dados de séries temporais devem suportar um número muito alto de gravações, pois normalmente coletam grandes quantidades de dados em tempo real de um grande número de fontes. Os armazenamentos de dados de séries temporais são otimizados para armazenar dados de telemetria. Os cenários incluem sensores de IoT ou contadores de aplicações/sistemas. As atualizações são raras e eliminações são, muitas vezes, feitas em operações em massa.
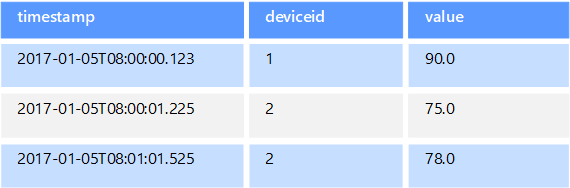
Apesar de os registos escritos numa base de dados de série temporal serem geralmente pequenos, o número de registos é, muitas vezes, grande, pelo que o tamanho total dos dados pode aumentar rapidamente. Os armazenamentos de dados de séries temporais também lidam com dados fora de ordem e que chegam tarde, indexação automática de pontos de dados e otimizações para consultas descritas em termos de janelas de tempo. Esse último recurso permite que as consultas sejam executadas em milhões de pontos de dados e vários fluxos de dados rapidamente, a fim de oferecer suporte a visualizações de séries temporais, que é uma maneira comum de consumir dados de séries temporais.
Serviços do Azure relevantes:
Armazenamentos de dados de objeto
Os armazenamentos de dados de objeto são otimizados para armazenar e recuperar grandes objetos binários ou blobs, como imagens, arquivos de texto, fluxos de vídeo e áudio, objetos e documentos de dados de aplicativos grandes e imagens de disco de máquina virtual. Um objeto consiste nos dados armazenados, alguns metadados e uma ID exclusiva para acessar o objeto. Os repositórios de objetos são projetados para suportar arquivos que são individualmente muito grandes, bem como fornecer grandes quantidades de armazenamento total para gerenciar todos os arquivos.
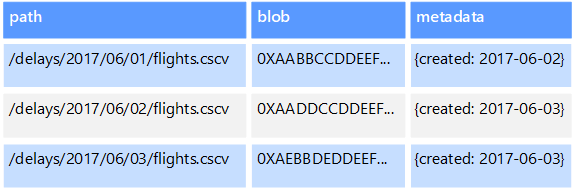
Alguns armazenamentos de dados de objeto replicam um determinado blob em vários nós de servidor, o que permite leituras paralelas rápidas. Esse processo, por sua vez, permite a consulta em expansão de dados contidos em arquivos grandes, porque vários processos, normalmente executados em servidores diferentes, podem consultar o arquivo de dados grande simultaneamente.
Um caso especial de armazenamentos de dados de objeto é o compartilhamento de arquivos de rede. O uso de compartilhamentos de arquivos permite que os arquivos sejam acessados através de uma rede usando protocolos de rede padrão, como o bloco de mensagens do servidor (SMB). Dada a segurança apropriada e os mecanismos de controle de acesso simultâneos, o compartilhamento de dados dessa maneira pode permitir que os serviços distribuídos forneçam acesso a dados altamente escalável para operações básicas e de baixo nível, como solicitações simples de leitura e gravação.
Serviços do Azure relevantes:
Armazenamentos de dados de índice externo
Os armazenamentos de dados de índice externos fornecem a capacidade de pesquisar informações mantidas em outros armazenamentos de dados e serviços. Um índice externo atua como um índice secundário para qualquer armazenamento de dados e pode ser usado para indexar grandes volumes de dados e fornecer acesso quase em tempo real a esses índices.
Por exemplo, você pode ter arquivos de texto armazenados em um sistema de arquivos. Encontrar um arquivo pelo caminho do arquivo é rápido, mas a pesquisa com base no conteúdo do arquivo exigiria uma verificação de todos os arquivos, o que é lento. Um índice externo permite criar índices de pesquisa secundários e, em seguida, encontrar rapidamente o caminho para os arquivos que correspondem aos seus critérios. Outro exemplo de aplicação de um índice externo é com armazenamentos de chave/valor que indexam apenas pela chave. Você pode criar um índice secundário com base nos valores nos dados e procurar rapidamente a chave que identifica exclusivamente cada item correspondente.
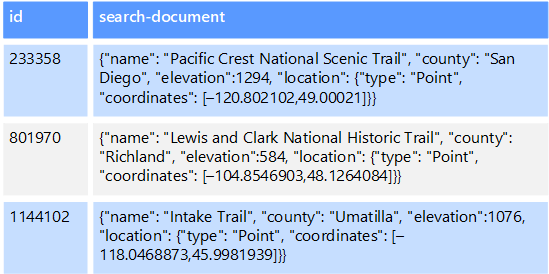
Os índices são criados executando um processo de indexação. Isso pode ser realizado usando um modelo pull, acionado pelo armazenamento de dados, ou usando um modelo push, iniciado pelo código do aplicativo. Os índices podem ser multidimensionais e podem suportar pesquisas de texto livre em grandes volumes de dados de texto.
Os armazenamentos de dados de índice externos são frequentemente usados para oferecer suporte a texto completo e pesquisa baseada na Web. Nestes casos, a pesquisa pode ser exata ou confusa. As pesquisas difusas localizam documentos que correspondem a um conjunto de termos e calculam o nível de correspondência entre os mesmos. Alguns índices externos também suportam análise linguística que pode retornar correspondências com base em sinônimos, expansões de gênero (por exemplo, combinando "cães" com "animais de estimação") e derivação (por exemplo, a busca por "correr" também corresponde a "correu" e "correu").
Serviço do Azure relevante:
Requisitos típicos
Os armazenamentos de dados não relacionais geralmente usam uma arquitetura de armazenamento diferente daquela usada pelos bancos de dados relacionais. Especificamente, eles tendem a não ter um esquema fixo. Além disso, eles tendem a não suportar transações, ou então restringir o escopo das transações, e geralmente não incluem índices secundários por motivos de escalabilidade.
Em comparação com muitos bancos de dados relacionais tradicionais, os bancos de dados NoSQL geralmente oferecem um nível desejável de flexibilidade de esquema e escalabilidade de plataforma, mas às vezes esses benefícios vêm ao custo de uma consistência mais fraca. Mesmo que você possa armazenar seus dados de forma flexível, você ainda precisa identificar e analisar seus padrões de acesso a dados e, em seguida, projetar um esquema de dados apropriado, caso contrário, seu banco de dados NoSQL pode sofrer sob carga de trabalho pesada ou padrões de uso inesperados.
O seguinte compara os requisitos para cada um dos armazenamentos de dados não relacionais:
| Necessidade | Dados do documento | Dados da família de colunas | Dados de chave/valor | Dados de gráficos |
|---|---|---|---|---|
| Normalização | Desnormalizado | Desnormalizado | Desnormalizado | Normalizado |
| Esquema | Esquema em leitura | Famílias de colunas definidas na escrita, esquema de coluna na leitura | Esquema em leitura | Esquema em leitura |
| Consistência (entre transações simultâneas) | Consistência ajustável, garantias ao nível do documento | Garantias ao nível da família de colunas | Garantias de nível chave | Garantias ao nível do gráfico |
| Atomicidade (escopo da transação) | Coleção | Tabela | Tabela | Gráfico |
| Estratégia de bloqueio | Otimista (sem bloqueio) | Pessimista (bloqueios de linha) | Otimista (tag de entidade (ETag)) | |
| Padrão de acesso | Acesso aleatório | Agrega dados altos/largos | Acesso aleatório | Acesso aleatório |
| Indexação | Índices primários e secundários | Índices primários e secundários | Apenas índice primário | Índices primários e secundários |
| Forma de dados | Documento | Tabela com famílias de colunas contendo colunas | Chave e valor | Gráfico contendo arestas e vértices |
| Dispersos | Sim | Sim | Sim | Não |
| Largo (muitas colunas/atributos) | Sim | Sim | Não | Não |
| Tamanho do datum | Pequeno (KBs) a médio (MBs baixos) | Médio (MBs) a Grande (GBs baixos) | Pequeno (KBs) | Pequeno (KBs) |
| Escala máxima global | Muito grande (PBs) | Muito grande (PBs) | Muito grande (PBs) | Grande (TBs) |
| Necessidade | Dados de série temporal | Dados do objeto | Dados do índice externo |
|---|---|---|---|
| Normalização | Normalizado | Desnormalizado | Desnormalizado |
| Esquema | Esquema em leitura | Esquema em leitura | Esquema na gravação |
| Consistência (entre transações simultâneas) | N/A | N/A | N/A |
| Atomicidade (escopo da transação) | N/A | Objeto | N/A |
| Estratégia de bloqueio | N/A | Pessimista (bolha de madeixas) | N/A |
| Padrão de acesso | Acesso aleatório e agregação | Acesso sequencial | Acesso aleatório |
| Indexação | Índices primários e secundários | Apenas índice primário | N/A |
| Forma de dados | Tabela | Blob e metadados | Documento |
| Dispersos | Não | N/A | Não |
| Largo (muitas colunas/atributos) | Não | Sim | Sim |
| Tamanho do datum | Pequeno (KBs) | Grande (GBs) a Muito Grande (TBs) | Pequeno (KBs) |
| Escala máxima global | Grande (TBs baixos) | Muito grande (PBs) | Grande (TBs baixos) |
Contribuidores
Este artigo é mantido pela Microsoft. Foi originalmente escrito pelos seguintes contribuidores.
Autor principal:
- Zoiner Tejada - Brasil | CEO e Arquiteto
Próximos passos
- Dados relacionais vs. dados NoSQL
- Compreender bancos de dados NoSQL distribuídos
- Fundamentos de dados do Microsoft Azure: explorar dados não relacionais no Azure
- Implementar um modelo de dados não relacional