Redundância de roteamento global para aplicativos Web de missão crítica
Importante
Projetar implementações de redundância que lidam com interrupções globais da plataforma para uma arquitetura de missão crítica pode ser complexo e caro. Devido aos potenciais problemas que podem surgir com este design, considere cuidadosamente as compensações.
Na maioria das situações, você não precisará da arquitetura descrita neste artigo.
Os sistemas de missão crítica se esforçam para minimizar pontos únicos de falha, criando recursos de redundância e autorrecuperação na solução, tanto quanto possível. Qualquer ponto de entrada unificado do sistema pode ser considerado um ponto de falha. Se esse componente sofrer uma interrupção, todo o sistema ficará offline para o usuário. Ao escolher um serviço de roteamento, é importante considerar a confiabilidade do próprio serviço.
Na arquitetura de linha de base para um aplicativo de missão crítica, o Azure Front Door foi escolhido por causa de seus contratos de nível de serviço (SLA) de alto tempo de atividade e um rico conjunto de recursos:
- Encaminhar o tráfego para várias regiões em um modelo ativo-ativo
- Failover transparente usando TCP anycast
- Veicule conteúdo estático de nós de borda usando redes integradas de distribuição de conteúdo (CDNs)
- Bloqueie o acesso não autorizado com o firewall integrado de aplicativos da Web
O Front Door foi projetado para fornecer a máxima resiliência e disponibilidade não apenas para nossos clientes externos, mas também para várias propriedades em toda a Microsoft. Para obter mais informações sobre os recursos do Front Door, consulte Acelerar e proteger seu aplicativo Web com o Azure Front Door.
Os recursos do Front Door são mais do que suficientes para atender à maioria dos requisitos de negócios, no entanto, com qualquer sistema distribuído, espere falhas. Se os requisitos de negócios exigirem um SLO composto mais alto ou tempo de inatividade zero em caso de interrupção, você precisará confiar em um caminho alternativo de entrada de tráfego. No entanto, a busca por um SLO mais alto vem com custos significativos, despesas gerais operacionais e pode reduzir sua confiabilidade geral. Considere cuidadosamente as compensações e possíveis problemas que o caminho alternativo pode introduzir em outros componentes que estão no caminho crítico. Mesmo quando o impacto da indisponibilidade é significativo, a complexidade pode superar o benefício.
Uma abordagem é definir um caminho secundário, com serviço(s) alternativo(s), que se torna ativo somente quando o Azure Front Door não está disponível. A paridade de recursos com a porta da frente não deve ser tratada como um requisito difícil. Priorize os recursos de que você absolutamente precisa para fins de continuidade de negócios, mesmo potencialmente executados em uma capacidade limitada.
Outra abordagem é o uso de tecnologia de terceiros para roteamento global. Essa abordagem exigirá uma implantação ativa-ativa multinuvem com selos hospedados em dois ou mais provedores de nuvem. Embora o Azure possa ser efetivamente integrado com outras plataformas de nuvem, essa abordagem não é recomendada devido à complexidade operacional entre as diferentes plataformas de nuvem.
Este artigo descreve algumas estratégias para roteamento global usando o Gerenciador de Tráfego do Azure como roteador alternativo em situações em que o Azure Front Door não está disponível.
Abordagem
Este diagrama de arquitetura mostra uma abordagem geral com vários caminhos de tráfego redundantes.
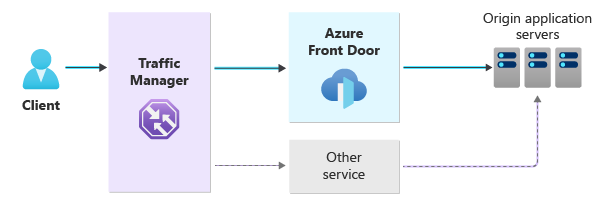
Com essa abordagem, introduziremos vários componentes e forneceremos orientações que farão alterações significativas associadas à entrega de sua(s) aplicação(ões) web:
O Azure Traffic Manager direciona o tráfego para o Azure Front Door ou para o serviço alternativo selecionado.
O Azure Traffic Manager é um balanceador de carga global baseado em DNS. O registro CNAME do seu domínio aponta para o Gerenciador de Tráfego, que determina o destino com base em como você configura seu método de roteamento. O uso do roteamento prioritário fará com que o tráfego flua pela Porta da Frente do Azure por padrão. O Gestor de Tráfego pode mudar automaticamente o tráfego para o seu caminho alternativo se o Azure Front Door não estiver disponível.
Importante
Essa solução reduz os riscos associados às interrupções da Porta da Frente do Azure, mas é suscetível a interrupções do Gerenciador de Tráfego do Azure como um ponto global de falha.
Você também pode considerar o uso de um sistema de roteamento de tráfego global diferente, como um balanceador de carga global. No entanto, o Traffic Manager funciona bem para muitas situações.
Você tem dois caminhos de entrada:
O Azure Front Door fornece o caminho principal e processa e roteia todo o tráfego do seu aplicativo.
Outro roteador é usado como backup para o Azure Front Door. O tráfego só flui através deste caminho secundário se a porta da frente não estiver disponível.
O serviço específico que você seleciona para o roteador secundário depende de muitos fatores. Você pode optar por usar serviços nativos do Azure ou serviços de terceiros. Nestes artigos, fornecemos opções nativas do Azure para evitar adicionar complexidade operacional adicional à solução. Se você usa serviços de terceiros, precisa usar vários planos de controle para gerenciar sua solução.
Seus servidores de aplicativos de origem precisam estar prontos para aceitar tráfego de qualquer serviço. Considere como você protege o tráfego para sua origem e quais responsabilidades a Front Door e outros serviços upstream oferecem. Certifique-se de que seu aplicativo possa lidar com o tráfego de qualquer caminho pelo qual o tráfego flua.
Vantagens e desvantagens
Embora essa estratégia de mitigação possa tornar o aplicativo disponível durante interrupções da plataforma, há algumas compensações significativas. Deve ponderar os benefícios potenciais em relação aos custos conhecidos e tomar uma decisão informada sobre se os benefícios valem a pena.
Custo financeiro: ao implantar vários caminhos redundantes em seu aplicativo, você precisa considerar o custo de implantação e execução dos recursos. Fornecemos dois cenários de exemplo para diferentes casos de uso, cada um com um perfil de custo diferente.
Complexidade operacional: Toda vez que você adiciona componentes adicionais à sua solução, aumenta a sobrecarga de gerenciamento. Qualquer alteração em um componente pode afetar outros componentes.
Suponha que você decida usar os novos recursos do Azure Front Door. Você precisa verificar se seu caminho de tráfego alternativo também fornece um recurso equivalente e, se não, você precisa decidir como lidar com a diferença de comportamento entre os dois caminhos de tráfego. Em aplicações do mundo real, essas complexidades podem ter um alto custo e representar um grande risco para a estabilidade do seu sistema.
Desempenho: Este design requer pesquisas CNAME adicionais durante a resolução de nomes. Na maioria dos aplicativos, essa não é uma preocupação significativa, mas você deve avaliar se o desempenho do aplicativo é afetado pela introdução de camadas adicionais no caminho de entrada.
Custo de oportunidade: projetar e implementar caminhos de entrada redundantes requer um investimento significativo em engenharia, o que, em última análise, tem um custo de oportunidade para o desenvolvimento de recursos e outras melhorias da plataforma.
Aviso
Se você não for cuidadoso na forma como projeta e implementa uma solução complexa de alta disponibilidade, pode realmente piorar sua disponibilidade. Aumentar o número de componentes em sua arquitetura aumenta o número de pontos de falha. Isso também significa que você tem um nível mais alto de complexidade operacional. Quando você adiciona componentes extras, cada alteração feita precisa ser cuidadosamente revisada para entender como isso afeta sua solução geral.
Disponibilidade do Azure Traffic Manager
O Azure Traffic Manager é um serviço confiável, mas o contrato de nível de serviço não garante 100% de disponibilidade. Se o Gerenciador de Tráfego não estiver disponível, seus usuários talvez não consigam acessar seu aplicativo, mesmo que o Azure Front Door e seu serviço alternativo estejam disponíveis. É importante planejar como sua solução continuará a operar nessas circunstâncias.
O Gerenciador de Tráfego retorna respostas DNS armazenáveis em cache. Se o tempo de vida (TTL) em seus registros DNS permitir o armazenamento em cache, interrupções curtas do Gerenciador de Tráfego podem não ser uma preocupação. Isso ocorre porque os resolvedores de DNS downstream podem ter armazenado em cache uma resposta anterior. Você deve planejar interrupções prolongadas. Você pode optar por reconfigurar manualmente seus servidores DNS para direcionar os usuários para o Azure Front Door se o Gerenciador de Tráfego não estiver disponível.
Consistência de roteamento de tráfego
É importante entender os recursos e os recursos do Azure Front Door que você usa e nos quais confia. Ao escolher o serviço alternativo, decida os recursos mínimos necessários e omita outros recursos quando sua solução estiver em um modo degradado.
Ao planejar um caminho de tráfego alternativo, aqui estão algumas perguntas-chave que você deve considerar:
- Você usa os recursos de cache do Azure Front Door? Se o cache não estiver disponível, seus servidores de origem podem acompanhar seu tráfego?
- Você usa o mecanismo de regras do Azure Front Door para executar lógica de roteamento personalizada ou para reescrever solicitações?
- Você usa o firewall de aplicativo Web (WAF) do Azure Front Door para proteger seus aplicativos?
- Você restringe o tráfego com base no endereço IP ou na geografia?
- Quem emite e gerencia seus certificados TLS?
- Como você restringe o acesso aos seus servidores de aplicativos de origem para garantir que ele chegue através da Porta da Frente do Azure? Você usa o Private Link ou confia em endereços IP públicos com tags de serviço e cabeçalhos de identificador?
- Seus servidores de aplicativos aceitam tráfego de qualquer lugar que não seja o Azure Front Door? Em caso afirmativo, que protocolos aceitam?
- Os seus clientes utilizam o suporte HTTP/2 do Azure Front Door?
Firewall de aplicações Web (WAF)
Se você usar o WAF do Azure Front Door para proteger seu aplicativo, considere o que acontece se o tráfego não passar pelo Azure Front Door.
Se o seu caminho alternativo também fornece um WAF, considere as seguintes perguntas:
- Ele pode ser configurado da mesma maneira que seu WAF de porta frontal do Azure?
- Precisa de ser ajustado e testado de forma independente, para reduzir a probabilidade de deteções de falsos positivos?
Aviso
Você pode optar por não usar o WAF para seu caminho de entrada alternativo. Esta abordagem pode ser considerada para apoiar o objetivo de fiabilidade da aplicação. No entanto, esta não é uma boa prática e não a recomendamos.
Considere a contrapartida em aceitar tráfego da internet sem qualquer verificação. Se um invasor descobrir um caminho de tráfego secundário desprotegido para seu aplicativo, ele poderá enviar tráfego mal-intencionado pelo caminho secundário, mesmo quando o caminho primário incluir um WAF.
É melhor proteger todos os caminhos para seus servidores de aplicativos.
Nomes de domínio e DNS
Seu aplicativo de missão crítica deve usar um nome de domínio personalizado. Você controlará como o tráfego flui para seu aplicativo e reduzirá as dependências de um único provedor.
Também é uma boa prática usar um serviço DNS resiliente e de alta qualidade para seu nome de domínio, como o DNS do Azure. Se os servidores DNS do seu nome de domínio não estiverem disponíveis, os utilizadores não poderão aceder ao seu serviço.
É recomendável usar vários resolvedores de DNS para aumentar ainda mais a resiliência geral.
Encadeamento CNAME
As soluções que combinam o Traffic Manager, o Azure Front Door e outros serviços usam um processo de resolução CNAME DNS multicamada, também chamado de encadeamento CNAME. Por exemplo, quando você resolve seu próprio domínio personalizado, pode ver cinco ou mais registros CNAME antes que um endereço IP seja retornado.
Adicionar links adicionais a uma cadeia CNAME pode afetar o desempenho da resolução de nomes DNS. No entanto, as respostas DNS geralmente são armazenadas em cache, o que reduz o impacto no desempenho.
Certificados TLS
Para um aplicativo de missão crítica, é recomendável provisionar e usar seus próprios certificados TLS em vez dos certificados gerenciados fornecidos pelo Azure Front Door. Você reduzirá o número de problemas potenciais com essa arquitetura complexa.
Aqui estão alguns benefícios:
Para emitir e renovar certificados TLS gerenciados, o Azure Front Door verifica sua propriedade do domínio. O processo de verificação de domínio pressupõe que os registos CNAME do seu domínio apontam diretamente para a Porta da Frente do Azure. Mas, essa suposição muitas vezes não está correta. Emitir e renovar certificados TLS gerenciados no Azure Front Door pode não funcionar sem problemas e você aumenta o risco de interrupções devido a problemas de certificado TLS.
Mesmo que seus outros serviços forneçam certificados TLS gerenciados, talvez não consigam verificar a propriedade do domínio.
Se cada serviço obtiver seus próprios certificados TLS gerenciados de forma independente, pode haver problemas. Por exemplo, os usuários podem não esperar ver diferentes certificados TLS emitidos por autoridades diferentes ou com datas de validade ou impressões digitais diferentes.
No entanto, haverá operações adicionais relacionadas à renovação e atualização de seus certificados antes que eles expirem.
Segurança de origem
Ao configurar sua origem para aceitar apenas tráfego por meio da Porta da Frente do Azure, você ganha proteção contra ataques DDoS de camada 3 e camada 4. Como o Azure Front Door só responde ao tráfego HTTP válido, ele também ajuda a reduzir sua exposição a muitas ameaças baseadas em protocolo. Se você alterar sua arquitetura para permitir caminhos de entrada alternativos, precisará avaliar se aumentou acidentalmente a exposição de sua origem a ameaças.
Se você usar o Private Link para se conectar do Azure Front Door ao seu servidor de origem, como o tráfego flui pelo seu caminho alternativo? Você pode usar endereços IP privados para acessar suas origens ou deve usar endereços IP públicos?
Se sua origem usa a marca de serviço do Azure Front Door e o cabeçalho X-Azure-FDID para validar que o tráfego fluiu pelo Azure Front Door, considere como suas origens podem ser reconfiguradas para validar que o tráfego fluiu por qualquer um dos seus caminhos válidos. Você deve testar se não abriu acidentalmente sua origem para o tráfego por outros caminhos, inclusive dos perfis do Azure Front Door de outros clientes.
Ao planejar sua segurança de origem, verifique se o caminho de tráfego alternativo depende do provisionamento de endereços IP públicos dedicados. Isso pode precisar de um processo acionado manualmente para colocar o caminho de backup online.
Se houver endereços IP públicos dedicados, considere se você deve implementar a Proteção contra DDoS do Azure para reduzir o risco de ataques de negação de serviço contra suas origens. Além disso, considere se você precisa implementar o Firewall do Azure ou outro firewall capaz de protegê-lo contra uma variedade de ameaças de rede. Você também pode precisar de mais estratégias de deteção de intrusão. Esses controles podem ser elementos importantes em uma arquitetura de vários caminhos mais complexa.
Modelação do estado de funcionamento
A metodologia de projeto de missão crítica requer um modelo de integridade do sistema que ofereça observabilidade geral da solução e de seus componentes. Ao usar vários caminhos de entrada de tráfego, você precisa monitorar a integridade de cada caminho. Se o tráfego for redirecionado para o caminho de entrada secundário, o modelo de integridade deverá refletir o fato de que o sistema ainda está operacional, mas está sendo executado em um estado degradado.
Inclua estas perguntas no design do seu modelo de saúde:
- Como é que os diferentes componentes da sua solução monitorizam o estado dos componentes a jusante?
- Quando os monitores de saúde devem considerar que os componentes a jusante não estão íntegros?
- Quanto tempo demora para uma interrupção ser detetada?
- Depois que uma interrupção é detetada, quanto tempo leva para o tráfego ser roteado por um caminho alternativo?
Há várias soluções de balanceamento de carga global que permitem monitorar a integridade do Azure Front Door e disparar um failover automático para uma plataforma de backup se ocorrer uma interrupção. O Azure Traffic Manager é adequado na maioria dos casos. Com o Gerenciador de Tráfego, você configura o monitoramento de ponto de extremidade para monitorar serviços downstream especificando qual URL verificar, com que frequência verificar essa URL e quando considerar que o serviço downstream não está íntegro com base nas respostas da sonda. Em geral, quanto menor o intervalo entre as verificações, menos tempo leva para o Gerenciador de Tráfego direcionar o tráfego através de um caminho alternativo para chegar ao seu servidor de origem.
Se o Front Door não estiver disponível, vários fatores influenciam a quantidade de tempo que a interrupção afeta seu tráfego, incluindo:
- O tempo de vida (TTL) em seus registros DNS.
- Com que frequência o Gestor de Tráfego executa as suas verificações de integridade.
- Quantas sondas com falha o Gerenciador de Tráfego está configurado para ver antes de redirecionar o tráfego.
- Por quanto tempo os clientes e servidores DNS upstream armazenam em cache as respostas DNS do Gerenciador de Tráfego.
Você também precisa determinar quais desses fatores estão sob seu controle e se os serviços upstream além do seu controle podem afetar a experiência do usuário. Por exemplo, mesmo que você use TTL baixo em seus registros DNS, os caches DNS upstream ainda podem fornecer respostas obsoletas por mais tempo do que deveriam. Esse comportamento pode exacerbar os efeitos de uma interrupção ou fazer parecer que seu aplicativo está indisponível, mesmo quando o Gerenciador de Tráfego já mudou para enviar solicitações para o caminho de tráfego alternativo.
Gorjeta
As soluções de missão crítica exigem abordagens automatizadas de failover sempre que possível. Os processos manuais de failover são considerados lentos para que o aplicativo permaneça responsivo.
Consulte a: Área de design de missão crítica: Modelagem de saúde
Implantação sem tempo de inatividade
Ao planejar como operar uma solução com caminho de entrada redundante, você também deve planejar como implantar ou configurar seus serviços quando eles estiverem degradados. Para a maioria dos serviços do Azure, os SLAs se aplicam ao tempo de atividade do próprio serviço e não a operações ou implantações de gerenciamento. Considere se seus processos de implantação e configuração precisam ser resilientes a interrupções de serviço.
Você também deve considerar o número de planos de controle independentes com os quais você precisa interagir para gerenciar sua solução. Quando você usa os serviços do Azure, o Azure Resource Manager fornece um plano de controle unificado e consistente. No entanto, se você usar um serviço de terceiros para rotear o tráfego, talvez seja necessário usar um plano de controle separado para configurar o serviço, o que introduz maior complexidade operacional.
Aviso
O uso de vários planos de controle introduz complexidade e risco à sua solução. Cada ponto de diferença aumenta a probabilidade de alguém acidentalmente perder uma definição de configuração ou aplicar configurações diferentes a componentes redundantes. Certifique-se de que seus procedimentos operacionais reduzam esse risco.
Consulte a: Área de projeto de missão crítica: implantação sem tempo de inatividade
Validação contínua
Para uma solução de missão crítica, suas práticas de teste precisam verificar se a solução atende aos seus requisitos, independentemente do caminho pelo qual o tráfego do aplicativo flui. Considere cada parte da solução e como testá-la para cada tipo de interrupção.
Certifique-se de que seus processos de teste incluam estes elementos:
- Você pode verificar se o tráfego é redirecionado corretamente pelo caminho alternativo quando o caminho principal não está disponível?
- Ambos os caminhos podem suportar o nível de tráfego de produção que você espera receber?
- Ambos os caminhos estão adequadamente protegidos, para evitar abrir ou expor vulnerabilidades quando você está em um estado degradado?
Consulte: Área de projeto de missão crítica: Validação contínua
Cenários comuns
Aqui estão os cenários comuns em que esse design pode ser usado:
A entrega de conteúdo global geralmente se aplica à entrega de conteúdo estático, mídia e aplicativos de comércio eletrônico de alta escala. Nesse cenário, o cache é uma parte crítica da arquitetura da solução, e falhas no cache podem resultar em desempenho ou confiabilidade significativamente degradados.
A entrada HTTP global geralmente se aplica a APIs e aplicativos dinâmicos de missão crítica. Nesse cenário, o requisito principal é rotear o tráfego para o servidor de origem de forma confiável e eficiente. Frequentemente, um WAF é um importante controle de segurança usado nessas soluções.
Aviso
Se você não for cuidadoso na forma como projeta e implementa uma solução complexa de multiingresso, pode realmente piorar sua disponibilidade. Aumentar o número de componentes em sua arquitetura aumenta o número de pontos de falha. Isso também significa que você tem um nível mais alto de complexidade operacional. Quando você adiciona componentes extras, cada alteração feita precisa ser cuidadosamente revisada para entender como isso afeta sua solução geral.
Próximos passos
Analise os cenários globais de entrada HTTP e entrega de conteúdo global para entender se eles se aplicam à sua solução.