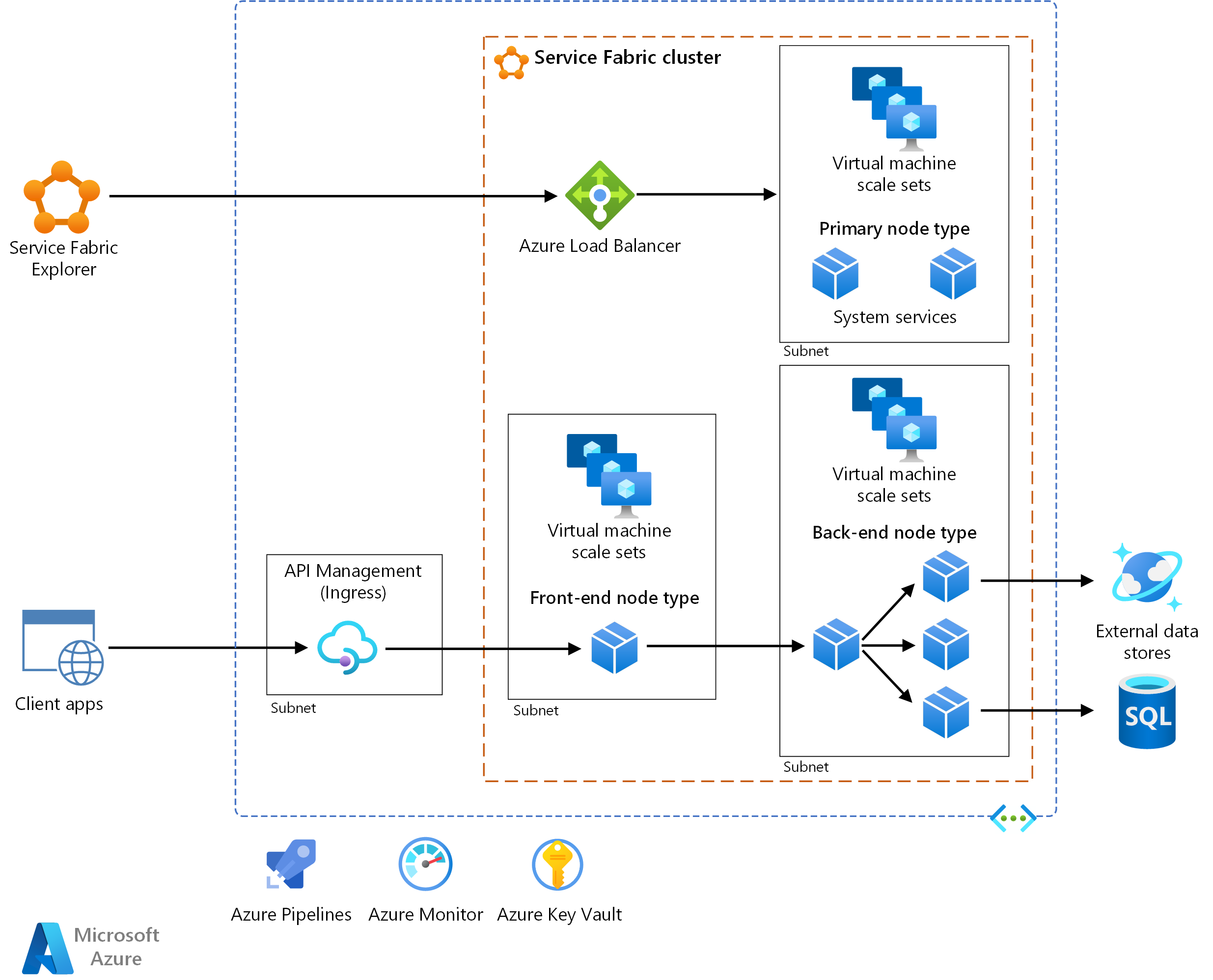
Esta arquitetura de referência mostra uma arquitetura de microsserviços implantada no Azure Service Fabric. Ele mostra uma configuração básica de cluster que pode ser o ponto de partida para a maioria das implantações.
 Uma implementação de referência dessa arquitetura está disponível no GitHub.
Uma implementação de referência dessa arquitetura está disponível no GitHub.
Arquitetura
Transfira um ficheiro do Visio desta arquitetura.
Nota
Este artigo se concentra no modelo de programação de Serviços Confiáveis para o Service Fabric. Usar o Service Fabric para implantar e gerenciar contêineres está além do escopo deste artigo.
Fluxo de Trabalho
A arquitetura é composta pelos seguintes componentes. Para outros termos, consulte Visão geral da terminologia do Service Fabric.
Cluster do Service Fabric. Um cluster é um conjunto de máquinas virtuais (VMs) conectado à rede no qual você implanta e gerencia seus microsserviços.
Conjuntos de dimensionamento de máquinas virtuais. Os conjuntos de dimensionamento de máquinas virtuais permitem criar e gerenciar um grupo de VMs idênticas, com balanceamento de carga e dimensionamento automático. Esses recursos de computação também fornecem os domínios de falha e atualização.
Nós. Os nós são as VMs que pertencem ao cluster do Service Fabric.
Tipos de nós. Um tipo de nó representa um conjunto de escala de máquina virtual que implanta uma coleção de nós. Um cluster do Service Fabric tem pelo menos um tipo de nó.
Em um cluster que tem vários tipos de nó, um deve ser declarado o tipo de nó primário. O tipo de nó primário no cluster executa os serviços do sistema Service Fabric. Esses serviços fornecem os recursos de plataforma do Service Fabric. O tipo de nó primário também atua como os nós semente, que são os nós que mantêm a disponibilidade do cluster subjacente.
Configure tipos de nó adicionais para executar seus serviços.
Serviços. Um serviço executa uma função autônoma que pode ser iniciada e executada independentemente de outros serviços. As instâncias de serviços são implantadas em nós no cluster. Existem duas variedades de serviços no Service Fabric:
- Serviço apátrida. Um serviço sem estado não mantém o estado dentro do serviço. Se a persistência de estado for necessária, o estado será gravado e recuperado de um repositório externo, como o Azure Cosmos DB.
- Serviço com estado. O estado do serviço é mantido dentro do próprio serviço. A maioria dos serviços com monitoração de estado implementa isso por meio de coleções confiáveis no Service Fabric.
Explorador do Service Fabric. O Service Fabric Explorer é uma ferramenta de código aberto para inspecionar e gerenciar clusters do Service Fabric.
Azure Pipelines. O Azure Pipelines faz parte dos Serviços de DevOps do Azure e executa compilações, testes e implantações automatizados. Você também pode usar soluções de integração contínua e entrega contínua (CI/CD) de terceiros, como o Jenkins.
Azure Monitor. O Azure Monitor coleta e armazena métricas e logs, incluindo métricas de plataforma para os serviços do Azure na solução e telemetria de aplicativos. Use esses dados para monitorar o aplicativo, configurar alertas e painéis e executar a análise de causa raiz de falhas. O Azure Monitor integra-se ao Service Fabric para coletar métricas de controladores, nós e contêineres, juntamente com logs de contêineres e nós.
Azure Key Vault. Use o Cofre da Chave para armazenar quaisquer segredos de aplicativos usados pelos microsserviços, como cadeias de conexão.
Gerenciamento de API do Azure. Nessa arquitetura, o Gerenciamento de API atua como um gateway de API que aceita solicitações de clientes e as encaminha para seus serviços.
Considerações
Essas considerações implementam os pilares do Azure Well-Architected Framework, que é um conjunto de princípios orientadores para melhorar a qualidade de uma carga de trabalho.
Considerações de design
Esta arquitetura de referência é focada em arquiteturas de microsserviços. Um microsserviço é uma pequena unidade de código com versão independente. Ele pode ser descoberto por meio de mecanismos de descoberta de serviços e pode se comunicar com outros serviços por meio de APIs. Cada serviço é autónomo e deve implementar uma única capacidade empresarial. Para obter mais informações sobre como decompor o domínio do aplicativo em microsserviços, consulte Usando a análise de domínio para modelar microsserviços.
O Service Fabric fornece uma infraestrutura para criar, implantar e atualizar microsserviços de forma eficiente. Ele também fornece opções para dimensionamento automático, gerenciamento de estado, monitoramento da integridade e reinicialização de serviços em caso de falha.
O Service Fabric segue um modelo de aplicativo em que um aplicativo é uma coleção de microsserviços. O aplicativo é descrito em um arquivo de manifesto do aplicativo. Esse arquivo define os tipos de serviços que o aplicativo contém, juntamente com ponteiros para os pacotes de serviços independentes.
O pacote do aplicativo também geralmente contém parâmetros que servem como substituições para determinadas configurações que os serviços usam. Cada pacote de serviço tem um arquivo de manifesto que descreve os arquivos físicos e pastas necessários para executar esse serviço, incluindo binários, arquivos de configuração e dados somente leitura. Os serviços e aplicativos são versionados e atualizáveis de forma independente.
Opcionalmente, o manifesto do aplicativo pode descrever serviços que são provisionados automaticamente quando uma instância do aplicativo é criada. Estes são chamados serviços padrão. Nesse caso, o manifesto do aplicativo também descreve como esses serviços devem ser criados. Essas informações incluem o nome do serviço, a contagem de instâncias, a política de segurança ou isolamento e as restrições de posicionamento.
Nota
Evite usar serviços padrão se quiser controlar o tempo de vida dos seus serviços. Os serviços padrão são criados quando o aplicativo é criado e são executados enquanto o aplicativo estiver em execução.
Para obter mais informações, consulte Para saber mais sobre o Service Fabric?.
Modelo de empacotamento de aplicativo para serviço
Um princípio dos microsserviços é que cada serviço pode ser implantado de forma independente. No Service Fabric, se você agrupar todos os seus serviços em um único pacote de aplicativo e um serviço não for atualizado, toda a atualização do aplicativo será revertida. Essa reversão impede que outros serviços sejam atualizados.
Por esse motivo, em uma arquitetura de microsserviços, recomendamos o uso de vários pacotes de aplicativos. Coloque um ou mais tipos de serviço intimamente relacionados em um único tipo de aplicativo. Por exemplo, coloque tipos de serviço no mesmo tipo de aplicativo se sua equipe for responsável por um conjunto de serviços que tenham um destes atributos:
- Eles funcionam pela mesma duração e precisam ser atualizados ao mesmo tempo.
- Têm o mesmo ciclo de vida.
- Eles compartilham recursos como dependências ou configuração.
Modelos de programação do Service Fabric
Ao adicionar um microsserviço a um aplicativo do Service Fabric, decida se ele tem estado ou dados que precisam ser altamente disponíveis e confiáveis. Em caso afirmativo, pode armazenar dados externamente ou os dados estão contidos como parte do serviço? Escolha um serviço sem estado se não precisar armazenar dados ou se quiser armazenar dados em armazenamento externo. Considere escolher um serviço com monitoração de estado se uma destas instruções se aplicar:
- Você deseja manter o estado ou os dados como parte do serviço. Por exemplo, você precisa que os dados residam na memória perto do código.
- Você não pode tolerar uma dependência de uma loja externa.
Se você tiver um código existente que deseja executar no Service Fabric, poderá executá-lo como um executável convidado: um executável arbitrário que é executado como um serviço. Como alternativa, você pode empacotar o executável em um contêiner que tenha todas as dependências necessárias para a implantação.
O Service Fabric modela contêineres e executáveis convidados como serviços sem monitoração de estado. Para obter orientação sobre como escolher um modelo, consulte Visão geral do modelo de programação do Service Fabric.
Você é responsável por manter o ambiente no qual um executável convidado é executado. Por exemplo, suponha que um executável convidado requer Python. Se o executável não for independente, você precisará certificar-se de que a versão necessária do Python está pré-instalada no ambiente. O Service Fabric não gerencia o ambiente. O Azure oferece vários mecanismos para configurar o ambiente, incluindo imagens e extensões de máquina virtual personalizadas.
Para acessar um executável convidado por meio de um proxy reverso, verifique se você adicionou o UriScheme atributo ao elemento no manifesto Endpoint de serviço do executável convidado.
<Endpoints>
<Endpoint Name="MyGuestExeTypeEndpoint" Port="8090" Protocol="http" UriScheme="http" PathSuffix="api" Type="Input"/>
</Endpoints>
Se o serviço tiver rotas adicionais, especifique as PathSuffix rotas no valor. O valor não deve ser prefixado ou sufixado com uma barra (/). Outra maneira é adicionar a rota no nome do serviço.
<Endpoints>
<Endpoint Name="MyGuestExeTypeEndpoint" Port="8090" Protocol="http" PathSuffix="api" Type="Input"/>
</Endpoints>
Para obter mais informações, consulte:
Gateway de API
Um gateway de API (entrada) fica entre clientes externos e os microsserviços. Ele atua como um proxy reverso, roteando solicitações de clientes para microsserviços. Ele também pode executar tarefas transversais, como autenticação, terminação SSL e limitação de taxa.
Recomendamos o Gerenciamento de API do Azure para a maioria dos cenários, mas o Traefik é uma alternativa popular de código aberto. Ambas as opções de tecnologia são integradas ao Service Fabric.
Gerenciamento de API. Expõe um endereço IP público e encaminha o tráfego para os seus serviços. Ele é executado em uma sub-rede dedicada na mesma rede virtual que o cluster do Service Fabric.
O Gerenciamento de API pode acessar serviços em um tipo de nó exposto por meio de um balanceador de carga com um endereço IP privado. Essa opção está disponível somente nas camadas Premium e Developer do Gerenciamento de API. Para cargas de trabalho de produção, use a camada Premium. As informações de preços são descritas em Preços do Gerenciamento de API.
Para obter mais informações, consulte Visão geral do Service Fabric com Gerenciamento de API do Azure.
Traefik. Suporta recursos como roteamento, rastreamento, logs e métricas. O Traefik é executado como um serviço sem estado no cluster do Service Fabric. O controle de versão do serviço pode ser suportado por meio do roteamento.
Para obter informações sobre como configurar o Traefik para entrada de serviço e como proxy reverso dentro do cluster, consulte Provedor do Azure Service Fabric no site do Traefik. Para obter mais informações sobre como usar o Traefik com o Service Fabric, consulte a postagem do blog Roteamento inteligente no Service Fabric com o Traefik.
Traefik, ao contrário do Azure API Management, não tem funcionalidade para resolver a partição de um serviço stateful (com mais de uma partição) para o qual uma solicitação é roteada. Para obter mais informações, consulte Adicionar um correspondente para serviços de particionamento.
Outras opções de gerenciamento de API incluem o Azure Application Gateway e o Azure Front Door. Você pode usar esses serviços em conjunto com o Gerenciamento de API para executar tarefas como roteamento, terminação SSL e firewall.
Comunicação entre serviços
Para facilitar a comunicação serviço-a-serviço, considere as seguintes recomendações:
Protocolo de comunicação. Em uma arquitetura de microsserviços, os serviços precisam se comunicar entre si com acoplamento mínimo em tempo de execução. Para permitir a comunicação agnóstica em termos de linguagem, o HTTP é um padrão da indústria com uma ampla gama de ferramentas e servidores HTTP disponíveis em diferentes idiomas. O Service Fabric suporta todas essas ferramentas e servidores.
Para a maioria das cargas de trabalho, recomendamos que você use HTTP em vez da comunicação remota de serviço incorporada ao Service Fabric.
Descoberta de serviços. Para se comunicar com outros serviços dentro de um cluster, um serviço cliente precisa resolver o local atual do serviço de destino. No Service Fabric, os serviços podem se mover entre nós e fazer com que os pontos de extremidade de serviço sejam alterados dinamicamente.
Para evitar conexões com pontos de extremidade obsoletos, você pode usar o serviço de nomenclatura no Service Fabric para recuperar informações atualizadas do ponto de extremidade. No entanto, o Service Fabric também fornece um serviço de proxy reverso interno que abstrai o serviço de nomenclatura. Recomendamos essa opção para descoberta de serviço como linha de base para a maioria dos cenários, pois é mais fácil de usar e resulta em código mais simples.
Outras opções de comunicação interserviços incluem:
- Traefik para roteamento avançado.
- DNS para cenários de compatibilidade em que um serviço espera usar o DNS.
- A classe ServicePartitionClient<TCommunicationClient> , que armazena em cache pontos de extremidade de serviço. Ele pode permitir um melhor desempenho, porque as chamadas vão diretamente entre os serviços, sem intermediários ou protocolos personalizados.
Escalabilidade
O Service Fabric oferece suporte ao dimensionamento dessas entidades de cluster:
- Dimensionamento do número de nós para cada tipo de nó
- Serviços de dimensionamento
Esta seção é focada no dimensionamento automático. Você pode optar por dimensionar manualmente em situações em que for apropriado. Por exemplo, a intervenção manual pode ser necessária para definir o número de instâncias.
Configuração inicial do cluster para escalabilidade
Ao criar um cluster do Service Fabric, provisione os tipos de nó com base em suas necessidades de segurança e escalabilidade. Cada tipo de nó é mapeado para um conjunto de escala de máquina virtual e pode ser dimensionado independentemente.
- Crie um tipo de nó para cada grupo de serviços que tenham diferentes requisitos de escalabilidade ou recursos. Comece provisionando um tipo de nó (que se torna o tipo de nó primário) para os serviços do sistema Service Fabric. Crie tipos de nó separados para executar seus serviços públicos ou front-end. Crie outros tipos de nó conforme necessário para seu back-end e serviços privados ou isolados. Especifique restrições de posicionamento para que os serviços sejam implantados somente nos tipos de nó pretendidos.
- Especifique a camada de durabilidade para cada tipo de nó. A camada de durabilidade representa a capacidade do Service Fabric de influenciar atualizações e operações de manutenção em conjuntos de dimensionamento de máquinas virtuais. Para cargas de trabalho de produção, escolha um nível de durabilidade Silver ou superior. Para obter informações sobre cada camada, consulte Características de durabilidade do cluster.
- Se você estiver usando o nível de durabilidade Bronze, certas operações exigem etapas manuais. Os tipos de nó com o nível de durabilidade Bronze exigem etapas adicionais durante a expansão. Para obter mais informações sobre operações de dimensionamento, consulte este guia.
Dimensionamento de nós
O Service Fabric oferece suporte ao dimensionamento automático para escalabilidade horizontal e horizontal. Você pode configurar cada tipo de nó para dimensionamento automático independentemente.
Cada tipo de nó pode ter um máximo de 100 nós. Comece com um conjunto menor de nós e adicione mais nós dependendo da sua carga. Se você precisar de mais de 100 nós em um tipo de nó, precisará adicionar mais tipos de nós. Para obter detalhes, consulte Considerações sobre planejamento de capacidade de cluster do Service Fabric. Um conjunto de dimensionamento de máquina virtual não é dimensionado instantaneamente, portanto, considere esse fator ao configurar regras de dimensionamento automático.
Para suportar a introdução automática de escala, configure o tipo de nó para ter o nível de durabilidade Silver ou Gold. Essa configuração garante que o dimensionamento seja adiado até que o Service Fabric termine de realocar serviços. Ele também garante que os conjuntos de dimensionamento de máquina virtual informem ao Service Fabric que as VMs foram removidas, não apenas temporariamente inativas.
Para obter mais informações sobre o dimensionamento no nível do nó ou do cluster, consulte Dimensionamento de clusters do Azure Service Fabric.
Serviços de dimensionamento
Os serviços sem estado e com estado aplicam abordagens diferentes ao dimensionamento.
Para um serviço sem estado (dimensionamento automático):
- Use o gatilho de carga de partição média. Esse gatilho determina quando o serviço é dimensionado para dentro ou para fora, com base em um valor de limite de carga especificado na política de dimensionamento. Você também pode definir a frequência com que o gatilho é verificado. Consulte Gatilho médio de carga de partição com dimensionamento baseado em instância. Essa abordagem permite que você aumente a escala para o número de nós disponíveis.
- Defina
InstanceCountcomo -1 no manifesto de serviço, que informa ao Service Fabric para executar uma instância do serviço em cada nó. Essa abordagem permite que o serviço seja dimensionado dinamicamente à medida que o cluster é dimensionado. À medida que o número de nós no cluster muda, o Service Fabric cria e exclui automaticamente instâncias de serviço para corresponder.
Nota
Em alguns casos, talvez você queira dimensionar manualmente o serviço. Por exemplo, se você tiver um serviço que lê de Hubs de Eventos do Azure, convém que uma instância dedicada leia de cada partição de hub de eventos. Dessa forma, você pode evitar o acesso simultâneo à partição.
Para um serviço com monitoração de estado, o dimensionamento é controlado pelo número de partições, o tamanho de cada partição e o número de partições ou réplicas em execução em uma máquina:
Se você estiver criando serviços particionados, certifique-se de que cada nó obtenha réplicas adequadas para distribuição uniforme da carga de trabalho sem causar contenções de recursos. Se você adicionar mais nós, o Service Fabric distribuirá as cargas de trabalho para as novas máquinas por padrão. Por exemplo, se houver 5 nós e 10 partições, o Service Fabric colocará duas réplicas primárias em cada nó por padrão. Se você dimensionar os nós, poderá obter maior desempenho porque o trabalho é distribuído uniformemente por mais recursos.
Para obter informações sobre cenários que aproveitam essa estratégia, consulte Dimensionamento no Service Fabric.
Adicionar ou remover partições não é bem suportado. Outra opção comumente usada para dimensionar é criar ou excluir dinamicamente serviços ou instâncias inteiras de aplicativos. Um exemplo desse padrão é descrito em Dimensionamento criando ou removendo novos serviços nomeados.
Para obter mais informações, consulte:
- Dimensionar um cluster do Service Fabric para dentro ou para fora usando regras de dimensionamento automático ou manualmente
- Dimensionar um cluster do Service Fabric programaticamente
- Dimensionar um cluster do Service Fabric adicionando um conjunto de dimensionamento de máquina virtual
Usando métricas para equilibrar a carga
Dependendo de como você projeta a partição, você pode ter nós com réplicas que recebem mais tráfego do que outros. Para evitar essa situação, particione o estado do serviço para que ele seja distribuído em todas as partições. Utilize o esquema de partição de intervalo com um bom algoritmo hash. Consulte Introdução ao particionamento.
O Service Fabric usa métricas para saber como colocar e equilibrar serviços dentro de um cluster. Você pode especificar uma carga padrão para cada métrica associada a um serviço quando esse serviço é criado. Em seguida, o Service Fabric leva essa carga em consideração ao colocar o serviço ou sempre que o serviço precisar ser movido (por exemplo, durante atualizações), para equilibrar os nós no cluster.
A carga padrão inicialmente especificada para um serviço não será alterada ao longo do tempo de vida do serviço. Para capturar métricas variáveis para um serviço, recomendamos que você monitore seu serviço e, em seguida, relate a carga dinamicamente. Essa abordagem permite que o Service Fabric ajuste a alocação com base na carga relatada em um determinado momento. Use o método IServicePartition.ReportLoad para relatar métricas personalizadas. Para obter mais informações, consulte Carga dinâmica.
Disponibilidade
Coloque seus serviços em um tipo de nó diferente do tipo de nó primário. Os serviços do sistema Service Fabric são sempre implantados no tipo de nó primário. Se seus serviços forem implantados no tipo de nó principal, eles poderão competir com (e interferir com) serviços do sistema por recursos. Se se espera que um tipo de nó hospede serviços com monitoração de estado, verifique se há pelo menos cinco instâncias de nó e se você seleciona a camada de durabilidade Silver ou Gold.
Considere restringir os recursos dos seus serviços. Consulte Mecanismo de governança de recursos.
Aqui estão as considerações comuns:
- Não misture serviços que são controlados por recursos e serviços que não são controlados por recursos no mesmo tipo de nó. Os serviços não governados podem consumir muitos recursos e afetar os serviços controlados. Especifique restrições de posicionamento para garantir que esses tipos de serviços não sejam executados no mesmo conjunto de nós. (Este é um exemplo do Padrão da antepara.)
- Especifique os núcleos de CPU e a memória a serem reservados para uma instância de serviço. Para obter informações sobre o uso e as limitações das políticas de governança de recursos, consulte Governança de recursos.
Para evitar um único ponto de falha (SPOF), verifique se a instância de destino ou a contagem de réplicas de cada serviço é maior que uma. O maior número que você pode usar como instância de serviço ou contagem de réplica é igual ao número de nós que restringem o serviço.
Certifique-se de que cada serviço com monitoração de estado tenha pelo menos duas réplicas secundárias ativas. Recomendamos cinco réplicas para cargas de trabalho de produção.
Para obter mais informações, consulte Disponibilidade dos serviços do Service Fabric.
Segurança
A segurança oferece garantias contra ataques deliberados e o abuso de seus valiosos dados e sistemas. Para obter mais informações, consulte Visão geral do pilar de segurança.
Aqui estão alguns pontos-chave para proteger seu aplicativo no Service Fabric.
Rede virtual
Considere definir limites de sub-rede para cada conjunto de escala de máquina virtual para controlar o fluxo de comunicação. Cada tipo de nó tem sua própria escala de máquina virtual definida em uma sub-rede dentro da rede virtual do cluster do Service Fabric. Você pode adicionar grupos de segurança de rede (NSGs) às sub-redes para permitir ou rejeitar o tráfego de rede. Por exemplo, com os tipos de nó front-end e back-end, você pode adicionar um NSG à sub-rede back-end para aceitar tráfego de entrada somente da sub-rede front-end.
Quando você estiver chamando serviços externos do Azure a partir do cluster, use pontos de extremidade de serviço de rede virtual se o serviço do Azure oferecer suporte a isso. O uso de um ponto de extremidade de serviço protege o serviço apenas para a rede virtual do cluster.
Por exemplo, se você estiver usando o Azure Cosmos DB para armazenar dados, configure a conta do Azure Cosmos DB com um ponto de extremidade de serviço para permitir o acesso somente de uma sub-rede específica. Consulte Acessar recursos do Azure Cosmos DB de redes virtuais.
Pontos finais e comunicação interserviços
Não crie um cluster do Service Fabric não seguro. Se o cluster expõe pontos de extremidade de gerenciamento à Internet pública, os usuários anônimos podem se conectar a ele. Não há suporte para clusters não seguros para cargas de trabalho de produção. Consulte Cenários de segurança de cluster do Service Fabric.
Para ajudar a proteger as suas comunicações interserviços:
- Considere habilitar endpoints HTTPS em seus serviços Web ASP.NET Core ou Java.
- Estabeleça uma conexão segura entre o proxy reverso e os serviços. Para obter detalhes, consulte Conectar-se a um serviço seguro.
Se você estiver usando um gateway de API, poderá descarregar a autenticação para o gateway. Certifique-se de que os serviços individuais não podem ser acessados diretamente (sem o gateway de API), a menos que haja segurança adicional para autenticar mensagens.
Não exponha o proxy reverso do Service Fabric publicamente. Isso faz com que todos os serviços que expõem pontos de extremidade HTTP sejam endereçáveis de fora do cluster. Isso introduzirá vulnerabilidades de segurança e potencialmente exporá informações adicionais fora do cluster desnecessariamente. Se você quiser acessar um serviço publicamente, use um gateway de API. A seção API gateway mais adiante neste artigo menciona algumas opções.
A Área de Trabalho Remota é útil para diagnóstico e solução de problemas, mas certifique-se de fechá-la. Deixá-lo aberto causa uma falha de segurança.
Segredos e certificados
Armazene segredos, como cadeias de conexão para armazenamentos de dados, em um cofre de chaves. O cofre de chaves deve estar na mesma região que o conjunto de escala da máquina virtual. Para usar um cofre de chaves:
Autentique o acesso do serviço ao cofre de chaves.
Habilite a identidade gerenciada no conjunto de escala da máquina virtual que hospeda o serviço.
Guarde os seus segredos no cofre das chaves.
Adicione segredos em um formato que possa ser traduzido para um par chave/valor. Por exemplo, use
CosmosDB--AuthKey. Quando a configuração é construída, o hífen duplo (--) é convertido em dois pontos (:).Aceda a esses segredos ao seu serviço.
Adicione o URI do cofre de chaves no arquivo appSettings.json . Em seu serviço, adicione o provedor de configuração que lê do cofre de chaves, cria a configuração e acessa o segredo da configuração construída.
Aqui está um exemplo em que o serviço de fluxo de trabalho armazena um segredo no cofre de chaves no formato CosmosDB--Database.
namespace Fabrikam.Workflow.Service
{
public class ServiceStartup
{
public static void ConfigureServices(StatelessServiceContext context, IServiceCollection services)
{
var preConfig = new ConfigurationBuilder()
…
.AddJsonFile(context, "appsettings.json");
var config = preConfig.Build();
if (config["AzureKeyVault:KeyVaultUri"] is var keyVaultUri && !string.IsNullOrWhiteSpace(keyVaultUri))
{
preConfig.AddAzureKeyVault(keyVaultUri);
config = preConfig.Build();
}
}
}
Para acessar o segredo, especifique o nome do segredo na configuração compilada.
if(builtConfig["CosmosDB:Database"] is var database && !string.IsNullOrEmpty(database))
{
// Use the secret.
}
Não use certificados de cliente para acessar o Service Fabric Explorer. Em vez disso, use o Microsoft Entra ID. Consulte Serviços do Azure que suportam a autenticação do Microsoft Entra.
Não use certificados autoassinados para produção.
Proteção de dados em repouso
Se você anexou discos de dados aos conjuntos de escala de máquina virtual do cluster do Service Fabric e seus serviços salvam dados nesses discos, você deve criptografar os discos. Para obter mais informações, consulte Criptografar o sistema operacional e discos de dados anexados em um conjunto de dimensionamento de máquina virtual com o Azure PowerShell (visualização).
Para obter mais informações sobre como proteger o Service Fabric, consulte:
- Visão geral da segurança do Azure Service Fabric
- Práticas recomendadas de segurança do Azure Service Fabric
- Lista de verificação de segurança do Azure Service Fabric
Resiliência
Para recuperar de falhas e manter um estado totalmente funcional, o aplicativo deve implementar determinados padrões de resiliência. Aqui estão alguns padrões comuns:
- Repetir: para lidar com erros que você espera que sejam transitórios, como recursos que estão temporariamente indisponíveis.
- Disjuntor: Para resolver falhas que podem levar mais tempo para serem corrigidas.
- Antepara: para isolar recursos para cada serviço.
Esta implementação de referência usa Polly, uma opção de código aberto, para implementar todos esses padrões.
Monitorização
Antes de explorar as opções de monitoramento, recomendamos que você leia este artigo sobre como diagnosticar cenários comuns com o Service Fabric. Você pode pensar em dados de monitoramento nestes conjuntos:
- Métricas e logs de aplicativos
- Dados de eventos e integridade do Service Fabric
- Métricas e logs de infraestrutura
- Métricas e logs para serviços dependentes
Estas são as duas principais opções para analisar esses dados:
- Application Insights
- Log Analytics
Você pode usar o Azure Monitor para configurar painéis para monitoramento e enviar alertas aos operadores. Algumas ferramentas de monitoramento de terceiros também são integradas ao Service Fabric, como o Dynatrace. Para obter detalhes, consulte Parceiros de monitoramento do Azure Service Fabric.
Métricas e logs de aplicativos
A telemetria de aplicativos fornece dados que podem ajudá-lo a monitorar a integridade do serviço e identificar problemas. Para adicionar rastreamentos e eventos ao seu serviço:
- Use Microsoft.Extensions.Logging se estiver desenvolvendo seu serviço com o ASP.NET Core. Para outras estruturas, use uma biblioteca de log de sua escolha, como o Serilog.
- Adicione sua própria instrumentação usando a classe TelemetryClient no SDK e exiba os dados no Application Insights. Consulte Adicionar instrumentação personalizada ao seu aplicativo.
- Registre eventos de rastreamento de eventos para Windows (ETW) usando EventSource. Essa opção está disponível por padrão em uma solução do Visual Studio Service Fabric.
O Application Insights fornece muita telemetria integrada: solicitações, rastreamentos, eventos, exceções, métricas, dependências. Se o seu serviço expõe pontos de extremidade HTTP, habilite o Application Insights chamando o UseApplicationInsights método de extensão para Microsoft.AspNetCore.Hosting.IWebHostBuilder. Para obter informações sobre como instrumentar seu serviço para o Application Insights, consulte estes artigos:
- Tutorial: Monitorar e diagnosticar um aplicativo ASP.NET Core no Service Fabric usando o Application Insights
- Application Insights para ASP.NET Core
- Application Insights .NET SDK
- SDK do Application Insights para Service Fabric
Para exibir os rastreamentos e logs de eventos, use o Application Insights como um dos coletores para registro estruturado. Configure o Application Insights com sua chave de instrumentação chamando o AddApplicationInsights método de extensão. Neste exemplo, a chave de instrumentação é armazenada como um segredo no cofre de chaves.
.ConfigureLogging((hostingContext, logging) =>
{
logging.AddApplicationInsights(hostingContext.Configuration ["ApplicationInsights:InstrumentationKey"]);
})
Se o serviço não expõe pontos de extremidade HTTP, você precisará escrever uma extensão personalizada que envie rastreamentos para o Application Insights. Para obter um exemplo, consulte o serviço de fluxo de trabalho na implementação de referência.
ASP.NET serviços principais usam a interface ILogger para registro em log de aplicativos. Para disponibilizar esses logs de aplicativos no Azure Monitor, envie os eventos para o ILogger Application Insights. O Application Insights pode adicionar propriedades de correlação a eventos, o ILogger que é útil para visualizar o rastreamento distribuído.
Para obter mais informações, consulte:
Dados de eventos e integridade do Service Fabric
A telemetria do Service Fabric inclui métricas de integridade e eventos sobre a operação e o desempenho de um cluster do Service Fabric e suas entidades: seus nós, aplicativos, serviços, partições e réplicas. Os dados de saúde e eventos podem vir de:
EventStore. Esse serviço de sistema com monitoração de estado coleta eventos relacionados ao cluster e suas entidades. O Service Fabric usa o EventStore para escrever eventos do Service Fabric para fornecer informações sobre seu cluster para atualizações de status, solução de problemas e monitoramento. EventStore também pode correlacionar eventos de entidades diferentes em um determinado momento para identificar problemas no cluster. O serviço expõe esses eventos por meio de uma API REST.
Para obter informações sobre como consultar as APIs do EventStore, consulte Consultar APIs do EventStore para eventos de cluster. Você pode exibir os eventos do EventStore no Log Analytics configurando seu cluster com a extensão de Diagnóstico do Azure para Windows (WAD).
HealthStore. Esse serviço com monitoração de estado fornece um instantâneo da integridade atual do cluster. Ele agrega todos os dados de integridade relatados por entidades em uma hierarquia. Os dados são visualizados no Service Fabric Explorer. HealthStore também monitora atualizações de aplicativos. Você pode usar consultas de integridade no PowerShell, em um aplicativo .NET ou em APIs REST. Consulte Introdução ao monitoramento de integridade do Service Fabric.
Relatórios de integridade personalizados. Considere a implementação de serviços de vigilância internos que possam relatar periodicamente dados de integridade personalizados, como estados defeituosos de serviços em execução. Você pode ler os relatórios de integridade no Service Fabric Explorer.
Métricas e logs de infraestrutura
As métricas de infraestrutura ajudam a entender a alocação de recursos no cluster. Aqui estão as principais opções para coletar essas informações:
- WAD. Colete logs e métricas no nível do nó no Windows. Você pode usar o WAD configurando a extensão de VM IaaSDiagnostics em qualquer conjunto de escala de máquina virtual mapeado para um tipo de nó para coletar eventos de diagnóstico. Esses eventos podem incluir logs de eventos do Windows, contadores de desempenho, ETW/manifesto do sistema e eventos operacionais e logs personalizados.
- Agente do Log Analytics. Configure a extensão de VM MicrosoftMonitoringAgent para enviar logs de eventos do Windows, contadores de desempenho e logs personalizados para o Log Analytics.
Há alguma sobreposição nos tipos de métricas coletadas por meio dos mecanismos anteriores, como contadores de desempenho. Quando houver sobreposição, recomendamos o uso do agente do Log Analytics. Como o agente do Log Analytics não usa o armazenamento do Azure, a latência é baixa. Além disso, os contadores de desempenho no IaaSDiagnostics não podem ser alimentados facilmente no Log Analytics.
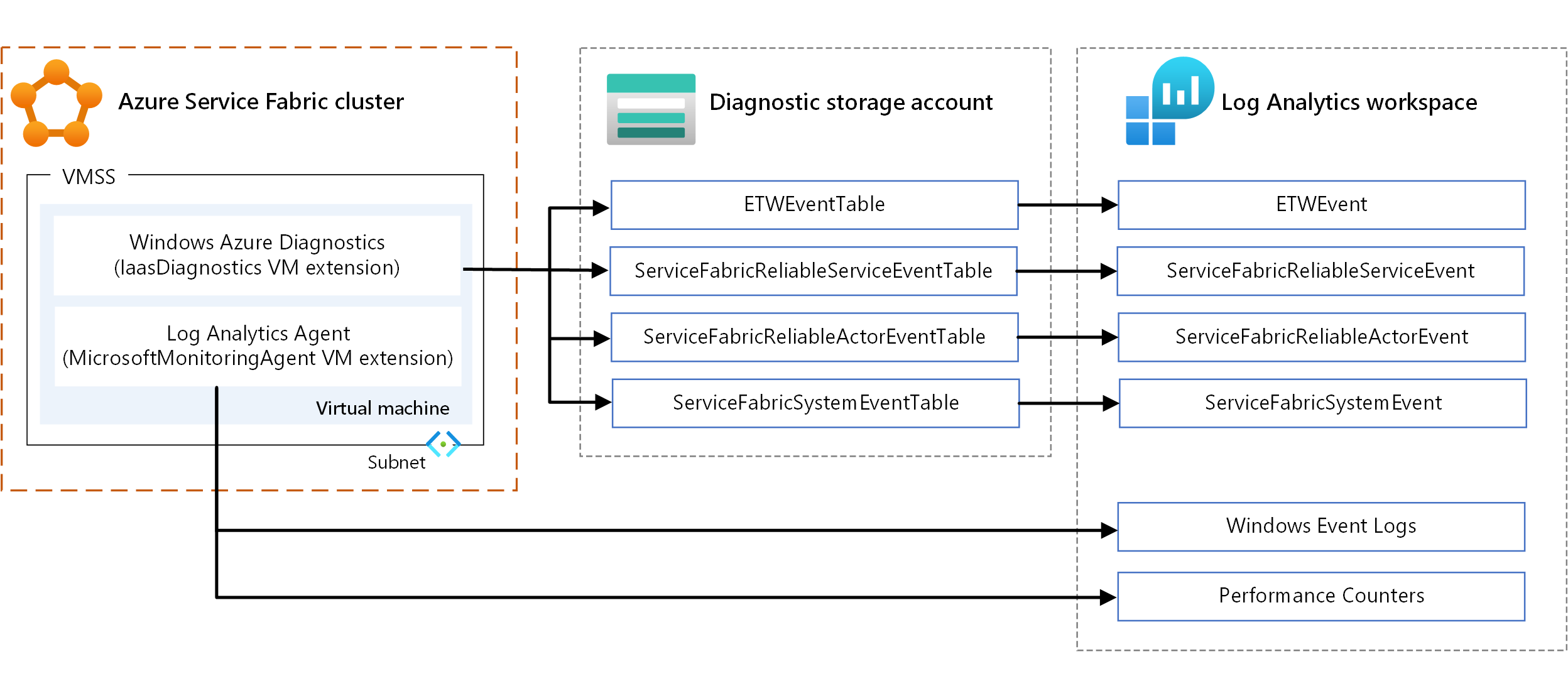
Para obter informações sobre como usar extensões de VM, consulte Extensões e recursos de máquina virtual do Azure.
Para visualizar os dados, configure o Log Analytics para exibir os dados coletados por meio do WAD. Para obter informações sobre como configurar o Log Analytics para ler eventos de uma conta de armazenamento, consulte Configurar o Log Analytics para um cluster.
Você também pode exibir logs de desempenho e dados de telemetria relacionados a um cluster do Service Fabric, cargas de trabalho, tráfego de rede, atualizações pendentes e muito mais. Consulte Monitoramento de desempenho com o Log Analytics.
A solução de Mapa de Serviços no Log Analytics fornece informações sobre a topologia do cluster (ou seja, os processos em execução em cada nó). Envie os dados na conta de armazenamento para o Application Insights. Pode haver algum atraso na obtenção de dados no Application Insights. Se você quiser ver os dados em tempo real, considere configurar Hubs de Eventos usando coletores e canais. Para obter mais informações, consulte Agregação e coleta de eventos usando WAD.
Métricas de serviço dependentes
- O Mapa do Aplicativo no Application Insights fornece a topologia do aplicativo usando chamadas de dependência HTTP feitas entre serviços, com o SDK do Application Insights instalado.
- O Mapa de Serviços no Log Analytics fornece informações sobre o tráfego de entrada e saída de e para serviços externos. O Service Map integra-se com outras soluções, como atualizações ou segurança.
- Os vigilantes personalizados podem relatar condições de erro em serviços externos. Por exemplo, o serviço pode fornecer um relatório de integridade de erro se não puder acessar um serviço externo ou armazenamento de dados (Azure Cosmos DB).
Rastreio distribuído
Em uma arquitetura de microsserviços, vários serviços geralmente participam para concluir uma tarefa. A telemetria de cada um desses serviços é correlacionada por meio de campos de contexto (como ID da operação e ID da solicitação) em um rastreamento distribuído.
Usando o Mapa do Aplicativo no Application Insights, você pode criar a exibição de operações lógicas distribuídas e visualizar todo o gráfico de serviço do seu aplicativo. Você também pode usar o diagnóstico de transação no Application Insights para correlacionar a telemetria do lado do servidor. Para obter mais informações, consulte Diagnóstico unificado de transações entre componentes.
Também é importante correlacionar tarefas que são despachadas de forma assíncrona usando uma fila. Para obter detalhes sobre como enviar telemetria de correlação em uma mensagem de fila, consulte Instrumentação de fila.
Para obter mais informações, consulte:
Alertas e painéis
O Application Insights e o Log Analytics suportam uma linguagem de consulta extensiva (linguagem de consulta Kusto) que permite recuperar e analisar dados de log. Use as consultas para criar conjuntos de dados e visualizá-los em painéis de diagnóstico.
Use os alertas do Azure Monitor para notificar os administradores do sistema quando determinadas condições ocorrerem em recursos específicos. A notificação pode ser um email, uma função do Azure ou um webhook, por exemplo. Para obter mais informações, consulte Alertas no Azure Monitor.
As regras de alerta de pesquisa de log permitem definir e executar uma consulta Kusto em um espaço de trabalho do Log Analytics em intervalos regulares. Um alerta é criado se o resultado da consulta corresponder a uma determinada condição.
Otimização de custos
Utilize a calculadora de preços do Azure para prever os custos. Outras considerações são descritas no pilar de otimização de custos do Microsoft Azure Well-Architected Framework.
Aqui estão alguns pontos a considerar para alguns dos serviços usados nesta arquitetura.
Azure Service Fabric
Você é cobrado pelas instâncias de computação, armazenamento, recursos de rede e endereços IP escolhidos ao criar um cluster do Service Fabric. Há taxas de implantação para o Service Fabric.
Conjuntos de dimensionamento de máquinas virtuais
Nessa arquitetura, os microsserviços são implantados em nós que são conjuntos de escala de máquina virtual. Você é cobrado pelas VMs do Azure que são implantadas como parte do cluster e dos recursos de infraestrutura subjacentes, como armazenamento e rede. Não há cobranças incrementais para os próprios conjuntos de escala de máquina virtual.
API Management do Azure
O Gerenciamento de API do Azure é um gateway para rotear as solicitações dos clientes para seus serviços no cluster.
Existem várias opções de preços. A opção Consumo é cobrada com base no pagamento por uso e inclui um componente de gateway. Com base na sua carga de trabalho, escolha uma opção descrita em Preços do Gerenciamento de API.
Application Insights
Você pode usar o Application Insights para coletar telemetria para todos os serviços e exibir os rastreamentos e logs de eventos de forma estruturada. O preço do Application Insights é um modelo de pagamento conforme o uso baseado no volume de dados ingerido e nas opções de retenção de dados. Para obter mais informações, consulte Gerenciar o uso e o custo do Application Insights.
Azure Monitor
Para o Azure Monitor Log Analytics, você é cobrado pela ingestão e retenção de dados. Para obter mais informações, consulte Preços do Azure Monitor.
Azure Key Vault
Você usa o Azure Key Vault para armazenar a chave de instrumentação do Application Insights como um segredo. O Azure oferece o Cofre da Chave em duas camadas de serviço. Se você não precisar de chaves protegidas por HSM, escolha a camada Padrão. Para obter informações sobre os recursos em cada camada, consulte Preços do Key Vault.
Serviços de DevOps do Azure
Essa arquitetura de referência usa o Azure Pipelines para implantação. O serviço Azure Pipelines permite um trabalho gratuito hospedado pela Microsoft com 1.800 minutos por mês para CI/CD e um trabalho auto-hospedado com minutos ilimitados por mês. Trabalhos extras têm cobranças. Para obter mais informações, consulte Preços dos Serviços de DevOps do Azure.
Para obter considerações sobre DevOps em uma arquitetura de microsserviços, consulte CI/CD para microsserviços.
Para saber como implantar um aplicativo de contêiner com CI/CD em um cluster do Service Fabric, consulte este tutorial.
Implementar este cenário
Para implantar a implementação de referência para essa arquitetura, siga as etapas no repositório GitHub.
Próximos passos
- Treinamento: Introdução ao Azure Service Fabric
- Descrição Geral do Azure Service Fabric
- Documentação da Gestão de API
- O que é o Azure Pipelines?