Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Neste início rápido, você cria um servidor lógico no Azure e um banco de dados Hyperscale no Banco de Dados SQL do Azure usando o portal do Azure, um script do PowerShell ou um script da CLI do Azure, com a opção de criar uma ou mais réplicas de Alta Disponibilidade (HA). Se você quiser usar um servidor lógico existente no Azure, também poderá criar um banco de dados Hyperscale usando Transact-SQL.
Sugestão
Os preços simplificados para o SQL Database Hyperscale chegaram em dezembro de 2023. Consulte o blog de preços do Hyperscale para obter detalhes.
Pré-requisitos
- Uma assinatura ativa do Azure. Se tu não tiveres uma, cria uma conta gratuita.
- A versão mais recente do Azure PowerShell ou da CLI do Azure, se você quiser seguir o início rápido programaticamente. Como alternativa, você pode concluir o início rápido no portal do Azure.
- Um servidor lógico existente no Azure é necessário se você quiser criar um banco de dados Hyperscale com Transact-SQL. Para essa abordagem, você precisará executar Transact-SQL por meio do editor de consultas do portal do Azure, do SQL Server Management Studio (SSMS),do sqlcmd ou do cliente de sua escolha.
Permissions
Para criar bancos de dados via Transact-SQL:CREATE DATABASE são necessárias permissões. Para criar um banco de dados, é necessário que o logon seja o logon de administrador do servidor (configurado durante o provisionamento do servidor lógico do Azure SQL Database), o administrador Microsoft Entra do servidor ou um membro da função de banco de dados dbmanager no master. Para obter mais informações, consulte CREATE DATABASE.
Para criar bancos de dados por meio do portal do Azure, PowerShell, CLI do Azure ou API REST: as permissões do RBAC do Azure são necessárias, especificamente a função Colaborador, Colaborador do Banco de Dados SQL ou Colaborador do SQL Server RBAC do Azure. Para obter mais informações, consulte Funções internas do RBAC do Azure.
Criar um banco de dados Hyperscale
Este início rápido configura um único banco de dados na camada de serviço Hyperscale.
- Portal
- CLI do Azure
- PowerShell
- Transact-SQL
Para criar um único banco de dados no portal do Azure:
Vá para o hub SQL do Azure em aka.ms/azuresqlhub. No painel Hiperescala do Banco de Dados SQL do Azure, selecione Mostrar opções.
Na janela de opções do Banco de Dados SQL do Azure , selecione Criar Hiperescala do Banco de Dados SQL.

Na guia Noções básicas do formulário Criar Banco de Dados SQL , em Detalhes do projeto, selecione a Assinatura do Azure desejada.
Para Grupo de recursos, selecione Criar novo, insira myResourceGroup e selecione OK.
Em Nome do banco de dados, digite mySampleDatabase.
Em Servidor, selecione Criar novo e preencha o formulário Novo servidor com os seguintes valores:
- Nome do servidor: Digite mysqlserver e adicione alguns caracteres para exclusividade. Não podemos fornecer um nome de servidor exato para usar porque os nomes de servidor devem ser globalmente exclusivos para todos os servidores no Azure, não apenas exclusivos dentro de uma assinatura. Digite um nome, como mysqlserver12345, e o portal informará se ele está disponível.
- Login de administrador do servidor: insira azureuser.
- Senha: insira uma senha que atenda aos requisitos e digite-a novamente no campo Confirmar senha .
- Localização: selecione um local na lista suspensa.
Selecione OK.
Em Computação + armazenamento, selecione Configurar banco de dados.
Este guia de início rápido cria um banco de dados Hyperscale. Em Camada de serviço, selecione Hiperescala.
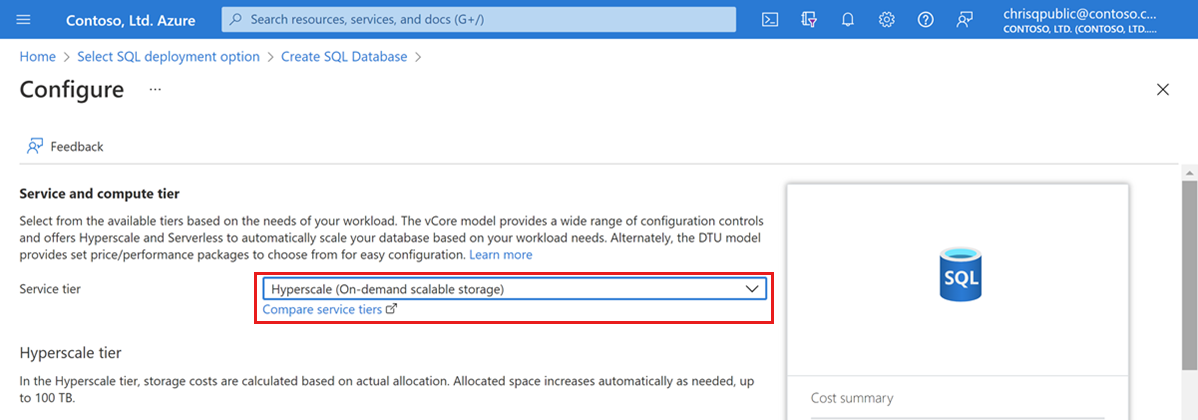
Em Hardware de computação, selecione Alterar configuração. Analise as configurações de hardware disponíveis e selecione a configuração mais apropriada para seu banco de dados. Para este exemplo, selecionaremos a configuração da série Standard (Gen5).
Selecione OK para confirmar a geração de hardware.
Opcionalmente, ajuste o controle deslizante vCores se quiser aumentar o número de vCores para seu banco de dados. Para este exemplo, selecionaremos 2 vCores.
Ajuste o controlo deslizante Réplicas Secundárias de Alta Disponibilidade para criar uma réplica de Alta Disponibilidade (HA).
Selecione Aplicar.
Considere cuidadosamente a opção de configuração para redundância de armazenamento de backup ao criar um banco de dados Hyperscale. A redundância de armazenamento só pode ser especificada durante o processo de criação de banco de dados para bancos de dados Hyperscale. Você pode escolher armazenamento localmente redundante, com redundância de zona ou com redundância geográfica. A opção de redundância de armazenamento selecionada será usada durante o tempo de vida do banco de dados para redundância de armazenamento de dados e redundância de armazenamento de backup. Os bancos de dados existentes podem migrar para redundância de armazenamento diferente usando cópia de banco de dados ou restauração point-in-time.

Selecione Next: Networking na parte inferior da página.
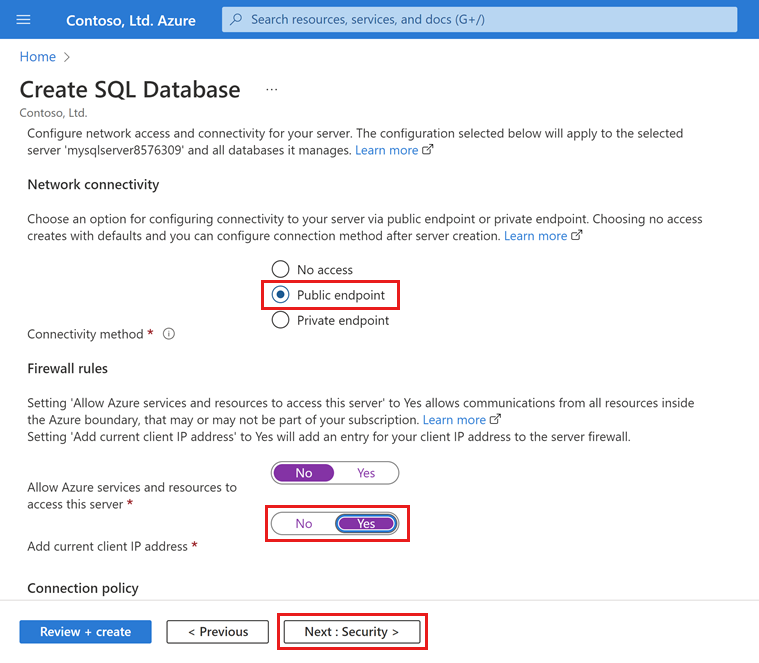
Na guia Rede , para Método de conectividade, selecione Ponto de extremidade público.
Para regras de firewall, defina Adicionar endereço IP do cliente atual como Sim. Deixe Permitir que os serviços e recursos do Azure acessem este servidor definido como Não.
Selecione Seguinte: Segurança na parte inferior da página.
Opcionalmente, habilite o Microsoft Defender para SQL.
Selecione Avançar: Configurações adicionais na parte inferior da página.
Na guia Configurações adicionais , na seção Fonte de dados , para Usar dados existentes, selecione Exemplo. Isso cria um banco de dados de exemplo AdventureWorksLT para que haja algumas tabelas e dados para consultar e experimentar, em vez de um banco de dados vazio em branco.
Selecione Analisar + criar na parte inferior da página:
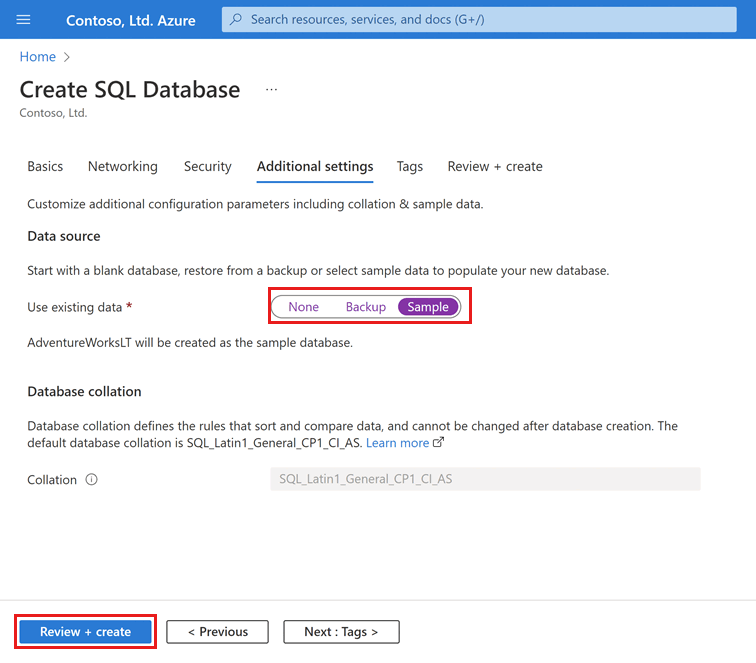
Na página Rever + criar , depois de rever, selecione Criar.






Consultar a base de dados
Depois que seu banco de dados for criado, você poderá usar o Editor de consultas (visualização) no portal do Azure para se conectar ao banco de dados e aos dados de consulta. Se preferir, você pode consultar alternadamente o banco de dados conectando-se ao SQL Server Management Studio (SSMS) ou ao cliente de sua escolha para executar comandos Transact-SQL (sqlcmd, etc.).
No portal, procure e selecione bancos de dados SQL e, em seguida, selecione seu banco de dados na lista.
Na página do seu banco de dados, selecione Editor de consultas (visualização) no menu à esquerda.
Insira as informações de login do administrador do servidor e selecione OK.
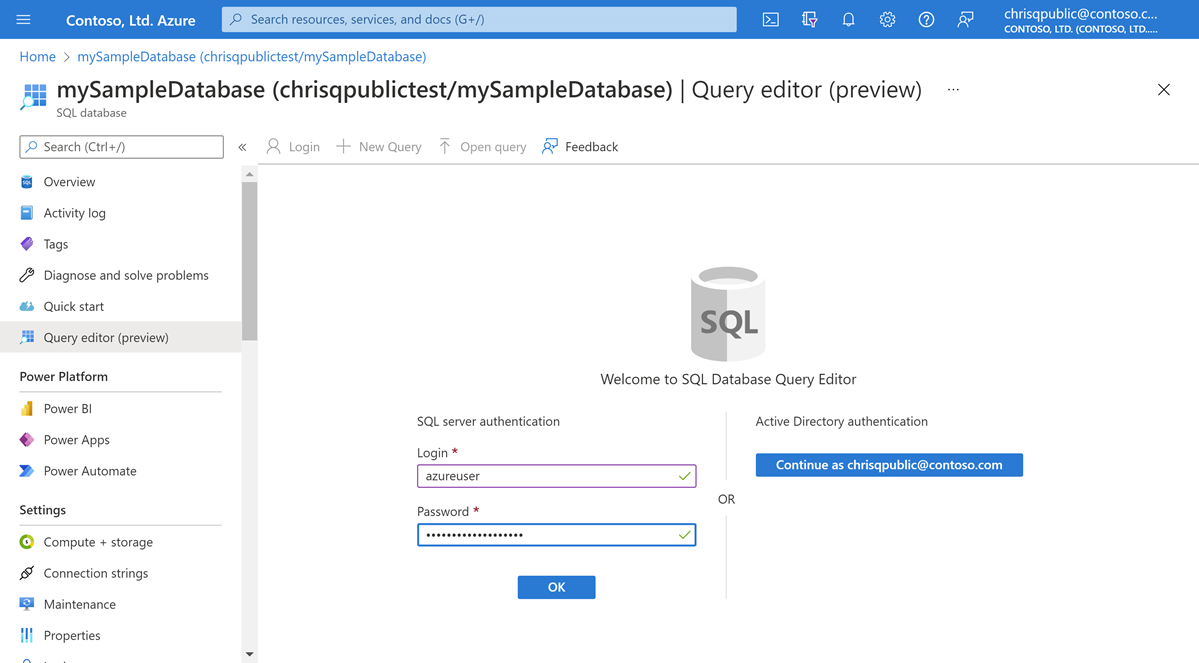
Se você criou seu banco de dados Hyperscale a partir do banco de dados de exemplo AdventureWorksLT, insira a seguinte consulta no painel Editor de consultas .
SELECT TOP 20 pc.Name as CategoryName, p.name as ProductName FROM SalesLT.ProductCategory pc JOIN SalesLT.Product p ON pc.productcategoryid = p.productcategoryid;Se você criou um banco de dados vazio usando o código de exemplo Transact-SQL, insira outra consulta de exemplo no painel Editor de consultas , como a seguinte:
CREATE TABLE dbo.TestTable( TestTableID int IDENTITY(1,1) NOT NULL, TestTime datetime NOT NULL, TestMessage nvarchar(4000) NOT NULL, CONSTRAINT PK_TestTable_TestTableID PRIMARY KEY CLUSTERED (TestTableID ASC) ) GO ALTER TABLE dbo.TestTable ADD CONSTRAINT DF_TestTable_TestTime DEFAULT (getdate()) FOR TestTime GO INSERT dbo.TestTable (TestMessage) VALUES (N'This is a test'); GO SELECT TestTableID, TestTime, TestMessage FROM dbo.TestTable; GOSelecione Executar e revise os resultados da consulta no painel Resultados .

Feche a página Editor de consultas e selecione OK quando solicitado a descartar as edições não salvas.


Limpeza de recursos
Mantenha o grupo de recursos, o servidor e o banco de dados único para passar para as próximas etapas e aprender a conectar e consultar seu banco de dados com métodos diferentes.
Quando terminar de usar esses recursos, você poderá excluir o grupo de recursos criado, que também excluirá o servidor e o banco de dados único dentro dele.
- Portal
- CLI do Azure
- PowerShell
- Transact-SQL
Para excluir myResourceGroup e todos os seus recursos usando o portal do Azure:
- No portal, procure e selecione Grupos de recursos e, em seguida, selecione myResourceGroup na lista.
- Na página do grupo de recursos, selecione Excluir grupo de recursos.
- Em Digite o nome do grupo de recursos, digite myResourceGroup e selecione Excluir.
Conteúdo relacionado
Conecte-se e consulte seu banco de dados usando diferentes ferramentas e idiomas:
- Conectar e consultar usando o SQL Server Management Studio
- A extensão mssql para Visual Studio Code
- sqlcmd
- Editor de consultas do portal do Azure para o Banco de Dados SQL do Azure
Saiba mais sobre bancos de dados Hyperscale nos seguintes artigos: