Neste início rápido, você cria um servidor lógico no Azure e um banco de dados Hyperscale no Banco de Dados SQL do Azure usando o portal do Azure, um script do PowerShell ou um script da CLI do Azure, com a opção de criar uma ou mais réplicas de Alta Disponibilidade (HA). Se você quiser usar um servidor lógico existente no Azure, também poderá criar um banco de dados Hyperscale usando Transact-SQL.
Para criar um único banco de dados no portal do Azure, este início rápido começa na página SQL do Azure.
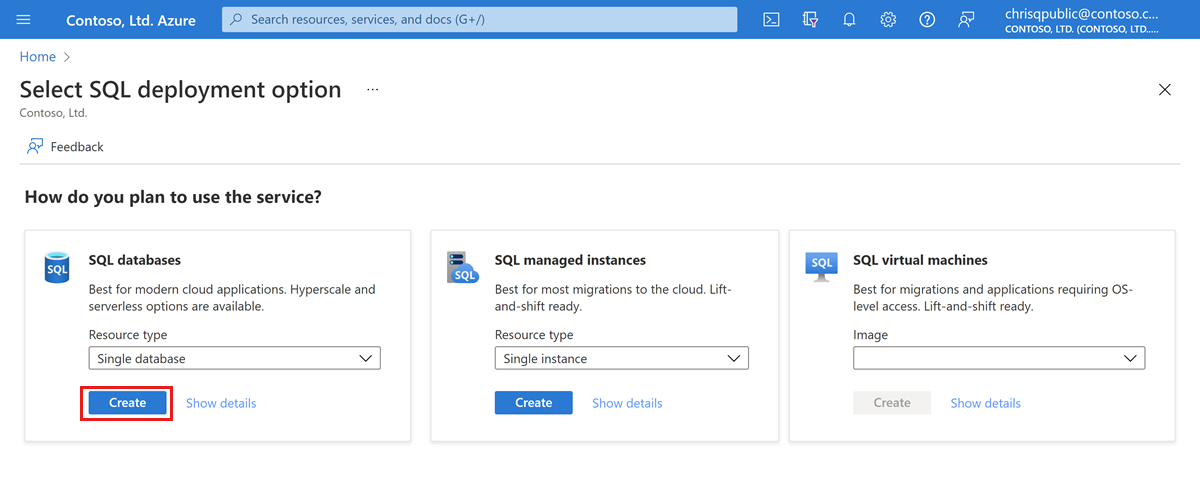
Navegue até a página de opção Selecionar Implantação SQL.
Em Bancos de dados SQL, deixe Tipo de recurso definido como Banco de dados único e selecione Criar.
Na guia Noções básicas do formulário Criar Banco de Dados SQL, em Detalhes do projeto, selecione a Assinatura do Azure desejada.
Para Grupo de recursos, selecione Criar novo, insira myResourceGroup e selecione OK.
Em Nome do banco de dados, digite mySampleDatabase.
Em Servidor, selecione Criar novo e preencha o formulário Novo servidor com os seguintes valores:
- Nome do servidor: Digite mysqlserver e adicione alguns caracteres para exclusividade. Não podemos fornecer um nome de servidor exato para usar porque os nomes de servidor devem ser globalmente exclusivos para todos os servidores no Azure, não apenas exclusivos dentro de uma assinatura. Digite um nome, como mysqlserver12345, e o portal informará se ele está disponível.
- Login de administrador do servidor: insira azureuser.
- Senha: insira uma senha que atenda aos requisitos e digite-a novamente no campo Confirmar senha .
- Localização: selecione um local na lista suspensa.
Selecione OK.
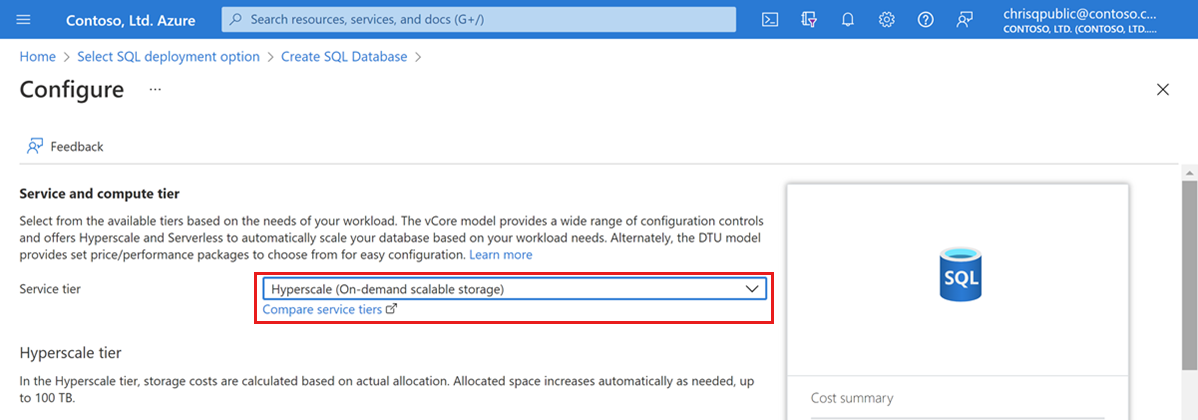
Em Computação + armazenamento, selecione a opção para configurar o servidor.
Este guia de início rápido cria um banco de dados Hyperscale. Em Camada de serviço, selecione Hiperescala.
Em Hardware de computação, selecione Alterar configuração. Analise as configurações de hardware disponíveis e selecione a configuração mais apropriada para seu banco de dados. Para este exemplo, selecionaremos a configuração da série Standard (Gen5).
Selecione OK para confirmar a geração de hardware.
Em Poupar dinheiro, analise se está qualificado para utilizar o Benefício Híbrido do Azure para esta base de dados. Em caso afirmativo, selecione Sim e confirme que tem a licença necessária.
Gorjeta
Preços simplificados para o SQL Database Hyperscale em breve. Consulte o blog de preços do Hyperscale para obter detalhes.
Opcionalmente, ajuste o controle deslizante vCores se quiser aumentar o número de vCores para seu banco de dados. Para este exemplo, selecionaremos 2 vCores.
Ajuste o controle deslizante Réplicas secundárias de alta disponibilidade para criar uma réplica de alta disponibilidade (HA).
Selecione Aplicar.
Considere cuidadosamente a opção de configuração para redundância de armazenamento de backup ao criar um banco de dados Hyperscale. A redundância de armazenamento só pode ser especificada durante o processo de criação de banco de dados para bancos de dados Hyperscale. Você pode escolher armazenamento localmente redundante, com redundância de zona ou com redundância geográfica. A opção de redundância de armazenamento selecionada será usada durante o tempo de vida do banco de dados para redundância de armazenamento de dados e redundância de armazenamento de backup. Os bancos de dados existentes podem migrar para redundância de armazenamento diferente usando cópia de banco de dados ou restauração point-in-time.

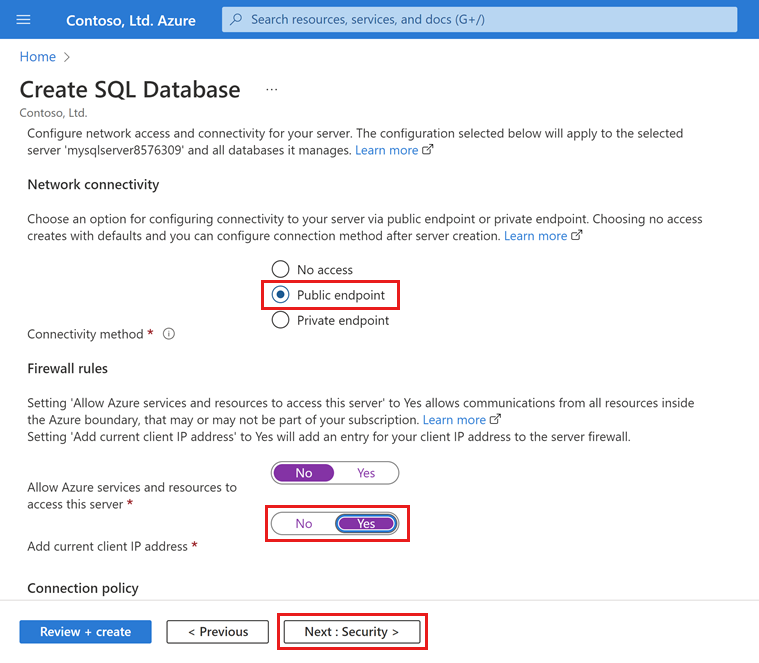
Selecione Next: Networking na parte inferior da página.
Na guia Rede, para Método de conectividade, selecione Ponto de extremidade público.
Para regras de firewall, defina Adicionar endereço IP do cliente atual como Sim. Deixe Permitir que os serviços e recursos do Azure acessem este servidor definido como Não.
Selecione Seguinte: Segurança na parte inferior da página.
Opcionalmente, habilite o Microsoft Defender para SQL.
Selecione Avançar: Configurações adicionais na parte inferior da página.
Na guia Configurações adicionais, na seção Fonte de dados, para Usar dados existentes, selecione Exemplo. Isso cria um banco de dados de exemplo AdventureWorksLT para que haja algumas tabelas e dados para consultar e experimentar, em vez de um banco de dados vazio em branco.
Selecione Rever + criar na parte inferior da página:
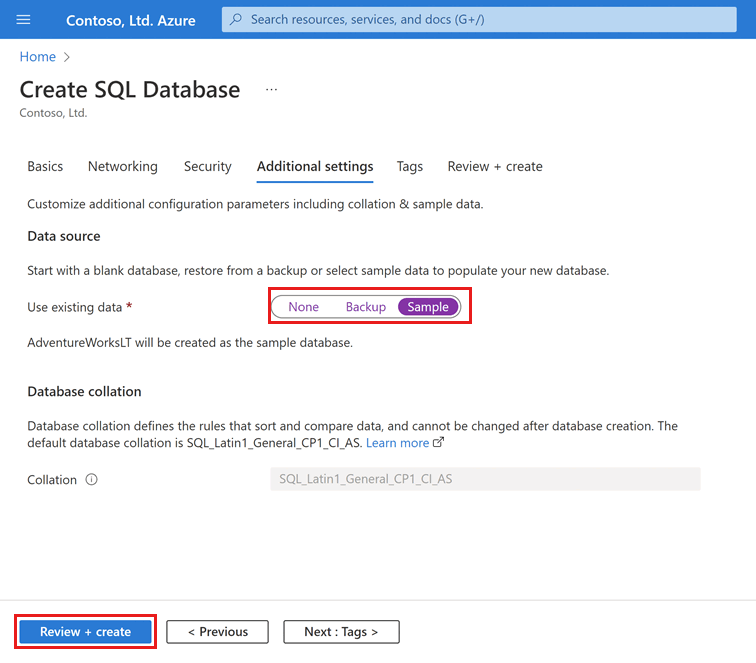
Na página Rever + criar, depois de rever, selecione Criar.
Os blocos de código da CLI do Azure nesta seção criam um grupo de recursos, servidor, banco de dados único e regra de firewall IP no nível do servidor para acesso ao servidor. Certifique-se de registrar o grupo de recursos gerado e os nomes dos servidores, para que você possa gerenciar esses recursos mais tarde.
Se não tiver uma subscrição do Azure, crie uma conta gratuita do Azure antes de começar.
Prepare o seu ambiente para o CLI do Azure
Use o ambiente Bash no Azure Cloud Shell. Para obter mais informações, consulte Guia de início rápido para Bash no Azure Cloud Shell.

Se preferir executar comandos de referência da CLI localmente, instale a CLI do Azure. Se estiver a utilizar o Windows ou macOS, considere executar a CLI do Azure num contentor Docker. Para obter mais informações, consulte Como executar a CLI do Azure em um contêiner do Docker.
Se estiver a utilizar uma instalação local, inicie sessão no CLI do Azure ao utilizar o comando az login. Para concluir o processo de autenticação, siga os passos apresentados no seu terminal. Para outras opções de entrada, consulte Entrar com a CLI do Azure.
Quando solicitado, instale a extensão da CLI do Azure na primeira utilização. Para obter mais informações sobre as extensões, veja Utilizar extensões com o CLI do Azure.
Execute o comando az version para localizar a versão e as bibliotecas dependentes instaladas. Para atualizar para a versão mais recente, execute o comando az upgrade.
Iniciar o Azure Cloud Shell
O Azure Cloud Shell é um shell interativo gratuito que pode utilizar para executar os passos neste artigo. Tem as ferramentas comuns do Azure pré-instaladas e configuradas para utilização com a sua conta.
Para abrir o Cloud Shell, selecione Experimente no canto superior direito de um bloco de código. Também pode iniciar o Cloud Shell num separador do browser separado ao aceder a https://shell.azure.com.
Quando o Cloud Shell abrir, verifique se o Bash está selecionado para o seu ambiente. As sessões subsequentes usarão a CLI do Azure em um ambiente Bash. Selecione Copiar para copiar os blocos de código, cole-o no Cloud Shell e pressione Enter para executá-lo.
Iniciar sessão no Azure
O Cloud Shell é autenticado automaticamente na conta inicial com a qual entrou conectado. Use o script a seguir para entrar usando uma assinatura diferente, substituindo <Subscription ID> pela sua ID de Assinatura do Azure. Se não tiver uma subscrição do Azure, crie uma conta gratuita do Azure antes de começar.
subscription="<subscriptionId>" # add subscription here
az account set -s $subscription # ...or use 'az login'
Para obter mais informações, consulte definir assinatura ativa ou fazer login interativamente
Definir valores de parâmetros
Os valores a seguir são usados em comandos subsequentes para criar o banco de dados e os recursos necessários. Os nomes de servidor precisam ser globalmente exclusivos em todo o Azure para que a função $RANDOM seja usada para criar o nome do servidor.
Antes de executar o código de exemplo, altere o location conforme apropriado para seu ambiente. Substitua 0.0.0.0 pelo intervalo de endereços IP para corresponder ao seu ambiente específico. Utilize o endereço IP público do computador que está a utilizar para restringir o acesso ao servidor apenas ao seu endereço IP.
# <FullScript>
# Create a single database and configure a firewall rule
# <SetParameterValues>
# Variable block
let "randomIdentifier=$RANDOM*$RANDOM"
location="East US"
resourceGroup="msdocs-azuresql-rg-$randomIdentifier"
tag="create-and-configure-database"
server="msdocs-azuresql-server-$randomIdentifier"
database="msdocsazuresqldb$randomIdentifier"
login="azureuser"
password="Pa$$w0rD-$randomIdentifier"
# Specify appropriate IP address values for your environment
# to limit access to the SQL Database server
startIp=0.0.0.0
let "randomIdentifier=$RANDOM*$RANDOM"
location="East US"
resourceGroupName="myResourceGroup"
tag="create-and-configure-database"
serverName="mysqlserver-$randomIdentifier"
databaseName="mySampleDatabase"
login="azureuser"
password="Pa$$w0rD-$randomIdentifier"
# Specify appropriate IP address values for your environment
# to limit access to the SQL Database server
startIp=0.0.0.0
endIp=0.0.0.0
echo "Using resource group $resourceGroupName with login: $login, password: $password..."
Criar um grupo de recursos
Crie um grupo de recursos com o comando az group create. Um grupo de recursos do Azure é um contentor lógico no qual os recursos do Azure são implementados e geridos. O exemplo a seguir cria um grupo de recursos no local especificado para o location parâmetro na etapa anterior:
echo "Creating $resourceGroupName in $location..."
az group create --name $resourceGroupName --location "$location" --tag $tag
Criar um servidor
Crie um servidor lógico com o comando az sql server create .
echo "Creating $serverName in $location..."
az sql server create --name $serverName --resource-group $resourceGroupName --location "$location" --admin-user $login --admin-password $password
Crie uma regra de firewall com o comando az sql server firewall-rule create .
echo "Configuring firewall..."
az sql server firewall-rule create --resource-group $resourceGroupName --server $serverName -n AllowYourIp --start-ip-address $startIp --end-ip-address $endIp
Criar um único banco de dados
Crie um banco de dados na camada de serviço Hyperscale com o comando az sql db create .
Ao criar um banco de dados Hyperscale, considere cuidadosamente a configuração do backup-storage-redundancy. A redundância de armazenamento só pode ser especificada durante o processo de criação de banco de dados para bancos de dados Hyperscale. Você pode escolher armazenamento localmente redundante, com redundância de zona ou com redundância geográfica. A opção de redundância de armazenamento selecionada será usada durante o tempo de vida do banco de dados para redundância de armazenamento de dados e redundância de armazenamento de backup. Os bancos de dados existentes podem migrar para redundância de armazenamento diferente usando cópia de banco de dados ou restauração point-in-time. Os valores permitidos para o backup-storage-redundancy parâmetro são: Local, , ZoneGeo. A menos que explicitamente especificado, os bancos de dados serão configurados para usar armazenamento de backup com redundância geográfica.
Execute o comando a seguir para criar um banco de dados Hyperscale preenchido com dados de exemplo AdventureWorksLT. O banco de dados usa hardware de série padrão (Gen5) com 2 vCores. O armazenamento de backup com redundância geográfica é usado para o banco de dados. O comando também cria uma réplica de Alta Disponibilidade (HA).
az sql db create \
--resource-group $resourceGroupName \
--server $serverName \
--name $databaseName \3
--sample-name AdventureWorksLT \
--edition Hyperscale \
--compute-model Provisioned \
--family Gen5 \
--capacity 2 \
--backup-storage-redundancy Geo \
--ha-replicas 1
Você pode criar um grupo de recursos, servidor e banco de dados único usando o Azure PowerShell.
Iniciar o Azure Cloud Shell
O Azure Cloud Shell é um shell interativo gratuito que pode utilizar para executar os passos neste artigo. Tem as ferramentas comuns do Azure pré-instaladas e configuradas para utilização com a sua conta.
Para abrir o Cloud Shell, selecione Experimente no canto superior direito de um bloco de código. Também pode iniciar o Cloud Shell num separador do browser separado ao aceder a https://shell.azure.com.
Quando o Cloud Shell abrir, verifique se o PowerShell está selecionado para seu ambiente. As sessões subsequentes usarão a CLI do Azure em um ambiente do PowerShell. Selecione Copiar para copiar os blocos de código, cole-o no Cloud Shell e pressione Enter para executá-lo.
Definir valores de parâmetros
Os valores a seguir são usados em comandos subsequentes para criar o banco de dados e os recursos necessários. Os nomes de servidor precisam ser globalmente exclusivos em todo o Azure para que o cmdlet Get-Random seja usado para criar o nome do servidor.
Antes de executar o código de exemplo, altere o location conforme apropriado para seu ambiente. Substitua 0.0.0.0 pelo intervalo de endereços IP para corresponder ao seu ambiente específico. Utilize o endereço IP público do computador que está a utilizar para restringir o acesso ao servidor apenas ao seu endereço IP.
# Set variables for your server and database
$resourceGroupName = "myResourceGroup"
$location = "eastus"
$adminLogin = "azureuser"
$password = "Pa$$w0rD-$(Get-Random)"
$serverName = "mysqlserver-$(Get-Random)"
$databaseName = "mySampleDatabase"
# The ip address range that you want to allow to access your server
$startIp = "0.0.0.0"
$endIp = "0.0.0.0"
# Show randomized variables
Write-host "Resource group name is" $resourceGroupName
Write-host "Server name is" $serverName
Write-host "Password is" $password
Criar grupo de recursos
Crie um grupo de recursos do Azure com New-AzResourceGroup. Um grupo de recursos é um contentor lógico no qual os recursos do Azure são implementados e geridos.
Write-host "Creating resource group..."
$resourceGroup = New-AzResourceGroup -Name $resourceGroupName -Location $location -Tag @{Owner="SQLDB-Samples"}
$resourceGroup
Criar um servidor
Crie um servidor com o cmdlet New-AzSqlServer .
Write-host "Creating primary server..."
$server = New-AzSqlServer -ResourceGroupName $resourceGroupName `
-ServerName $serverName `
-Location $location `
-SqlAdministratorCredentials $(New-Object -TypeName System.Management.Automation.PSCredential `
-ArgumentList $adminLogin, $(ConvertTo-SecureString -String $password -AsPlainText -Force))
$server
Criar uma regra de firewall
Crie uma regra de firewall de servidor com o cmdlet New-AzSqlServerFirewallRule .
Write-host "Configuring server firewall rule..."
$serverFirewallRule = New-AzSqlServerFirewallRule -ResourceGroupName $resourceGroupName `
-ServerName $serverName `
-FirewallRuleName "AllowedIPs" -StartIpAddress $startIp -EndIpAddress $endIp
$serverFirewallRule
Criar um único banco de dados
Crie um único banco de dados com o cmdlet New-AzSqlDatabase .
Ao criar um banco de dados Hyperscale, considere cuidadosamente a configuração do BackupStorageRedundancy. A redundância de armazenamento só pode ser especificada durante o processo de criação de banco de dados para bancos de dados Hyperscale. Você pode escolher armazenamento localmente redundante, com redundância de zona ou com redundância geográfica. A opção de redundância de armazenamento selecionada será usada durante o tempo de vida do banco de dados para redundância de armazenamento de dados e redundância de armazenamento de backup. Os bancos de dados existentes podem migrar para redundância de armazenamento diferente usando cópia de banco de dados ou restauração point-in-time. Os valores permitidos para o BackupStorageRedundancy parâmetro são: Local, , ZoneGeo. A menos que explicitamente especificado, os bancos de dados serão configurados para usar armazenamento de backup com redundância geográfica.
Execute o comando a seguir para criar um banco de dados Hyperscale preenchido com dados de exemplo AdventureWorksLT. O banco de dados usa hardware de série padrão (Gen5) com 2 vCores. O armazenamento de backup com redundância geográfica é usado para o banco de dados. O comando também cria uma réplica de Alta Disponibilidade (HA).
Write-host "Creating a standard-series (Gen5) 2 vCore Hyperscale database..."
$database = New-AzSqlDatabase -ResourceGroupName $resourceGroupName `
-ServerName $serverName `
-DatabaseName $databaseName `
-Edition Hyperscale `
-ComputeModel Provisioned `
-ComputeGeneration Gen5 `
-VCore 2 `
-MinimumCapacity 2 `
-SampleName "AdventureWorksLT" `
-BackupStorageRedundancy Geo `
-HighAvailabilityReplicaCount 1
$database
Para criar um banco de dados Hyperscale com Transact-SQL, você deve primeiro criar ou identificar informações de conexão para um servidor lógico existente no Azure.
Conecte-se ao banco de dados usando o SQL Server Management Studio (SSMS), o Azure Data Studio ou o master cliente de sua escolha para executar comandos Transact-SQL (sqlcmd, etc.).
Ao criar um banco de dados Hyperscale, considere cuidadosamente a configuração do BACKUP_STORAGE_REDUNDANCY. A redundância de armazenamento só pode ser especificada durante o processo de criação de banco de dados para bancos de dados Hyperscale. Você pode escolher armazenamento localmente redundante, com redundância de zona ou com redundância geográfica. A opção de redundância de armazenamento selecionada será usada durante o tempo de vida do banco de dados para redundância de armazenamento de dados e redundância de armazenamento de backup. Os bancos de dados existentes podem migrar para redundância de armazenamento diferente usando cópia de banco de dados ou restauração point-in-time. Os valores permitidos para o BackupStorageRedundancy parâmetro são: LOCAL, , ZONEGEO. A menos que explicitamente especificado, os bancos de dados serão configurados para usar armazenamento de backup com redundância geográfica.
Execute o seguinte comando Transact-SQL para criar um novo banco de dados Hyperscale com hardware Gen 5, 2 vCores e armazenamento de backup com redundância geográfica. Você deve especificar a edição e o objetivo do serviço na CREATE DATABASE instrução. Consulte os limites de recursos para obter uma lista de objetivos de serviço válidos, como HS_Gen5_2.
Este código de exemplo cria um banco de dados vazio. Se você quiser criar um banco de dados com dados de exemplo, use o portal do Azure, a CLI do Azure ou exemplos do PowerShell neste início rápido.
CREATE DATABASE [myHyperscaleDatabase]
(EDITION = 'Hyperscale', SERVICE_OBJECTIVE = 'HS_Gen5_2') WITH BACKUP_STORAGE_REDUNDANCY= 'LOCAL';
GO
Consulte CREATE DATABASE (Transact-SQL) para obter mais parâmetros e opções.
Para adicionar uma ou mais réplicas de Alta Disponibilidade (HA) ao seu banco de dados, use o painel Computação e armazenamento para o banco de dados no portal do Azure, o comando Set-AzSqlDatabase PowerShell ou o comando az sql db update Azure CLI.
Mantenha o grupo de recursos, o servidor e o banco de dados único para passar para as próximas etapas e aprender a conectar e consultar seu banco de dados com métodos diferentes.
Quando terminar de usar esses recursos, você poderá excluir o grupo de recursos criado, que também excluirá o servidor e o banco de dados único dentro dele.