Aplica-se a: do Banco de Dados SQL do Azure
do Banco de Dados SQL do Azure
A camada de serviço Hyperscale fornece uma camada de desempenho de computação e armazenamento altamente escalável que aproveita a arquitetura do Azure para dimensionar recursos de armazenamento e computação para um Banco de Dados SQL do Azure substancialmente além dos limites disponíveis para as camadas de serviço de Propósito Geral e Críticas para os Negócios.
Este artigo contém links para guias importantes para executar tarefas de administração essenciais para bancos de dados Hyperscale, incluindo a conversão de um banco de dados existente para Hyperscale, restauração de um banco de dados Hyperscale para uma região diferente, migração reversa do Hyperscale para outra camada de serviço e monitoramento do status de operações atuais e recentes em um banco de dados Hyperscale.
Saiba como criar um novo banco de dados Hyperscale em Guia de início rápido: criar um banco de dados Hyperscale no Banco de Dados SQL do Azure.
Monitorar operações de um banco de dados Hyperscale
Você pode monitorar o status de operações em andamento ou concluídas recentemente para um Banco de Dados SQL do Azure usando o portal do Azure, a CLI do Azure, o PowerShell ou o Transact-SQL.
Selecione a guia do seu método preferido para monitorar as operações.
O portal do Azure mostra uma notificação para um banco de dados no Banco de Dados SQL do Azure quando uma operação como uma migração, migração reversa ou restauração está em andamento.
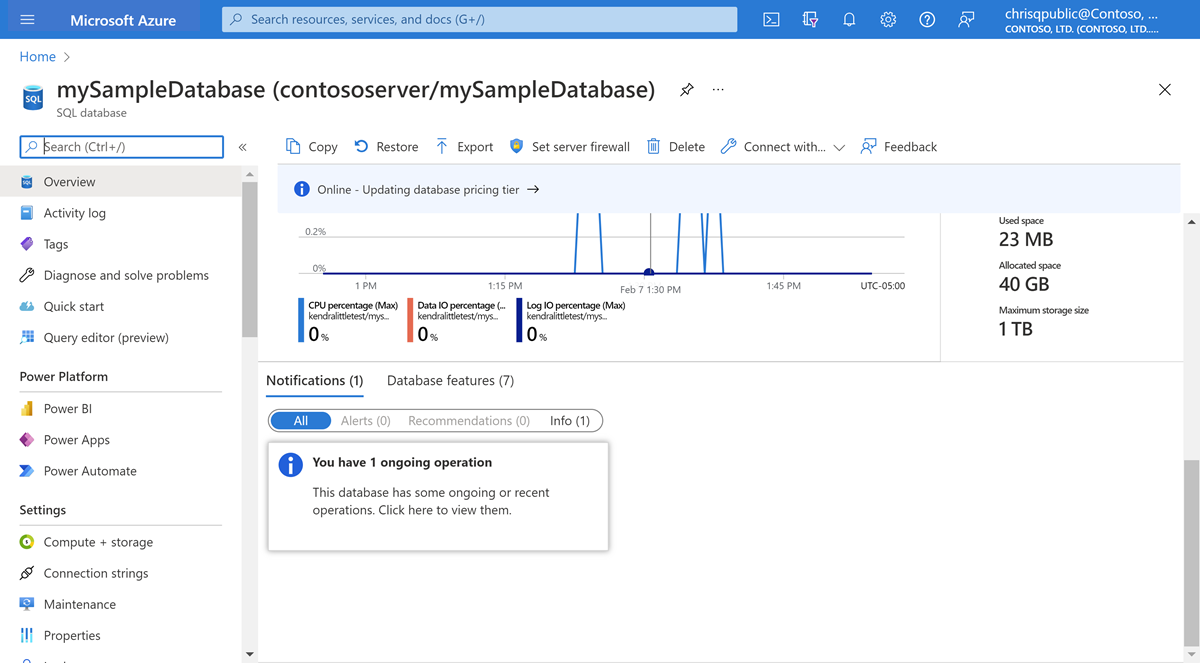
- Navegue até o banco de dados no portal do Azure.
- Na barra de navegação esquerda, selecione Visão geral.
- Revise a seção Notificações na parte inferior do painel direito. Se as operações estiverem em andamento, uma caixa de notificação será exibida.
- Selecione a caixa de notificação para ver os detalhes.
- O painel Operações em curso abre. Analise os detalhes das operações em curso.
Este exemplo de código utiliza o comando az sql db op list para listar operações recentes ou em andamento de um banco de dados no Azure SQL Database.
Substitua resourceGroupName, serverName, databaseNamee serviceObjective pelos valores apropriados antes de executar o seguinte exemplo de código:
resourceGroupName="myResourceGroup"
serverName="server01"
databaseName="mySampleDatabase"
az sql db op list -g $resourceGroupName -s $serverName --database $databaseName
O cmdlet Get-AzSqlDatabaseActivity retorna operações recentes ou em andamento para um banco de dados no Banco de Dados SQL do Azure.
Defina os parâmetros $resourceGroupName, $serverNamee $databaseName para os valores apropriados para seu banco de dados antes de executar o código de exemplo:
$resourceGroupName = "myResourceGroup"
$serverName = "server01"
$databaseName = "mySampleDatabase"
Get-AzSqlDatabaseActivity -ResourceGroupName $resourceGroupName -ServerName $serverName -DatabaseName $databaseName
Para monitorar operações para um banco de dados Hyperscale, primeiro conecte-se ao banco de dados em seu master usando o SQL Server Management Studio (SSMS) ou o cliente de sua escolha para executar comandos Transact-SQL.
Consulte a Vista de Gestão Dinâmica sys.dm_operation_status para rever informações sobre operações recentes realizadas em bases de dados no seu [servidor lógico](logical-servers.md].
Este exemplo de código retorna todos os inteiros em sys.dm_operation_status para o banco de dados especificado, classificado por quais operações começaram mais recentemente. Substitua o nome do banco de dados pelo valor apropriado antes de executar o exemplo de código.
SELECT *
FROM sys.dm_operation_status
WHERE major_resource_id = 'mySampleDatabase'
ORDER BY start_time DESC;
GO
Exibir bancos de dados na camada de serviço Hyperscale
Depois de migrar um banco de dados para o Hyperscale ou reconfigurar um banco de dados dentro da camada de serviço Hyperscale, talvez você queira visualizar e/ou documentar a configuração do seu banco de dados Hyperscale.
O portal do Azure mostra uma lista de todos os bancos de dados em um servidor lógico . A coluna da camada de preços inclui a camada de serviço para cada banco de dados.
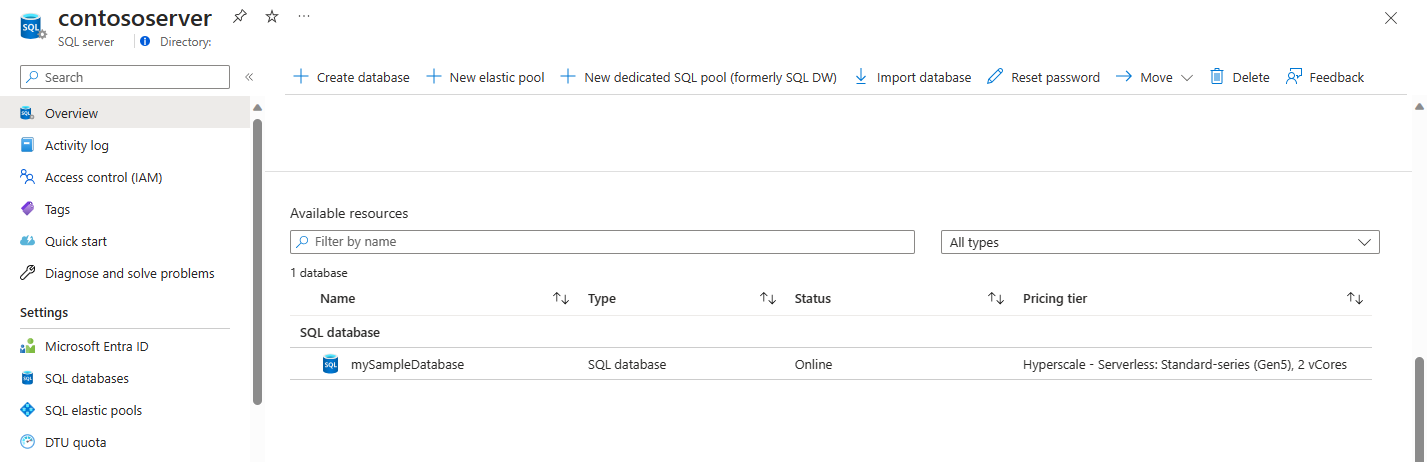
- Navegue até o do servidor lógico no portal do Azure.
- Na barra de navegação esquerda, selecione Visão geral.
- Desloque-se para a lista de recursos na parte inferior do painel. A janela exibe os pools elásticos SQL e os bancos de dados no servidor lógico.
- Analise a coluna da camada de preços para identificar bancos de dados na camada de serviço de hiperescala.
Este exemplo de código da CLI do Azure invoca az sql db list para listar bancos de dados Hyperscale em um servidor lógico com o seu nome, localização, objetivo de nível de serviço, tamanho máximo e número de réplicas de alta disponibilidade.
Substitua resourceGroupName e serverName pelos valores apropriados antes de executar o seguinte exemplo de código:
resourceGroupName="myResourceGroup"
serverName="server01"
az sql db list -g $resourceGroupName -s $serverName --query "[].{Name:name, Location:location, SLO:currentServiceObjectiveName, Tier:currentSku.tier, maxSizeBytes:maxSizeBytes,HAreplicas:highAvailabilityReplicaCount}[?Tier=='Hyperscale']" --output table
O cmdlet Get-AzSqlDatabase do Azure PowerShell retorna uma lista de bancos de dados Hyperscale em um servidor lógico com seu nome, local, objetivo de nível de serviço, tamanho máximo e número de réplicas de alta disponibilidade.
Defina os parâmetros $resourceGroupName e $serverName para os valores apropriados antes de executar o código de exemplo:
$resourceGroupName = "myResourceGroup"
$serverName = "server01"
Get-AzSqlDatabase -ResourceGroupName $resourceGroupName -ServerName $serverName | `
Where-Object { $_.Edition -eq 'Hyperscale' } | `
Select-Object DatabaseName, Location, currentServiceObjectiveName, Edition, `
MaxSizeBytes, HighAvailabilityReplicaCount | `
Format-Table
Analise a coluna do Edition para identificar bancos de dados na camada de serviço Hyperscale.
Para examinar as camadas de serviço de todos os bancos de dados Hyperscale em um servidor lógico com Transact-SQL, primeiro conecte-se ao banco de dados usando o masterSQL Server Management Studio (SSMS).
Consulte a vista do catálogo do sistema sys.database_service_objectives para revisar bancos de dados no nível de serviço Hyperscale:
SELECT d.name, dso.edition, dso.service_objective
FROM sys.database_service_objectives AS dso
JOIN sys.databases as d on dso.database_id = d.database_id
WHERE dso.edition = 'Hyperscale';
GO
Converter banco de dados em Hyperscale
Você pode converter um banco de dados existente no Banco de Dados SQL do Azure em Hyperscale usando o portal do Azure, a CLI do Azure, o PowerShell ou o Transact-SQL.
O processo de conversão é dividido em duas fases - a conversão de dados, que ocorre enquanto o banco de dados existente está on-line e, em seguida, uma transferência para o novo banco de dados Hyperscale. Você tem a capacidade de escolher quando a transferência ocorre - assim que o banco de dados estiver pronto, ou manualmente no momento de sua escolha.
Para obter mais informações e etapas, consulte Converter um banco de dados existente em Hyperscale.
Migração reversa do Hyperscale
A migração reversa para a camada de serviço de Uso Geral permite que os clientes que converteram recentemente um banco de dados existente no Banco de Dados SQL do Azure para o Hyperscale voltem em uma emergência, caso o Hyperscale não atenda às suas necessidades. Embora a migração reversa seja iniciada por uma alteração na camada de serviço, ela é essencialmente uma movimentação de tamanho de dados entre arquiteturas diferentes.
Para obter mais informações e etapas, consulte migrar reversamente um banco de dados do Hyperscale.
Conteúdo relacionado

