Escalão de computação sem servidor para a Base de Dados SQL do Azure
Aplica-se a:![]() Banco de Dados SQL do Azure
Banco de Dados SQL do Azure
Serverless é uma camada de computação para bancos de dados únicos no Banco de Dados SQL do Azure que dimensiona automaticamente a computação com base na demanda de carga de trabalho e fatura a quantidade de computação usada por segundo. O nível de computação sem servidor também coloca automaticamente em pausa as bases de dados durante períodos inativos quando apenas o armazenamento é faturado e retoma automaticamente as bases de dados quando a atividade é retomada. A camada de computação sem servidor está disponível na camada de serviço de uso geral e na camada deserviço Hyperscale .
Nota
Atualmente, a pausa e a retomada automáticas são suportadas apenas na camada de serviço de uso geral.
Descrição geral
Um intervalo de dimensionamento automático de computação e um atraso de pausa automática são parâmetros importantes para a camada de computação sem servidor. A configuração desses parâmetros molda a experiência de desempenho do banco de dados e o custo de computação.
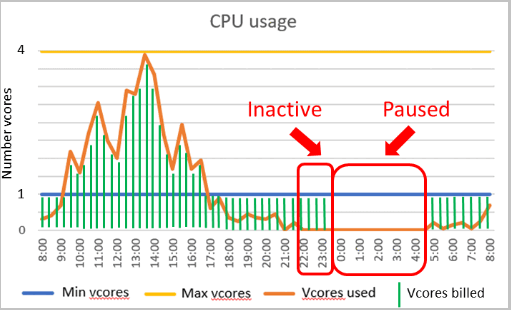
Configuração do desempenho
- Os vCores mínimos e máximos são parâmetros configuráveis que definem o intervalo de capacidade de computação disponível para o banco de dados. Os limites de memória e E/S são proporcionais ao intervalo vCore especificado.
- O atraso de pausa automática é um parâmetro configurável que define o período de tempo em que o banco de dados deve ficar inativo antes de ser pausado automaticamente. O banco de dados é retomado automaticamente quando ocorre a próxima entrada ou outra atividade. Como alternativa, a pausa automática pode ser desativada.
Custo
- O custo de um banco de dados sem servidor é a soma do custo de computação e do custo de armazenamento.
- Quando o uso de computação está entre os limites mínimo e máximo configurados, o custo de computação é baseado no vCore e na memória usada.
- Quando o uso de computação está abaixo dos limites mínimos configurados, o custo de computação é baseado nos vCores mínimos e na memória mínima configurada.
- Quando o banco de dados é pausado, o custo de computação é zero e apenas os custos de armazenamento são incorridos.
- O custo de armazenamento é determinado da mesma forma que no nível de computação provisionado.
Para obter mais detalhes de custo, consulte Faturamento.
Cenários
O escalão Sem servidor está otimizado para uma relação preço/desempenho das bases de dados individuais com padrões de utilização imprevisíveis ou intermitentes que se podem permitir ter algum atraso no aquecimento da computação após períodos de inatividade. Por outro lado, a camada de computação provisionada é otimizada em termos de preço-desempenho para bancos de dados únicos ou vários bancos de dados em pools elásticos com uso médio mais alto que não podem suportar qualquer atraso no aquecimento da computação.
Cenários adequados para computação sem servidor
- Bases de dados individuais com padrões de utilização intermitentes e imprevisíveis intercalados com períodos de inatividade e uma utilização abaixo da média da computação ao longo do tempo.
- Bases de dados individuais no escalão de computação aprovisionada que são frequentemente redimensionadas e clientes que preferem delegar o redimensionamento da computação ao serviço.
- Novos bancos de dados únicos sem histórico de uso em que o dimensionamento de computação é difícil ou não é possível estimar antes da implantação em um Banco de Dados SQL do Azure.
Cenários adequados para computação provisionada
- Bancos de dados únicos com padrões de uso mais regulares e previsíveis e maior utilização média de computação ao longo do tempo.
- Bancos de dados que não podem tolerar compensações de desempenho resultantes de cortes de memória mais frequentes ou atrasos na retomada de um estado pausado.
- Vários bancos de dados com padrões de uso intermitentes e imprevisíveis que podem ser consolidados em pools elásticos para melhor otimização de preço-desempenho.
Comparar níveis de computação
A tabela a seguir resume as distinções entre a camada de computação sem servidor e a camada de computação provisionada:
| Computação sem servidor | Computação provisionada | |
|---|---|---|
| Padrão de uso do banco de dados | Uso intermitente e imprevisível com menor utilização média de computação ao longo do tempo. | Padrões de uso mais regulares com maior utilização média de computação ao longo do tempo ou vários bancos de dados usando pools elásticos. |
| Esforço de gestão do desempenho | Lower | Mais alto |
| Dimensionamento de computação | Automático | Manual |
| Capacidade de resposta computacional | Menor após períodos inativos | Imediata |
| Granularidade de faturamento | Por segundo | Por hora |
Modelo de compra e nível de serviço
A tabela a seguir descreve o suporte sem servidor com base no modelo de compra, camadas de serviço e hardware:
| Categoria | Suportado | Não suportado |
|---|---|---|
| Modelo de compra | vCore | DTU |
| Escalão de serviço | Fins Gerais Hyperscale |
Crítico para a Empresa |
| Hardware | Série padrão (Gen5) | Todos os outros hardwares |
Dimensionamento automático
Capacidade de resposta de dimensionamento
Os bancos de dados sem servidor são executados em uma máquina com capacidade suficiente para satisfazer a demanda de recursos sem interrupção para qualquer quantidade de computação solicitada dentro dos limites definidos pelo valor máximo de vCores. Ocasionalmente, o balanceamento de carga ocorre automaticamente se a máquina não conseguir satisfazer a demanda de recursos em poucos minutos. Por exemplo, se a demanda de recursos for de 4 vCores, mas apenas 2 vCores estiverem disponíveis, pode levar até alguns minutos para balancear a carga antes que 4 vCores sejam fornecidos. O banco de dados permanece online durante o balanceamento de carga, exceto por um breve período no final da operação, quando as conexões são descartadas.
Gestão da memória
Nas camadas de serviço de uso geral e hiperescala, a memória para bancos de dados sem servidor é recuperada com mais frequência do que para bancos de dados de computação provisionados. Esse comportamento é importante para controlar os custos no serverless e pode afetar o desempenho.
Recuperação de cache
Ao contrário dos bancos de dados de computação provisionados, a memória do cache SQL é recuperada de um banco de dados sem servidor quando a utilização da CPU ou do cache ativo é baixa.
- A utilização do cache ativo é considerada baixa quando o tamanho total das entradas de cache usadas mais recentemente fica abaixo de um limite, por um período de tempo.
- Quando a recuperação de cache é acionada, o tamanho do cache de destino é reduzido incrementalmente para uma fração de seu tamanho anterior e a recuperação só continua se o uso permanecer baixo.
- Quando a recuperação de cache ocorre, a política para selecionar entradas de cache a serem removidas é a mesma política de seleção para bancos de dados de computação provisionados quando a pressão de memória é alta.
- O tamanho do cache nunca é reduzido abaixo do limite mínimo de memória, conforme definido pelo mínimo de vCores.
Em bancos de dados de computação sem servidor e provisionados, as entradas de cache podem ser removidas se toda a memória disponível for usada.
Quando a utilização da CPU é baixa, a utilização do cache ativo pode permanecer alta dependendo do padrão de uso e impedir a recuperação de memória. Além disso, pode haver outros atrasos após a atividade do usuário parar antes que a recuperação de memória ocorra devido a processos periódicos em segundo plano que respondem à atividade anterior do usuário. Por exemplo, as operações de exclusão e as tarefas de limpeza do Repositório de Consultas geram registros fantasmas que são marcados para exclusão, mas não são excluídos fisicamente até que o processo de limpeza fantasma seja executado. A limpeza fantasma pode envolver a leitura de páginas de dados em cache.
Hidratação do cache
O cache de memória SQL cresce à medida que os dados são buscados no disco da mesma maneira e com a mesma velocidade dos bancos de dados provisionados. Quando o banco de dados está ocupado, o cache pode crescer sem restrições enquanto há memória disponível.
Gerenciamento de cache de disco
Na camada de serviço Hyperscale para as camadas de computação sem servidor e provisionadas, cada réplica de computação usa um cache RBPEX (Resilient Buffer Pool Extension), que armazena páginas de dados em SSD local para melhorar o desempenho de E/S. No entanto, na camada de computação sem servidor para Hyperscale, o cache RBPEX para cada réplica de computação cresce e diminui automaticamente em resposta à demanda crescente e decrescente de carga de trabalho. O tamanho máximo que o cache RBPEX pode aumentar é três vezes a memória máxima configurada para o banco de dados. Para obter detalhes sobre a memória máxima e os limites de dimensionamento automático RBPEX no serverless, consulte serverless Hyperscale resource limits.
Pausa e retomada automáticas
Atualmente, a pausa automática sem servidor e a retomada automática são suportadas apenas na camada de uso geral.
Pausa automática
A pausa automática é acionada se todas as seguintes condições forem verdadeiras durante o atraso da pausa automática:
- Número de sessões = 0
- CPU = 0 para a carga de trabalho do utilizador em execução no agrupamento de recursos do utilizador
É fornecida uma opção para desativar a pausa automática, se desejado.
Os recursos a seguir não suportam pausa automática, mas suportam dimensionamento automático. Se qualquer um dos seguintes recursos for usado, a pausa automática deverá ser desabilitada e o banco de dados permanecerá online, independentemente da duração da inatividade do banco de dados:
- Replicação geográfica (grupos ativos de replicação geográfica e failover).
- Retenção de backup de longo prazo (LTR).
- O banco de dados de sincronização usado no SQL Data Sync. Ao contrário dos bancos de dados sincronizados, os bancos de dados de hub e membros suportam pausa automática.
- Alias DNS criado para o servidor lógico que contém um banco de dados sem servidor.
- Trabalhos elásticos (visualização), o banco de dados sem servidor habilitado para pausa automática não é suportado como um banco de dados de trabalhos. Os bancos de dados sem servidor direcionados por trabalhos elásticos oferecem suporte à pausa automática. As conexões de trabalho retomarão um banco de dados.
A pausa automática é temporariamente impedida durante a implantação de algumas atualizações de serviço, que exigem que o banco de dados esteja online. Nesses casos, a pausa automática torna-se permitida novamente assim que a atualização do serviço for concluída.
Solução de problemas de pausa automática
Se a pausa automática estiver habilitada e os recursos que bloqueiam a pausa automática não forem usados, mas um banco de dados não fizer a pausa automática após o período de atraso, as sessões do aplicativo ou do usuário podem estar impedindo a pausa automática.
Para ver se existem quaisquer sessões de utilizador ou aplicação atualmente ligadas à base de dados, ligue-se à base de dados através de qualquer ferramenta do cliente e execute a seguinte consulta:
SELECT session_id,
host_name,
program_name,
client_interface_name,
login_name,
status,
login_time,
last_request_start_time,
last_request_end_time
FROM sys.dm_exec_sessions AS s
INNER JOIN sys.dm_resource_governor_workload_groups AS wg
ON s.group_id = wg.group_id
WHERE s.session_id <> @@SPID
AND
(
(
wg.name like 'UserPrimaryGroup.DB%'
AND
TRY_CAST(RIGHT(wg.name, LEN(wg.name) - LEN('UserPrimaryGroup.DB') - 2) AS int) = DB_ID()
)
OR
wg.name = 'DACGroup'
);
Gorjeta
Depois de executar a consulta, certifique-se de se desconectar do banco de dados. Caso contrário, a sessão aberta usada pela consulta impedirá a pausa automática.
- Se o conjunto de resultados não estiver vazio, isso indica que há sessões atualmente impedindo a pausa automática.
- Se o conjunto de resultados estiver vazio, ainda será possível que as sessões estivessem abertas, possivelmente durante um curto período de tempo, em algum momento anteriormente durante o período de atraso da pausa automática. Para verificar a atividade durante o período de atraso, você pode usar a Auditoria SQL do Azure e examinar os dados de auditoria para o período relevante.
Importante
A presença de sessões abertas, com ou sem utilização simultânea da CPU no conjunto de recursos do utilizador, é o motivo mais comum para uma base de dados sem servidor não fazer ser colocada em pausa automática como esperado.
Retomada automática
A retomada automática é acionada se qualquer uma das seguintes condições for verdadeira a qualquer momento:
| Funcionalidade | Gatilho de retomada automática |
|---|---|
| Autenticação e autorização | Iniciar sessão |
| Deteção de ameaças | Ativar/desativar definições de deteção de ameaças ao nível da base de dados ou do servidor. Modificar definições de deteção de ameaças ao nível da base de dados ou do servidor. |
| Deteção e classificação de dados | Adicionar, modificar, eliminar ou visualizar etiquetas de sensibilidade |
| Auditoria | Ver registos de auditoria. Atualizar ou ver a política de auditoria. |
| Máscara de dados | Adicionar, modificar, excluir ou visualizar regras de mascaramento de dados |
| Encriptação de dados transparente | Visualizando o estado ou o status da criptografia de dados transparente |
| Avaliação de vulnerabilidades | Varreduras ad hoc e verificações periódicas, se ativadas |
| Arquivo de dados (de desempenho) de consulta | Modificando ou exibindo configurações de armazenamento de consultas |
| Recomendações de desempenho | Visualizar ou aplicar recomendações de desempenho |
| Ajuste automático | Aplicação e verificação de recomendações de ajuste automático, como indexação automática |
| Cópia de base de dados | Criar base de dados como cópia. Exporte para um arquivo BACPAC. |
| Sincronização de dados SQL | Sincronização entre bancos de dados de hub e membros que são executados em uma programação configurável ou são executados manualmente |
| Modificar determinados metadados de base de dados | Adicionando novas tags de banco de dados. Alterar vCores máximos, vCores mínimos ou atraso de pausa automática. |
| SQL Server Management Studio (SSMS) | Quando você usa versões do SSMS anteriores à 18.1 e abre uma nova janela de consulta para qualquer banco de dados no servidor, qualquer banco de dados pausado automaticamente no mesmo servidor é retomado. Esse comportamento não ocorre se estiver usando o SSMS versão 18.1 ou posterior. |
- O monitoramento, o gerenciamento ou outras soluções que executam qualquer uma dessas operações listadas acionam a retomada automática.
- A retomada automática também é acionada durante a implantação de algumas atualizações de serviço que exigem que o banco de dados esteja online.
Conectividade
Se um banco de dados sem servidor for pausado, a primeira atividade de entrada retomará o banco de dados e retornará um erro informando que o banco de dados não está disponível com o código de erro 40613. Depois que o banco de dados for retomado, o login poderá ser tentado novamente para estabelecer a conectividade. Os clientes de banco de dados com uma lógica de repetição de conexão recomendada não precisam ser modificados. Para obter os padrões recomendados para a lógica de repetição de conexão, revise:
- Lógica de repetição em SqlClient
- Repetir a lógica no Banco de dados SQL usando o Entity Framework Core
- Lógica de repetição no Banco de dados SQL usando o Entity Framework 6
- Repetir a lógica no Banco de dados SQL usando ADO.NET
Latência
A latência para retomar e pausar automaticamente um banco de dados sem servidor é geralmente ordem de 1 minuto para retomar automaticamente e 1-10 minutos após a expiração do período de atraso para pausa automática.
Encriptação de dados transparente gerida pelo cliente (BYOK)
Exclusão ou revogação de chave
Se o uso da criptografia de dados transparente gerenciada pelo cliente (BYOK) e o banco de dados sem servidor for pausado automaticamente quando ocorrer a exclusão ou revogação de chaves, o banco de dados permanecerá no estado de pausa automática. Nesse caso, depois que o banco de dados é retomado em seguida, o banco de dados torna-se inacessível dentro de aproximadamente 10 minutos. Quando o banco de dados se torna inacessível, o processo de recuperação é o mesmo dos bancos de dados de computação provisionados. Se o banco de dados sem servidor estiver online quando ocorrer a exclusão ou revogação de chaves, o banco de dados também ficará inacessível em aproximadamente 10 minutos, da mesma forma que com bancos de dados de computação provisionados.
Rotação de chaves
Se estiver usando a criptografia de dados transparente gerenciada pelo cliente (BYOK) e o banco de dados sem servidor for pausado automaticamente, a rotação automatizada de chaves será adiada até que o banco de dados seja retomado automaticamente.
Criar um novo banco de dados sem servidor
Criar um novo banco de dados ou mover um banco de dados existente para uma camada de computação sem servidor segue o mesmo padrão da criação de um novo banco de dados na camada de computação provisionada e envolve as duas etapas a seguir:
Especifique o objetivo do serviço. O objetivo de serviço prescreve a camada de serviço, a configuração de hardware e o máximo de vCores. Para opções de objetivo de serviço, consulte Limites de recursos sem servidor
Opcionalmente, especifique o vCores mínimo e o atraso de pausa automática para alterar seus valores padrão. A tabela a seguir mostra os valores disponíveis para esses parâmetros.
Parâmetro Opções de valor Default value Mínimo de vCores Depende do máximo de vCores configurados - consulte limites de recursos. 0,5 vCores Atraso de pausa automática Mínimo: 60 minutos (1 hora)
Máximo: 10.080 minutos (7 dias)
Incrementos: 10 minutos
Desativar pausa automática: -160 minutos
Os exemplos a seguir criam um novo banco de dados na camada de computação sem servidor.
Utilizar o portal do Azure
Utilizar o PowerShell
Crie um novo banco de dados de uso geral sem servidor com o seguinte exemplo do PowerShell:
New-AzSqlDatabase -ResourceGroupName $resourceGroupName -ServerName $serverName -DatabaseName $databaseName `
-Edition GeneralPurpose -ComputeModel Serverless -ComputeGeneration Gen5 `
-MinVcore 0.5 -MaxVcore 2 -AutoPauseDelayInMinutes 720
Utilizar a CLI do Azure
Crie um novo banco de dados de uso geral sem servidor com o seguinte exemplo de CLI do Azure:
az sql db create -g $resourceGroupName -s $serverName -n $databaseName `
-e GeneralPurpose --compute-model Serverless -f Gen5 `
--min-capacity 0.5 -c 2 --auto-pause-delay 720
Usar Transact-SQL (T-SQL)
Quando você usa o T-SQL para criar um novo banco de dados sem servidor, os valores padrão são aplicados para o vCores mínimo e o atraso de pausa automática. Eles podem ser alterados posteriormente no portal do Azure ou por meio de outras APIs de gerenciamento (PowerShell, CLI do Azure, API REST).
Para obter detalhes, consulte CREATE DATABASE.
Crie um novo banco de dados sem servidor de uso geral com o seguinte exemplo de T-SQL:
CREATE DATABASE testdb
( EDITION = 'GeneralPurpose', SERVICE_OBJECTIVE = 'GP_S_Gen5_1' ) ;
Mover um banco de dados entre camadas de computação
É possível mover seu banco de dados da camada de computação provisionada para a camada de computação sem servidor e vice-versa.
Nota
Também é possível atualizar seu banco de dados na camada de uso geral para a camada de hiperescala. Consulte Gerenciar bancos de dados de hiperescala para saber mais.
Ao mover seu banco de dados entre camadas de computação, forneça o parâmetro Compute model como ou ServerlessProvisioned ao usar o PowerShell e a CLI do Azure e o tamanho de computação para o SERVICE_OBJETIVE ao usar T-SQL. Analise os limites de recursos para identificar o tamanho de computação apropriado.
Os exemplos nesta seção mostram como mover seu banco de dados provisionado para serverless. Modifique o objetivo de serviço conforme necessário, pois esses exemplos definem o máximo de vCores como 4.
Utilizar o PowerShell
Mova um banco de dados de computação provisionado de uso geral para a camada de computação sem servidor com o seguinte exemplo do PowerShell:
Set-AzSqlDatabase -ResourceGroupName $resourceGroupName -ServerName $serverName -DatabaseName $databaseName `
-Edition GeneralPurpose -ComputeModel Serverless -ComputeGeneration Gen5 `
-MinVcore 1 -MaxVcore 4 -AutoPauseDelayInMinutes 1440
Utilizar a CLI do Azure
Mova um banco de dados de Propósito Geral de computação provisionado para a camada de computação sem servidor com o seguinte exemplo de CLI do Azure:
az sql db update -g $resourceGroupName -s $serverName -n $databaseName `
--edition GeneralPurpose --compute-model Serverless --family Gen5 `
--min-capacity 1 --capacity 4 --auto-pause-delay 1440
Usar Transact-SQL (T-SQL)
Quando você usa o T-SQL para mover um banco de dados entre camadas de computação, os valores padrão são aplicados para os vCores mínimos e o atraso de pausa automática. Eles podem ser alterados posteriormente no portal do Azure ou por meio de outras APIs de gerenciamento (PowerShell, CLI do Azure, API REST). Para obter mais informações, consulte ALTER DATABASE.
Mova um banco de dados de uso geral de computação provisionado para a camada de computação sem servidor com o seguinte exemplo de T-SQL:
ALTER DATABASE testdb
MODIFY ( SERVICE_OBJECTIVE = 'GP_S_Gen5_1') ;
Modificar a configuração sem servidor
Utilizar o PowerShell
Use Set-AzSqlDatabase para modificar o vCores máximo ou mínimo e o atraso de pausa automática. Use o MaxVcore, MinVcoree AutoPauseDelayInMinutes argumentos. Atualmente, não há suporte para a pausa automática sem servidor na camada Hyperscale, portanto, o argumento de atraso de pausa automática só é aplicável à camada de Propósito Geral.
Utilizar a CLI do Azure
Use az sql db update para modificar os vCores máximos ou mínimos e o atraso de pausa automática. Use o capacity, min-capacitye auto-pause-delay argumentos. Atualmente, não há suporte para a pausa automática sem servidor na camada Hyperscale, portanto, o argumento de atraso de pausa automática só é aplicável à camada de Propósito Geral.
Monitorizar
Recursos utilizados e faturados
Os recursos de um banco de dados sem servidor incluem o pacote do aplicativo, a instância SQL e as entidades do pool de recursos do usuário.
Pacote do aplicativo
O pacote do aplicativo é o limite externo de gerenciamento de recursos para um banco de dados, independentemente de o banco de dados estar em uma camada de computação sem servidor ou provisionada. O pacote do aplicativo contém a instância SQL e serviços externos, como a Pesquisa de Texto Completo, que, juntos, abrangem todos os recursos do usuário e do sistema usados por um banco de dados no Banco de dados SQL. A instância SQL geralmente domina a utilização geral de recursos em todo o pacote do aplicativo.
Pool de recursos do usuário
O pool de recursos do usuário é um limite interno de gerenciamento de recursos para um banco de dados, independentemente de o banco de dados estar em uma camada de computação sem servidor ou provisionada. O pool de recursos do usuário escopos CPU e E/S para a carga de trabalho do usuário gerada pelas consultas DDL (CREATE e ALTER) e DML (INSERT, UPDATE, DELETE e MERGE e SELECT). Essas consultas geralmente representam a proporção mais substancial de utilização dentro do pacote do aplicativo.
Métricas
A tabela a seguir inclui métricas para monitorar o uso de recursos do pacote do aplicativo e do pool de recursos do usuário de um banco de dados sem servidor, incluindo réplicas geográficas:
| Entity | Métrico | Description | Units |
|---|---|---|---|
| Pacote do aplicativo | app_cpu_percent | Porcentagem de vCores usados pelo aplicativo em relação ao máximo de vCores permitidos para o aplicativo. Para Hyperscale sem servidor, essa métrica é exposta para todas as réplicas primárias, réplicas nomeadas e réplicas geográficas. | Percentagem |
| Pacote do aplicativo | app_cpu_billed | A quantidade de computação cobrada pelo aplicativo durante o período de relatório. O valor pago durante este período é o produto desta métrica e do preço unitário vCore. Os valores desta métrica são determinados agregando o máximo de CPU usada e memória usada a cada segundo. Se o valor usado for menor do que o valor mínimo provisionado conforme definido pelos vCores mínimos e memória mínima, o valor mínimo provisionado será cobrado. De modo a comparar a CPU à memória para fins de faturação, a memória é normalizada em unidades de vCores ao redimensionar a quantidade de memória em GB por 3 GB por vCore. Para Hyperscale sem servidor, essa métrica é exposta para a réplica primária e quaisquer réplicas nomeadas. |
vCore segundos |
| Pacote do aplicativo | app_cpu_billed_HA_replicas | Aplicável apenas à Hyperscale sem servidor. Soma da computação cobrada em todos os aplicativos para réplicas de HA durante o período de relatório. Essa soma tem como escopo as réplicas de HA pertencentes à réplica primária ou as réplicas de HA pertencentes a uma determinada réplica nomeada. Antes de calcular essa soma em réplicas de HA, a quantidade de computação cobrada por uma réplica de HA individual é determinada da mesma forma que para a réplica primária ou uma réplica nomeada. Para Hyperscale sem servidor, essa métrica é exposta para todas as réplicas primárias, réplicas nomeadas e réplicas geográficas. O valor pago durante o período de relatório é o produto dessa métrica e do preço unitário vCore. | vCore segundos |
| Pacote do aplicativo | app_memory_percent | Porcentagem de memória usada pelo aplicativo em relação à memória máxima permitida para o aplicativo. Para Hyperscale sem servidor, essa métrica é exposta para todas as réplicas primárias, réplicas nomeadas e réplicas geográficas. | Percentagem |
| Pool de recursos do usuário | cpu_percent | Porcentagem de vCores usados pela carga de trabalho do usuário em relação ao máximo de vCores permitido para a carga de trabalho do usuário. | Percentagem |
| Pool de recursos do usuário | data_IO_percent | Porcentagem de IOPS de dados usada pela carga de trabalho do usuário em relação ao máximo de IOPS de dados permitido para a carga de trabalho do usuário. | Percentagem |
| Pool de recursos do usuário | log_IO_percent | Porcentagem de MB/s de log usada pela carga de trabalho do usuário em relação ao máximo de MB/s de log permitido para a carga de trabalho do usuário. | Percentagem |
| Pool de recursos do usuário | workers_percent | Porcentagem de trabalhadores usados pela carga de trabalho do usuário em relação aos trabalhadores máximos permitidos para a carga de trabalho do usuário. | Percentagem |
| Pool de recursos do usuário | sessions_percent | Porcentagem de sessões usadas pela carga de trabalho do usuário em relação ao máximo de sessões permitidas para a carga de trabalho do usuário. | Percentagem |
Pausar e retomar o status
No portal do Azure, o status do banco de dados é exibido no painel de visão geral do servidor que lista os bancos de dados que ele contém. O status do banco de dados também é exibido no painel de visão geral do banco de dados.
Usando os seguintes comandos para consultar o status de pausa e retomada de um banco de dados:
Utilizar o PowerShell
Get-AzSqlDatabase -ResourceGroupName $resourcegroupname -ServerName $servername -DatabaseName $databasename `
| Select -ExpandProperty "Status"
Utilizar a CLI do Azure
az sql db show --name $databasename --resource-group $resourcegroupname --server $servername --query 'status' -o json
Limites de recursos
Para limites de recursos, consulte camada de computação sem servidor.
Faturação
A quantidade de computação cobrada por um banco de dados sem servidor é o máximo de CPU usada e memória usada a cada segundo. Se a quantidade de CPU e memória usada for menor do que o valor mínimo provisionado para cada recurso, o valor provisionado será cobrado. Para comparar a CPU com a memória para fins de faturamento, a memória é normalizada em unidades de vCores reescalonando o número de GB em 3 GB por vCore.
- Recurso faturado: CPU e memória
- Valor cobrado: vCore preço unitário * máximo (vCores mínimo, vCores usados, GB de memória mínimo * 1/3, GB de memória usado * 1/3)
- Frequência de faturação: Por segundo
O preço unitário do vCore é o custo por vCore por segundo. Para Hyperscale, o preço unitário vCore para uma réplica HA ou réplica nomeada é menor do que para a réplica primária.
Veja a página de preços da Base de Dados SQL do Azure para obter os preços unitários específicos numa determinada região.
A quantidade de computação cobrada sem servidor para um banco de dados de uso geral ou uma réplica primária ou nomeada de hiperescala é exposta pela seguinte métrica:
- Métrica: app_cpu_billed (segundos vCore)
- Definição: máximo (mínimo vCores, vCores usados, mínimo GB de memória * 1/3, GB de memória usado * 1/3)
- Frequência de notificação: por minuto com base em medições por segundo agregadas ao longo de 1 minuto.
A quantidade de computação cobrada sem servidor para réplicas de HA de hiperescala pertencentes à réplica primária ou a qualquer réplica nomeada é exposta pela seguinte métrica:
- Métrica: app_cpu_billed_HA_replicas (segundos vCore)
- Definição: Soma do máximo (vCores mínimos, vCores usados, GB mínimo de memória * 1/3, GB de memória usado * 1/3) para quaisquer réplicas HA pertencentes ao recurso pai.
- Recurso pai e ponto de extremidade de métrica: a réplica primária e qualquer réplica nomeada separadamente expõem essa métrica, que mede a computação cobrada por quaisquer réplicas de HA associadas.
- Frequência de notificação: por minuto com base em medições por segundo agregadas ao longo de 1 minuto.
Conta mínima de computação
Se um banco de dados sem servidor estiver pausado, a conta de computação será zero. Se um banco de dados sem servidor não estiver pausado, a conta mínima de computação não será inferior à quantidade de vCores com base no máximo (vCores mínimo, GB de memória mínimo * 1/3).
Exemplos:
- Suponha que um banco de dados sem servidor na camada de uso geral não esteja pausado e configurado com 8 vCores máximos e 1 vCore mínimo correspondente a 3,0 GB de memória mínima. Em seguida, a conta mínima de computação é baseada no máximo (1 vCore, 3,0 GB * 1 vCore / 3 GB) = 1 vCore.
- Suponha que um banco de dados sem servidor na camada de uso geral não esteja pausado e configurado com 4 vCores máximos e 0,5 vCores mínimos correspondentes a 2,1 GB de memória mínima. Em seguida, a conta mínima de computação é baseada no máximo (0,5 vCores, 2,1 GB * 1 vCore / 3 GB) = 0,7 vCores.
- Suponha que um banco de dados sem servidor na camada Hyperscale tenha uma réplica primária com uma réplica HA e uma réplica nomeada sem réplicas HA. Suponha que cada réplica esteja configurada com 8 vCores no máximo e 1 vCore mínimo correspondente a 3 GB de memória mínima. Em seguida, a fatura mínima de computação para a réplica primária, a réplica HA e a réplica nomeada são baseadas no máximo (1 vCore, 3 GB * 1 vCore / 3 GB) = 1 vCore.
A calculadora de preços do Banco de Dados SQL do Azure para serverless pode ser usada para determinar a memória mínima configurável com base no número máximo e mínimo de vCores configurados. Como regra, se o mínimo de vCores configurado for maior que 0,5 vCores, a fatura mínima de computação será independente da memória mínima configurada e baseada apenas no número mínimo de vCores configurados.
Exemplos de cenários
Considere um banco de dados sem servidor na camada de uso geral configurado com 1 vCore mínimo e 4 vCores máximos. Esta configuração corresponde a cerca de 3 GB de memória mínima e 12 GB de memória máxima. Suponha que o atraso de pausa automática esteja definido como 6 horas e a carga de trabalho do banco de dados esteja ativa durante as primeiras 2 horas de um período de 24 horas e inativa.
Nesse caso, o banco de dados é cobrado pela computação e armazenamento durante as primeiras 8 horas. Mesmo que o banco de dados esteja inativo a partir da segunda hora, ele ainda é cobrado pela computação nas 6 horas subsequentes com base na computação mínima provisionada enquanto o banco de dados está online. Somente o armazenamento é cobrado durante o restante do período de 24 horas enquanto o banco de dados está pausado.
Mais precisamente, a conta de computação neste exemplo é calculada da seguinte forma:
| Intervalo de tempo | vCores usados a cada segundo | GB usado a cada segundo | Dimensão de computação faturada | vCore segundos faturados ao longo do intervalo de tempo |
|---|---|---|---|---|
| 0:00-1:00 | 4 | 9 | vCores usados | 4 vCores * 3600 segundos = 14400 segundos vCore |
| 1:00-2:00 | 5 | 12 | Memória utilizada | 12 GB * 1/3 * 3600 segundos = 14400 segundos vCore |
| 2:00-8:00 | 0 | 0 | Memória mínima provisionada | 3 GB * 1/3 * 21600 segundos = 21600 segundos vCore |
| 8:00-24:00 | 0 | 0 | Nenhum cálculo cobrado durante a pausa | 0 segundos vCore |
| Total de segundos vCore faturados em 24 horas | 50.400 segundos vCore |
Suponha que o preço unitário de computação seja $0,000145/vCore/segundo. Em seguida, o cálculo cobrado para este período de 24 horas é o produto do preço unitário de computação e segundos vCore faturados: $0,000145/vCore/segundo * 50400 segundos vCore ~ $7,31.
Benefício Híbrido do Azure e capacidade reservada
O Benefício Híbrido do Azure (AHB) e os descontos de capacidade reservada não se aplicam à camada de computação sem servidor.
Regiões disponíveis
As camadas Serverless for General Purpose e Hyperscale com suporte a até 40 vCores no máximo estão disponíveis em todo o mundo, exceto nas seguintes regiões:
- Norte da China
- Norte da China
- Alemanha Central
- Nordeste da Alemanha
- Governo Central dos EUA (Iowa)
Regiões que suportam 80 vCores máximos sem zonas de disponibilidade para uso geral e hiperescala
Atualmente, há suporte para o máximo de 80 vCores sem servidor para camadas de uso geral e hiperescala nas seguintes regiões:
- Leste da Austrália
- Austrália Sudeste
- Sul do Brasil
- Canadá Central
- E.U.A. Central
- Ásia Leste
- E.U.A. Leste
- E.U.A. Leste 2
- França Central
- Sul de França
- Alemanha Centro-Oeste
- Índia Central
- Índia do Sul
- Leste do Japão
- Oeste do Japão
- E.U.A. Centro-Norte
- Europa do Norte
- Leste da Noruega
- Catar Central
- Norte da África do Sul
- E.U.A. Centro-Sul
- Norte da Suíça
- Sul do Reino Unido
- Oeste do Reino Unido
- Europa Ocidental
- E.U.A. Centro-Oeste
- E.U.A. Oeste
- E.U.A. Oeste 2
- EUA Oeste 3
Regiões que suportam 80 vCores máximos com zonas de disponibilidade para uso geral
Atualmente, 80 vCores máximos com suporte à zona de disponibilidade sem servidor para a camada de uso geral são fornecidos nas seguintes regiões com mais regiões planejadas:
- E.U.A. Leste
- Europa do Norte
- Europa Ocidental
- E.U.A. Oeste 2
Regiões que suportam 80 vCores máximos com zonas de disponibilidade para Hyperscale
Atualmente, 80 vCores máximos com suporte à zona de disponibilidade sem servidor para a camada Hyperscale são fornecidos nas seguintes regiões com mais regiões planejadas:
- E.U.A. Central
- E.U.A. Leste
- Europa do Norte
- Europa Ocidental
- E.U.A. Oeste 2
- EUA Oeste 3
Conteúdos relacionados
- Para começar, consulte Guia de início rápido: criar um único banco de dados - Banco de Dados SQL do Azure.
- Para opções de camada de serviço sem servidor, consulte Uso geral e hiperescala.
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários