Réplicas secundárias do Hyperscale
Aplica-se a:![]() Banco de Dados SQL do Azure
Banco de Dados SQL do Azure
Conforme descrito em Arquitetura de funções distribuídas, o Azure SQL Database Hyperscale tem dois tipos diferentes de nós de computação, também conhecidos como réplicas:
- Principal: serve operações de leitura e escrita
- Secundário: fornece escalabilidade horizontal de leitura, alta disponibilidade e replicação geográfica
As réplicas secundárias são sempre somente leitura e podem ser de três tipos diferentes:
- Réplica de alta disponibilidade
- Geo-réplica
- Réplica nomeada
Cada tipo tem uma arquitetura, um conjunto de recursos, uma finalidade e um custo diferentes. Com base nos recursos que você precisa, você pode usar apenas um ou até mesmo todos os três juntos. As réplicas secundárias são suportadas por camadas de computação provisionadas e sem servidor.
Réplica de alta disponibilidade
Uma réplica de alta disponibilidade (HA) usa os mesmos servidores de página que a réplica primária, portanto, nenhuma cópia de dados é necessária para adicionar uma réplica de HA. As réplicas de HA são usadas principalmente para aumentar a disponibilidade do banco de dados; eles atuam como hot standbys para fins de failover. Se a réplica primária ficar indisponível, o failover para uma das réplicas de HA existentes será automático e rápido. A cadeia de conexão não precisa ser alterada; Durante o failover, os aplicativos podem enfrentar um tempo de inatividade mínimo devido à queda de conexões ativas. Como de costume para esse cenário, recomenda-se a lógica de repetição adequada. Vários drivers já fornecem algum grau de lógica de repetição automática. Se você estiver usando o .NET, a biblioteca Microsoft.Data.SqlClient mais recente fornece suporte nativo completo para lógica de repetição automática configurável.
As réplicas HA usam o mesmo nome de servidor e banco de dados que a réplica primária. Seu Objetivo de Nível de Serviço também é sempre o mesmo da réplica principal. As réplicas de HA não são visíveis ou gerenciáveis como um recurso autônomo do portal ou de qualquer API.
Pode haver de zero a quatro réplicas de HA. Seu número pode ser alterado durante a criação de um banco de dados ou após a criação do banco de dados, por meio dos pontos de extremidade e ferramentas de gerenciamento comuns (por exemplo: PowerShell, AZ CLI, Portal, API REST). A criação ou remoção de réplicas HA não afeta as conexões ativas na réplica primária.
Conectar-se a uma réplica HA
Em bancos de dados Hyperscale, o ApplicationIntent argumento na cadeia de conexão usada pelo cliente determina se a conexão é roteada para a réplica primária de leitura-gravação ou para uma réplica HA somente leitura. Se ApplicationIntent estiver definido como ReadOnly e o banco de dados não tiver uma réplica secundária, a conexão será roteada para a réplica primária e assumirá como padrão o ReadWrite comportamento.
-- Connection string with application intent
Server=tcp:<myserver>.database.windows.net;Database=<mydatabase>;ApplicationIntent=ReadOnly;User ID=<myLogin>;Password=<myPassword>;Trusted_Connection=False; Encrypt=True;
Todas as réplicas de HA são idênticas em sua capacidade de recursos. Se mais de uma réplica de HA estiver presente, a carga de trabalho de intenção de leitura será distribuída arbitrariamente em todas as réplicas de HA disponíveis. Quando houver várias réplicas de HA, lembre-se de que cada uma delas pode ter latência de dados diferente em relação às alterações de dados feitas na primária. Cada réplica HA usa os mesmos dados que o primário no mesmo conjunto de servidores de página. No entanto, os caches de dados locais em cada réplica HA refletem as alterações feitas no primário por meio do serviço de log de transações, que encaminha registros de log da réplica primária para réplicas HA. Como resultado, dependendo da carga de trabalho que está sendo processada por uma réplica HA, a aplicação de registros de log pode acontecer em velocidades diferentes e, portanto, réplicas diferentes podem ter latência de dados diferente em relação à réplica primária.
Réplica nomeada
Uma réplica nomeada, assim como uma réplica HA, usa os mesmos servidores de página que a réplica primária. Semelhante às réplicas HA, não há nenhuma cópia de dados necessária para adicionar uma réplica nomeada.
Há diferenças entre réplicas HA e réplicas nomeadas:
- As réplicas nomeadas aparecem como bancos de dados SQL regulares (somente leitura) do Azure no portal e em chamadas API (AZ CLI, PowerShell, T-SQL).
- As réplicas nomeadas podem ter um nome de banco de dados diferente da réplica primária e, opcionalmente, estar localizadas em um servidor lógico diferente (desde que estejam na mesma região da réplica primária).
- As réplicas nomeadas têm seu próprio Objetivo de Nível de Serviço que pode ser definido e alterado independentemente da réplica primária.
- As réplicas nomeadas suportam até 30 réplicas nomeadas (para cada réplica primária).
- As réplicas nomeadas oferecem suporte a autenticação diferente para cada réplica nomeada, criando logins diferentes em servidores lógicos que hospedam réplicas nomeadas.
Como resultado, as réplicas nomeadas oferecem vários benefícios em relação às réplicas HA, no que diz respeito às cargas de trabalho somente leitura:
- Os usuários conectados a uma réplica nomeada não sofrerão nenhuma desconexão se a réplica primária for dimensionada para cima ou para baixo; Ao mesmo tempo, os usuários conectados à réplica principal não serão afetados pelo dimensionamento de réplicas nomeadas para cima ou para baixo.
- As cargas de trabalho executadas em qualquer réplica, primária ou nomeada, não serão afetadas por consultas de longa execução em execução em outras réplicas.
O principal objetivo das réplicas nomeadas é permitir uma ampla variedade de cenários de expansão de leitura e melhorar as cargas de trabalho de processamento analítico e transacional híbrido (HTAP). Exemplos de como criar tais soluções estão disponíveis aqui:
Além dos principais cenários listados acima, as réplicas nomeadas oferecem flexibilidade e elasticidade para também satisfazer muitos outros casos de uso:
- Isolamento de acesso: você pode conceder acesso a uma réplica nomeada específica, mas não à réplica primária ou outras réplicas nomeadas.
- Objetivo de nível de serviço dependente da carga de trabalho: como uma réplica nomeada pode ter seu próprio objetivo de nível de serviço, é possível usar réplicas nomeadas diferentes para cargas de trabalho e casos de uso diferentes. Por exemplo, uma réplica nomeada pode ser usada para atender solicitações do Power BI, enquanto outra pode ser usada para fornecer dados ao Apache Spark para tarefas de Ciência de Dados. Cada um pode ter um objetivo de nível de serviço independente e escalar de forma independente.
- Roteamento dependente da carga de trabalho: com até 30 réplicas nomeadas, é possível usar réplicas nomeadas em grupos para que um aplicativo possa ser isolado de outro. Por exemplo, um grupo de quatro réplicas nomeadas pode ser usado para atender solicitações provenientes de aplicativos móveis, enquanto outro grupo de duas réplicas nomeadas pode ser usado para atender solicitações provenientes de um aplicativo Web. Esta abordagem permitiria um ajuste refinado do desempenho e dos custos para cada grupo.
O exemplo a seguir cria uma réplica WideWorldImporters_NamedReplica nomeada para o banco de dados WideWorldImporters. A réplica primária usa HS_Gen5_4 de objetivo de nível de serviço, enquanto a réplica nomeada usa HS_Gen5_2. Ambos usam o mesmo servidor contosoeastlógico. Se você preferir usar a API REST diretamente, essa opção também é possível: Bancos de dados - Criar um banco de dados como réplica nomeada secundária.
No portal do Azure, navegue até o banco de dados para o qual você deseja criar a réplica nomeada.
Na página Banco de Dados SQL, selecione seu banco de dados, role até Gerenciamento de dados, selecione Réplicas e selecione Criar réplica.
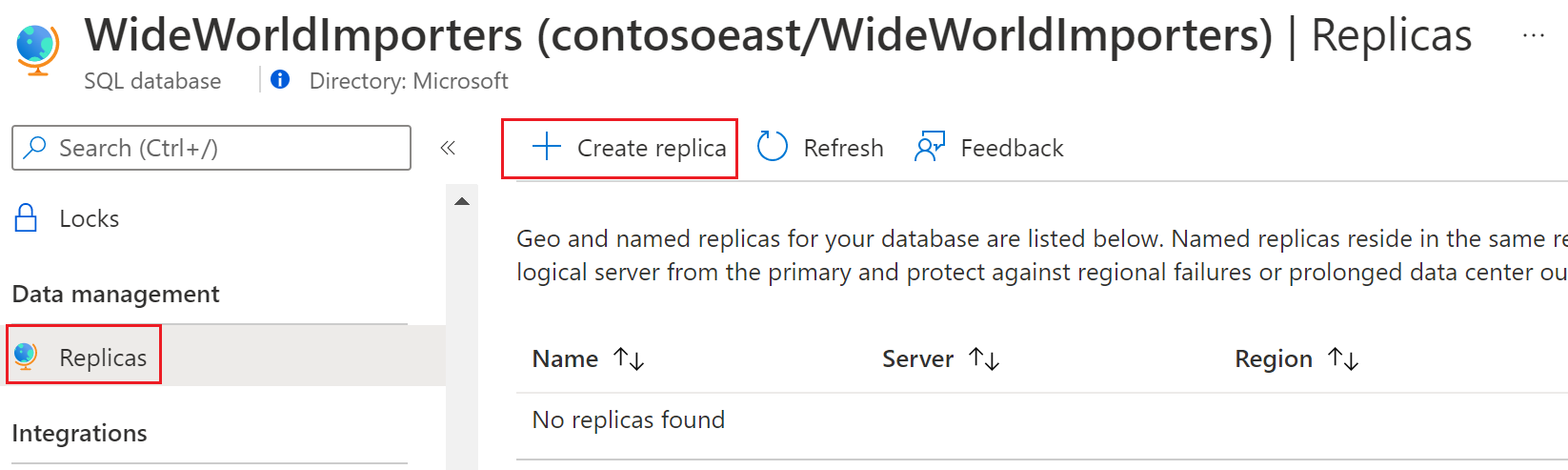
Escolha Réplica nomeada em Configuração da réplica, selecione ou crie o servidor para a réplica nomeada, insira o nome do banco de dados da réplica nomeada e configure as opções Computação + armazenamento , se necessário.
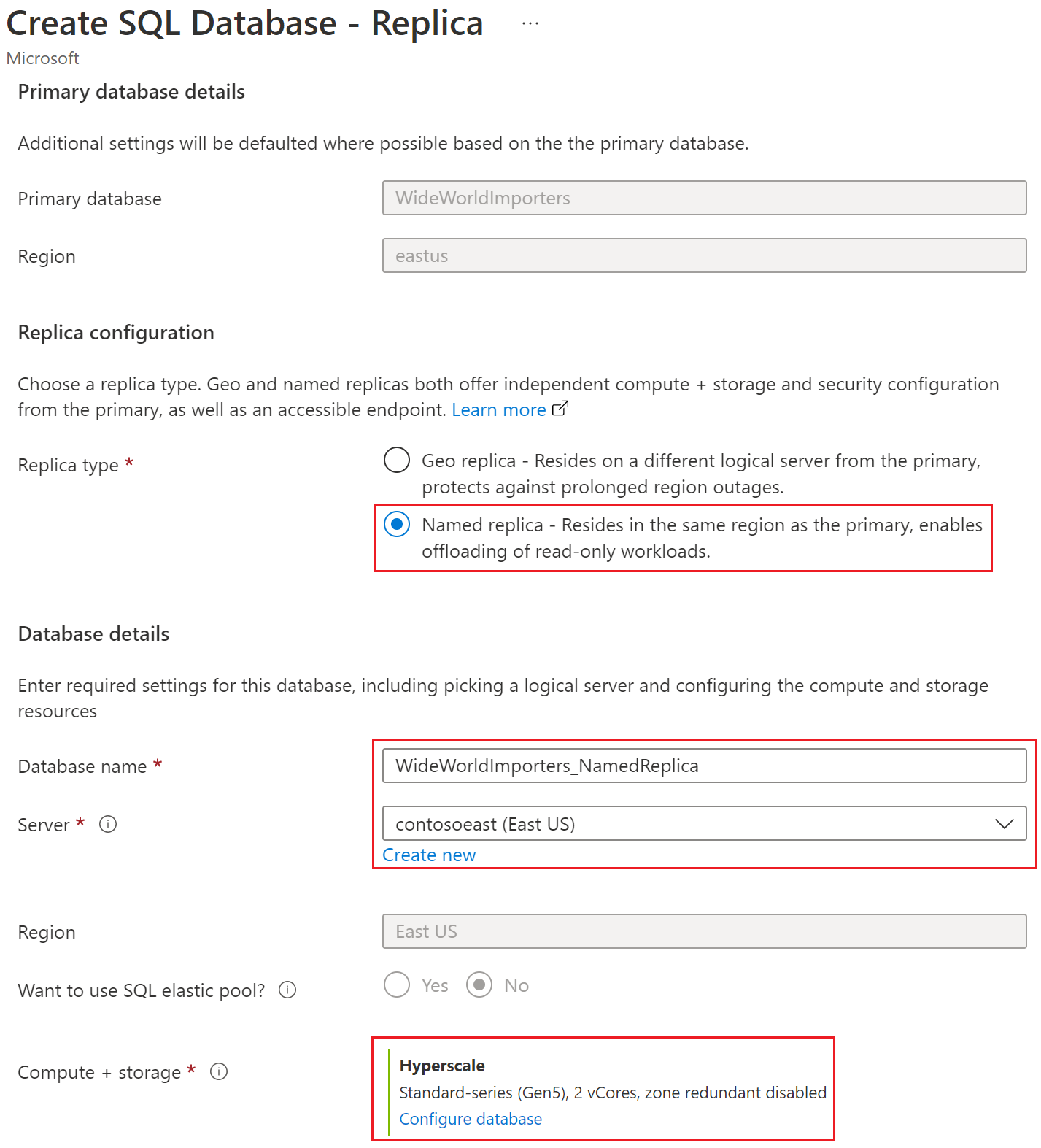
Selecione Rever + criar, reveja as informações e, em seguida, selecione Criar.
O processo de implantação da réplica nomeada é iniciado.
Quando a implantação estiver concluída, a réplica nomeada exibirá seu status.
Retorne à página do banco de dados primário e selecione Réplicas. Sua réplica nomeada está listada em Réplicas nomeadas.
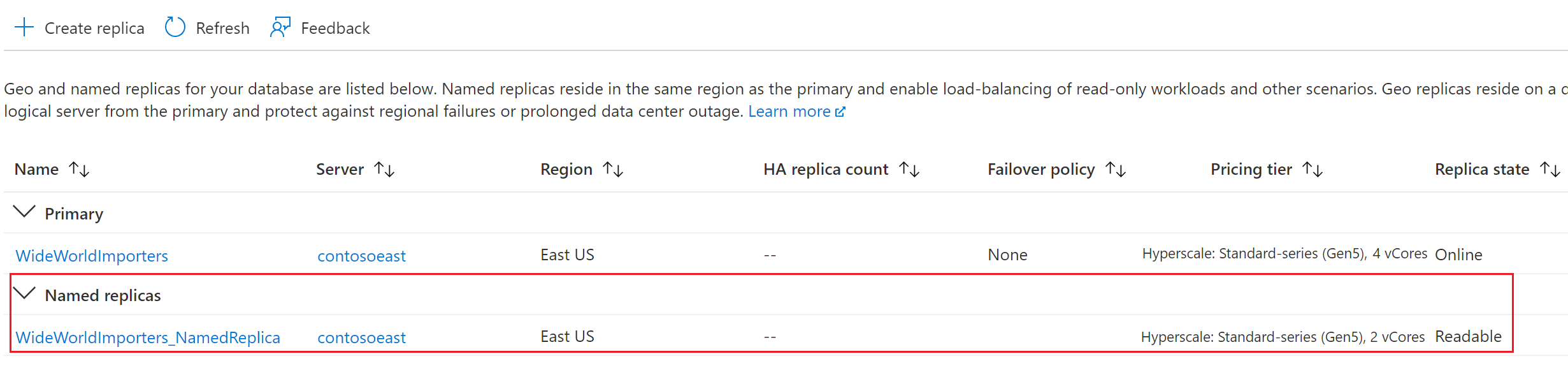
Como não há movimentação de dados envolvida, na maioria dos casos, uma réplica nomeada será criada em cerca de um minuto. Quando a réplica nomeada estiver disponível, ela ficará visível no portal ou em qualquer ferramenta de linha de comando, como AZ CLI ou PowerShell. Uma réplica nomeada é utilizável como um banco de dados somente leitura regular.
Nota
Para perguntas frequentes sobre réplicas nomeadas Hyperscale, consulte Perguntas frequentes sobre réplicas nomeadas Hyperscale do Banco de Dados SQL do Azure.
Conectar-se a uma réplica nomeada
Para se conectar a uma réplica nomeada, você deve usar a cadeia de conexão para essa réplica nomeada, fazendo referência aos nomes de servidor e banco de dados. Não há necessidade de especificar a opção "ApplicationIntent=ReadOnly", pois as réplicas nomeadas são sempre somente leitura.
Assim como para réplicas de HA, embora as réplicas primárias, HA e nomeadas compartilhem os mesmos dados no mesmo conjunto de servidores de página, os caches de dados em cada réplica nomeada são mantidos em sincronia com a principal por meio do serviço de log de transações, que encaminha os registros de log da réplica primária para as réplicas nomeadas. Como resultado, dependendo da carga de trabalho que está sendo processada por uma réplica nomeada, a aplicação dos registros de log pode acontecer em velocidades diferentes e, portanto, réplicas diferentes podem ter latência de dados diferente em relação à réplica primária.
Modificar uma réplica nomeada
Você pode definir o objetivo de nível de serviço de uma réplica nomeada ao criá-la, por meio do comando ou de qualquer outra forma suportada ALTER DATABASE (Portal, AZ CLI, PowerShell, API REST). Se você precisar alterar o objetivo de nível de serviço após a réplica nomeada ter sido criada, poderá fazê-lo usando o ALTER DATABASE ... MODIFY comando na própria réplica nomeada. Por exemplo, se WideWorldImporters_NamedReplica for a réplica nomeada do banco de WideWorldImporters dados, você pode fazê-lo como mostrado abaixo.
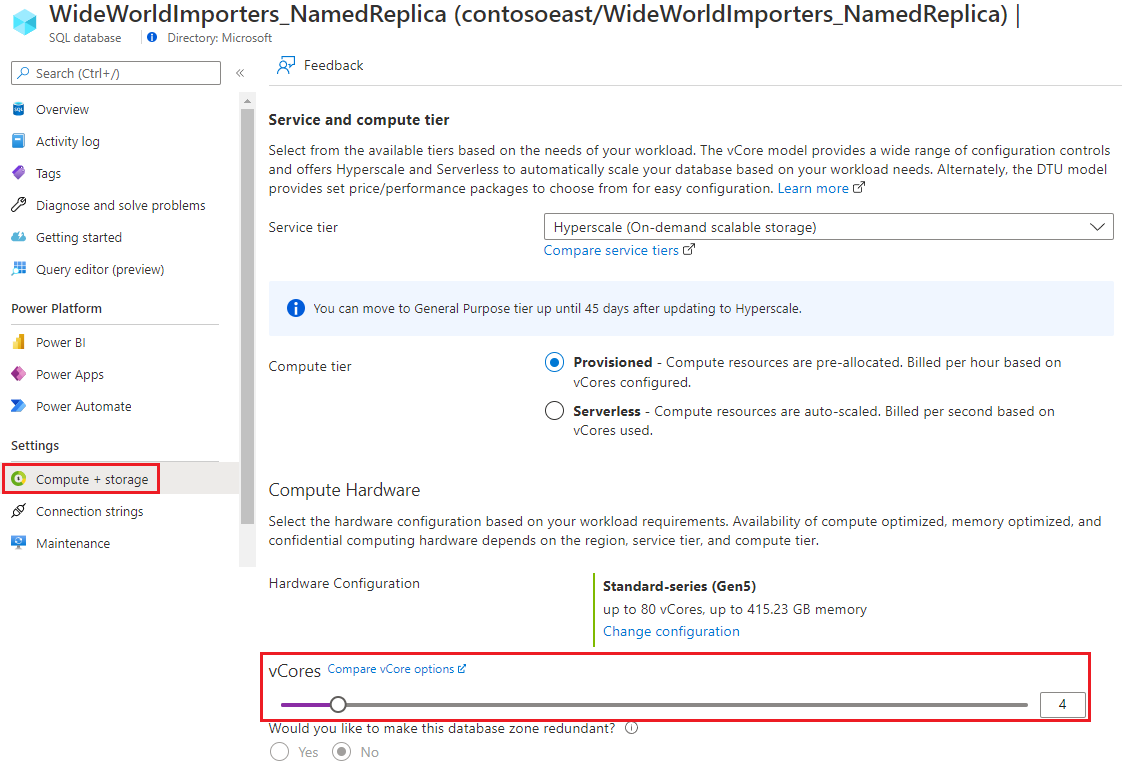
Abra a página do banco de dados de réplica nomeada e selecione Computação + armazenamento. Atualize os vCores.
Remover uma réplica nomeada
Para remover uma réplica nomeada, solte-a como faria com um banco de dados normal.
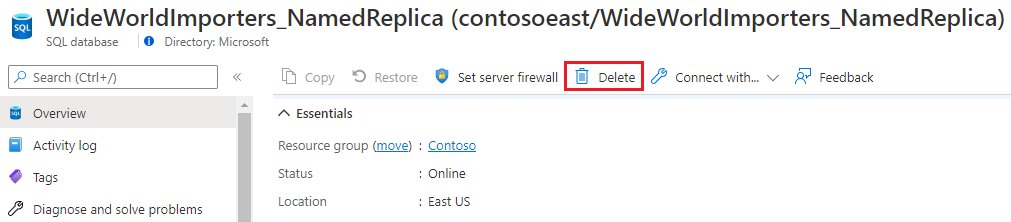
Abra a página do banco de dados de réplica nomeada e escolha a Delete opção.
Importante
As réplicas nomeadas serão removidas automaticamente quando a réplica primária a partir da qual foram criadas for excluída.
Problemas conhecidos
Dados parcialmente incorretos retornados de sys.databases
Os valores de linha retornados de , para réplicas nomeadas, em colunas diferentes de sys.databasesname e , podem ser inconsistentes e database_idincorretos. Por exemplo, a coluna de uma réplica nomeada pode ser relatada como 140 mesmo que o banco de dados primário a partir do qual a compatibility_level réplica nomeada foi criada esteja definido como 150. Uma solução alternativa, quando possível, é obter os mesmos dados usando a DATABASEPROPERTYEX() função, que retornará os dados corretos.
Geo-réplica
Com a replicação geográfica ativa, você pode criar uma réplica secundária legível do banco de dados primário do Hyperscale na mesma região do Azure ou em uma região diferente. As réplicas geográficas devem ser criadas em um servidor lógico diferente. O nome do banco de dados de uma réplica geográfica sempre corresponde ao nome do banco de dados primário.
Ao criar uma réplica geográfica, todos os dados são copiados do primário para um conjunto diferente de servidores de página. Uma réplica geográfica não compartilha servidores de página com o principal, mesmo que eles estejam na mesma região. Essa arquitetura fornece a redundância necessária para geofailovers.
As réplicas geográficas são usadas para manter uma cópia transacionalmente consistente do banco de dados por meio da replicação assíncrona. Se uma réplica geográfica estiver em uma região diferente do Azure, ela poderá ser usada para recuperação de desastres em caso de desastre ou interrupção na região principal. As réplicas geográficas também podem ser usadas para cenários de expansão de leitura geográfica. A partir de outubro de 2022, a cópia de banco de dados de uma réplica secundária geográfica Hyperscale é suportada.
A replicação geográfica para o banco de dados Hyperscale tem as seguintes limitações atuais:
- Apenas uma réplica geográfica pode ser criada (na mesma região ou em regiões diferentes).
- Não há suporte para a restauração point-in-time da réplica geográfica.
- Não há suporte para a criação de uma réplica geográfica de uma réplica geográfica (também conhecida como "encadeamento de réplica geográfica").